
 Périphériques technologiques
IA
Une plongée approfondie dans les modèles, les données et les frameworks : une revue exhaustive de 54 pages de grands modèles de langage efficaces
Périphériques technologiques
IA
Une plongée approfondie dans les modèles, les données et les frameworks : une revue exhaustive de 54 pages de grands modèles de langage efficaces
Une plongée approfondie dans les modèles, les données et les frameworks : une revue exhaustive de 54 pages de grands modèles de langage efficaces

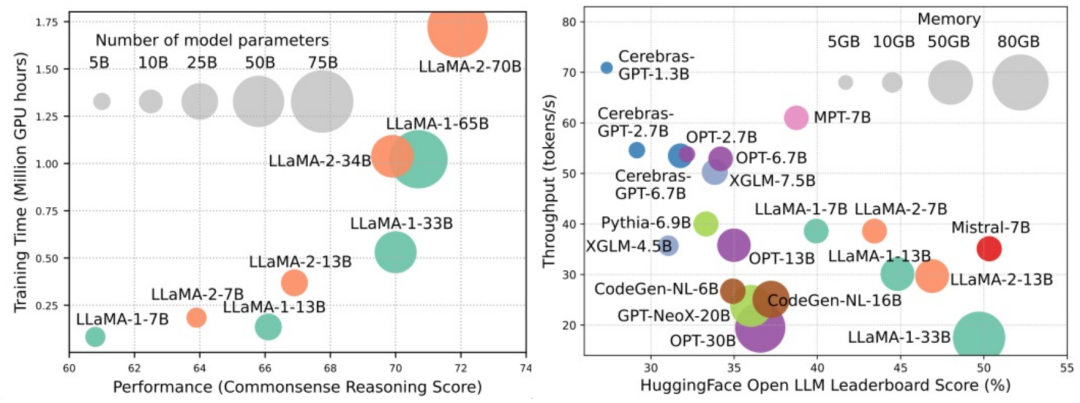
Les modèles linguistiques à grande échelle (LLM) ont démontré des capacités convaincantes dans de nombreuses tâches importantes, notamment la compréhension du langage naturel, la génération de langages et le raisonnement complexe, et ont eu un impact profond sur la société. Cependant, ces capacités exceptionnelles nécessitent des ressources de formation importantes (illustrées dans l’image de gauche) et de longs temps d’inférence (illustrés dans l’image de droite). Les chercheurs doivent donc développer des moyens techniques efficaces pour résoudre leurs problèmes d’efficacité.
De plus, comme on peut le voir sur le côté droit de la figure, certains LLM (Language Models) efficaces tels que Mistral-7B ont été utilisés avec succès dans la conception et le déploiement de LLM. Ces LLM efficaces peuvent réduire considérablement l'utilisation de la mémoire d'inférence et réduire la latence d'inférence tout en conservant une précision similaire à celle du LLaMA1-33B. Cela montre qu'il existe déjà des méthodes réalisables et efficaces qui ont été appliquées avec succès à la conception et à l'utilisation des LLM.
Dans cette revue, des chercheurs de l'Ohio State University, de l'Imperial College, de la Michigan State University, de l'Université du Michigan, d'Amazon, de Google, de Boson AI et de Microsoft Asia Research fournissent un aperçu de la recherche sur les LLM efficaces. étude du système. Ils ont divisé les technologies existantes pour optimiser l'efficacité des LLM en trois catégories, notamment centrées sur le modèle, centrées sur les données et centrées sur le framework, et ont résumé et discuté des technologies connexes les plus avancées.

- Article : https://arxiv.org/abs/2312.03863
- GitHub : https://github.com/AIoT-MLSys-Lab/Ef compétent-LLM s -Enquête
Afin d'organiser facilement les articles impliqués dans l'examen et de les tenir à jour, le chercheur a créé un référentiel GitHub et le maintient activement. Ils espèrent que ce référentiel aidera les chercheurs et les praticiens à comprendre systématiquement la recherche et le développement de LLM efficaces et les incitera à contribuer à ce domaine important et passionnant.
