
 Périphériques technologiques
IA
NVIDIA, Mila et Caltech lancent conjointement un modèle multimodal de structure moléculaire-texte combinant LLM et découverte de médicaments
Périphériques technologiques
IA
NVIDIA, Mila et Caltech lancent conjointement un modèle multimodal de structure moléculaire-texte combinant LLM et découverte de médicaments
NVIDIA, Mila et Caltech lancent conjointement un modèle multimodal de structure moléculaire-texte combinant LLM et découverte de médicaments


Auteur | Liu Shengchao
Éditeur | Kaixia
À partir de 2021, la combinaison du grand langage et de la multimodalité a balayé la communauté de recherche sur l'apprentissage automatique.
Avec le développement de grands modèles et d'applications multimodales, pouvons-nous appliquer ces techniques à la découverte de médicaments ? Et ces descriptions textuelles en langage naturel peuvent-elles apporter de nouvelles perspectives à ce problème difficile ? La réponse est oui, et nous en sommes optimistes
Récemment, des équipes de recherche de l'Institut des algorithmes d'apprentissage de Montréal (Mila) au Canada, de NVIDIA Research, de l'Université de l'Illinois à Urbana-Champaign (UIUC), de l'Université de Princeton et de l'Université de Californie Institute of Technology, un modèle multimodal de structure moléculaire-texte MoleculeSTM est proposé en apprenant conjointement la structure chimique et la description textuelle des molécules grâce à des stratégies d'apprentissage contrastées.
Cette recherche s'intitule « Structure moléculaire multimodale – modèle de texte pour la récupération et l'édition textuelles » et a été publiée dans « Nature Machine Intelligence » le 18 décembre 2023.

Lien papier : https://www.nature.com/articles/s42256-023-00759-6 doit être réécrit
Le Dr Liu Shengchao est le premier auteur, et le professeur Anima Anandkumar de NVIDIA Research est. l'auteur correspondant. Nie Weili, Wang Chengpeng, Lu Jiarui, Qiao Zhuoran, Liu Ling, Tang Jian et Xiao Chaowei sont co-auteurs.
Ce projet a été réalisé par le Dr Liu Shengchao après avoir rejoint NVIDIA Research en mars 2022, sous la direction des professeurs Nie Weili, professeur Tang Jian, professeur Xiao Chaowei et professeur Anima Anandkumar.
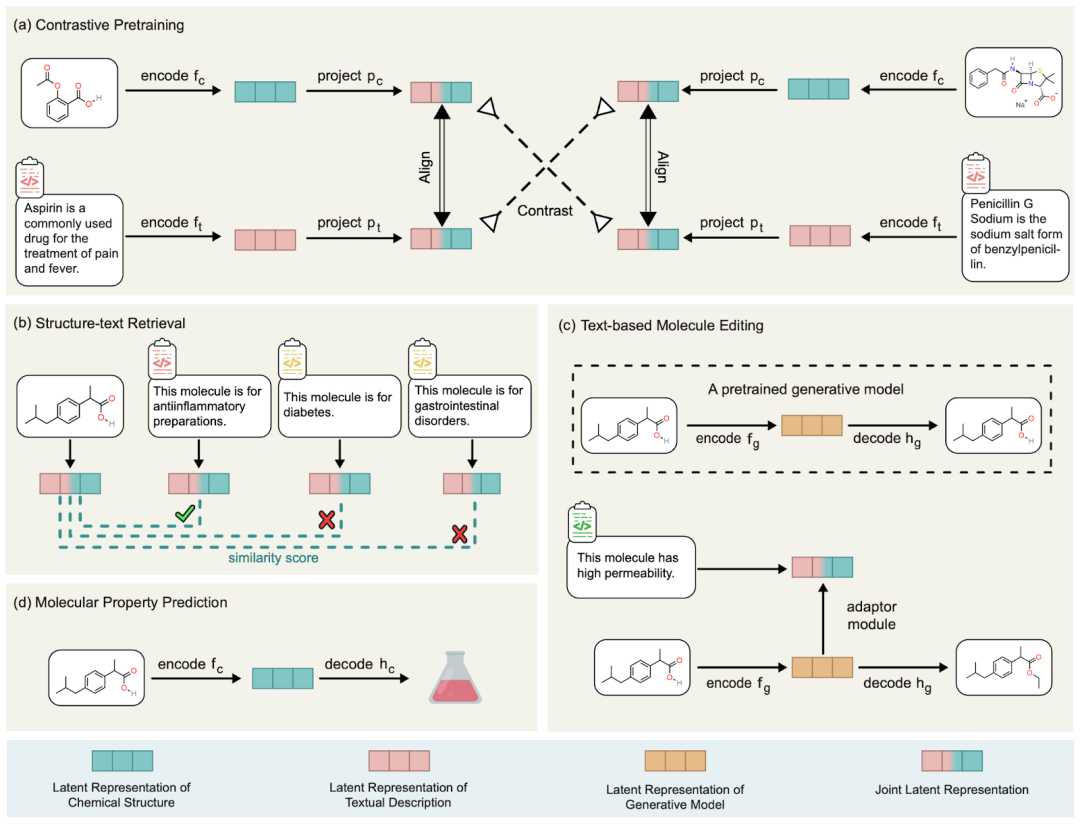
