
 Périphériques technologiques
IA
Utiliser des graphiques de connaissances pour améliorer les capacités des modèles RAG et atténuer les fausses impressions des grands modèles
Périphériques technologiques
IA
Utiliser des graphiques de connaissances pour améliorer les capacités des modèles RAG et atténuer les fausses impressions des grands modèles
Utiliser des graphiques de connaissances pour améliorer les capacités des modèles RAG et atténuer les fausses impressions des grands modèles

L'illusion est un problème courant lors de l'utilisation de grands modèles de langage (LLM). Bien que LLM puisse générer un texte fluide et cohérent, les informations qu'il génère sont souvent inexactes ou incohérentes. Afin d'éviter les hallucinations du LLM, des sources de connaissances externes, telles que des bases de données ou des graphiques de connaissances, peuvent être utilisées pour fournir des informations factuelles. De cette manière, LLM peut s’appuyer sur ces sources de données fiables, ce qui permet d’obtenir un contenu textuel plus précis et plus fiable.
Base de données vectorielles et Knowledge Graph
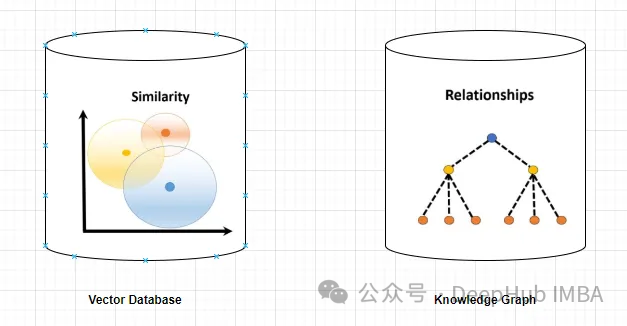
Base de données vectorielles
Une base de données vectorielles est un ensemble de vecteurs de grande dimension qui représentent des entités ou des concepts. Ils peuvent être utilisés pour mesurer la similarité ou la corrélation entre différentes entités ou concepts, calculées à travers leurs représentations vectorielles.
Une base de données vectorielles peut vous dire, sur la base de la distance vectorielle, que « Paris » et « France » sont plus liés que « Paris » et « Allemagne ».
L'interrogation d'une base de données de vecteurs implique généralement la recherche de vecteurs similaires ou la récupération de vecteurs en fonction de critères spécifiques. Ce qui suit est un exemple simple d’interrogation d’une base de données vectorielles.
Supposons qu'il existe une base de données vectorielles de grande dimension qui stocke les profils des clients. Vous souhaitez rechercher des clients similaires à un client de référence donné.
Tout d'abord, afin de définir un client sous forme de représentation vectorielle, nous pouvons extraire des caractéristiques ou des attributs pertinents et les convertir sous forme vectorielle.
Une recherche de similarité peut être effectuée dans une base de données vectorielles en utilisant un algorithme approprié tel que le k-voisin le plus proche ou la similarité cosinus pour identifier les voisins les plus similaires.
Récupérez les profils clients correspondant aux vecteurs voisins les plus proches déterminés qui représentent les clients similaires au client de référence, selon la mesure de similarité définie.
Affichez à l'utilisateur le profil client récupéré ou des informations associées telles que le nom, les données démographiques ou l'historique des achats.
Graphique de connaissances
Un graphe de connaissances est une collection de nœuds et d'arêtes qui représentent des entités ou des concepts et leurs relations (telles que des faits, des attributs ou des catégories). En fonction de leurs attributs de nœud et de bord, ils peuvent être utilisés pour interroger ou déduire des informations factuelles sur différentes entités ou concepts.
Par exemple, un knowledge graph peut vous indiquer que « Paris » est la capitale de la « France » sur la base des étiquettes de bord.
Interroger une base de données graphique implique de parcourir la structure du graphique et de récupérer des nœuds, des relations ou des modèles en fonction de critères spécifiques.
Supposons que vous disposiez d'une base de données graphique représentant un réseau social, où les utilisateurs sont des nœuds et leurs relations sont représentées sous forme de bords reliant les nœuds. Si des amis d'amis (connexions communes) sont trouvés pour un utilisateur donné, alors nous devons procéder comme suit :
1. Identifiez le nœud représentant l'utilisateur de référence dans la base de données graphique. Cela peut être accompli en recherchant un identifiant d'utilisateur spécifique ou d'autres critères pertinents.
