
 Périphériques technologiques
IA
Les dernières recherches de Google MIT montrent : obtenir des données de haute qualité n'est pas difficile, les grands modèles sont la solution
Périphériques technologiques
IA
Les dernières recherches de Google MIT montrent : obtenir des données de haute qualité n'est pas difficile, les grands modèles sont la solution
Les dernières recherches de Google MIT montrent : obtenir des données de haute qualité n'est pas difficile, les grands modèles sont la solution

L'acquisition de données de haute qualité est devenue un goulot d'étranglement majeur dans la formation actuelle des grands modèles.
Il y a quelques jours, OpenAI a été poursuivi en justice par le New York Times et a exigé des milliards de dollars de compensation. La plainte énumère plusieurs preuves de plagiat par GPT-4.
Même le New York Times a appelé à la destruction de presque tous les grands modèles comme le GPT.

De nombreux grands noms de l’industrie de l’IA croient depuis longtemps que les « données synthétiques » pourraient être la meilleure solution à ce problème.

Auparavant, l'équipe de Google a également proposé une méthode d'utilisation de LLM pour remplacer les préférences d'étiquetage humaines RLAIF, et l'effet n'est même pas inférieur à celui des humains.
Maintenant, des chercheurs de Google et du MIT ont découvert que l'apprentissage à partir de grands modèles peut conduire à des représentations des meilleurs modèles formés à l'aide de données réelles.
Cette dernière méthode s'appelle SynCLR, une méthode d'apprentissage de représentations virtuelles entièrement à partir d'images synthétiques et de descriptions synthétiques, sans aucune donnée réelle.

Adresse papier : https://arxiv.org/abs/2312.17742
Les résultats expérimentaux montrent que la représentation apprise grâce à la méthode SynCLR peut être aussi bonne que l'effet de transmission du CLIP d'OpenAI sur ImageNet .
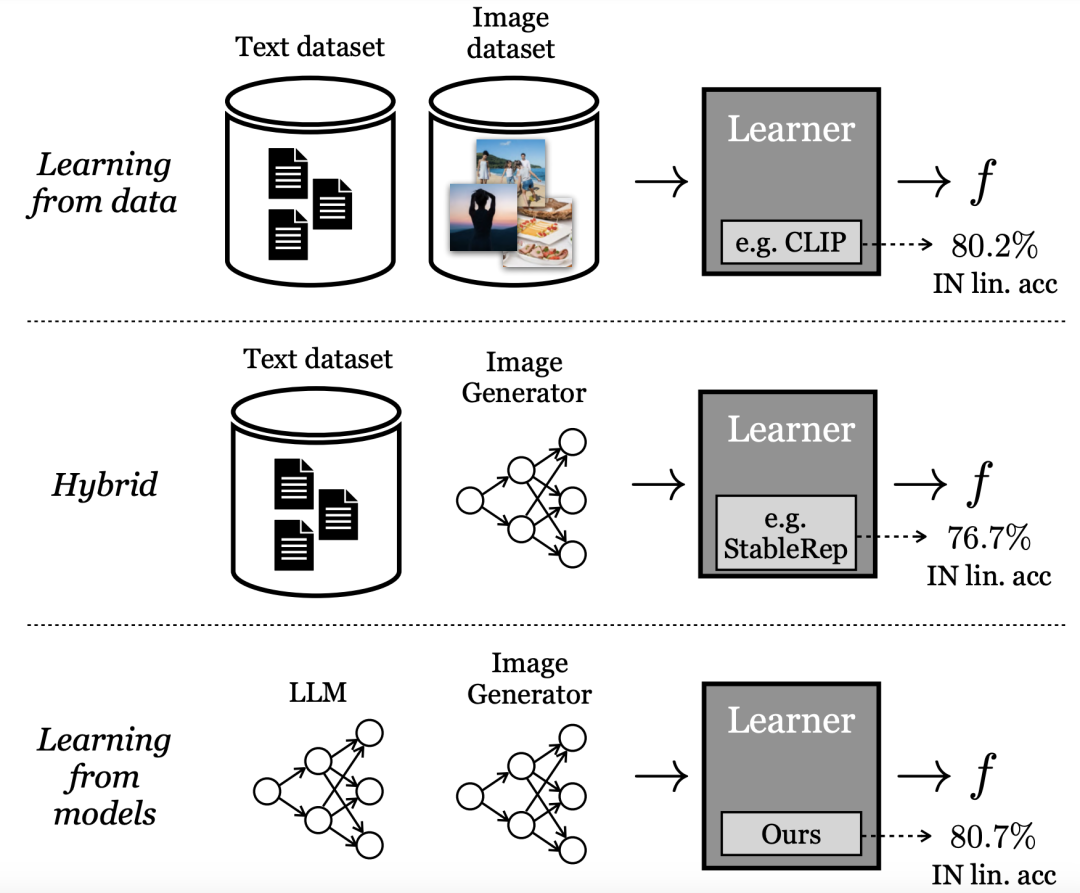
Apprentissage à partir de modèles génératifs
Les méthodes d'apprentissage par « représentation visuelle » les plus performantes s'appuient actuellement sur des ensembles de données réelles à grande échelle. Cependant, la collecte de données réelles se heurte à de nombreuses difficultés.