Le Dr Liu Shengchao a déclaré : "Notre motivation était de mener une exploration préliminaire du LLM et de la découverte de médicaments, et a finalement proposé MoleculeSTM." est très simple et directe, c'est-à-dire que la description des molécules peut être divisée en deux catégories : la structure chimique interne et la description fonctionnelle externe. Ici, nous utilisons une méthode contrastive de pré-formation pour aligner et connecter ces deux types d'informations. Le diagramme spécifique est présenté dans la figure ci-dessous
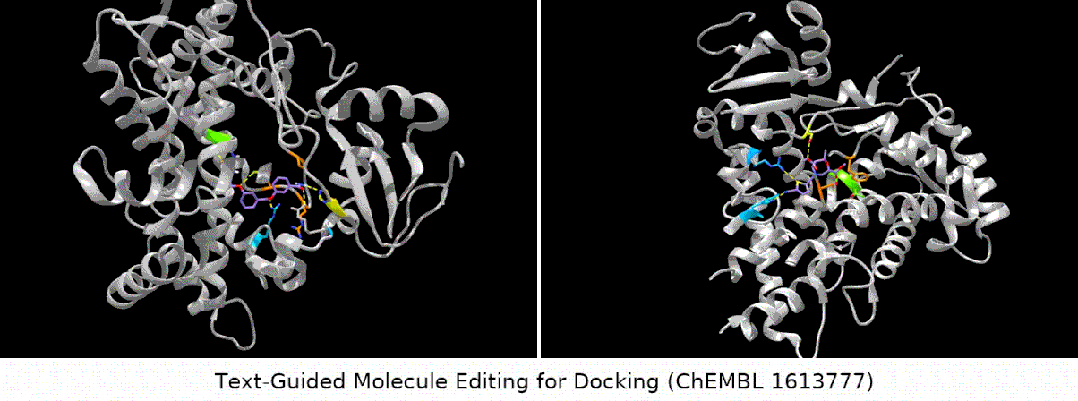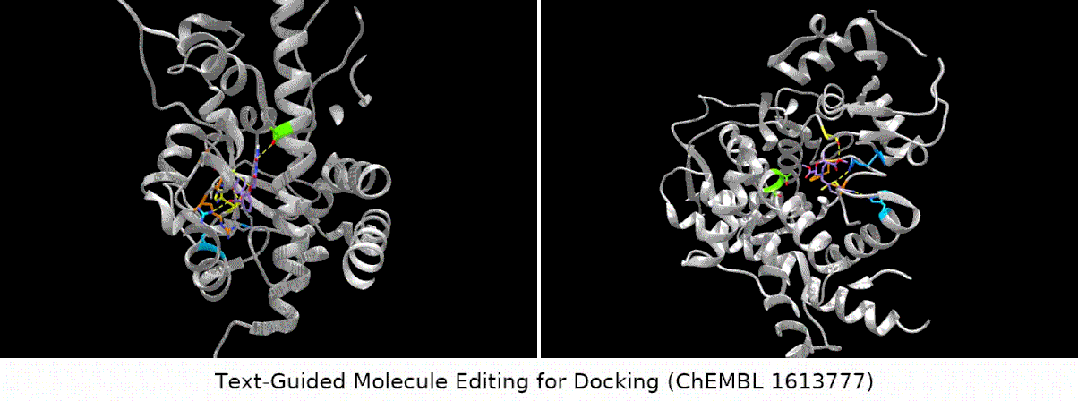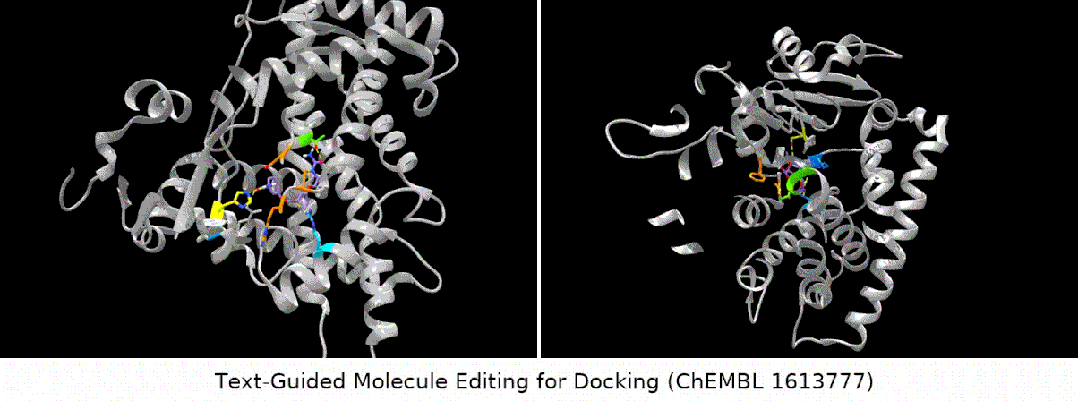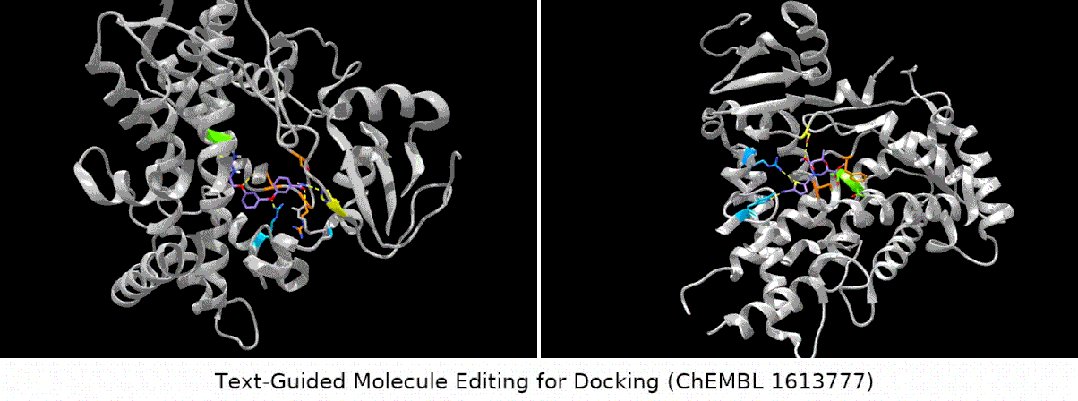
Illustration : organigramme MoleculeSTM.
Et cet alignement de MoleculeSTM a une très bonne propriété : lorsqu'il y a des tâches difficiles à résoudre dans l'espace chimique, nous pouvons les transférer dans l'espace du langage naturel. Et les tâches en langage naturel seront relativement plus faciles à résoudre en raison de ses caractéristiques. Sur cette base, nous avons conçu une grande variété de tâches en aval pour vérifier son efficacité. Ci-dessous, nous discutons en détail de plusieurs idées.