2. Utilisez un langage de requête graphique, tel que Cypher (utilisé dans Neo4j) ou Gremlin, pour parcourir le graphique à partir d'un nœud utilisateur de référence. Spécifiez les modèles ou les relations à explorer.
MATCH (:User {userId: ‘referenceUser’})-[:FRIEND]->()-[:FRIEND]->(fof:User) RETURN fofCette requête commence par l'utilisateur de référence, suit la relation FRIEND pour trouver un autre nœud (FRIEND), puis suit une autre relation FRIEND pour trouver les amis d'amis (fof).
3. Exécutez une requête sur la base de données graphique, récupérez les nœuds de résultat (amis des amis) selon le mode de requête et obtenez des attributs spécifiques ou d'autres informations sur les nœuds récupérés.
Les bases de données graphiques peuvent fournir des fonctions de requête plus avancées, notamment le filtrage, l'agrégation et la correspondance de modèles complexes. Le langage et la syntaxe de requête spécifiques peuvent varier, mais le processus général implique de parcourir la structure du graphe pour récupérer les nœuds et les relations qui répondent aux critères requis.
Avantages des graphiques de connaissances pour résoudre le problème de « l'illusion »
Les graphiques de connaissances fournissent des informations plus précises et spécifiques que les bases de données vectorielles. Une base de données vectorielle représente la similarité ou la corrélation entre deux entités ou concepts, tandis qu'un graphe de connaissances permet de mieux comprendre la relation entre eux. Par exemple, le graphe de connaissances peut vous indiquer que la « Tour Eiffel » est l'emblème de « Paris », tandis que la base de données vectorielles ne peut que montrer la similitude des deux concepts, mais elle n'explique pas comment ils sont liés.
Le graphe de connaissances prend en charge des requêtes plus diverses et complexes que les bases de données vectorielles. Les bases de données vectorielles peuvent principalement répondre à des requêtes basées sur la distance vectorielle, la similarité ou le voisin le plus proche, qui se limitent à des mesures de similarité directe. Et le graphe de connaissances peut gérer des requêtes basées sur des opérateurs logiques, telles que « Quelles sont toutes les entités avec l'attribut Z ? » ou « Quelle est la catégorie commune de W et V ? » Cela peut aider LLM à générer des textes plus diversifiés et intéressants.
Les graphiques de connaissances sont meilleurs pour le raisonnement et l'inférence que les bases de données vectorielles. Les bases de données vectorielles ne peuvent fournir que des informations directes stockées dans la base de données. Les graphes de connaissances peuvent fournir des informations indirectes dérivées de relations entre des entités ou des concepts. Par exemple, un graphe de connaissances peut déduire « La Tour Eiffel est située en Europe » sur la base des deux faits « Paris est la capitale de la France » et « La France est située en Europe ». Cela peut aider LLM à générer un texte plus logique et cohérent.
Le graphe de connaissances est donc une meilleure solution que la base de données vectorielle. Cela fournit aux LLM des informations plus précises, pertinentes, diversifiées, intéressantes, logiques et cohérentes, ce qui les rend plus fiables dans la génération de textes précis et authentiques. Mais la clé ici est qu’il doit y avoir une relation claire entre les documents, sinon le graphe de connaissances ne pourra pas la capturer.
