
 Périphériques technologiques
IA
Accélération d'inférence de modèle : les performances du processeur sont multipliées par 5. Apple utilise la mémoire flash pour accélérer l'inférence à grande échelle. Siri 2.0 est-il sur le point de faire ses débuts ?
Périphériques technologiques
IA
Accélération d'inférence de modèle : les performances du processeur sont multipliées par 5. Apple utilise la mémoire flash pour accélérer l'inférence à grande échelle. Siri 2.0 est-il sur le point de faire ses débuts ?
Accélération d'inférence de modèle : les performances du processeur sont multipliées par 5. Apple utilise la mémoire flash pour accélérer l'inférence à grande échelle. Siri 2.0 est-il sur le point de faire ses débuts ?

Ce nouveau travail d'Apple apportera une imagination illimitée à la possibilité d'ajouter de grands modèles aux futurs iPhones.
Ces dernières années, les grands modèles de langage (LLM) tels que GPT-3, OPT et PaLM ont démontré de solides performances dans un large éventail de tâches de traitement du langage naturel (NLP). Cependant, pour atteindre ces performances, il faut beaucoup de calculs et d'inférences de mémoire, car ces grands modèles de langage peuvent contenir des centaines de milliards, voire des milliards de paramètres, ce qui rend difficile le chargement et l'exécution efficace sur des appareils aux ressources limitées.
Actuellement, la solution standard consiste à charger l'intégralité du modèle dans la DRAM à des fins d'inférence, mais cela limite considérablement la taille maximale du modèle pouvant être exécuté. Par exemple, un modèle de 7 milliards de paramètres nécessite plus de 14 Go de mémoire pour charger les paramètres au format à virgule flottante demi-précision, ce qui dépasse les capacités de la plupart des appareils de pointe.
Afin de résoudre cette limitation, les chercheurs d'Apple ont proposé de stocker les paramètres du modèle dans la mémoire flash, qui est au moins un ordre de grandeur plus grand que la DRAM. Ensuite, lors de l'inférence, ils ont directement et intelligemment chargé les paramètres requis, éliminant ainsi le besoin d'insérer l'intégralité du modèle dans la DRAM.
Cette approche s'appuie sur des travaux récents qui montrent que LLM présente un degré élevé de parcimonie dans la couche de réseau feedforward (FFN), avec des modèles tels que OPT et Falcon atteignant une parcimonie supérieure à 90 %. Par conséquent, nous exploitons cette rareté pour charger sélectivement à partir de la mémoire flash uniquement les paramètres qui ont des entrées non nulles ou qui devraient avoir des sorties non nulles.

Adresse papier : https://arxiv.org/pdf/2312.11514.pdf
Plus précisément, les chercheurs ont discuté d'un modèle de coûts inspiré du matériel qui comprend la mémoire flash, la DRAM et les cœurs de calcul (CPU ou GPU). Ensuite, deux techniques complémentaires sont introduites pour minimiser le transfert de données et maximiser le débit flash :
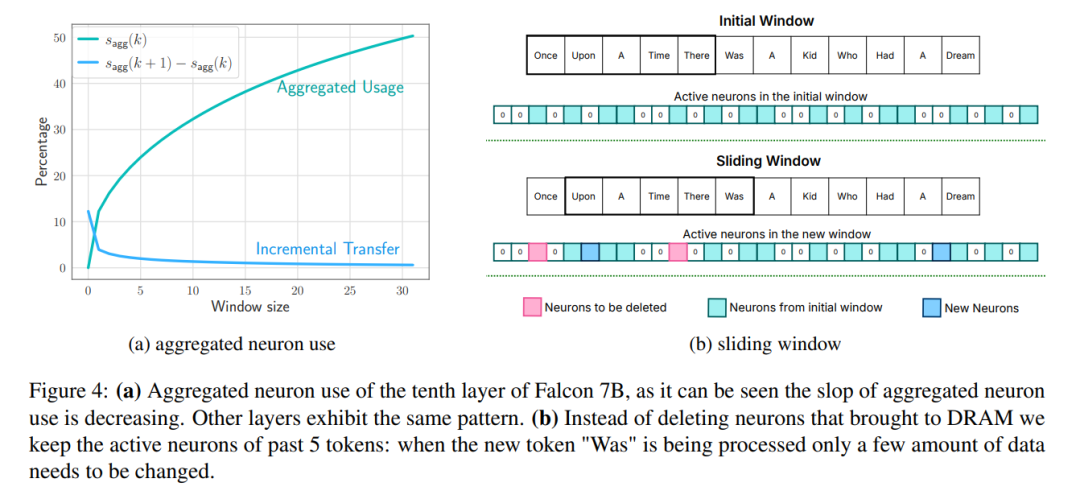
Windowing : charge uniquement les paramètres des premiers tags et réutilise l'activation du tag le plus récemment calculé. Cette approche de fenêtre coulissante réduit le nombre de requêtes d'E/S pour charger des poids ;
Regroupement de lignes et de lignes : stocke les lignes et les colonnes concaténées des couches de projection vers le haut et vers le bas pour lire des blocs contigus plus grands de mémoire flash. Cela augmentera le débit en lisant des blocs plus gros.