 Caractéristiques du langage naturel et des grands modèles de langage
Caractéristiques du langage naturel et des grands modèles de langage
Le vocabulaire ouvert signifie que nous pouvons exprimer toutes les connaissances humaines actuelles en langage naturel, de sorte que les nouvelles connaissances qui apparaîtront dans le futur peuvent également être résumées et résumées en utilisant le langage existant. Résumer. Par exemple, si une nouvelle protéine apparaît, nous espérons décrire sa fonction en langage naturel. La compositionnalité signifie qu'en langage naturel, un concept complexe peut être exprimé conjointement par plusieurs concepts simples. Ceci est très utile pour des tâches telles que l'édition multi-attributs : il est très difficile d'éditer des molécules pour qu'elles répondent à plusieurs propriétés en même temps dans l'espace chimique, mais nous pouvons exprimer plusieurs propriétés très simplement en langage naturel.
Dans notre récent travail ChatDrug (https://arxiv.org/abs/2305.18090), nous avons exploré les caractéristiques du dialogue entre le langage naturel et les grands modèles de langage. Les amis qui sont intéressés par cela peuvent le vérifier- Conception de tâches. induit par les fonctionnalités fait référence à la conception de la planification et de l'organisation des tâches en fonction des caractéristiques du produit ou du système
- La première tâche que nous envisageons est d'être capable d'effectuer des simulations informatiques et d'obtenir des résultats. À l’avenir, les résultats de vérification en laboratoire humide seront pris en compte, mais cela n’entre pas dans le cadre des travaux actuels.
- Deuxièmement, nous ne considérons que les problèmes dont les résultats sont ambigus. Des exemples spécifiques incluent le fait de rendre une certaine molécule plus soluble ou pénétrable dans l’eau. Certains problèmes ont des résultats clairs, comme l'ajout d'un certain groupe fonctionnel à une certaine position dans une molécule. Nous pensons que de telles tâches sont plus simples et plus directes pour les experts en drogue et en chimie. Elle peut donc être utilisée comme tâche de validation de principe à l'avenir, mais elle ne deviendra pas l'objectif principal de la tâche.
Nous avons ainsi conçu trois grandes catégories de tâches :
- Récupération de texte de structure sans tir ;
- Édition de molécules basée sur du texte sans tir ;
- Prédiction des propriétés moléculaires.
Nous nous concentrerons sur la deuxième tâche dans la section suivante
Les résultats qualitatifs de l'édition de molécules sont reformulés comme suit :
Cette tâche consiste à saisir une molécule et une description en langage naturel (comme des attributs supplémentaires) au en même temps, puis il est souhaitable de pouvoir produire des descriptions textuelles en langage complexe de nouvelles molécules. Il s’agit d’une optimisation des leads guidée par texte.
La méthode spécifique consiste à utiliser le modèle de génération de molécules déjà entraîné et notre MoleculeSTM pré-entraîné pour apprendre l'alignement de leurs espaces latents afin d'effectuer une interpolation de l'espace latent, puis générer les molécules cibles par décodage. Le diagramme de processus est le suivant.
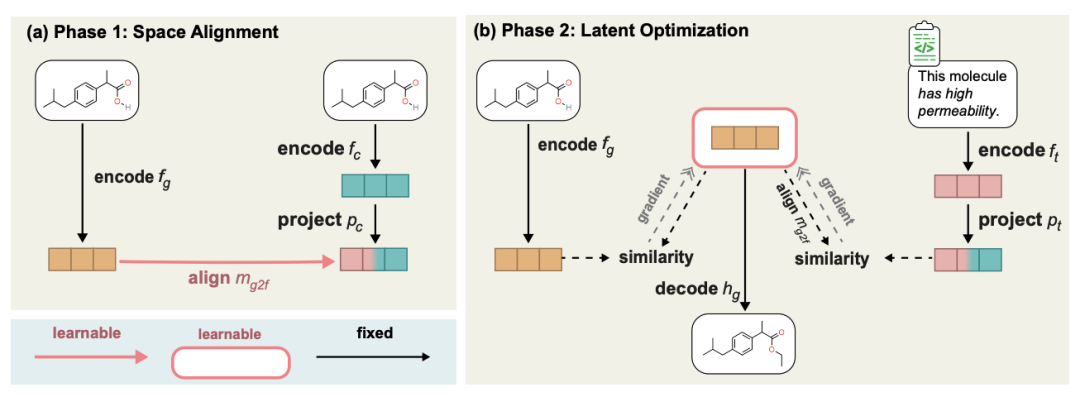
Le contenu qui doit être réécrit est : un diagramme de processus en deux étapes d'édition moléculaire guidée par texte à échantillon nul
Nous montrons ici les résultats qualitatifs de plusieurs groupes d'édition moléculaire, reformulés comme suit : (Le les détails des résultats des tâches restantes en aval peuvent être consultés (voir le document original). Nous considérons principalement quatre types de tâches d'édition moléculaire :
- Édition d'un seul attribut : édition d'un seul attribut, tel que la solubilité dans l'eau, la pénétrabilité et le nombre de donneurs et d'accepteurs de liaisons hydrogène.