L'URL de l'entrepôt est https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey. Dans ce référentiel, vous pouvez trouver du contenu lié à une enquête sur les systèmes d'apprentissage automatique efficaces et à faible consommation. Ce référentiel fournit des articles de recherche, du code et de la documentation pour aider les utilisateurs à mieux comprendre et explorer les systèmes d'apprentissage automatique efficaces et à faible consommation. Si ce domaine vous intéresse, vous pouvez obtenir plus d’informations en visitant ce référentiel.
Centrée sur le modèle
Une approche centrée sur le modèle se concentre sur des techniques efficaces au niveau de l'algorithme et du système, où le modèle lui-même est au centre. Étant donné que les LLM comportent des milliards, voire des milliards de paramètres et présentent des caractéristiques uniques telles que l’émergence par rapport aux modèles à plus petite échelle, de nouvelles techniques doivent être développées pour optimiser l’efficacité des LLM. Cet article examine en détail cinq catégories de méthodes centrées sur le modèle, notamment la compression de modèle, un pré-entraînement efficace, un réglage fin efficace, une inférence efficace et une conception efficace d'architecture de modèle.
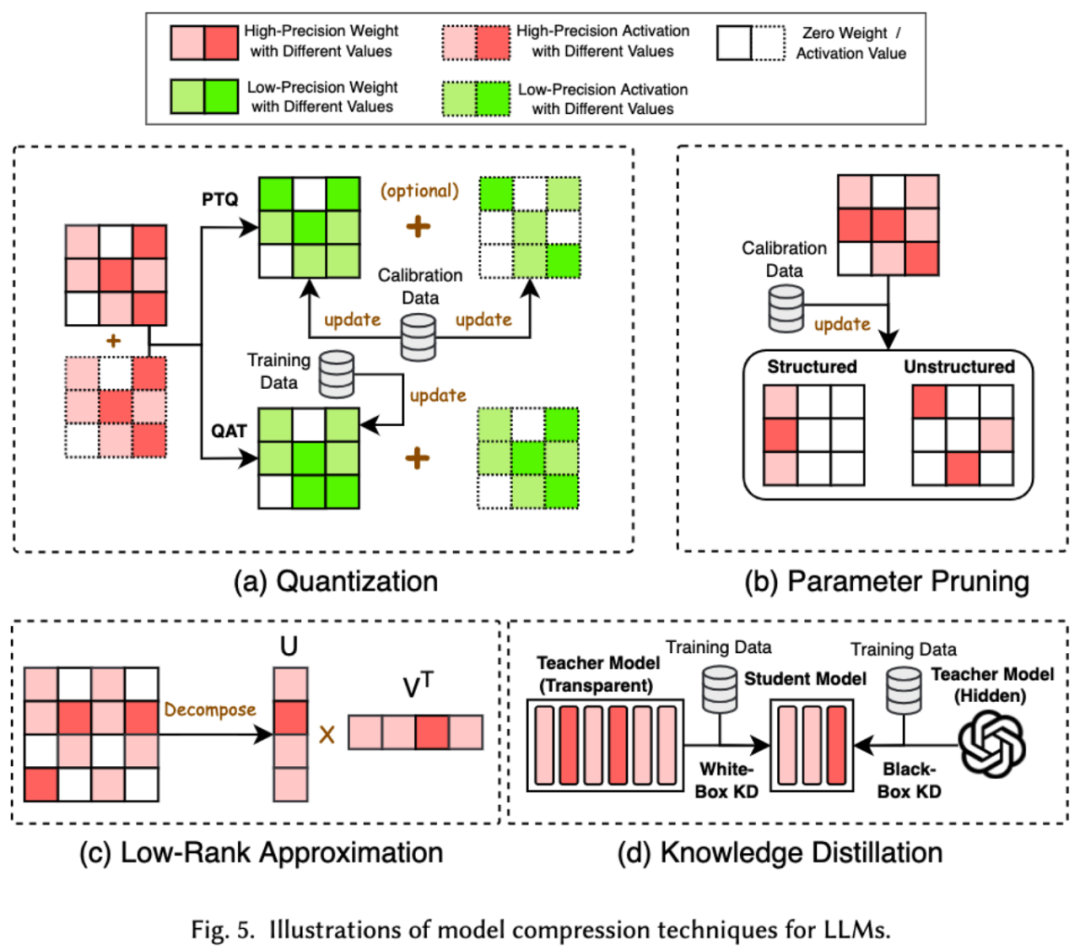
