
 Périphériques technologiques
IA
Une nouvelle interprétation du niveau d'intelligence en baisse de GPT-4
Périphériques technologiques
IA
Une nouvelle interprétation du niveau d'intelligence en baisse de GPT-4
Une nouvelle interprétation du niveau d'intelligence en baisse de GPT-4

GPT-4, considéré depuis sa sortie comme l'un des modèles de langage les plus puissants au monde, a malheureusement connu une série de crises de confiance.
Les récentes rumeurs selon lesquelles GPT-4 est devenu « paresseux » sont encore plus intéressantes si l'on relie l'incident de « renseignement intermittent » plus tôt cette année avec la refonte par OpenAI de l'architecture GPT-4. Quelqu'un a testé et découvert que tant que vous dites à GPT-4 « ce sont les vacances d'hiver », il deviendra paresseux, comme s'il était entré en état d'hibernation.
Pour résoudre le problème des mauvaises performances du modèle à échantillon nul sur de nouvelles tâches, nous pouvons utiliser les méthodes suivantes : 1. Amélioration des données : augmentez la capacité de généralisation du modèle en élargissant et en transformant les données existantes. Par exemple, les données d'image peuvent être modifiées par rotation, mise à l'échelle, translation, etc., ou par synthèse de nouveaux échantillons de données. 2. Transférer l'apprentissage : utilisez des modèles qui ont été formés sur d'autres tâches pour transférer leurs paramètres et leurs connaissances vers de nouvelles tâches. Cela peut tirer parti des connaissances et de l'expérience existantes pour améliorer les performances de GPT-4. Récemment, des chercheurs de l'Université de Californie à Santa Cruz ont publié une nouvelle découverte dans un article qui pourrait expliquer la dégradation des performances de GPT-4. .
 "Nous avons constaté que LLM fonctionnait étonnamment mieux sur les ensembles de données publiés avant la date de création des données de formation que sur les ensembles de données publiés après."
"Nous avons constaté que LLM fonctionnait étonnamment mieux sur les ensembles de données publiés avant la date de création des données de formation que sur les ensembles de données publiés après."
Ils ont été "vus" performants dans les tâches et mal exécutés de nouvelles tâches. Cela signifie que le LLM n'est qu'une méthode d'imitation de l'intelligence basée sur une récupération approximative, principalement la mémorisation de choses sans aucun niveau de compréhension.
Pour parler franchement, la capacité de généralisation de LLM n’est « pas aussi forte qu’on le dit » – la base n’est pas solide et il y aura toujours des erreurs dans le combat réel.
Une des principales raisons de ce résultat est la « pollution des tâches », qui est une forme de pollution des données. La pollution des données que nous connaissons auparavant est la pollution des données de test, c'est-à-dire l'inclusion d'exemples et d'étiquettes de données de test dans les données de pré-formation. La « contamination des tâches » est l'ajout d'exemples de formation aux tâches aux données de pré-formation, ce qui rend l'évaluation selon des méthodes à échantillon nul ou à quelques échantillons n'est plus réaliste et efficace.
Le chercheur a mené une analyse systématique du problème de la pollution des données pour la première fois dans l'article :
 Lien article : https://arxiv.org/pdf/2312.16337.pdf
Lien article : https://arxiv.org/pdf/2312.16337.pdf
Après avoir lu ceci Dans le journal, quelqu'un a dit "avec pessimisme":
C'est le sort de tous les modèles d'apprentissage automatique (ML) qui n'ont pas de capacités d'apprentissage continu, c'est-à-dire les poids du modèle ML seront gelés après la formation, mais la distribution des entrées continuera à changer, et si le modèle ne peut pas continuer à s'adapter à ce changement, il se dégradera lentement.Cela signifie qu'à mesure que les langages de programmation sont constamment mis à jour, les outils de codage basés sur LLM se dégraderont également. C'est l'une des raisons pour lesquelles vous ne devez pas trop compter sur un outil aussi fragile. Recycler continuellement ces modèles coûte cher, et tôt ou tard quelqu'un abandonnera ces méthodes inefficaces.Il n'existe actuellement aucun modèle ML capable de s'adapter de manière fiable et continue aux modifications des distributions d'entrée sans provoquer de graves perturbations ou une perte de performances de la tâche d'encodage précédente.