Pour réduire davantage le nombre de poids transférés du flash vers la DRAM, les chercheurs ont tenté de prédire la rareté du FFN et d'éviter de charger les paramètres de remise à zéro. En utilisant une combinaison de fenêtrage et de prédiction de parcimonie, seuls 2 % de la couche flash FFN sont chargés par requête d'inférence. Ils ont également proposé une pré-allocation de mémoire statique pour minimiser les transferts intra-DRAM et réduire la latence d'inférence.
Le modèle de coût de chargement flash de cet article établit un équilibre entre le chargement de meilleures données et la lecture de morceaux plus volumineux. Une stratégie Flash qui optimise ce modèle de coût et charge sélectivement les paramètres à la demande peut exécuter des modèles avec une capacité DRAM deux fois supérieure et améliorer les vitesses d'inférence de 4 à 5 fois et de 20 à 25 fois respectivement par rapport aux implémentations naïves dans les temps de processeurs et de GPU.
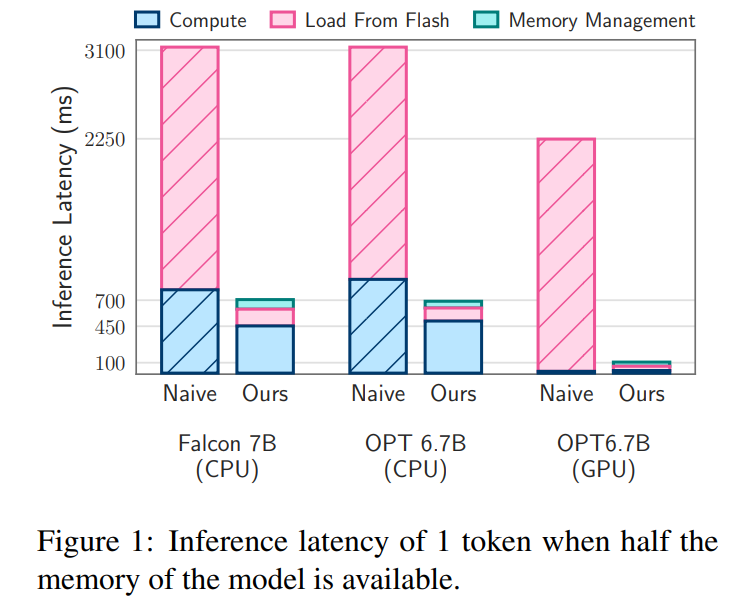
Certaines personnes ont commenté que ce travail rendra le développement iOS plus intéressant. "Inférence Flash et LLM" La figure 2a ci-dessous illustre ces différences.
Les implémentations d'inférence naïve qui reposent sur le flash NAND peuvent nécessiter le rechargement de l'intégralité du modèle pour chaque passage direct, ce qui est un processus fastidieux qui même la compression du modèle prend plusieurs secondes. De plus, le transfert de données de la DRAM vers la mémoire CPU ou GPU nécessite plus d'énergie.
Dans les scénarios où la DRAM est suffisante, le coût de chargement des données est réduit et le modèle peut résider dans la DRAM. Cependant, le chargement initial du modèle consomme toujours de l'énergie, surtout si le premier token nécessite un temps de réponse rapide. Notre méthode exploite la rareté d'activation dans LLM pour relever ces défis en lisant sélectivement les poids des modèles, réduisant ainsi les coûts de temps et d'énergie.
