
 Périphériques technologiques
IA
Réduisez le rang du Transformer pour améliorer les performances tout en conservant le LLM sans réduire la suppression de plus de 90 % des composants dans une couche spécifique.
Périphériques technologiques
IA
Réduisez le rang du Transformer pour améliorer les performances tout en conservant le LLM sans réduire la suppression de plus de 90 % des composants dans une couche spécifique.
Réduisez le rang du Transformer pour améliorer les performances tout en conservant le LLM sans réduire la suppression de plus de 90 % des composants dans une couche spécifique.

Le MIT et Microsoft ont mené des recherches conjointes et ont découvert qu'aucune formation supplémentaire n'est nécessaire pour améliorer les performances des tâches des grands modèles de langage et réduire leur taille
À l'ère des grands modèles, Transformer est connu pour ses capacités uniques. tout le domaine de la recherche scientifique. Depuis leur introduction, les modèles de langage basés sur Transformer (LLM) ont démontré d'excellentes performances dans diverses tâches. L'architecture sous-jacente de Transformer est devenue la technologie de pointe pour la modélisation et le raisonnement du langage naturel, et a montré de fortes perspectives dans des domaines tels que la vision par ordinateur et l'apprentissage par renforcement.
Cependant, l'architecture actuelle de Transformer est très vaste et généralement nécessite une grande quantité de ressources informatiques pour l’entraînement et le raisonnement.
Réécrivez-le comme ceci : cela est logique de faire cela car un Transformer formé avec plus de paramètres ou de données est évidemment plus performant que les autres modèles. Cependant, de plus en plus de recherches montrent que les modèles basés sur Transformer et les réseaux de neurones n'ont pas besoin de conserver tous les paramètres d'adaptation pour conserver leurs hypothèses apprises.
En général, la surparamétrage semble être utile lors de la formation de modèles, mais ces modèles peuvent être fortement élagué avant l'inférence. Des études ont montré que les réseaux de neurones peuvent souvent supprimer plus de 90 % des poids sans baisse significative des performances. Ce phénomène a suscité l'intérêt des chercheurs pour les stratégies d'élagage qui aident à modéliser le raisonnement.
Des chercheurs du MIT et de Microsoft ont écrit dans l'article "The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction" qui présente une découverte surprenante qui fait preuve de prudence. l'élagage sur des couches spécifiques du modèle Transformer peut améliorer considérablement les performances du modèle sur certaines tâches.

Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/pdf/2312.13558.pdf
-
Page d'accueil de l'article : https://pratyushashama.github.io/laser/
L'étude appelle cette intervention simple LASER (Layer Selective Rank Reduction), qui améliore considérablement les performances du LLM en réduisant sélectivement les composants d'ordre supérieur de la matrice de poids apprise de couches spécifiques dans le modèle Transformer grâce à une décomposition en valeurs singulières. Cette opération peut être effectuée une fois la formation du modèle terminée sans paramètres ni données supplémentaires
Pendant l'opération, la réduction des poids est effectuée dans des matrices et des couches de poids spécifiques au modèle. Cette étude a également révélé que de nombreuses matrices similaires peuvent réduire considérablement les poids, et généralement aucune dégradation des performances n'est observée jusqu'à ce que plus de 90 % des composants soient supprimés.
L'étude a également révélé que ces réductions peuvent améliorer considérablement la précision, une conclusion qui ne semble pas limitée. Par rapport au langage naturel, des améliorations des performances ont également été constatées dans l’apprentissage par renforcement.
De plus, cette recherche tente de déduire ce qui est stocké dans les composants d'ordre supérieur afin de pouvoir le supprimer pour améliorer les performances. L'étude a révélé que LASER répondait aux bonnes questions, mais qu'avant l'intervention, le modèle original répondait principalement avec des mots à haute fréquence (tels que "le", "de", etc.), qui n'étaient même pas du même type sémantique que le bonne réponse, et aussi C'est-à-dire que ces composants amèneront le modèle à générer des mots haute fréquence non pertinents sans intervention.