1. Dans le domaine de l’apprentissage automatique, la taille du modèle est souvent une considération importante. Les modèles plus grands nécessitent souvent plus d'espace de stockage et de ressources informatiques, et peuvent rencontrer des limitations lorsqu'ils sont exécutés sur des appareils mobiles. Par conséquent, la compression du modèle est une technique couramment utilisée pour réduire la taille du modèle. Les techniques de compression de modèle sont principalement divisées en quatre catégories : la quantification, l'élagage des paramètres, l'estimation de bas rang et la distillation des connaissances (voir la figure ci-dessous), parmi lesquelles la quantification. compressera les poids ou les valeurs d'activation du modèle de haute précision à faible précision. L'élagage des paramètres recherchera et supprimera les parties les plus redondantes des poids du modèle. L'estimation de bas rang convertira la matrice de poids du modèle en plusieurs bas-rangs. classer les petites matrices.La distillation des produits et des connaissances utilise directement un grand modèle pour former un petit modèle, de sorte que le petit modèle ait la capacité de remplacer le grand modèle lors de l'exécution de certaines tâches.
 2. Une pré-formation efficace
2. Une pré-formation efficace
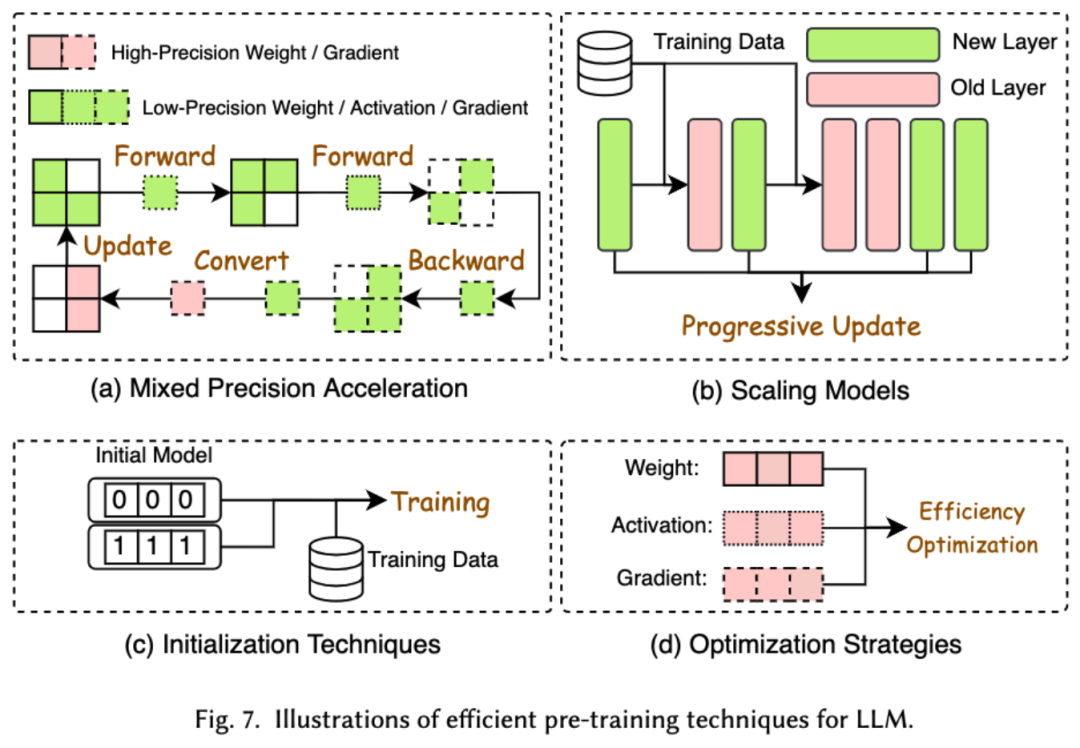
Le coût des LLM de pré-formation est très cher. Une pré-formation efficace vise à améliorer l’efficacité et à réduire le coût du processus de pré-formation pour les LLM. Une pré-formation efficace peut être divisée en une accélération de précision mixte, une mise à l'échelle du modèle, une technologie d'initialisation, des stratégies d'optimisation et une accélération au niveau du système.