Réexprimé comme : Obtenez le taux de transfert de données
Les systèmes Flash fonctionnent mieux avec de nombreuses lectures séquentielles. Par exemple, l'Apple MacBook Pro M2 est équipé de 2 To de mémoire flash et, lors des tests de référence, la vitesse de lecture linéaire de 1 Go de fichiers non mis en cache dépassait 6 Go/s. Cependant, les lectures aléatoires plus petites ne peuvent pas atteindre des bandes passantes aussi élevées en raison de la nature multi-étapes de ces lectures, incluant le système d'exploitation, les pilotes, les processeurs de milieu de gamme et les contrôleurs flash. Chaque étape introduit une latence, qui a un impact plus important sur des vitesses de lecture plus faibles.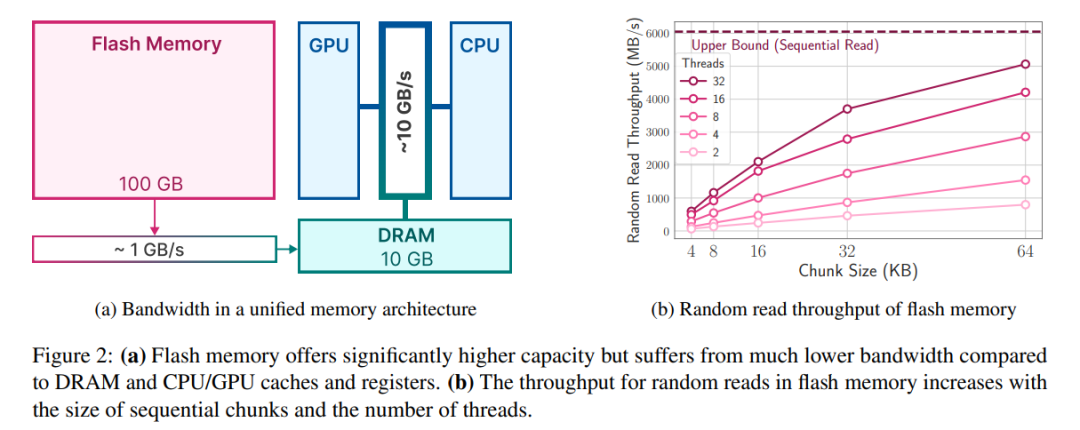 Pour contourner ces limitations, les chercheurs préconisent deux stratégies principales, qui peuvent être utilisées simultanément.
Pour contourner ces limitations, les chercheurs préconisent deux stratégies principales, qui peuvent être utilisées simultanément.
La première stratégie consiste à lire des blocs de données plus volumineux. Bien que l'augmentation du débit ne soit pas linéaire (des blocs de données plus volumineux nécessitent des temps de transfert plus longs), le retard des octets initiaux représente une plus petite proportion du temps total de requête, ce qui rend les lectures de données plus efficaces. La figure 2b illustre ce principe. Une observation contre-intuitive mais intéressante est que dans certains cas, lire plus de données que nécessaire (mais en morceaux plus gros) puis les supprimer est plus rapide que de lire uniquement ce qui est nécessaire mais en morceaux plus petits.
La deuxième stratégie consiste à exploiter le parallélisme inhérent de la pile de stockage et du contrôleur flash pour réaliser des lectures parallèles. Les résultats montrent qu'un débit adapté à l'inférence LLM clairsemée peut être obtenu à l'aide de lectures aléatoires multithread de 32 Ko ou plus sur du matériel standard.
La clé pour maximiser le débit réside dans la façon dont les poids sont stockés, car une disposition qui augmente la longueur moyenne des blocs peut augmenter considérablement la bande passante. Dans certains cas, il peut être avantageux de lire puis de supprimer les données excédentaires, plutôt que de diviser les données en morceaux plus petits et moins efficaces.
Chargement flash
Inspirés par les défis ci-dessus, les chercheurs ont proposé une méthode pour optimiser le volume de transfert de données et améliorer le taux de transfert de données, qui peut s'exprimer comme suit : Obtenir un taux de transfert de données pour améliorer considérablement la vitesse d'inférence. Cette section aborde les défis liés à la réalisation d'inférences sur des appareils où la mémoire de calcul disponible est beaucoup plus petite que la taille du modèle.