Cependant, en effectuant un certain degré de réduction de rang, la réponse du modèle peut être transformée en correcte.
Pour comprendre cela, l'étude a également exploré ce que les composants restants codaient individuellement, et ils ont approximé la matrice de poids en utilisant uniquement leurs vecteurs singuliers d'ordre supérieur. Il a été constaté que ces composants décrivaient des réponses différentes ou des mots courants à haute fréquence dans la même catégorie sémantique que la réponse correcte.
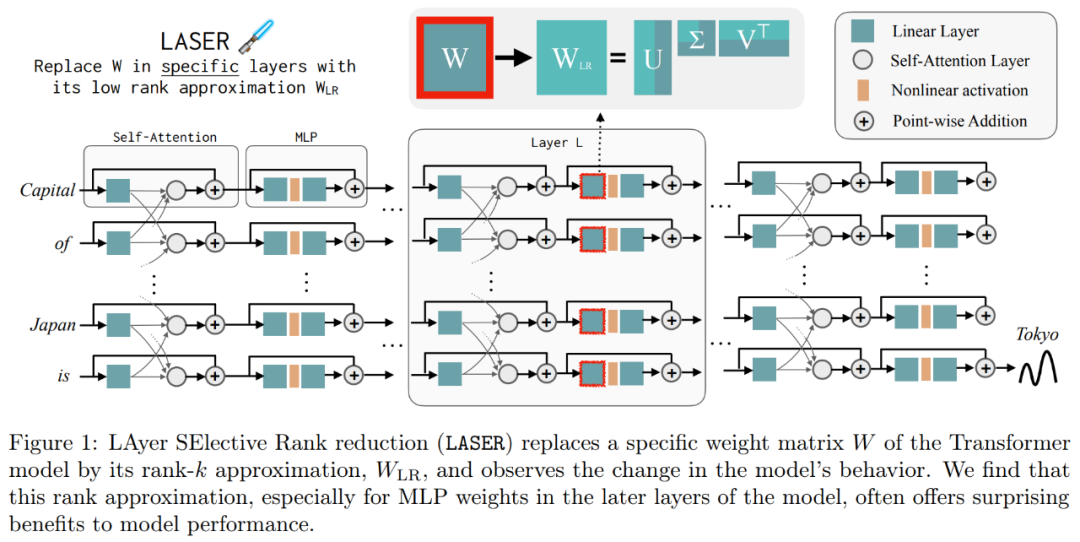
Ces résultats suggèrent que lorsque des composants bruyants d'ordre supérieur sont combinés avec des composants d'ordre inférieur, leurs réponses contradictoires produisent une réponse moyenne, qui peut être incorrecte. La figure 1 fournit une représentation visuelle de l'architecture du Transformer et de la procédure suivie par LASER. Ici, la matrice de poids d'une couche spécifique de perceptron multicouche (MLP) est remplacée par son approximation de bas rang.
Vue d'ensemble du laser
fournit une introduction détaillée à l'intervention LASER. Une intervention LASER en une seule étape est définie par le triplet (τ, ℓ, ρ), qui contient le paramètre τ, le nombre de couches ℓ et le rang réduit ρ. Ensemble, ces valeurs décrivent les matrices à remplacer par leurs approximations de bas rang, et le degré d'approximation. Les chercheurs classent les types de matrices avec lesquels ils interféreront en fonction des types de paramètres
Les chercheurs se concentrent sur les matrices en W = {W_q, W_k, W_v, W_o, U_in, U_out}, qui se composent de matrices en MLP et de couches d'attention. Le nombre de strates représente la strate d'intervention du chercheur (la première strate est indexée à partir de 0). Par exemple, Llama-2 a 32 couches, donc ℓ ∈ {0, 1, 2,・・・31}.
