

Il existe désormais un nouveau modèle de génération d'images conçu par Google, qui permet de dessiner le chat de la figure 1 dans le style de la figure 2 et de lui mettre un chapeau. Ce modèle utilise une technologie de réglage fin des instructions pour générer avec précision de nouvelles images basées sur des instructions textuelles et plusieurs images de référence. L'effet est très bon, comparable à celui d'un maître PS vous aidant personnellement à créer une image.

Lors de l'utilisation de grands modèles de langage (LLM), nous avons réalisé l'importance de peaufiner l'enseignement. Avec un réglage approprié des instructions, LLM peut effectuer diverses tâches, telles que composer de la poésie, écrire du code, rédiger des scripts, contribuer à la recherche scientifique et même diriger la gestion des investissements.
Maintenant que les grands modèles sont entrés dans l’ère du multimodal, la mise au point pédagogique est-elle toujours efficace ? Par exemple, pouvons-nous affiner le contrôle de la génération d’images grâce à des instructions multimodales ? Contrairement à la génération de langage, la génération d’images implique dès le départ la multimodalité. Pouvons-nous effectivement permettre aux modèles d’appréhender la complexité de la multimodalité ?
Afin de résoudre ce problème, Google DeepMind et Google Research ont proposé une méthode d'instruction multimodale pour réaliser la génération d'images. Cette méthode entrelace des informations provenant de différentes modalités pour exprimer les conditions de génération d'images (exemple illustré dans le panneau de gauche de la figure 1).
Les instructions multimodales peuvent améliorer les instructions linguistiques. Par exemple, les utilisateurs peuvent spécifier le style de l'image de référence pour générer un modèle pour restituer l'image. Cette interface interactive intuitive permet de définir efficacement des conditions multimodales pour les tâches de génération d'images.
Sur la base de cette idée, l'équipe a créé un modèle de génération d'images d'instructions multimodales : Instruct-Imagen.

Adresse papier : https://arxiv.org/abs/2401.01952

Le modèle utilise une méthode de formation en deux étapes : améliorez d'abord la capacité du modèle à gérer des instructions multimodales, puis suivez fidèlement Intention d'utilisateur multimodale.
Dans la première phase, l'équipe a adopté un modèle texte-image pré-entraîné chargé de traiter des entrées multimodales supplémentaires ; puis de l'affiner afin qu'il puisse répondre avec précision aux instructions multimodales. Plus précisément, le modèle pré-entraîné qu'ils ont utilisé était un modèle de diffusion et augmenté d'un contexte similaire (image, texte) tiré d'un corpus à l'échelle du réseau (image, texte).
Dans la deuxième phase, l'équipe a affiné le modèle sur une variété de tâches de génération d'images, chacune étant associée à des instructions multimodales correspondantes - ces instructions incluaient les éléments clés des tâches respectives. Après les étapes ci-dessus, le modèle Instruct-Imagen résultant peut gérer très habilement l'entrée de fusion de plusieurs modalités (telles que des croquis et des styles visuels décrits avec des instructions textuelles), afin de pouvoir générer des images qui s'adaptent avec précision au contexte et sont suffisamment lumineuses.
Comme le montre la figure 1, Instruct-Imagen fonctionne extrêmement bien, étant capable de comprendre des instructions multimodales complexes et de générer des images qui suivent fidèlement les intentions humaines, même en gérant des combinaisons d'instructions qui n'ont jamais été vues auparavant.