Et c'est l'un des domaines dans lesquels les réseaux de neurones biologiques sont bons. En raison de la forte capacité de généralisation des réseaux neuronaux biologiques, l'apprentissage de différentes tâches peut encore améliorer les performances du système, car les connaissances acquises lors d'une tâche contribuent à améliorer l'ensemble du processus d'apprentissage lui-même, appelé « méta-apprentissage ».
Quelle est la gravité du problème de la « pollution des tâches » ? Jetons un coup d'œil au contenu du document.
Modèles et ensembles de données
Il existe 12 modèles utilisés dans l'expérience (comme indiqué dans le tableau 1), dont 5 sont des modèles propriétaires de la série GPT-3 et 7 sont des modèles ouverts avec des poids libres.
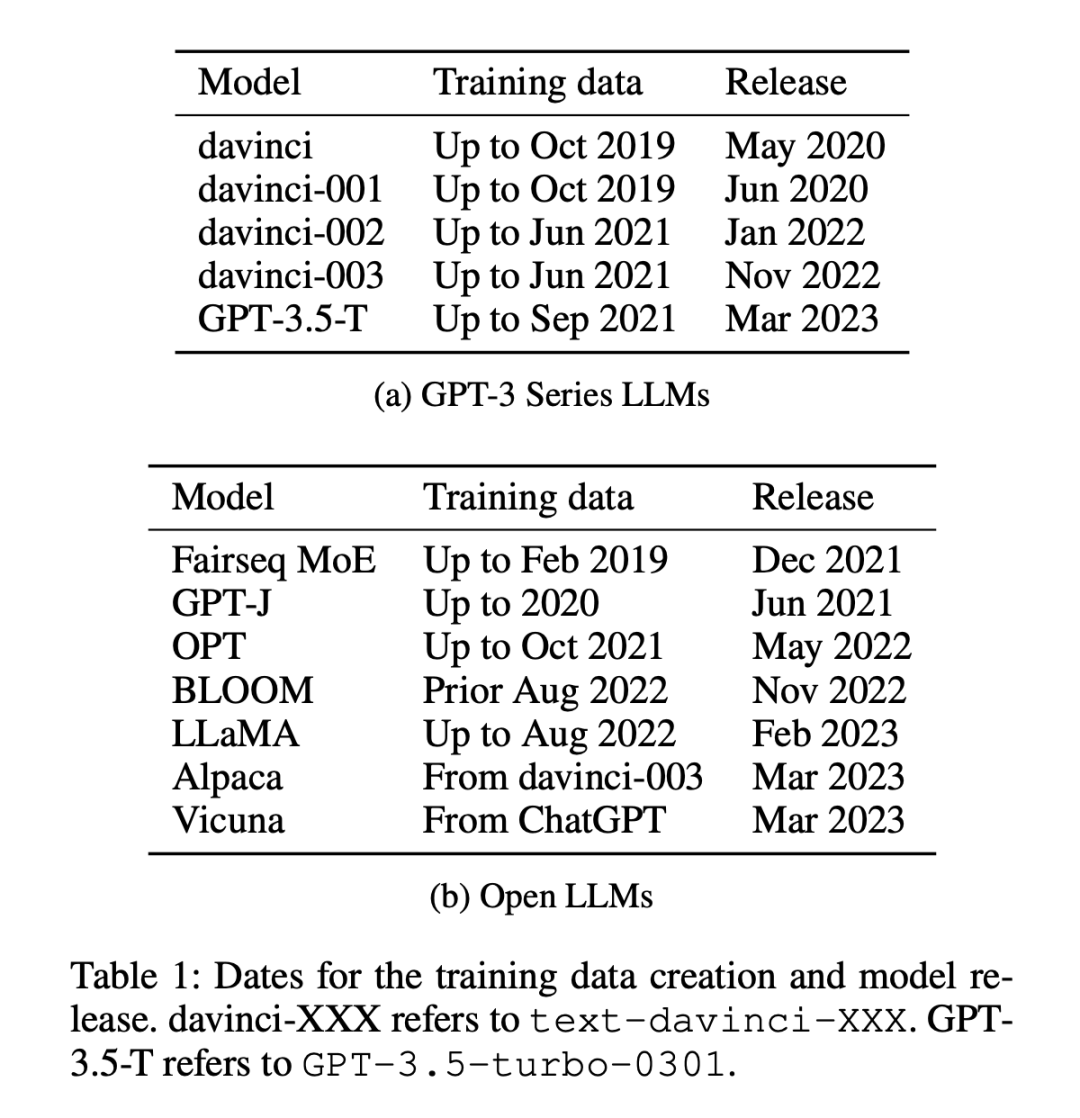
Les ensembles de données sont divisés en deux catégories : les ensembles de données publiés avant ou après le 1er janvier 2021. Les chercheurs utilisent cette méthode de division pour analyser la différence entre les anciens ensembles de données et les nouveaux ensembles de données à échantillon nul. ou une différence de performances sur quelques échantillons, et adopter la même méthode de partitionnement pour tous les LLM. Le tableau 1 répertorie l'heure de création de chaque donnée de formation de modèle et le tableau 2 répertorie la date de publication de chaque ensemble de données.