En fin de compte, ρ ∈ [0, 1) décrit quelle partie du rang maximum doit être préservée lors des approximations de bas rang. Par exemple, en supposant 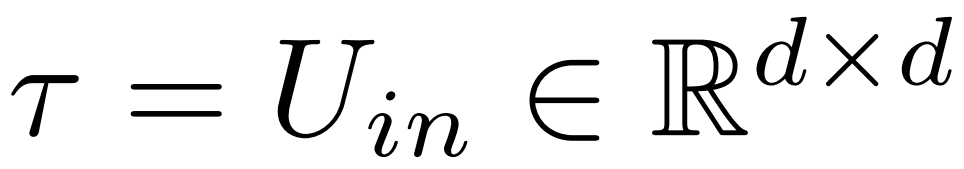 , le rang maximum de cette matrice est d. Les chercheurs l'ont remplacé par l'approximation ⌊ρ・d⌋-.
, le rang maximum de cette matrice est d. Les chercheurs l'ont remplacé par l'approximation ⌊ρ・d⌋-.
La figure 1 ci-dessous est un exemple de LASER. Dans cette figure, τ = U_in et ℓ = L représentent la mise à jour de la matrice de poids de la première couche de MLP dans le bloc Transformateur de la L^ème couche. Un autre paramètre contrôle k dans l'approximation du rang k.
LASER peut restreindre le flux de certaines informations dans un réseau et produire de manière inattendue des avantages significatifs en termes de performances. Ces interventions peuvent également être facilement combinées, comme appliquer un ensemble d'interventions dans n'importe quel ordre 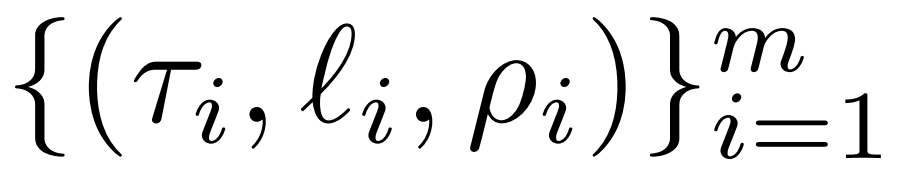 .
.
La méthode LASER n'est qu'une simple recherche de telles interventions, modifiées pour apporter un maximum de bénéfices. Il existe cependant de nombreuses autres manières de combiner ces interventions, ce qui constitue une orientation pour les travaux futurs.
Afin de conserver le sens original inchangé, le contenu doit être réécrit en chinois. Il n'est pas nécessaire d'afficher la phrase originale
Dans la partie expérimentale, le chercheur a utilisé le modèle GPT-J pré-entraîné sur l'ensemble de données PILE. Le nombre de couches du modèle est de 27 et les paramètres sont de 6 milliards. Le comportement du modèle est ensuite évalué sur l'ensemble de données CounterFact, qui contient des échantillons de triplets (sujet, relation et réponse), avec trois invites de paraphrase fournies pour chaque question.
La première est l'analyse du modèle GPT-J sur le jeu de données CounterFact. La figure 2 ci-dessous montre l'impact sur la perte de classification de l'ensemble de données suite à l'application de différents niveaux de réduction de rang à chaque matrice de l'architecture Transformer. Chacune des couches du transformateur se compose d'un petit MLP à deux couches, avec les matrices d'entrée et de sortie affichées séparément. Différentes couleurs représentent différents pourcentages de composants supprimés.