Les commentaires humains montrent que dans de nombreux cas, Instruct-Imagen non seulement correspond aux performances de modèles spécifiques à des tâches sur les tâches correspondantes, mais les surpasse même. De plus, Instruct-Imagen présente également de fortes capacités de généralisation et peut être utilisé pour des tâches de génération d'images invisibles et plus complexes.
Instructions multimodales pour la génération
Le modèle pré-entraîné utilisé par l'équipe est un modèle de diffusion et l'utilisateur peut définir des conditions de saisie pour celui-ci. Veuillez vous référer à l'article original pour plus de détails.
Pour les instructions multimodales, afin d'assurer la polyvalence et la capacité de généralisation, l'équipe a proposé un format d'instruction multimodale unifié, dans lequel le rôle du langage est d'énoncer clairement le but de la tâche et les conditions multimodales. sont utilisées comme informations de référence.
Ce format de commande nouvellement proposé contient deux composants clés : (1) Commande de texte de charge utile, dont le rôle est de décrire l'objectif de la tâche en détail et de donner des informations d'identification de référence, telles que [réf# ?]. (2) Contexte multimodal avec jumelé (logo + texte, image). Le modèle utilise ensuite un modèle de compréhension des instructions partagé pour gérer les instructions textuelles et les contextes multimodaux ; la modalité spécifique du contexte n'est pas limitée ici.
La figure 2 montre comment ce format peut représenter diverses tâches de génération précédente à travers trois exemples, ce qui montre que ce format peut être compatible avec les tâches de génération d'images précédentes. Plus important encore, le langage est flexible, de sorte que les instructions multimodales peuvent être étendues à de nouvelles tâches sans aucune conception particulière pour les modalités et les tâches.