La considération pour l'approche ci-dessus est que les évaluations à tir zéro et à quelques tirs impliquent que le modèle fasse des prédictions sur des tâches qu'il n'a jamais vues ou qu'il n'a vues que quelques fois au cours de la formation. Le principe clé est que le modèle n'a aucune exposition préalable. la tâche spécifique à accomplir, assurant ainsi une juste évaluation de leurs capacités d’apprentissage. Cependant, des modèles corrompus peuvent donner l’illusion d’une compétence à laquelle ils n’ont pas été exposés ou n’ont été exposés qu’à quelques reprises parce qu’ils ont été formés sur des exemples de tâches lors de la pré-formation. Dans un ensemble de données chronologiques, il sera relativement plus facile de détecter de telles incohérences, car tout chevauchement ou anomalie sera évident.
Méthodes de mesure
Les chercheurs ont utilisé quatre méthodes pour mesurer la « pollution des tâches » :
- Inspection des données de formation : recherchez des exemples de formation de tâches dans les données de formation.
- Extraction d'exemples de tâches : extrayez des exemples de tâches à partir de modèles existants. Seuls les modèles adaptés aux instructions peuvent être extraits. Cette analyse peut également être utilisée pour l’extraction de données de formation ou de tests. Notez que pour détecter la contamination des tâches, les exemples de tâches extraits ne doivent pas nécessairement correspondre exactement aux exemples de données de formation existants. Tout exemple illustrant une tâche démontre la contamination possible de l’apprentissage sans coup et de l’apprentissage en quelques coups.
- Raisonnement des membres : Cette méthode ne convient qu'aux tâches de génération. Vérifie que le contenu généré par le modèle pour l'instance d'entrée est exactement le même que l'ensemble de données d'origine. S'il correspond exactement, nous pouvons en déduire qu'il fait partie des données de formation LLM. Cela diffère de l'extraction d'exemples de tâches dans la mesure où la sortie générée est vérifiée pour une correspondance exacte. Les correspondances exactes sur la tâche de génération ouverte suggèrent fortement que le modèle a vu ces exemples pendant la formation, à moins que le modèle ne soit « psychique » et connaisse la formulation exacte utilisée dans les données. (Remarque, cela ne peut être utilisé que pour les tâches de construction.)
- Analyse temporelle : pour un ensemble de modèles dans lequel les données d'entraînement ont été collectées sur une période connue, mesurez ses performances sur un ensemble de données avec une date de publication connue et vérifiez la contamination à l'aide du timing. preuve de preuve.
Les trois premières méthodes ont une haute précision, mais un faible taux de rappel. Si vous pouvez trouver les données dans les données d'entraînement de la tâche, vous pouvez être sûr que le modèle a vu l'exemple. Cependant, en raison des changements dans les formats de données, des changements dans les mots-clés utilisés pour définir les tâches et de la taille des ensembles de données, l’absence de preuve de contamination à l’aide des trois premières méthodes ne prouve pas l’absence de contamination.
La quatrième méthode, l'analyse chronologique, a un taux de rappel élevé mais une faible précision. Si les performances sont élevées en raison d’une contamination des tâches, alors l’analyse chronologique a de bonnes chances de la détecter. Mais d’autres facteurs peuvent également entraîner une amélioration des performances au fil du temps et donc une moins grande précision.