Pour réduire le coût de la collecte de données, les chercheurs de cet article posent la question :
Les données synthétiques échantillonnées à partir de modèles génératifs disponibles dans le commerce constituent-elles une voie viable vers des ensembles de données organisés à grande échelle ? former des représentations visuelles de pointe ?
Différent de l'apprentissage direct à partir des données, les chercheurs de Google appellent ce mode « apprentissage à partir du modèle ». En tant que source de données pour créer des ensembles de formation à grande échelle, les modèles présentent plusieurs avantages :
- Fournir de nouvelles méthodes de contrôle pour la gestion des données via leurs variables latentes, variables conditionnelles et hyperparamètres.
- Les modèles sont également plus faciles à partager et à stocker (puisque les modèles sont plus faciles à compresser que les données) et peuvent produire un nombre illimité d'échantillons de données.
De plus en plus de littérature étudie ces propriétés ainsi que d'autres avantages et inconvénients des modèles génératifs en tant que source de données pour la formation de modèles en aval.
Certaines de ces méthodes adoptent un modèle hybride, c'est-à-dire mélangent des ensembles de données réelles et synthétiques, ou nécessitent qu'un ensemble de données réels génère un autre ensemble de données synthétiques.
D'autres méthodes tentent d'apprendre des représentations à partir de « données purement synthétiques » mais sont loin derrière les modèles les plus performants.
Dans l'article, la dernière méthode proposée par les chercheurs utilise un modèle génératif pour redéfinir la granularité des classes de visualisation.
Comme le montre la figure 2, quatre images ont été générées à l'aide de 2 astuces "Un golden retriever portant des lunettes de soleil et un chapeau de plage faisant du vélo" et "Un joli golden retriever assis sur une maison faite de sushi" à l'intérieur".