L'analyse de ce défi nécessite de stocker les poids complets du modèle dans la mémoire flash. La principale mesure utilisée par les chercheurs pour évaluer diverses stratégies de chargement flash est la latence, qui est divisée en trois éléments différents : le coût d'E/S nécessaire à l'exécution du chargement flash, la surcharge de mémoire liée à la gestion des données nouvellement chargées et le coût de calcul du chargement flash. opération d’inférence.
Apple divise les solutions permettant de réduire la latence sous contraintes de mémoire en trois domaines stratégiques, chacun ciblant un aspect spécifique de la latence :
1 Réduction de la charge de données : vise à réduire la latence en chargeant moins de latence de données associée aux opérations d'E/S flash.
2. Optimiser la taille des blocs de données : Améliorez le débit du flash en augmentant la taille des blocs de données chargés, réduisant ainsi la latence.
Voici la stratégie utilisée par les chercheurs pour augmenter la taille des blocs de données afin d'améliorer l'efficacité de la lecture flash :
Regroupement de colonnes et de lignes
Regroupement basé sur la co-activation
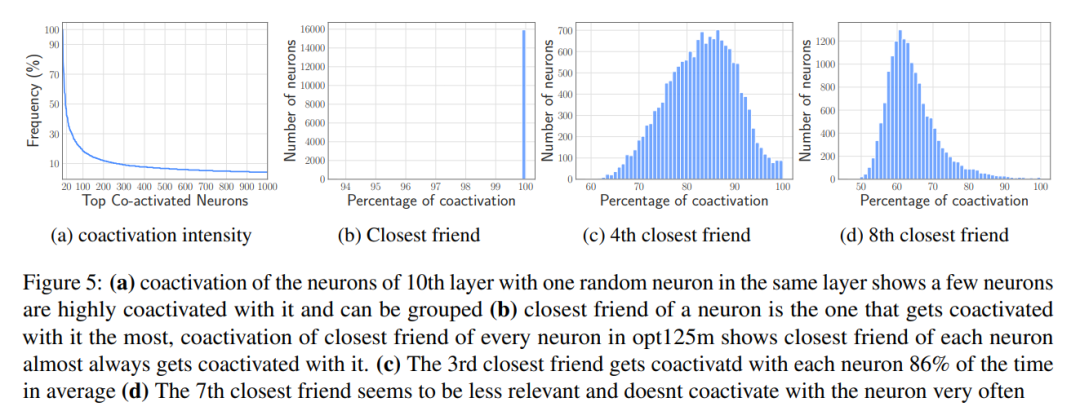
3. Gestion efficace données chargées : simplifiez la gestion des données une fois qu'elles sont chargées en mémoire, en minimisant les frais généraux.
Bien que le transfert de données en DRAM soit plus efficace que l'accès à la mémoire flash, il engendre un coût non négligeable. Lors de l’introduction de données pour de nouveaux neurones, la réaffectation de matrices et l’ajout de nouvelles matrices peuvent entraîner une surcharge importante en raison de la nécessité de réécrire les données neuronales existantes dans la DRAM. Cela s’avère particulièrement coûteux lorsqu’une grande partie (~ 25 %) du réseau feedforward (FFN) de la DRAM doit être réécrite.