L'accélération de précision mixte améliore l'efficacité du pré-entraînement en calculant les gradients, les poids et les activations à l'aide de poids de faible précision, puis en les reconvertissant en haute précision et en les appliquant pour mettre à jour les poids d'origine. La mise à l'échelle du modèle accélère la convergence avant la formation et réduit les coûts de formation en utilisant les paramètres des petits modèles pour passer aux grands modèles. La technologie d'initialisation accélère la convergence du modèle en concevant la valeur d'initialisation du modèle. La stratégie d'optimisation se concentre sur la conception d'optimiseurs légers pour réduire la consommation de mémoire lors de la formation du modèle. L'accélération au niveau du système utilise des technologies distribuées et autres pour accélérer la pré-formation du modèle à partir du niveau du système.
3. Un réglage fin efficace
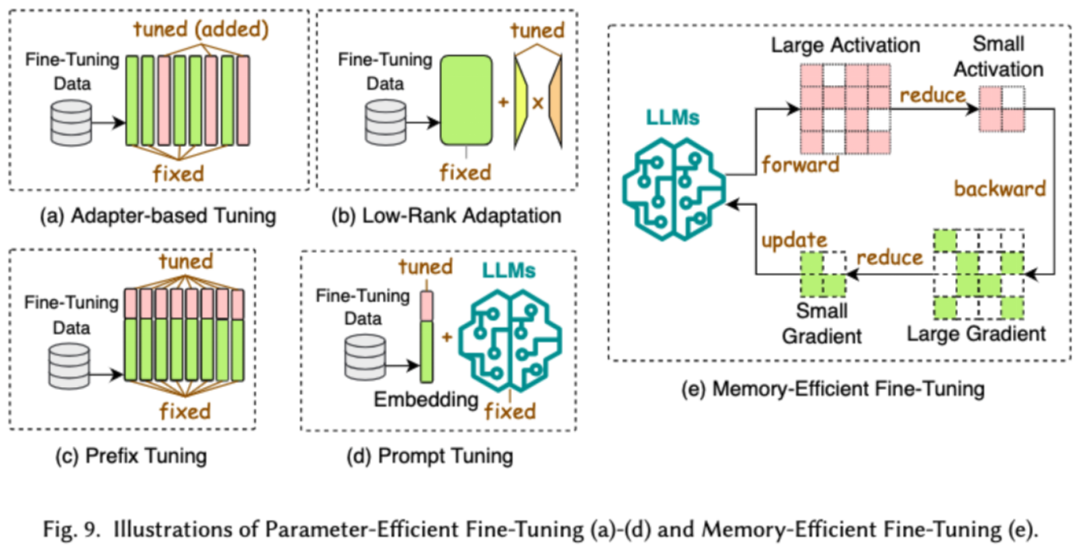
Un réglage fin efficace est conçu pour améliorer l'efficacité du processus de réglage fin des LLM. Les technologies de réglage fin efficaces courantes sont divisées en deux catégories, l'une est un réglage fin efficace basé sur des paramètres et l'autre est un réglage fin efficace en termes de mémoire.
Parameter Efficient Fine-Tuning (PEFT) vise à adapter le LLM aux tâches en aval en gelant l'ensemble du squelette du LLM et en mettant à jour uniquement un petit ensemble de paramètres supplémentaires. Dans cet article, nous avons divisé le PEFT en un réglage fin basé sur un adaptateur, une adaptation de bas rang, un réglage fin du préfixe et un réglage fin des mots d'invite.