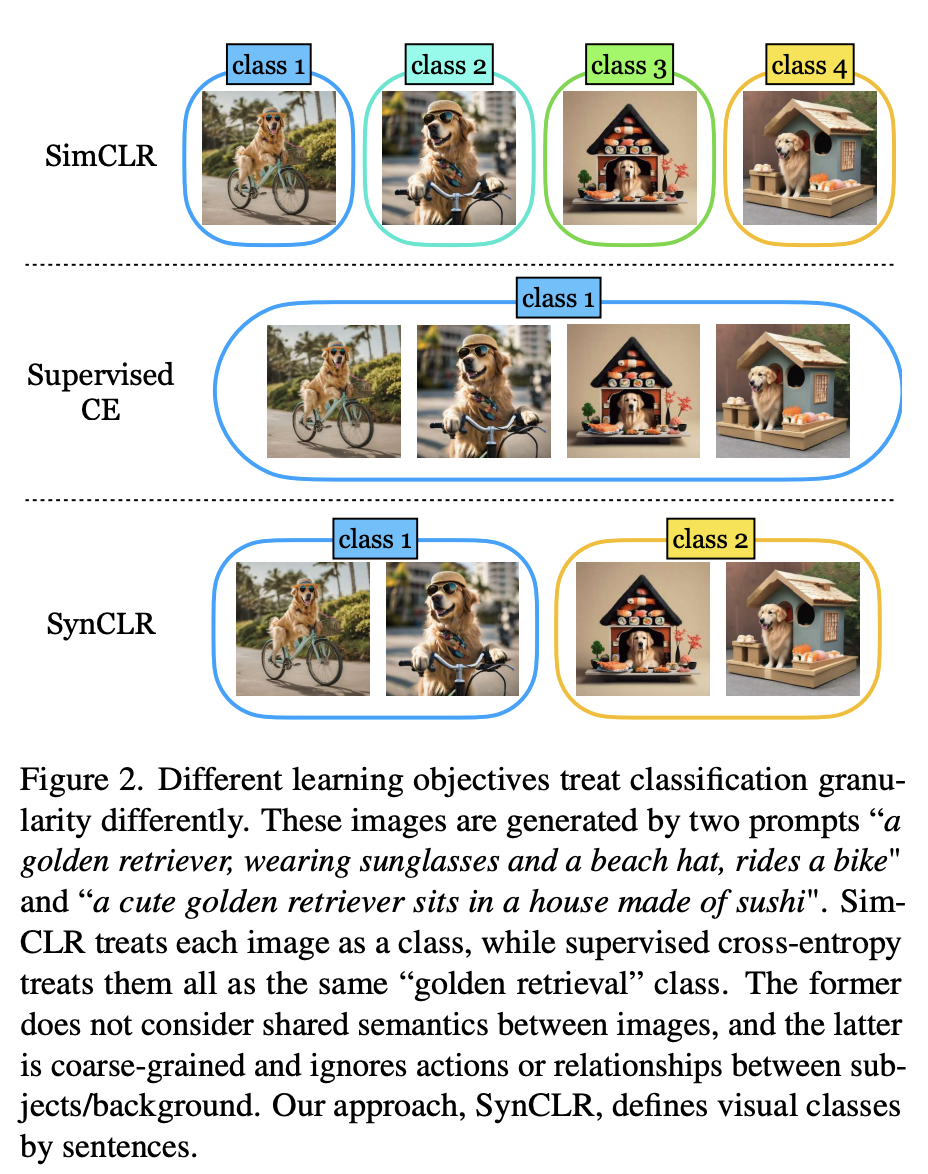
Les méthodes traditionnelles auto-supervisées (telles que Sim-CLR) traiteront ces images comme des classes différentes, et les intégrations de différentes images seront séparées, sans prendre explicitement en compte la sémantique partagée entre les images.
À l'autre extrême, les méthodes d'apprentissage supervisé (c'est-à-dire SupCE) traitent toutes ces images comme une seule classe (comme "golden retriever"). Cela ignore les nuances sémantiques des images, comme un chien faisant du vélo dans une paire d'images et un chien assis dans une maison de sushi dans une autre.
En revanche, l'approche SynCLR traite les descriptions comme des classes, c'est-à-dire une classe de visualisation par description.
De cette façon, nous pouvons regrouper les images selon les deux concepts « faire du vélo » et « s'asseoir dans un restaurant de sushi ».
Ce type de granularité est difficile à exploiter dans des données réelles car collecter plusieurs images par une description donnée n'est pas anodin, surtout lorsque le nombre de descriptions augmente.
Cependant, le modèle de diffusion texte-image a fondamentalement cette capacité.
En conditionnant simplement la même description et en utilisant différentes entrées de bruit, le modèle de diffusion texte-image peut générer différentes images qui correspondent à la même description.
Plus précisément, les auteurs étudient le problème de l'apprentissage des encodeurs visuels sans données d'image ou de texte réelles.
La dernière approche repose sur l'utilisation de 3 ressources clés : un modèle génératif de langage (g1), un modèle génératif de texte en image (g2) et une liste organisée de concepts visuels (c).