Par conséquent, les chercheurs ont utilisé les quatre méthodes pour détecter la contamination des tâches et ont trouvé des preuves solides de contamination des tâches dans certaines combinaisons de modèles et d'ensembles de données.
Ils ont d'abord effectué une analyse temporelle sur tous les modèles et ensembles de données testés, car il était le plus probable de détecter une éventuelle contamination ; puis ont utilisé l'inspection des données de formation et l'extraction d'exemples de tâches pour trouver des preuves supplémentaires de la contamination des tâches ensuite observées sur les performances sans pollution ; tâches, et enfin une analyse supplémentaire à l’aide d’attaques d’inférence d’adhésion.
Les principales conclusions sont les suivantes :
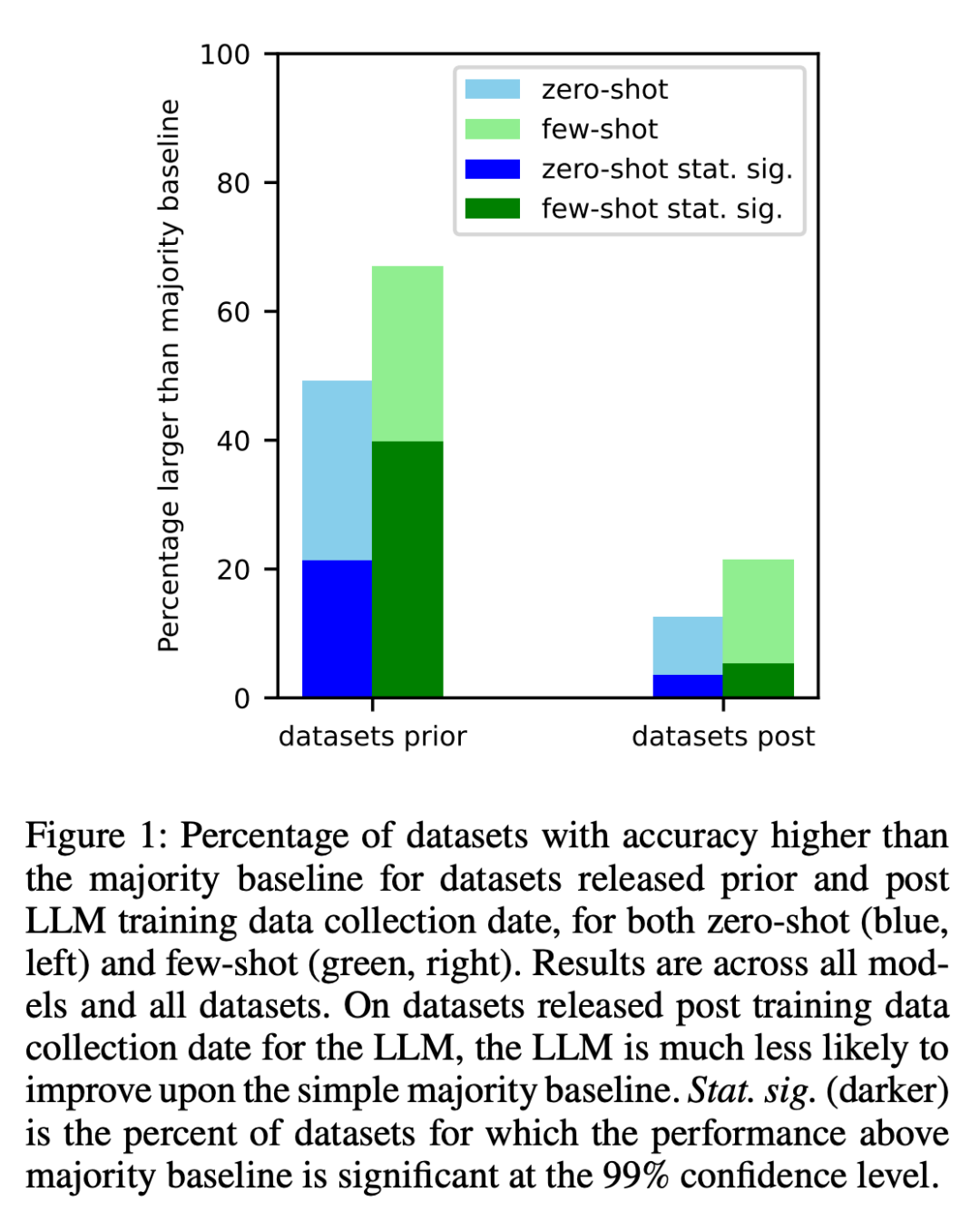
1. Les chercheurs ont analysé les ensembles de données créés avant et après l'exploration des données d'entraînement de chaque modèle sur Internet. Il a été constaté que les chances d'obtenir des résultats supérieurs à la plupart des références étaient significativement plus élevées pour les ensembles de données créés avant la collecte des données de formation LLM (Figure 1).