Le réglage fin efficace basé sur la mémoire se concentre sur la réduction de la consommation de mémoire pendant tout le processus de réglage fin du LLM, comme la réduction de la mémoire consommée par l'état de l'optimiseur et les valeurs d'activation.
4. Raisonnement efficace
Le raisonnement efficace vise à améliorer l'efficacité du processus d'inférence des LLM. Les chercheurs divisent les technologies de raisonnement à haute efficacité courantes en deux catégories : l’une est l’accélération du raisonnement au niveau de l’algorithme et l’autre est l’accélération du raisonnement au niveau du système.
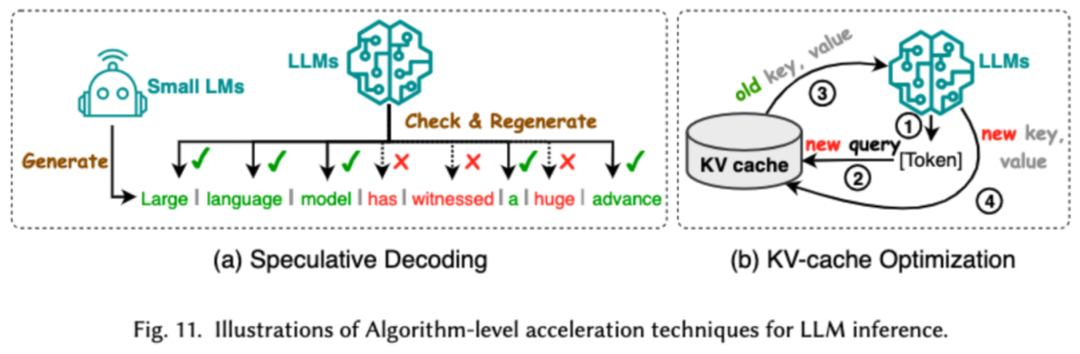
L'accélération d'inférence au niveau de l'algorithme peut être divisée en deux catégories : le décodage spéculatif et l'optimisation du cache KV. Le décodage spéculatif accélère le processus d'échantillonnage en calculant les jetons en parallèle à l'aide d'un modèle préliminaire plus petit afin de créer des préfixes spéculatifs pour le modèle cible plus grand. KV - L'optimisation du cache fait référence à l'optimisation du calcul répété des paires clé-valeur (KV) pendant le processus d'inférence des LLM.
L'accélération de l'inférence au niveau du système consiste à optimiser le nombre d'accès à la mémoire sur le matériel spécifié, à augmenter la quantité de parallélisme des algorithmes, etc. pour accélérer l'inférence LLM.
5. Conception d'architecture de modèle efficace
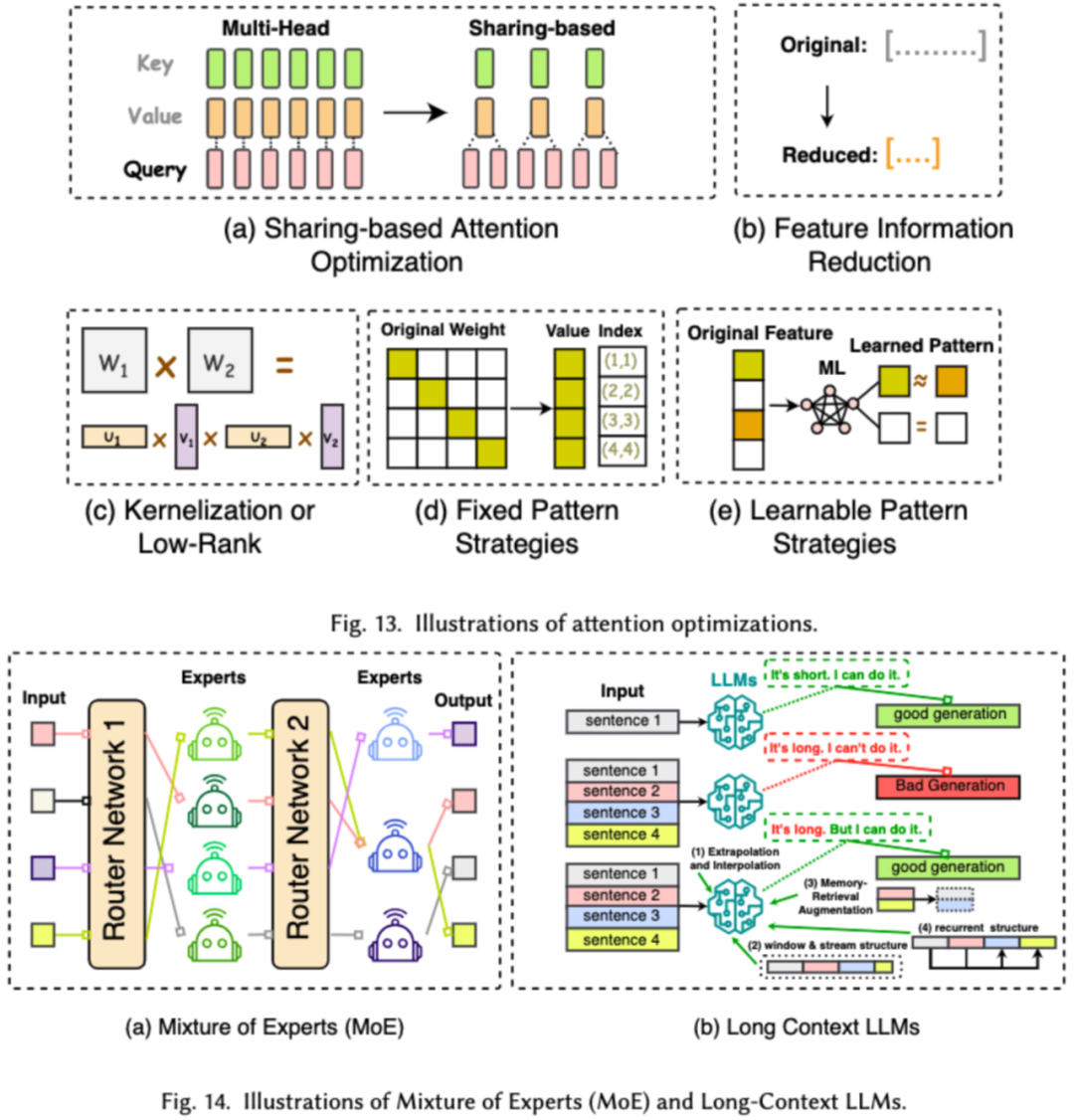