Le pré-traitement comprend trois étapes :
(1) Utilisez (g1) pour synthétiser un ensemble complet de descriptions d'images T, qui couvrent divers concepts visuels en C
(2) Pour Pour chacun ; titre dans T, plusieurs images sont générées à l'aide de (g2), générant finalement un vaste ensemble de données d'images synthétiques X
(3) est entraîné sur X pour obtenir un encodeur de représentation visuelle f ;
Ensuite, utilisez lama-27b et Stable Diffusion 1.5 comme (g1) et (g2) respectivement en raison de sa vitesse d'inférence rapide.
Descriptions synthétiques
Afin d'exploiter la puissance de puissants modèles texte-image pour générer de grands ensembles de données d'images d'entraînement, nous avons d'abord besoin d'un ensemble de descriptions qui non seulement décrivent avec précision les images, mais présentent également de la diversité. pour inclure un large éventail de concepts visuels.
En réponse, les auteurs ont développé une méthode évolutive pour créer un si grand ensemble de descriptions, en tirant parti des capacités d'apprentissage contextuel des grands modèles.
Ce qui suit montre trois exemples de modèles synthétiques.

Ce qui suit utilise Llama-2 pour générer des descriptions de contexte. Les chercheurs ont échantillonné au hasard trois exemples de contexte dans chaque exécution d'inférence.
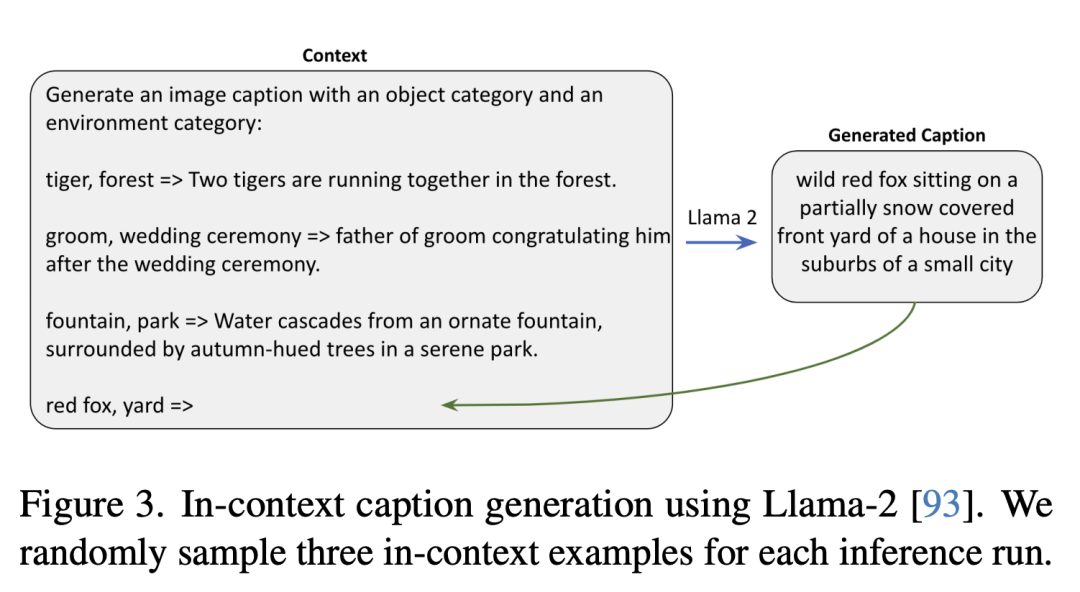
Images synthétiques
Pour chaque description textuelle, les chercheurs ont lancé le processus de rétrodiffusion avec différents bruits aléatoires, ce qui a donné lieu à diverses images.
Dans ce processus, le ratio CFG (classifier-free bootstrapping) est un facteur clé.
Plus l'échelle CFG est élevée, meilleure est la qualité des échantillons et la cohérence entre le texte et les images, tandis que plus l'échelle est basse, plus la diversité des échantillons est grande et meilleure est la cohérence entre les images basées sur le texte original conditionnel donné. distribution.

Apprentissage par représentation
Dans l'article, la méthode d'apprentissage par représentation est basée sur StableRep.