- Modification des attributs composites : modifiez plusieurs attributs en même temps, tels que la solubilité dans l'eau et le nombre de donneurs de liaisons hydrogène.
- Édition de similarité de médicament : (Annexe D.5) consiste à rapprocher la molécule d'entrée et la molécule cible du médicament.
- Recherche voisine de médicaments brevetés : pour les médicaments brevetés, les médicaments intermédiaires sont souvent déclarés ensemble. Ce que nous faisons ici, c'est combiner le médicament intermédiaire avec la description en langage naturel pour voir s'il peut générer le médicament cible final.
- éditeur d'affinité de liaison : nous avons sélectionné plusieurs tests ChEMBL comme cibles, dans le but d'avoir une affinité de liaison plus élevée entre les molécules d'entrée et les cibles.
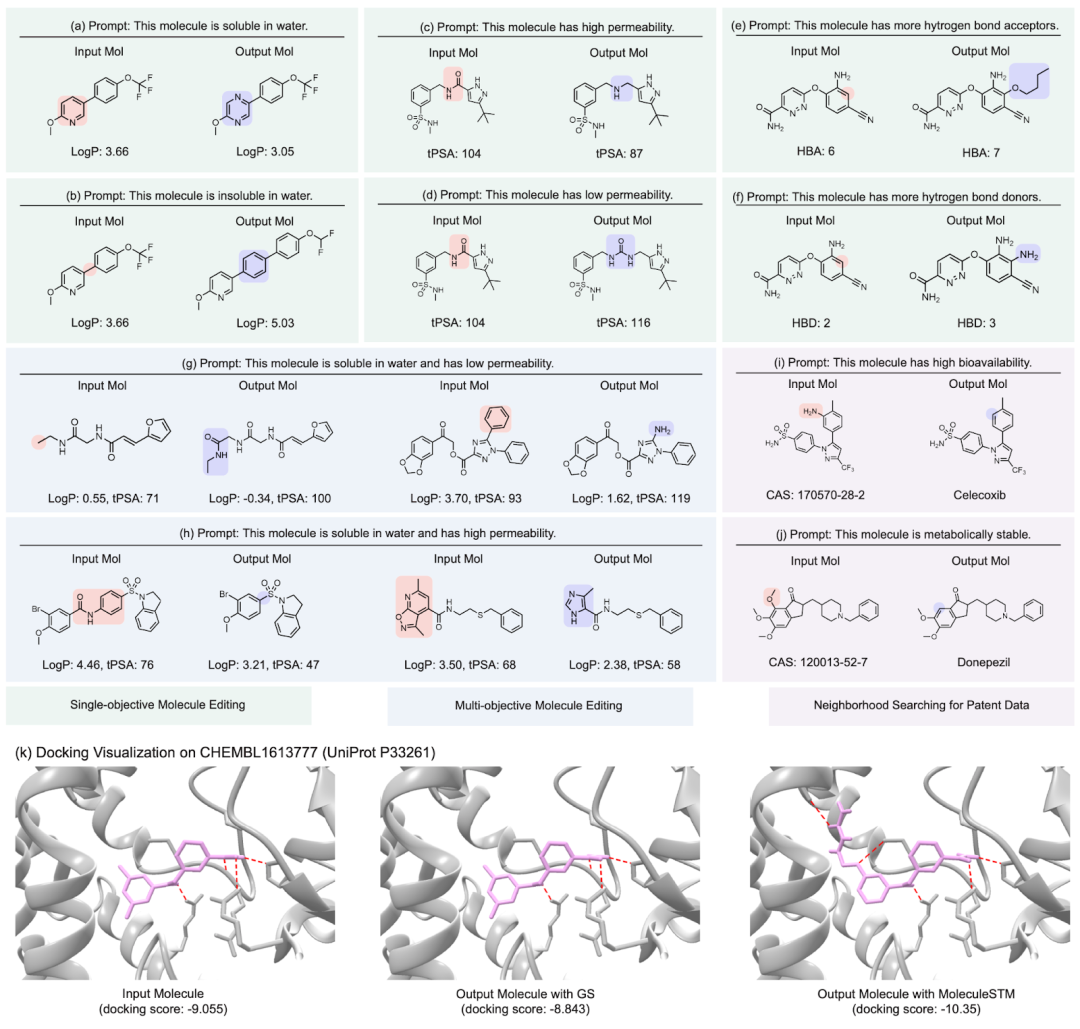
Affichage des résultats : édition de molécules guidée par texte sans échantillon. (Remarque : il s'agit d'une traduction directe de la phrase originale en chinois.)