La conception d'architecture efficace pour les LLM fait référence à l'optimisation stratégique de la structure du modèle et du processus de calcul pour améliorer les performances et l'évolutivité tout en minimisant le LF. Nous divisons la conception d'architectures de modèles efficaces en quatre grandes catégories en fonction du type de modèle : les modules d'attention efficaces, les modèles experts hybrides, les grands modèles à texte long et les architectures pouvant remplacer les transformateurs.
Le module d'attention efficace vise à optimiser les calculs complexes et l'utilisation de la mémoire dans le module d'attention. Le modèle expert hybride (MoE) remplace les décisions de raisonnement de certains modules de LLM par plusieurs petits modèles experts pour obtenir une parcimonie globale, à long terme. Les grands modèles de texte sont des LLM spécialement conçus pour traiter efficacement des textes ultra-longs. L'architecture qui peut remplacer le transformateur réduit la complexité du modèle et atteint des capacités de raisonnement comparables à l'architecture post-transformateur en repensant l'architecture du modèle.
Centrée sur les données
L'approche centrée sur les données se concentre sur le rôle de la qualité et de la structure des données dans l'amélioration de l'efficacité des LLM. Dans cet article, les chercheurs discutent en détail de deux types de méthodes centrées sur les données, notamment la sélection de données et l'ingénierie des mots indicateurs.