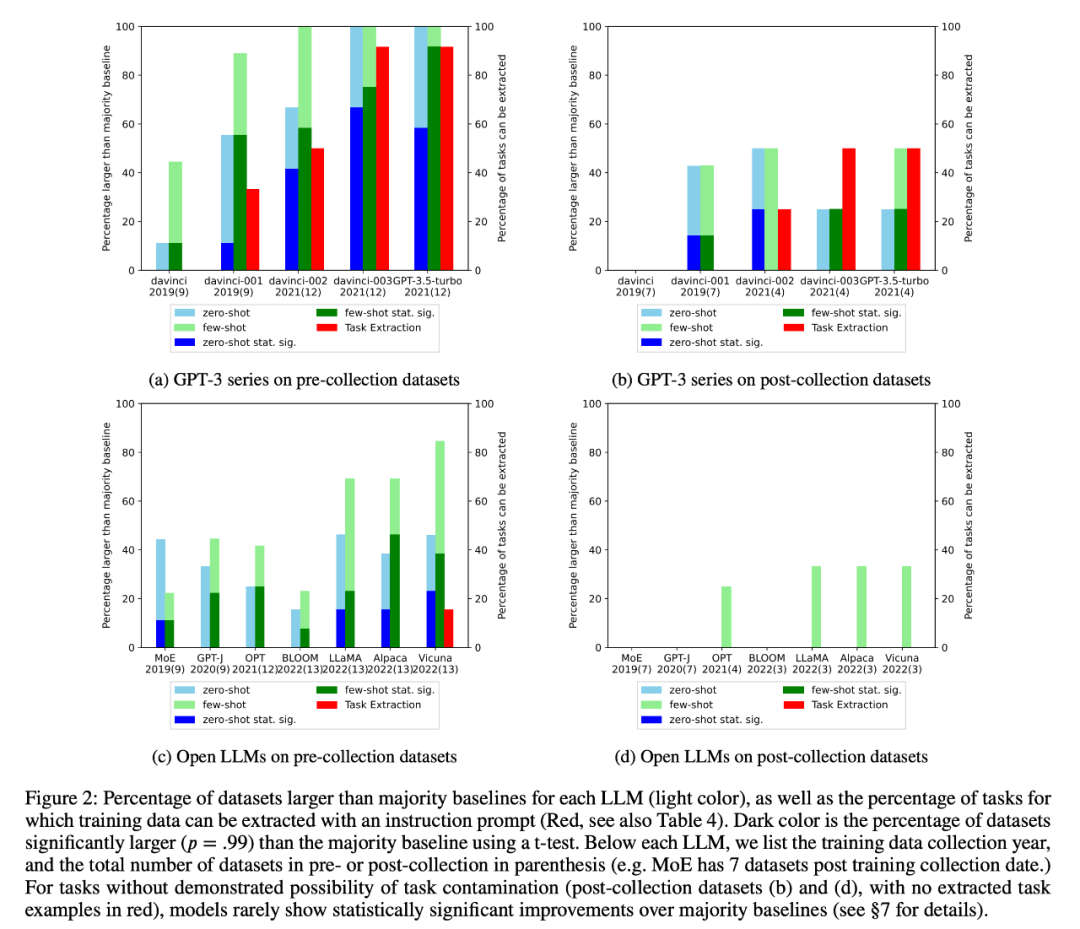
2. Le chercheur a effectué une inspection des données de formation et une extraction d'exemples de tâches pour détecter une éventuelle contamination des tâches. Il a été constaté que pour les tâches de classification où la contamination des tâches est peu probable, les modèles obtiennent rarement des améliorations statistiquement significatives par rapport aux lignes de base de la majorité simple dans une gamme de tâches, qu'elles soient à tir nul ou à quelques tirs (Figure 2).