Afin de résoudre ce problème, les chercheurs ont adopté une autre stratégie de gestion de la mémoire. Cette stratégie implique de pré-allouer toute la mémoire nécessaire et d'établir les structures de données correspondantes pour une gestion efficace. Comme le montre la figure 6, la structure des données comprend des éléments tels que des pointeurs, des matrices, des décalages, des nombres utilisés et last_k_active
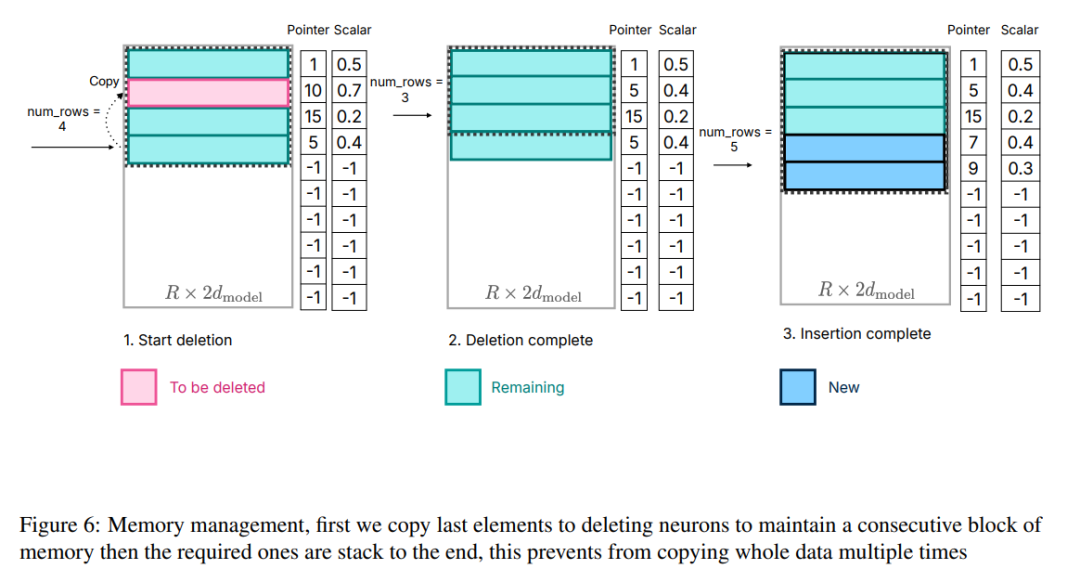
Figure 6 : Gestion de la mémoire, copiez d'abord le dernier élément dans le neurone de suppression pour conserver la continuité du bloc de mémoire, puis en empilant les éléments requis jusqu'à la fin, ce qui évite de copier plusieurs fois l'intégralité des données.
Il convient de noter que l'accent n'est pas mis sur le processus de calcul, car il n'a rien à voir avec le travail de base de cet article. Ce partitionnement permet aux chercheurs de se concentrer sur l'optimisation de l'interaction flash et de la gestion de la mémoire afin d'obtenir une inférence efficace sur les appareils à mémoire limitée
Réécriture des résultats expérimentaux requise
Résultats du modèle OPT 6.7B
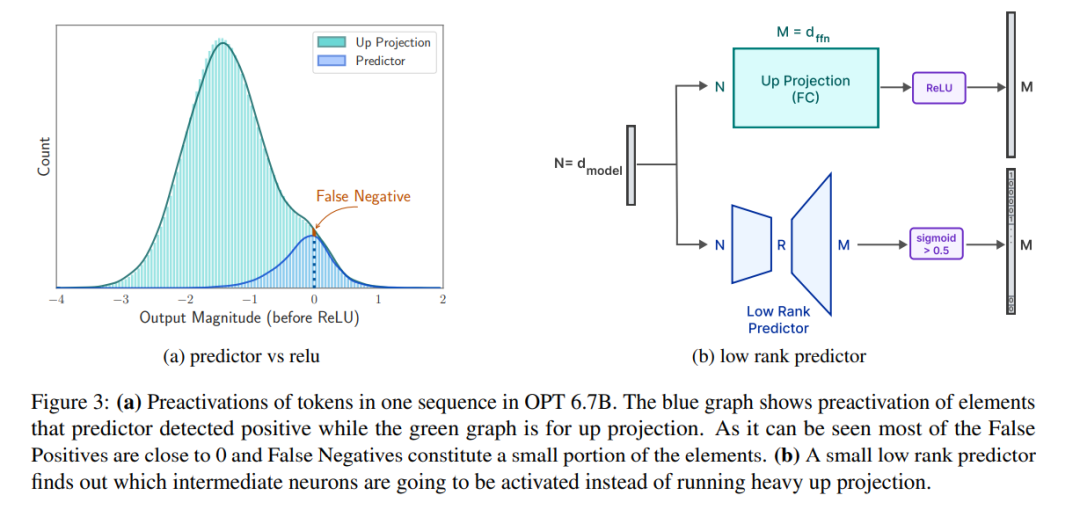
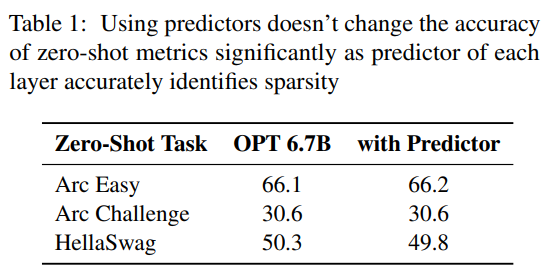
prédicteur. Comme le montre la figure 3a, notre prédicteur peut identifier avec précision la plupart des neurones activés, mais identifie parfois à tort les neurones non activés avec des valeurs proches de zéro. Il convient de noter qu'une fois ces neurones faussement négatifs avec des valeurs proches de zéro éliminés, le résultat final ne sera pas modifié de manière significative. De plus, comme le montre le tableau 1, ce niveau de précision de prédiction n'affecte pas négativement les performances du modèle sur la tâche zéro tir.