Ce qui est plus intéressant est le dernier type de tâche. Nous avons constaté que MoleculeSTM peut effectivement effectuer une correspondance de ligand sur la base de la description textuelle du composé principal. optimisation. (Remarque : les informations sur la structure des protéines ici ne seront connues qu'après évaluation.)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Dans la fabrication moderne, une détection précise des défauts est non seulement la clé pour garantir la qualité des produits, mais également la clé de l’amélioration de l’efficacité de la production. Cependant, les ensembles de données de détection de défauts existants manquent souvent de précision et de richesse sémantique requises pour les applications pratiques, ce qui rend les modèles incapables d'identifier des catégories ou des emplacements de défauts spécifiques. Afin de résoudre ce problème, une équipe de recherche de premier plan composée de l'Université des sciences et technologies de Hong Kong, Guangzhou et de Simou Technology a développé de manière innovante l'ensemble de données « DefectSpectrum », qui fournit une annotation à grande échelle détaillée et sémantiquement riche des défauts industriels. Comme le montre le tableau 1, par rapport à d'autres ensembles de données industrielles, l'ensemble de données « DefectSpectrum » fournit le plus grand nombre d'annotations de défauts (5 438 échantillons de défauts) et la classification de défauts la plus détaillée (125 catégories de défauts).
 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les tâches de langage visuel.
 Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Pour l’IA, l’Olympiade mathématique n’est plus un problème. Jeudi, l'intelligence artificielle de Google DeepMind a réalisé un exploit : utiliser l'IA pour résoudre la vraie question de l'Olympiade mathématique internationale de cette année, l'OMI, et elle n'était qu'à un pas de remporter la médaille d'or. Le concours de l'OMI qui vient de se terminer la semaine dernière comportait six questions portant sur l'algèbre, la combinatoire, la géométrie et la théorie des nombres. Le système d'IA hybride proposé par Google a répondu correctement à quatre questions et a marqué 28 points, atteignant le niveau de la médaille d'argent. Plus tôt ce mois-ci, le professeur titulaire de l'UCLA, Terence Tao, venait de promouvoir l'Olympiade mathématique de l'IA (AIMO Progress Award) avec un prix d'un million de dollars. De manière inattendue, le niveau de résolution de problèmes d'IA s'était amélioré à ce niveau avant juillet. Posez les questions simultanément sur l'OMI. La chose la plus difficile à faire correctement est l'OMI, qui a la plus longue histoire, la plus grande échelle et la plus négative.
 Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Editeur | KX À ce jour, les détails structurels et la précision déterminés par cristallographie, des métaux simples aux grandes protéines membranaires, sont inégalés par aucune autre méthode. Cependant, le plus grand défi, appelé problème de phase, reste la récupération des informations de phase à partir d'amplitudes déterminées expérimentalement. Des chercheurs de l'Université de Copenhague au Danemark ont développé une méthode d'apprentissage en profondeur appelée PhAI pour résoudre les problèmes de phase cristalline. Un réseau neuronal d'apprentissage en profondeur formé à l'aide de millions de structures cristallines artificielles et de leurs données de diffraction synthétique correspondantes peut générer des cartes précises de densité électronique. L'étude montre que cette méthode de solution structurelle ab initio basée sur l'apprentissage profond peut résoudre le problème de phase avec une résolution de seulement 2 Angströms, ce qui équivaut à seulement 10 à 20 % des données disponibles à la résolution atomique, alors que le calcul ab initio traditionnel
 Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Editeur | ScienceAI Sur la base de données cliniques limitées, des centaines d'algorithmes médicaux ont été approuvés. Les scientifiques se demandent qui devrait tester les outils et comment le faire au mieux. Devin Singh a vu un patient pédiatrique aux urgences subir un arrêt cardiaque alors qu'il attendait un traitement pendant une longue période, ce qui l'a incité à explorer l'application de l'IA pour réduire les temps d'attente. À l’aide des données de triage des salles d’urgence de SickKids, Singh et ses collègues ont construit une série de modèles d’IA pour fournir des diagnostics potentiels et recommander des tests. Une étude a montré que ces modèles peuvent accélérer les visites chez le médecin de 22,3 %, accélérant ainsi le traitement des résultats de près de 3 heures par patient nécessitant un examen médical. Cependant, le succès des algorithmes d’intelligence artificielle dans la recherche ne fait que le vérifier.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 PRO | Pourquoi les grands modèles basés sur le MoE méritent-ils davantage d'attention ?
Aug 07, 2024 pm 07:08 PM
PRO | Pourquoi les grands modèles basés sur le MoE méritent-ils davantage d'attention ?
Aug 07, 2024 pm 07:08 PM
En 2023, presque tous les domaines de l’IA évoluent à une vitesse sans précédent. Dans le même temps, l’IA repousse constamment les limites technologiques de domaines clés tels que l’intelligence embarquée et la conduite autonome. Sous la tendance multimodale, le statut de Transformer en tant qu'architecture dominante des grands modèles d'IA sera-t-il ébranlé ? Pourquoi l'exploration de grands modèles basés sur l'architecture MoE (Mixture of Experts) est-elle devenue une nouvelle tendance dans l'industrie ? Les modèles de grande vision (LVM) peuvent-ils constituer une nouvelle avancée dans la vision générale ? ...Dans la newsletter des membres PRO 2023 de ce site publiée au cours des six derniers mois, nous avons sélectionné 10 interprétations spéciales qui fournissent une analyse approfondie des tendances technologiques et des changements industriels dans les domaines ci-dessus pour vous aider à atteindre vos objectifs dans le nouveau année. Cette interprétation provient de la Week50 2023
 Identifiez automatiquement les meilleures molécules et réduisez les coûts de synthèse. Le MIT développe un cadre d'algorithme de prise de décision en matière de conception moléculaire.
Jun 22, 2024 am 06:43 AM
Identifiez automatiquement les meilleures molécules et réduisez les coûts de synthèse. Le MIT développe un cadre d'algorithme de prise de décision en matière de conception moléculaire.
Jun 22, 2024 am 06:43 AM
Éditeur | L’utilisation de Ziluo AI pour rationaliser la découverte de médicaments explose. Ciblez des milliards de molécules candidates pour détecter celles qui pourraient posséder les propriétés nécessaires au développement de nouveaux médicaments. Il y a tellement de variables à prendre en compte, depuis le prix des matériaux jusqu’au risque d’erreur, qu’évaluer les coûts de synthèse des meilleures molécules candidates n’est pas une tâche facile, même si les scientifiques utilisent l’IA. Ici, les chercheurs du MIT ont développé SPARROW, un cadre d'algorithme de prise de décision quantitative, pour identifier automatiquement les meilleurs candidats moléculaires, minimisant ainsi les coûts de synthèse tout en maximisant la probabilité que les candidats possèdent les propriétés souhaitées. L’algorithme a également identifié les matériaux et les étapes expérimentales nécessaires à la synthèse de ces molécules. SPARROW prend en compte le coût de synthèse d'un lot de molécules à la fois, puisque plusieurs molécules candidates sont souvent disponibles