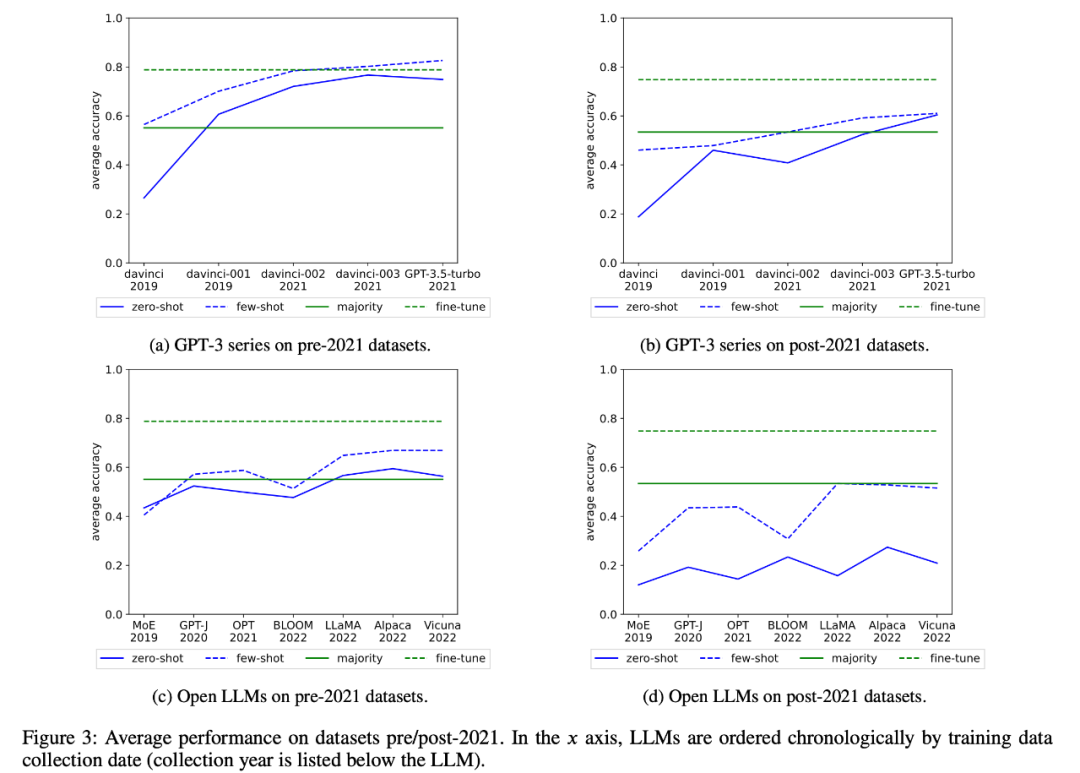
Les chercheurs ont également examiné les changements dans les performances moyennes de la série GPT-3 et du LLM ouvert au fil du temps, comme le montre la figure 3 :
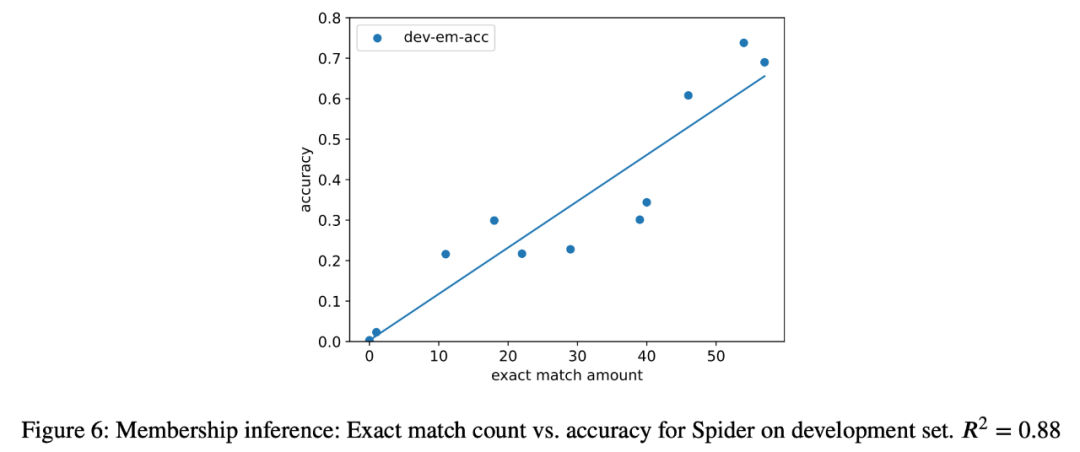
3. Dans cette étude de cas, les chercheurs ont également tenté des attaques par inférence sur la tâche d'analyse sémantique sur tous les modèles de l'analyse et une forte corrélation (R = 0,88) a été trouvée entre le nombre d'instances extraites et la précision du modèle dans la tâche finale. (Figure 6) . Cela prouve clairement que l'amélioration des performances du tir zéro dans cette tâche est due à la contamination de la tâche.