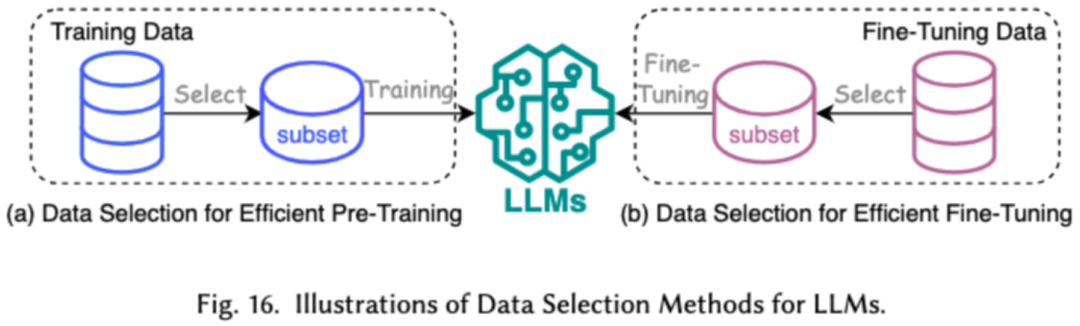
1. Sélection des données
La sélection des données LLM vise à nettoyer et sélectionner les données de pré-entraînement/affinage, telles que la suppression des données redondantes et invalides, pour accélérer le processus de formation.
2. Ingénierie de mots rapides
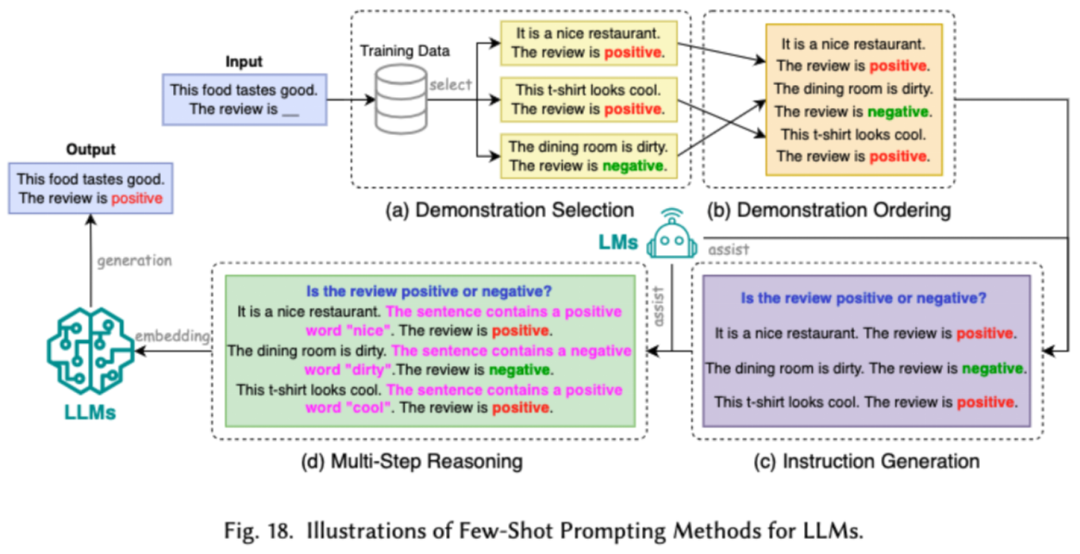
L'ingénierie de mots rapides guide les LLM pour générer les résultats souhaités en concevant des entrées efficaces (mots rapides). Son efficacité réside dans le fait qu'elle peut atteindre et après un réglage fastidieux des performances considérables du modèle. . Les chercheurs divisent les technologies courantes d’ingénierie de mots d’invite en trois grandes catégories : l’ingénierie de mots d’invite à partir de quelques échantillons, la compression de mots d’invite et la génération de mots d’invite.