但是,知识图谱的使用并没有向量数据库那么直接简单,不仅在内容的梳理(数据),应用部署,查询生成等方面都没有向量数据库那么方便,这也影响了它在实际应用中的使用频率。所以下面我们使用一个简单的例子来介绍如何使用知识图谱构建RAG。
代码实现
我们需要使用3个主要工具/组件:
1、LlamaIndex是一个编排框架,它简化了私有数据与公共数据的集成,它提供了数据摄取、索引和查询的工具,使其成为生成式人工智能需求的通用解决方案。
2、嵌入模型将文本转换为文本所提供的一条信息的数字表示形式。这种表示捕获了所嵌入内容的语义含义,使其对于许多行业应用程序都很健壮。这里使用“thenlper/gte-large”模型。
3、需要大型语言模型来根据所提供的问题和上下文生成响应。这里使用Zephyr 7B beta模型
下面我们开始进行代码编写,首先安装包
%%capture pip install llama_index pyvis Ipython langchain pypdf
启用日志Logging Level设置为“INFO”,我们可以输出有助于监视应用程序操作流的消息
import logging import sys # logging.basicConfig(stream=sys.stdout, level=logging.INFO) logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
导入依赖项
from llama_index import (SimpleDirectoryReader,LLMPredictor,ServiceContext,KnowledgeGraphIndex) # from llama_index.graph_stores import SimpleGraphStore from llama_index.storage.storage_context import StorageContext from llama_index.llms import HuggingFaceInferenceAPI from langchain.embeddings import HuggingFaceInferenceAPIEmbeddings from llama_index.embeddings import LangchainEmbedding from pyvis.network import Network
我们使用Huggingface推理api端点载入LLM
HF_TOKEN = "api key DEEPHUB 123456" llm = HuggingFaceInferenceAPI(model_name="HuggingFaceH4/zephyr-7b-beta", token=HF_TOKEN )
首先载入嵌入模型:
embed_model = LangchainEmbedding(HuggingFaceInferenceAPIEmbeddings(api_key=HF_TOKEN,model_name="thenlper/gte-large") )
加载数据集
documents = SimpleDirectoryReader("/content/Documents").load_data() print(len(documents)) ####Output### 44构建知识图谱索引
创建知识图谱通常涉及专业和复杂的任务。通过利用Llama Index (LLM)、KnowledgeGraphIndex和GraphStore,可以方便地任何数据源创建一个相对有效的知识图谱。
#setup the service context service_context = ServiceContext.from_defaults(chunk_size=256,llm=llm,embed_model=embed_model ) #setup the storage context graph_store = SimpleGraphStore() storage_context = StorageContext.from_defaults(graph_store=graph_store) #Construct the Knowlege Graph Undex index = KnowledgeGraphIndex.from_documents( documents=documents,max_triplets_per_chunk=3,service_context=service_context,storage_context=storage_context,include_embeddings=True)
Max_triplets_per_chunk:它控制每个数据块处理的关系三元组的数量
Include_embeddings:切换在索引中包含嵌入以进行高级分析。
通过构建查询引擎对知识图谱进行查询
query = "What is ESOP?" query_engine = index.as_query_engine(include_text=True,response_mode ="tree_summarize",embedding_mode="hybrid",similarity_top_k=5,) # message_template =f"""Please check if the following pieces of context has any mention of the keywords provided in the Question.If not then don't know the answer, just say that you don't know.Stop there.Please donot try to make up an answer. Question: {query} Helpful Answer: """ # response = query_engine.query(message_template) # print(response.response.split("")[-1].strip()) #####OUTPUT ##################### ESOP stands for Employee Stock Ownership Plan. It is a retirement plan that allows employees to receive company stock or stock options as part of their compensation. In simpler terms, it is a plan that allows employees to own a portion of the company they work for. This can be a motivating factor for employees as they have a direct stake in the company's success. ESOPs can also be a tax-efficient way for companies to provide retirement benefits to their employees.可以看到,输出的结果已经很好了,可以说与向量数据库的结果非常一致。
最后还可以可视化我们生成的图谱,使用Pyvis库进行可视化展示
from pyvis.network import Network from IPython.display import display g = index.get_networkx_graph() net = Network(notebook=True,cdn_resources="in_line",directed=True) net.from_nx(g) net.show("graph.html") net.save_graph("Knowledge_graph.html") # import IPython IPython.display.HTML(filename="/content/Knowledge_graph.html")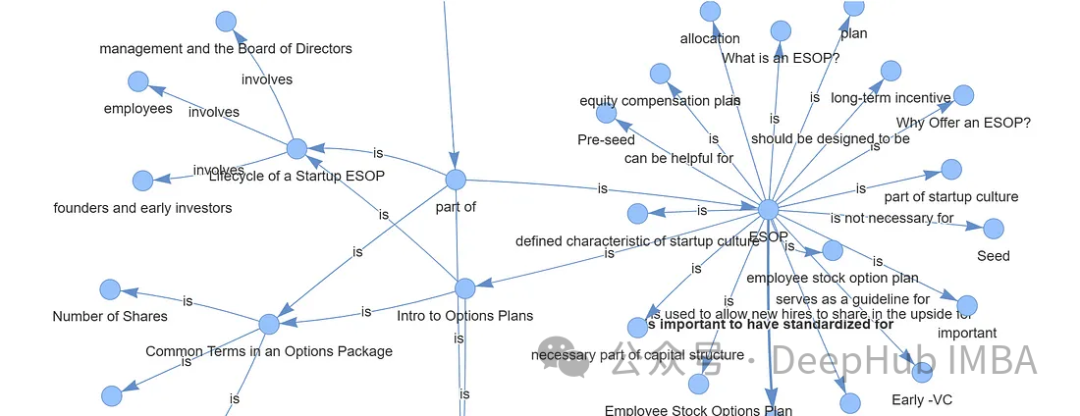

通过上面的代码我们可以直接通过LLM生成知识图谱,这样简化了我们非常多的人工操作。如果需要更精准更完整的知识图谱,还需要人工手动检查,这里就不细说了。
数据存储,通过持久化数据,可以将结果保存到硬盘中,供以后使用。
storage_context.persist()
存储的结果如下:

总结
向量数据库和知识图谱的区别在于它们存储和表示数据的方法。向量数据库擅长基于相似性的操作,依靠数值向量来测量实体之间的距离。知识图谱通过节点和边缘捕获复杂的关系和依赖关系,促进语义分析和高级推理。