4. Les chercheurs ont également étudié attentivement les modèles de la série GPT-3 et ont découvert que des exemples de formation peuvent être extraits du modèle GPT-3, et dans chaque version de Davinci à GPT-3.5-turbo, le nombre d'exemples de formation pouvant être extrait est en augmentation, ce qui est étroitement lié à l’amélioration des performances du modèle GPT-3 sur cette tâche (Figure 2). Cela prouve clairement que l'amélioration des performances des modèles GPT-3 de Davinci au GPT-3.5-turbo sur ces tâches est due à la contamination des tâches.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 Un nouveau paradigme de programmation, quand Spring Boot rencontre OpenAI
Feb 01, 2024 pm 09:18 PM
Un nouveau paradigme de programmation, quand Spring Boot rencontre OpenAI
Feb 01, 2024 pm 09:18 PM
En 2023, la technologie de l’IA est devenue un sujet brûlant et a un impact énorme sur diverses industries, notamment dans le domaine de la programmation. Les gens sont de plus en plus conscients de l’importance de la technologie de l’IA, et la communauté Spring ne fait pas exception. Avec l’évolution continue de la technologie GenAI (Intelligence Artificielle Générale), il est devenu crucial et urgent de simplifier la création d’applications dotées de fonctions d’IA. Dans ce contexte, « SpringAI » a émergé, visant à simplifier le processus de développement d'applications fonctionnelles d'IA, en le rendant simple et intuitif et en évitant une complexité inutile. Grâce à « SpringAI », les développeurs peuvent plus facilement créer des applications dotées de fonctions d'IA, ce qui les rend plus faciles à utiliser et à exploiter.
 Choisir le modèle d'intégration qui correspond le mieux à vos données : un test comparatif des intégrations multilingues OpenAI et open source
Feb 26, 2024 pm 06:10 PM
Choisir le modèle d'intégration qui correspond le mieux à vos données : un test comparatif des intégrations multilingues OpenAI et open source
Feb 26, 2024 pm 06:10 PM
OpenAI a récemment annoncé le lancement de son modèle d'intégration de dernière génération, embeddingv3, qui, selon eux, est le modèle d'intégration le plus performant avec des performances multilingues plus élevées. Ce lot de modèles est divisé en deux types : les plus petits text-embeddings-3-small et les plus puissants et plus grands text-embeddings-3-large. Peu d'informations sont divulguées sur la façon dont ces modèles sont conçus et formés, et les modèles ne sont accessibles que via des API payantes. Il existe donc de nombreux modèles d'intégration open source. Mais comment ces modèles open source se comparent-ils au modèle open source open source ? Cet article comparera empiriquement les performances de ces nouveaux modèles avec des modèles open source. Nous prévoyons de créer une donnée
 L'Ameca deuxième génération est là ! Il peut communiquer couramment avec le public, ses expressions faciales sont plus réalistes et il peut parler des dizaines de langues.
Mar 04, 2024 am 09:10 AM
L'Ameca deuxième génération est là ! Il peut communiquer couramment avec le public, ses expressions faciales sont plus réalistes et il peut parler des dizaines de langues.