L'élément clé de la méthode proposée par les auteurs est la perte d'apprentissage par contraste multi-positif, qui fonctionne en alignant (dans l'espace d'intégration) les images générées à partir de la même description.
De plus, diverses techniques issues d'autres méthodes d'apprentissage auto-supervisées ont également été combinées dans la recherche.
Comparable au CLIP d'OpenAI
Dans l'évaluation expérimentale, les chercheurs ont d'abord mené des études d'ablation pour évaluer l'efficacité de diverses conceptions et modules au sein du pipeline, puis ont continué à augmenter la quantité de données synthétiques.
L'image ci-dessous est une comparaison de différentes stratégies de synthèse de descriptions.
Les chercheurs rapportent la précision de l'évaluation linéaire et la précision moyenne d'ImageNet sur 9 ensembles de données à grain fin. Chaque élément comprend ici 10 millions de descriptions et 4 images par description.
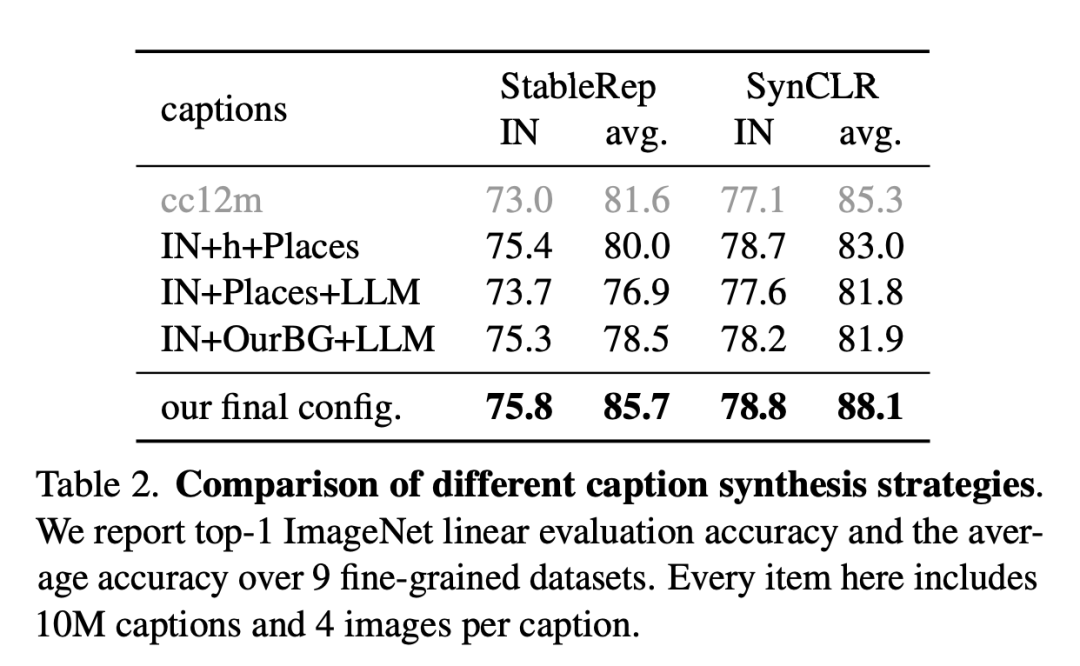
Le tableau suivant est une comparaison de l'évaluation linéaire ImageNet et de la classification à grain fin.