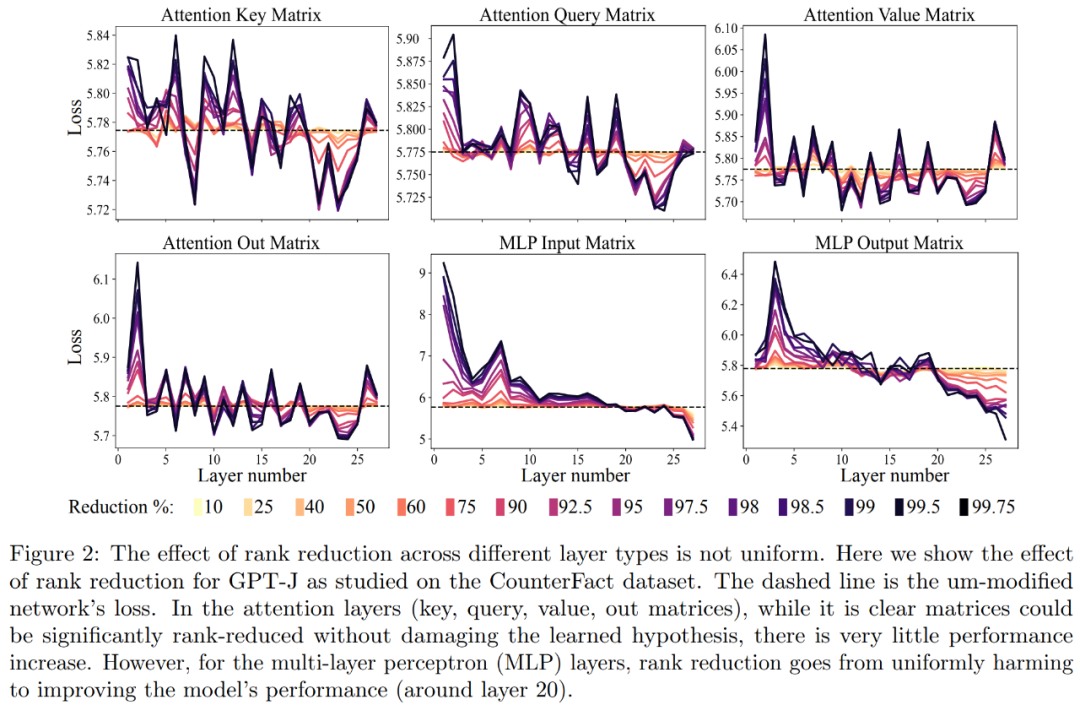
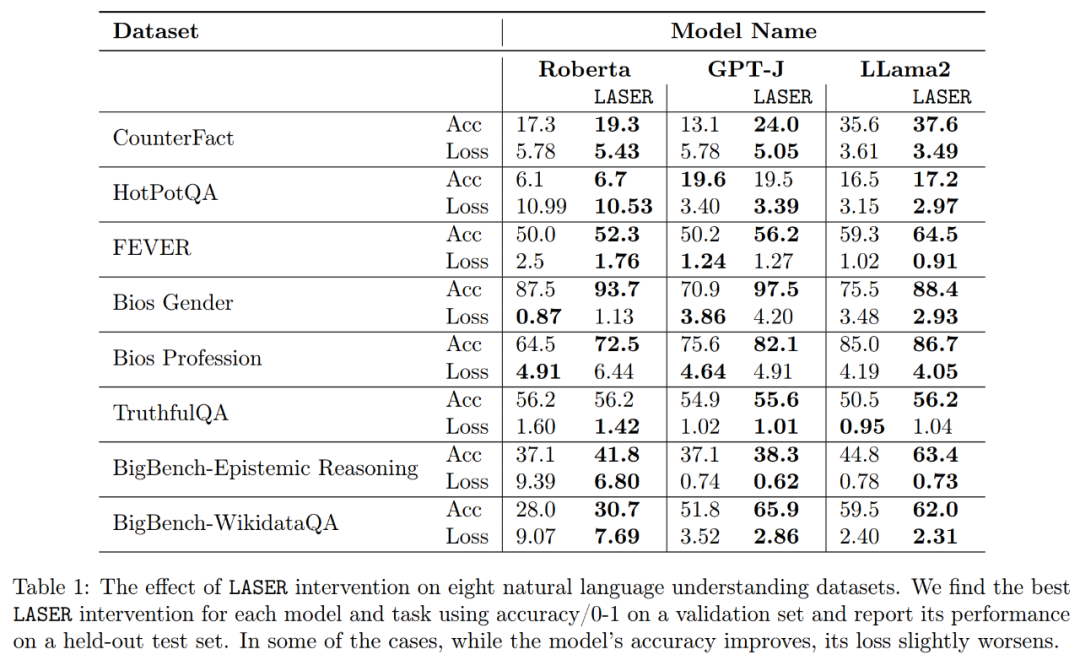
En ce qui concerne l'amélioration de la précision et de la robustesse de l'interprétation, comme le montrent la figure 2 ci-dessus et le tableau 1 ci-dessous, les chercheurs ont constaté que lors de la réduction de rang sur une seule couche, le fait que le modèle GPT-J fonctionnait bien sur la Ensemble de données CounterFact La précision est passée de 13,1 % à 24,0 %. Il est important de noter que ces améliorations sont uniquement le résultat d’une réduction de rang et n’impliquent aucune formation supplémentaire ni ajustement du modèle.