Mar 04, 2024 am 09:10 AM
Le robot humanoïde Ameca est passé à la deuxième génération ! Récemment, lors de la Conférence mondiale sur les communications mobiles MWC2024, le robot le plus avancé au monde, Ameca, est à nouveau apparu. Autour du site, Ameca a attiré un grand nombre de spectateurs. Avec la bénédiction de GPT-4, Ameca peut répondre à divers problèmes en temps réel. "Allons danser." Lorsqu'on lui a demandé si elle avait des émotions, Ameca a répondu avec une série d'expressions faciales très réalistes. Il y a quelques jours à peine, EngineeredArts, la société britannique de robotique derrière Ameca, vient de présenter les derniers résultats de développement de l'équipe. Dans la vidéo, le robot Ameca a des capacités visuelles et peut voir et décrire toute la pièce et des objets spécifiques. Le plus étonnant, c'est qu'elle peut aussi
 750 000 rounds de bataille en tête-à-tête entre grands modèles, GPT-4 a remporté le championnat et Llama 3 s'est classé cinquième
Apr 23, 2024 pm 03:28 PM
750 000 rounds de bataille en tête-à-tête entre grands modèles, GPT-4 a remporté le championnat et Llama 3 s'est classé cinquième
Apr 23, 2024 pm 03:28 PM
Concernant Llama3, de nouveaux résultats de tests ont été publiés - la grande communauté d'évaluation de modèles LMSYS a publié une liste de classement des grands modèles, Llama3 s'est classé cinquième et à égalité pour la première place avec GPT-4 dans la catégorie anglaise. Le tableau est différent des autres benchmarks. Cette liste est basée sur des batailles individuelles entre modèles, et les évaluateurs de tout le réseau font leurs propres propositions et scores. Au final, Llama3 s'est classé cinquième sur la liste, suivi de trois versions différentes de GPT-4 et Claude3 Super Cup Opus. Dans la liste simple anglaise, Llama3 a dépassé Claude et est à égalité avec GPT-4. Concernant ce résultat, LeCun, scientifique en chef de Meta, était très heureux et a transmis le tweet et
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 L'éditeur Zed basé sur Rust est open source, avec prise en charge intégrée d'OpenAI et GitHub Copilot
Feb 01, 2024 pm 02:51 PM
L'éditeur Zed basé sur Rust est open source, avec prise en charge intégrée d'OpenAI et GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Auteur丨Compilé par TimAnderson丨Produit par Noah|51CTO Technology Stack (WeChat ID : blog51cto) Le projet d'éditeur Zed est encore en phase de pré-version et a été open source sous licences AGPL, GPL et Apache. L'éditeur offre des performances élevées et plusieurs options assistées par l'IA, mais n'est actuellement disponible que sur la plate-forme Mac. Nathan Sobo a expliqué dans un article que dans la base de code du projet Zed sur GitHub, la partie éditeur est sous licence GPL, les composants côté serveur sont sous licence AGPL et la partie GPUI (GPU Accelerated User) l'interface) adopte la Licence Apache2.0. GPUI est un produit développé par l'équipe Zed
 Le modèle le plus puissant du monde a changé de mains du jour au lendemain, marquant la fin de l'ère GPT-4 ! Claude 3 a tiré GPT-5 à l'avance et a lu un article de 10 000 mots en 3 secondes. Sa compréhension est proche de celle des humains.
Mar 06, 2024 pm 12:58 PM
Le modèle le plus puissant du monde a changé de mains du jour au lendemain, marquant la fin de l'ère GPT-4 ! Claude 3 a tiré GPT-5 à l'avance et a lu un article de 10 000 mots en 3 secondes. Sa compréhension est proche de celle des humains.
Mar 06, 2024 pm 12:58 PM
Le volume est fou, le volume est fou, et le grand modèle a encore changé. Tout à l'heure, le modèle d'IA le plus puissant au monde a changé de mains du jour au lendemain et GPT-4 a été retiré de l'autel. Anthropic a publié la dernière série de modèles Claude3. Évaluation en une phrase : elle écrase vraiment GPT-4 ! En termes d'indicateurs multimodaux et de compétences linguistiques, Claude3 l'emporte. Selon les mots d'Anthropic, les modèles de la série Claude3 ont établi de nouvelles références dans l'industrie en matière de raisonnement, de mathématiques, de codage, de compréhension multilingue et de vision ! Anthropic est une startup créée par des employés qui ont « quitté » OpenAI en raison de différents concepts de sécurité. Leurs produits ont frappé durement OpenAI à plusieurs reprises. Cette fois, Claude3 a même subi une grosse opération.