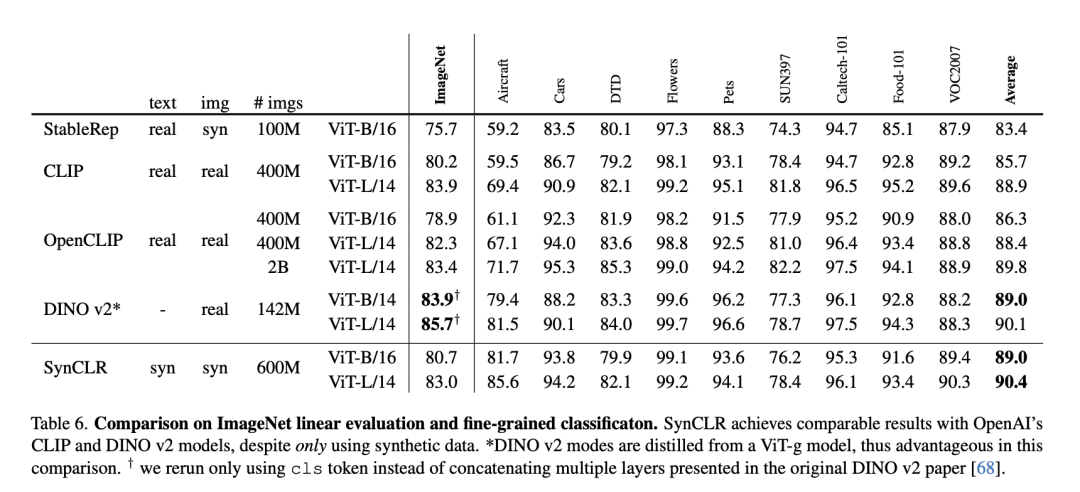
Malgré l'utilisation uniquement de données synthétiques, SynCLR a obtenu des résultats comparables à ceux des modèles CLIP et DINO v2 d'OpenAI.
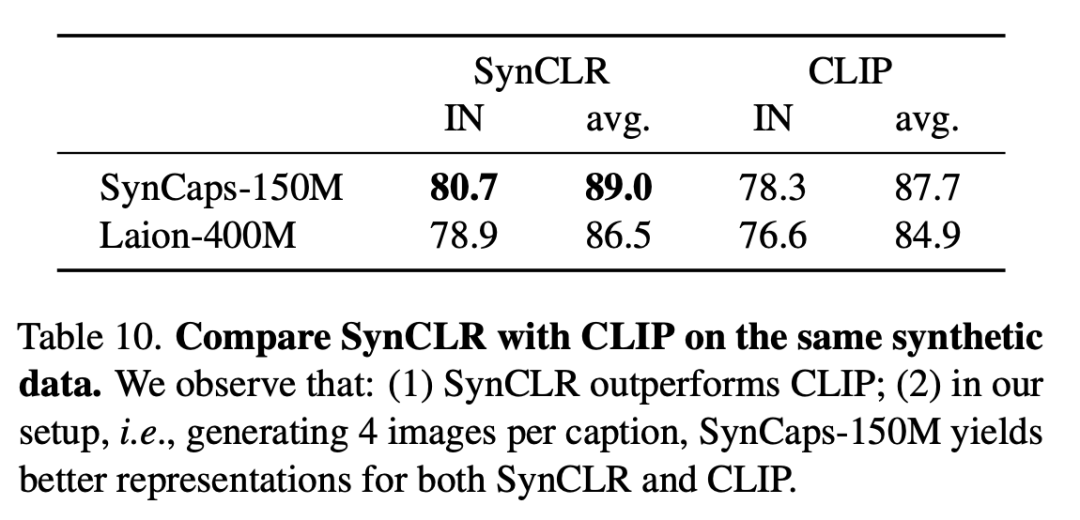
Le tableau suivant compare SynCLR et CLIP sur les mêmes données synthétiques. On voit que SynCLR est nettement meilleur que CLIP.
Spécifiquement configuré pour générer 4 images par titre, SynCaps-150M offre une meilleure représentation pour SynCLR et CLIP.
La visualisation PCA est la suivante. Suite à DINO v2, les chercheurs ont calculé la PCA entre les patchs du même ensemble d’images et les ont colorés en fonction de leurs 3 premiers composants.
Comparé à DINO v2, SynCLR est plus précis pour les dessins de voitures et d'avions, mais légèrement pire pour les dessins qui peuvent être dessinés.