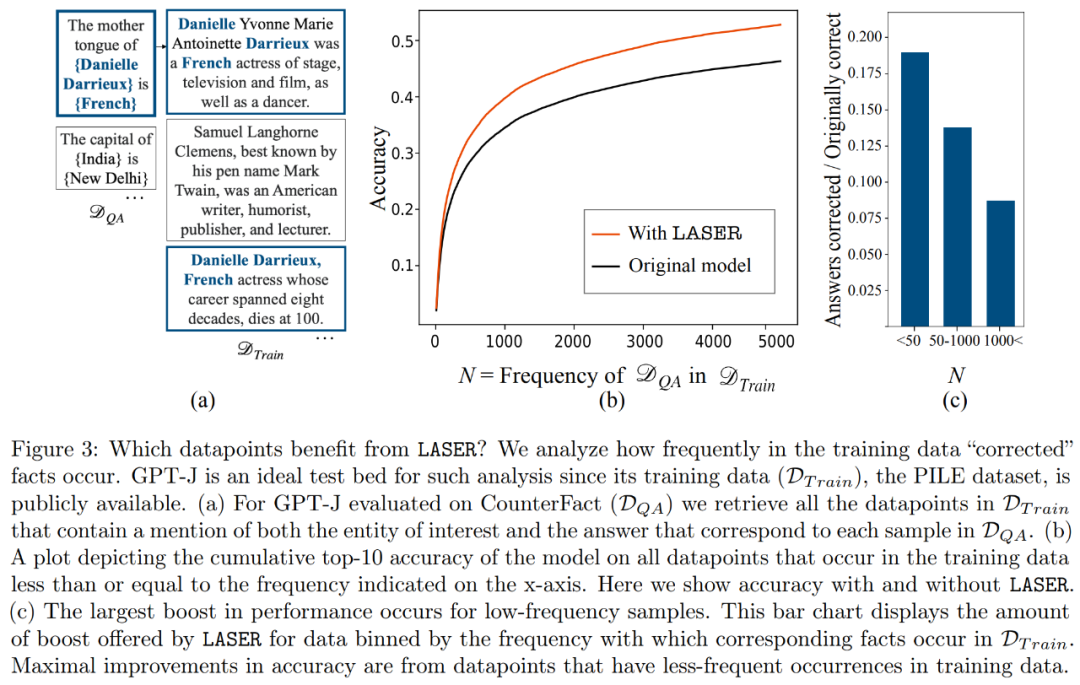
Les faits qui seront restaurés dans l'ensemble de données grâce à une réduction de classement sont devenus une préoccupation pour les chercheurs. Les chercheurs ont découvert que le fait de récupération par réduction de rang apparaissait rarement dans les données, comme le montre la figure 3
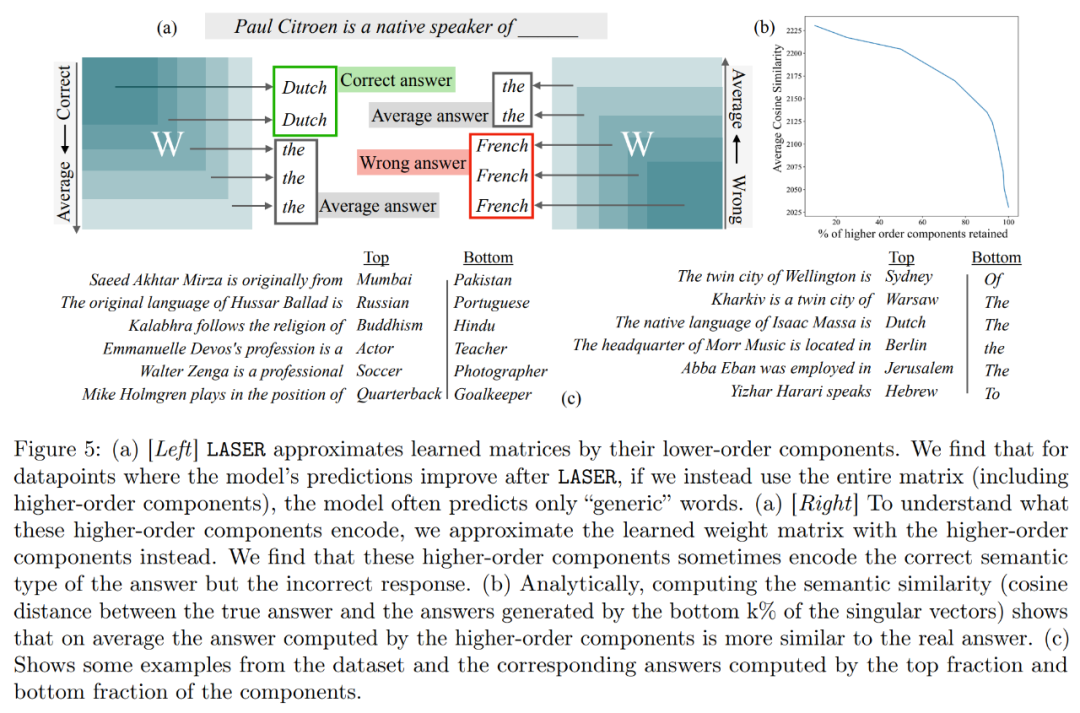
Que stockent les composants d'ordre supérieur ? Les chercheurs utilisent des composants d'ordre élevé pour approximer la matrice de poids finale, contrairement à LASER, ils n'utilisent pas de composants d'ordre inférieur pour l'approximation, comme le montre la figure 5 (a). Lors de l'approximation de la matrice en utilisant différents nombres de composants d'ordre supérieur, ils ont mesuré la similarité moyenne en cosinus entre les réponses vraies et prédites, comme le montre la figure 5(b)
Enfin, les chercheurs ont évalué leurs résultats. LLM sur plusieurs tâches de compréhension linguistique. Pour chaque tâche, ils ont évalué les performances du modèle en générant trois mesures : précision, précision de classification et perte. Comme le montre le tableau 1 ci-dessus, même si la réduction du classement est importante, elle n'entraînera pas une diminution de la précision du modèle, mais elle peut améliorer les performances du modèle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
Il s'agit également d'une vidéo Tusheng, mais PaintsUndo a emprunté une voie différente. L'auteur de ControlNet, LvminZhang, a recommencé à vivre ! Cette fois, je vise le domaine de la peinture. Le nouveau projet PaintsUndo a reçu 1,4kstar (toujours en hausse folle) peu de temps après son lancement. Adresse du projet : https://github.com/lllyasviel/Paints-UNDO Grâce à ce projet, l'utilisateur saisit une image statique et PaintsUndo peut automatiquement vous aider à générer une vidéo de l'ensemble du processus de peinture, du brouillon de ligne au suivi du produit fini. . Pendant le processus de dessin, les changements de lignes sont étonnants. Le résultat vidéo final est très similaire à l’image originale : jetons un coup d’œil à un dessin complet.