对于语言模型(LLM)幻觉,知识图被证明优于向量数据库。知识图谱提供了更准确、多样、有趣、有逻辑性和一致性的信息,减少了LLM产生幻觉的可能性。这种优势源于它们能够提供实体之间关系的精确细节,而不仅仅是表明相似性,从而支持更复杂的查询和逻辑推理。
在以前知识图谱的应用难点在于图谱的构建,但是现在LLM的出现简化了这个过程,使得我们可以轻松的构建出可用的知识图谱,这使得他在应用方面又向前迈出了一大步。对于RAG,知识图谱是一个非常好的应用方向。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi les grands modèles linguistiques utilisent-ils SwiGLU comme fonction d'activation ?
Apr 08, 2024 pm 09:31 PM
Pourquoi les grands modèles linguistiques utilisent-ils SwiGLU comme fonction d'activation ?
Apr 08, 2024 pm 09:31 PM
Si vous avez prêté attention à l'architecture des grands modèles de langage, vous avez peut-être vu le terme « SwiGLU » dans les derniers modèles et documents de recherche. SwiGLU peut être considéré comme la fonction d'activation la plus couramment utilisée dans les grands modèles de langage. Nous la présenterons en détail dans cet article. SwiGLU est en fait une fonction d'activation proposée par Google en 2020, qui combine les caractéristiques de SWISH et de GLU. Le nom chinois complet de SwiGLU est « unité linéaire à porte bidirectionnelle ». Il optimise et combine deux fonctions d'activation, SWISH et GLU, pour améliorer la capacité d'expression non linéaire du modèle. SWISH est une fonction d'activation très courante et largement utilisée dans les grands modèles de langage, tandis que GLU a montré de bonnes performances dans les tâches de traitement du langage naturel.
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 GraphRAG amélioré pour la récupération de graphes de connaissances (implémenté sur la base du code Neo4j)
Jun 12, 2024 am 10:32 AM
GraphRAG amélioré pour la récupération de graphes de connaissances (implémenté sur la base du code Neo4j)
Jun 12, 2024 am 10:32 AM
La génération améliorée de récupération de graphiques (GraphRAG) devient progressivement populaire et est devenue un complément puissant aux méthodes de recherche vectorielles traditionnelles. Cette méthode tire parti des caractéristiques structurelles des bases de données graphiques pour organiser les données sous forme de nœuds et de relations, améliorant ainsi la profondeur et la pertinence contextuelle des informations récupérées. Les graphiques présentent un avantage naturel dans la représentation et le stockage d’informations diverses et interdépendantes, et peuvent facilement capturer des relations et des propriétés complexes entre différents types de données. Les bases de données vectorielles sont incapables de gérer ce type d'informations structurées et se concentrent davantage sur le traitement de données non structurées représentées par des vecteurs de grande dimension. Dans les applications RAG, la combinaison de données graphiques structurées et de recherche de vecteurs de texte non structuré nous permet de profiter des avantages des deux en même temps, ce dont discutera cet article. structure
 Visualisez l'espace vectoriel FAISS et ajustez les paramètres RAG pour améliorer la précision des résultats
Mar 01, 2024 pm 09:16 PM
Visualisez l'espace vectoriel FAISS et ajustez les paramètres RAG pour améliorer la précision des résultats
Mar 01, 2024 pm 09:16 PM
À mesure que les performances des modèles de langage open source à grande échelle continuent de s'améliorer, les performances d'écriture et d'analyse du code, des recommandations, du résumé de texte et des paires questions-réponses (QA) se sont toutes améliorées. Mais lorsqu'il s'agit d'assurance qualité, le LLM ne répond souvent pas aux problèmes liés aux données non traitées, et de nombreux documents internes sont conservés au sein de l'entreprise pour garantir la conformité, les secrets commerciaux ou la confidentialité. Lorsque ces documents sont interrogés, LLM peut halluciner et produire un contenu non pertinent, fabriqué ou incohérent. Une technique possible pour relever ce défi est la génération augmentée de récupération (RAG). Cela implique le processus d'amélioration des réponses en référençant des bases de connaissances faisant autorité au-delà de la source de données de formation pour améliorer la qualité et la précision de la génération. Le système RAG comprend un système de récupération permettant de récupérer des fragments de documents pertinents du corpus