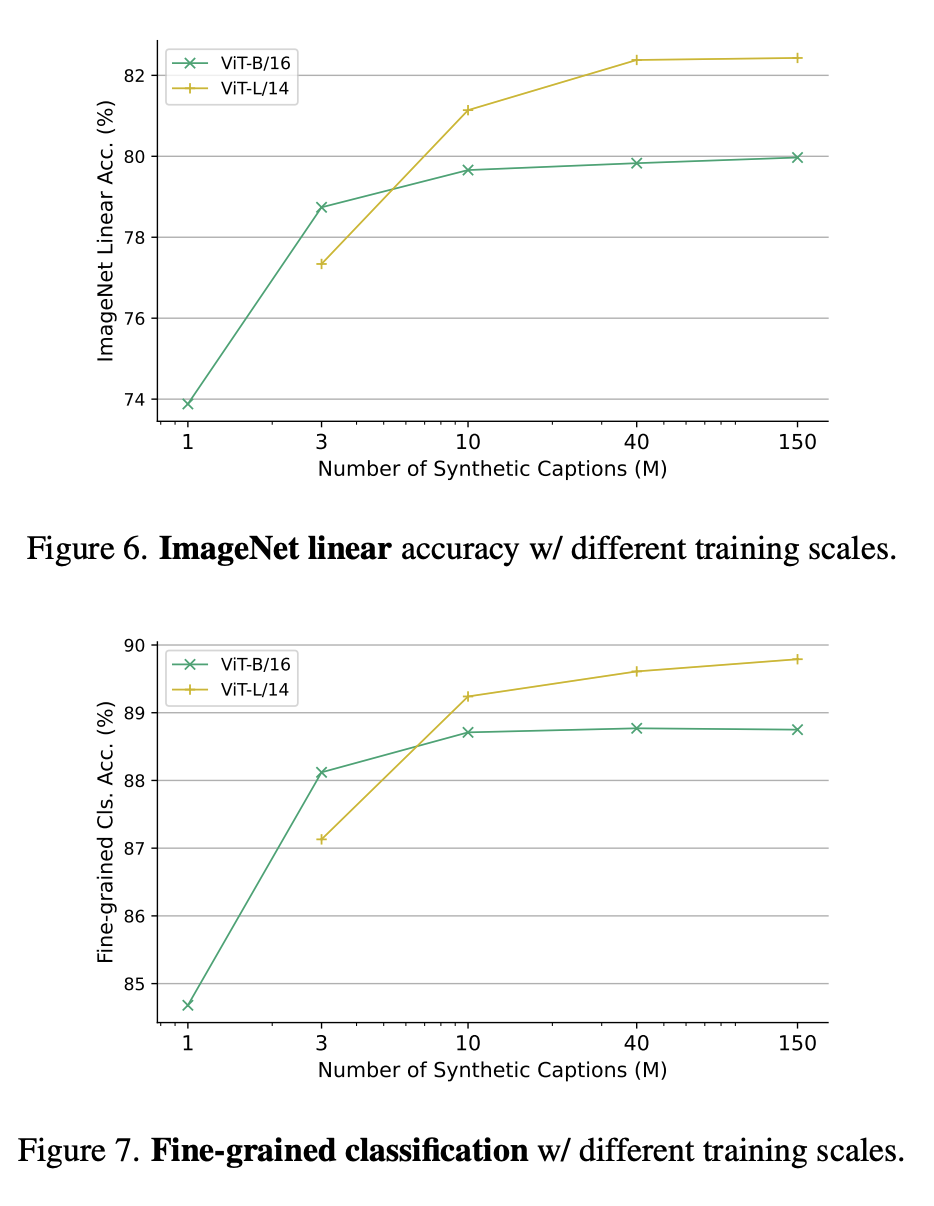
La figure 6 et la figure 7 montrent respectivement la précision linéaire d'ImageNet sous différentes échelles de formation et la classification fine sous différentes échelles de paramètres de formation.
Pourquoi apprendre des modèles génératifs ?
Une raison impérieuse est que les modèles génératifs peuvent fonctionner sur des centaines d'ensembles de données simultanément, offrant ainsi un moyen pratique et efficace de conserver les données d'entraînement.
En résumé, le dernier article étudie un nouveau paradigme d'apprentissage des représentations visuelles : l'apprentissage à partir de modèles génératifs.
Les représentations visuelles apprises par SynCLR sont comparables à celles apprises par les apprenants de pointe en représentation visuelle à usage général sans utiliser de données réelles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