 En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Les auteurs de cet article font tous partie de l'équipe de l'enseignant Zhang Lingming de l'Université de l'Illinois à Urbana-Champaign (UIUC), notamment : Steven Code repair ; doctorant en quatrième année, chercheur
 Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Dans le processus de développement de l'intelligence artificielle, le contrôle et le guidage des grands modèles de langage (LLM) ont toujours été l'un des principaux défis, visant à garantir que ces modèles sont à la fois puissant et sûr au service de la société humaine. Les premiers efforts se sont concentrés sur les méthodes d’apprentissage par renforcement par feedback humain (RL
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
acclamations! Qu’est-ce que ça fait lorsqu’une discussion sur papier se résume à des mots ? Récemment, des étudiants de l'Université de Stanford ont créé alphaXiv, un forum de discussion ouvert pour les articles arXiv qui permet de publier des questions et des commentaires directement sur n'importe quel article arXiv. Lien du site Web : https://alphaxiv.org/ En fait, il n'est pas nécessaire de visiter spécifiquement ce site Web. Il suffit de remplacer arXiv dans n'importe quelle URL par alphaXiv pour ouvrir directement l'article correspondant sur le forum alphaXiv : vous pouvez localiser avec précision les paragraphes dans. l'article, Phrase : dans la zone de discussion sur la droite, les utilisateurs peuvent poser des questions à l'auteur sur les idées et les détails de l'article. Par exemple, ils peuvent également commenter le contenu de l'article, tels que : "Donné à".
 La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
Montrez la chaîne causale à LLM et il pourra apprendre les axiomes. L'IA aide déjà les mathématiciens et les scientifiques à mener des recherches. Par exemple, le célèbre mathématicien Terence Tao a partagé à plusieurs reprises son expérience de recherche et d'exploration à l'aide d'outils d'IA tels que GPT. Pour que l’IA soit compétitive dans ces domaines, des capacités de raisonnement causal solides et fiables sont essentielles. La recherche présentée dans cet article a révélé qu'un modèle Transformer formé sur la démonstration de l'axiome de transitivité causale sur de petits graphes peut se généraliser à l'axiome de transitivité sur de grands graphes. En d’autres termes, si le Transformateur apprend à effectuer un raisonnement causal simple, il peut être utilisé pour un raisonnement causal plus complexe. Le cadre de formation axiomatique proposé par l'équipe est un nouveau paradigme pour l'apprentissage du raisonnement causal basé sur des données passives, avec uniquement des démonstrations.
 Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Récemment, l’hypothèse de Riemann, connue comme l’un des sept problèmes majeurs du millénaire, a réalisé une nouvelle avancée. L'hypothèse de Riemann est un problème mathématique non résolu très important, lié aux propriétés précises de la distribution des nombres premiers (les nombres premiers sont les nombres qui ne sont divisibles que par 1 et par eux-mêmes, et jouent un rôle fondamental dans la théorie des nombres). Dans la littérature mathématique actuelle, il existe plus d'un millier de propositions mathématiques basées sur l'établissement de l'hypothèse de Riemann (ou sa forme généralisée). En d’autres termes, une fois que l’hypothèse de Riemann et sa forme généralisée seront prouvées, ces plus d’un millier de propositions seront établies sous forme de théorèmes, qui auront un impact profond sur le domaine des mathématiques et si l’hypothèse de Riemann s’avère fausse, alors parmi eux ; ces propositions qui en font partie perdront également de leur efficacité. Une nouvelle percée vient du professeur de mathématiques du MIT, Larry Guth, et de l'Université d'Oxford
 Le premier MLLM basé sur Mamba est là ! Les poids des modèles, le code de formation, etc. sont tous open source
Jul 17, 2024 am 02:46 AM
Le premier MLLM basé sur Mamba est là ! Les poids des modèles, le code de formation, etc. sont tous open source
Jul 17, 2024 am 02:46 AM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com. Introduction Ces dernières années, l'application de grands modèles de langage multimodaux (MLLM) dans divers domaines a connu un succès remarquable. Cependant, en tant que modèle de base pour de nombreuses tâches en aval, le MLLM actuel se compose du célèbre réseau Transformer, qui