L'ingénierie de mots rapides à quelques exemples fournit à LLM un ensemble limité d'exemples pour guider sa compréhension des tâches qui doivent être effectuées. La compression des mots d'invite accélère le traitement des entrées par les LLM en compressant les entrées ou l'apprentissage d'invites longues et en utilisant des représentations d'invite. La génération de mots rapides vise à créer automatiquement des invites efficaces qui guident le modèle pour générer des réponses spécifiques et pertinentes, plutôt que d'utiliser des données annotées manuellement.
Centrée sur le framework
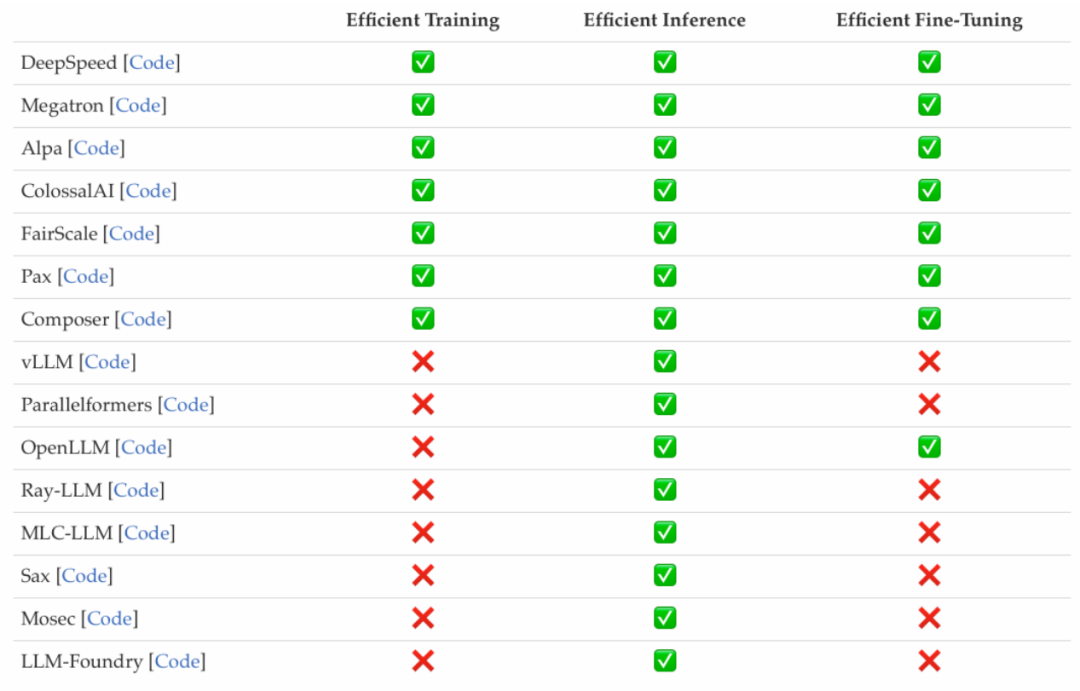
Les chercheurs ont étudié les frameworks LLM efficaces récemment populaires et ont répertorié les tâches efficaces qu'ils peuvent optimiser, y compris la pré-formation, le réglage fin et l'inférence (comme suit) comme montré sur la figure).
Résumé
Dans cette enquête, les chercheurs vous proposent une revue systématique des LLM efficaces, qui est un domaine de recherche important dédié à rendre les LLM plus démocratisés. Ils commencent par expliquer pourquoi des LLM efficaces sont nécessaires. Dans un cadre ordonné, cet article étudie les technologies efficaces au niveau algorithmique et au niveau système des LLM du point de vue respectivement centré sur le modèle, centré sur les données et centré sur le cadre.
Les chercheurs pensent que l'efficacité jouera un rôle de plus en plus important dans les LLM et les systèmes orientés LLM. Ils espèrent que cette enquête aidera les chercheurs et les praticiens à entrer rapidement dans ce domaine et servira de catalyseur pour stimuler de nouvelles recherches sur les LLM efficaces.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