 Optimisation du LLM à l'aide de la technologie SPIN pour la formation de mise au point du jeu personnel
Jan 25, 2024 pm 12:21 PM
Optimisation du LLM à l'aide de la technologie SPIN pour la formation de mise au point du jeu personnel
Jan 25, 2024 pm 12:21 PM
2024 est une année de développement rapide pour les grands modèles de langage (LLM). Dans la formation du LLM, les méthodes d'alignement sont un moyen technique important, notamment le réglage fin supervisé (SFT) et l'apprentissage par renforcement avec rétroaction humaine qui s'appuie sur les préférences humaines (RLHF). Ces méthodes ont joué un rôle crucial dans le développement du LLM, mais les méthodes d’alignement nécessitent une grande quantité de données annotées manuellement. Face à ce défi, la mise au point est devenue un domaine de recherche dynamique, les chercheurs travaillant activement au développement de méthodes permettant d’exploiter efficacement les données humaines. Par conséquent, le développement de méthodes d’alignement favorisera de nouvelles percées dans la technologie LLM. L'Université de Californie a récemment mené une étude introduisant une nouvelle technologie appelée SPIN (SelfPlayfInetuNing). S
 Utiliser des graphiques de connaissances pour améliorer les capacités des modèles RAG et atténuer les fausses impressions des grands modèles
Jan 14, 2024 pm 06:30 PM
Utiliser des graphiques de connaissances pour améliorer les capacités des modèles RAG et atténuer les fausses impressions des grands modèles
Jan 14, 2024 pm 06:30 PM
Les hallucinations sont un problème courant lorsque l'on travaille avec de grands modèles de langage (LLM). Bien que LLM puisse générer un texte fluide et cohérent, les informations qu'il génère sont souvent inexactes ou incohérentes. Afin d'éviter les hallucinations du LLM, des sources de connaissances externes, telles que des bases de données ou des graphiques de connaissances, peuvent être utilisées pour fournir des informations factuelles. De cette manière, LLM peut s’appuyer sur ces sources de données fiables, ce qui permet d’obtenir un contenu textuel plus précis et plus fiable. Base de données vectorielles et base de données vectorielles Knowledge Graph Une base de données vectorielles est un ensemble de vecteurs de grande dimension qui représentent des entités ou des concepts. Ils peuvent être utilisés pour mesurer la similarité ou la corrélation entre différentes entités ou concepts, calculées à travers leurs représentations vectorielles. Une base de données vectorielles peut vous indiquer, sur la base de la distance vectorielle, que « Paris » et « France » sont plus proches que « Paris » et
 Méthodes de construction de systèmes RAG multimodaux : utilisation de CLIP et LLM
Jan 13, 2024 pm 10:24 PM
Méthodes de construction de systèmes RAG multimodaux : utilisation de CLIP et LLM
Jan 13, 2024 pm 10:24 PM
Nous discuterons des moyens de créer un système de génération augmentée par récupération (RAG) à l'aide de l'open source LargeLanguageMulti-Modal. Notre objectif est d'y parvenir sans compter sur LangChain ou LLlamaindex pour éviter d'ajouter davantage de dépendances au framework. Qu'est-ce que RAG Dans le domaine de l'intelligence artificielle, l'émergence de la technologie de génération augmentée par récupération (RAG) a apporté des améliorations révolutionnaires aux grands modèles de langage (LargeLanguageModels). L'essence de RAG est d'améliorer l'intelligence artificielle en permettant aux modèles de récupérer dynamiquement des informations en temps réel à partir de sources externes.