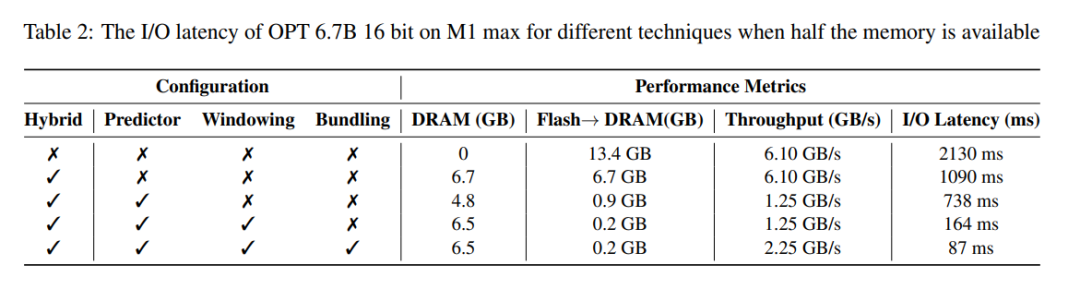
Analyse de latence. Lorsque la taille de la fenêtre est de 5, chaque jeton doit accéder à 2,4 % des neurones du réseau à réaction (FFN). Pour le modèle 32 bits, la taille de bloc par lecture est de 2dmodel × 4 octets = 32 Ko, car cela implique une concaténation de lignes et de colonnes. Sur le M1 Max, la latence de chargement flash par jeton est de 125 millisecondes, et la latence de gestion de la mémoire (y compris la suppression et l'ajout de neurones) est de 65 millisecondes. Par conséquent, la latence totale liée à la mémoire est inférieure à 190 millisecondes par jeton (voir Figure 1). En comparaison, l’approche de base nécessite le chargement de 13,4 Go de données à 6,1 Go/s, ce qui entraîne une latence d’environ 2 330 millisecondes par jeton. Notre méthode est donc grandement améliorée par rapport à la méthode de base.
Pour le modèle 16 bits sur une machine GPU, le temps de chargement du flash est réduit à 40,5 ms et le temps de gestion de la mémoire est à 40 ms, avec une légère augmentation due à la surcharge supplémentaire liée au transfert de données du CPU vers le GPU. Malgré cela, le temps d'E/S de la méthode de base est toujours supérieur à 2 000 ms.
Le tableau 2 fournit une comparaison détaillée de l'impact sur les performances de chaque méthode.
Résultats du modèle Falcon 7B
Analyse de latence. En utilisant une taille de fenêtre de 4 dans notre modèle, chaque jeton doit accéder à 3,1 % des neurones du réseau à réaction (FFN). Dans le modèle 32 bits, cela équivaut à une taille de bloc de 35,5 Ko par lecture (calculée comme modèle 2d × 4 octets). Sur un appareil M1 Max, le chargement flash de ces données prend environ 161 millisecondes, et le processus de gestion de la mémoire ajoute 90 millisecondes supplémentaires, de sorte que la latence totale par jeton est de 250 millisecondes. En comparaison, avec une latence de base d’environ 2 330 millisecondes, notre méthode est environ 9 à 10 fois plus rapide.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
Il s'agit également d'une vidéo Tusheng, mais PaintsUndo a emprunté une voie différente. L'auteur de ControlNet, LvminZhang, a recommencé à vivre ! Cette fois, je vise le domaine de la peinture. Le nouveau projet PaintsUndo a reçu 1,4kstar (toujours en hausse folle) peu de temps après son lancement. Adresse du projet : https://github.com/lllyasviel/Paints-UNDO Grâce à ce projet, l'utilisateur saisit une image statique et PaintsUndo peut automatiquement vous aider à générer une vidéo de l'ensemble du processus de peinture, du brouillon de ligne au suivi du produit fini. . Pendant le processus de dessin, les changements de lignes sont étonnants. Le résultat vidéo final est très similaire à l’image originale : jetons un coup d’œil à un dessin complet.
 Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Dans le processus de développement de l'intelligence artificielle, le contrôle et le guidage des grands modèles de langage (LLM) ont toujours été l'un des principaux défis, visant à garantir que ces modèles sont à la fois puissant et sûr au service de la société humaine. Les premiers efforts se sont concentrés sur les méthodes d’apprentissage par renforcement par feedback humain (RL
 En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Les auteurs de cet article font tous partie de l'équipe de l'enseignant Zhang Lingming de l'Université de l'Illinois à Urbana-Champaign (UIUC), notamment : Steven Code repair ; doctorant en quatrième année, chercheur
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
Montrez la chaîne causale à LLM et il pourra apprendre les axiomes. L'IA aide déjà les mathématiciens et les scientifiques à mener des recherches. Par exemple, le célèbre mathématicien Terence Tao a partagé à plusieurs reprises son expérience de recherche et d'exploration à l'aide d'outils d'IA tels que GPT. Pour que l’IA soit compétitive dans ces domaines, des capacités de raisonnement causal solides et fiables sont essentielles. La recherche présentée dans cet article a révélé qu'un modèle Transformer formé sur la démonstration de l'axiome de transitivité causale sur de petits graphes peut se généraliser à l'axiome de transitivité sur de grands graphes. En d’autres termes, si le Transformateur apprend à effectuer un raisonnement causal simple, il peut être utilisé pour un raisonnement causal plus complexe. Le cadre de formation axiomatique proposé par l'équipe est un nouveau paradigme pour l'apprentissage du raisonnement causal basé sur des données passives, avec uniquement des démonstrations.
 Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Récemment, l’hypothèse de Riemann, connue comme l’un des sept problèmes majeurs du millénaire, a réalisé une nouvelle avancée. L'hypothèse de Riemann est un problème mathématique non résolu très important, lié aux propriétés précises de la distribution des nombres premiers (les nombres premiers sont les nombres qui ne sont divisibles que par 1 et par eux-mêmes, et jouent un rôle fondamental dans la théorie des nombres). Dans la littérature mathématique actuelle, il existe plus d'un millier de propositions mathématiques basées sur l'établissement de l'hypothèse de Riemann (ou sa forme généralisée). En d’autres termes, une fois que l’hypothèse de Riemann et sa forme généralisée seront prouvées, ces plus d’un millier de propositions seront établies sous forme de théorèmes, qui auront un impact profond sur le domaine des mathématiques et si l’hypothèse de Riemann s’avère fausse, alors parmi eux ; ces propositions qui en font partie perdront également de leur efficacité. Une nouvelle percée vient du professeur de mathématiques du MIT, Larry Guth, et de l'Université d'Oxford
 Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
acclamations! Qu’est-ce que ça fait lorsqu’une discussion sur papier se résume à des mots ? Récemment, des étudiants de l'Université de Stanford ont créé alphaXiv, un forum de discussion ouvert pour les articles arXiv qui permet de publier des questions et des commentaires directement sur n'importe quel article arXiv. Lien du site Web : https://alphaxiv.org/ En fait, il n'est pas nécessaire de visiter spécifiquement ce site Web. Il suffit de remplacer arXiv dans n'importe quelle URL par alphaXiv pour ouvrir directement l'article correspondant sur le forum alphaXiv : vous pouvez localiser avec précision les paragraphes dans. l'article, Phrase : dans la zone de discussion sur la droite, les utilisateurs peuvent poser des questions à l'auteur sur les idées et les détails de l'article. Par exemple, ils peuvent également commenter le contenu de l'article, tels que : "Donné à".
 Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
Jul 23, 2024 pm 02:05 PM
Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
Jul 23, 2024 pm 02:05 PM
Actuellement, les modèles linguistiques autorégressifs à grande échelle utilisant le prochain paradigme de prédiction de jetons sont devenus populaires partout dans le monde. Dans le même temps, un grand nombre d'images et de vidéos synthétiques sur Internet nous ont déjà montré la puissance des modèles de diffusion. Récemment, une équipe de recherche de MITCSAIL (dont Chen Boyuan, doctorant au MIT) a intégré avec succès les puissantes capacités du modèle de diffusion en séquence complète et du prochain modèle de jeton, et a proposé un paradigme de formation et d'échantillonnage : le forçage de diffusion (DF ). Titre de l'article : DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Adresse de l'article : https://