Instruct-Imagen
Instruct-Imagen est basé sur des instructions multimodales. Sur cette base, l'équipe a conçu une architecture de modèle basée sur un modèle de diffusion texte-image pré-entraîné, à savoir le modèle de diffusion en cascade, afin qu'elle puisse adopter pleinement les conditions d'instruction multimodale d'entrée.
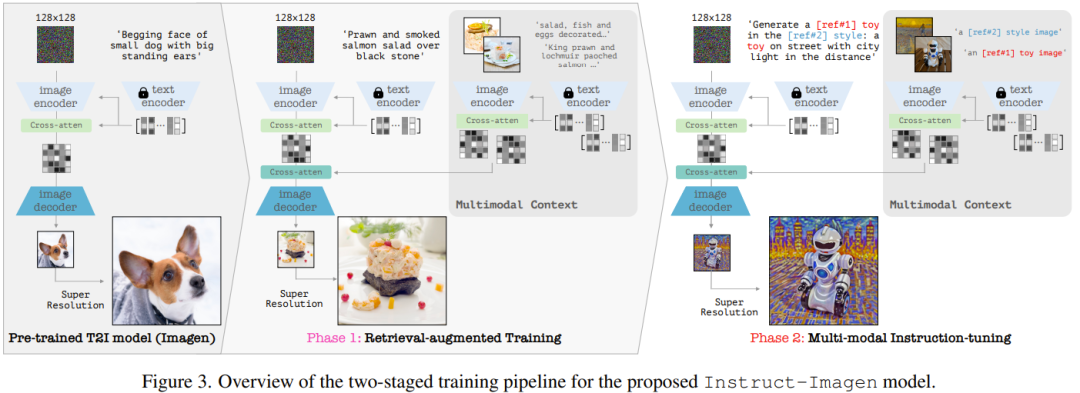
Plus précisément, ils ont utilisé une variante d'Imagen, voir l'article "Modèles de diffusion photoréalistes de texte à image avec une compréhension approfondie du langage", et pré-entraînés sur la base de leurs sources de données internes. Son modèle complet contient deux sous-composants : (1) un composant texte-image, dont la tâche est de générer des images de résolution 128 × 128 en utilisant uniquement des invites de texte, (2) un modèle de super-résolution conditionnelle de texte, qui peut convertir une résolution de 128 ; images dans la mise à niveau vers la résolution 1024.
En ce qui concerne le codage des instructions multimodales, voir la figure 3 (à droite), qui montre le flux de données des instructions multimodales de codage Instruct-Imagen.
Formation Instruct-Imagen avec une méthode en deux étapes
Le processus de formation d'Instruct-Imagen est divisé en deux étapes.
La première étape est la formation texte-image améliorée par récupération, qui utilise les paires de voisins récupérés améliorés (image, texte) pour continuer la formation de la génération texte-image.
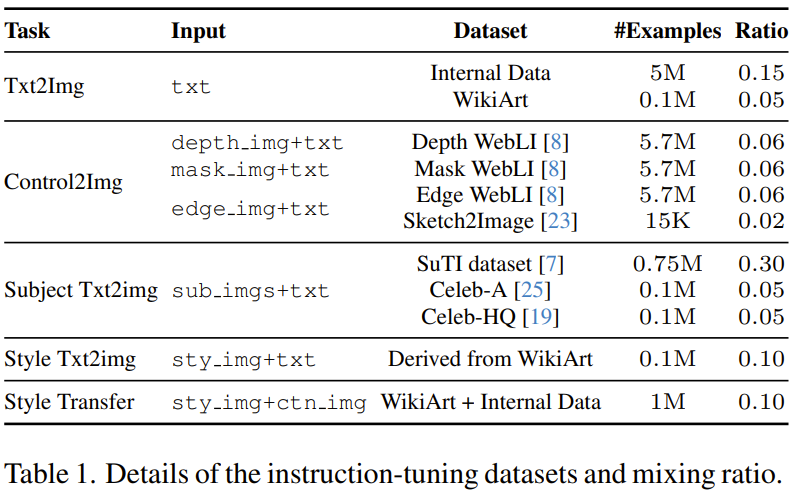
La deuxième étape consiste à affiner le modèle de sortie de la première étape, qui utilisera un mélange de diverses tâches de génération d'images, chacune étant associée à des instructions multimodales correspondantes. Plus précisément, l'équipe a utilisé 11 images réparties dans 5 catégories de tâches pour générer l'ensemble de données, voir le tableau 1.
Dans les deux étapes de formation, le modèle est optimisé de bout en bout.
Expériences
L'équipe a mené des évaluations expérimentales des méthodes et des modèles nouvellement proposés, et a mené une analyse approfondie de la conception et des modes de défaillance d'Instruct-Imagen.
Paramètres expérimentaux
L'équipe a évalué le modèle dans deux paramètres, à savoir l'évaluation des tâches dans le domaine et l'évaluation des tâches zéro, ce dernier paramètre étant plus difficile que le premier.
Principaux résultats
La figure 4 compare Instruct-Imagen avec la méthode de base et les méthodes précédentes, et les résultats montrent qu'elle est comparable aux méthodes précédentes en matière d'évaluation de domaine et d'évaluation à échantillon nul.
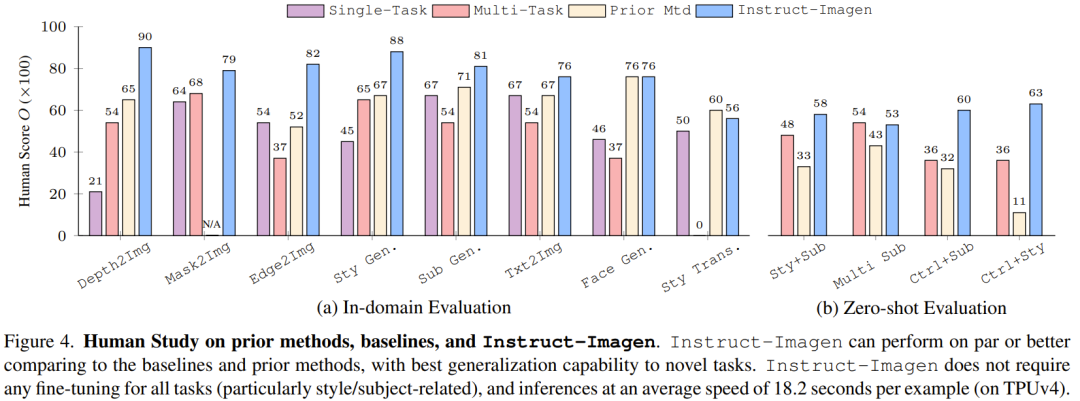
Cela montre que l'entraînement avec des instructions multimodales peut améliorer les performances du modèle sur les tâches avec des données d'entraînement limitées (telles que la génération de stylisation), tout en maintenant les performances sur les tâches riches en données (telles que la génération d'images de type photo). Sans formation pédagogique multimodale, les tests multitâches ont tendance à aboutir à une mauvaise qualité d’image et à un alignement du texte médiocre.
Par exemple, dans l'exemple de stylisation en contexte de la figure 5, le benchmark multitâche a du mal à distinguer les styles des objets, les objets sont donc reproduits dans les résultats générés. Pour des raisons similaires, il fonctionne également mal dans les tâches de transfert de style. Ces observations mettent en évidence l’intérêt d’affiner l’enseignement.
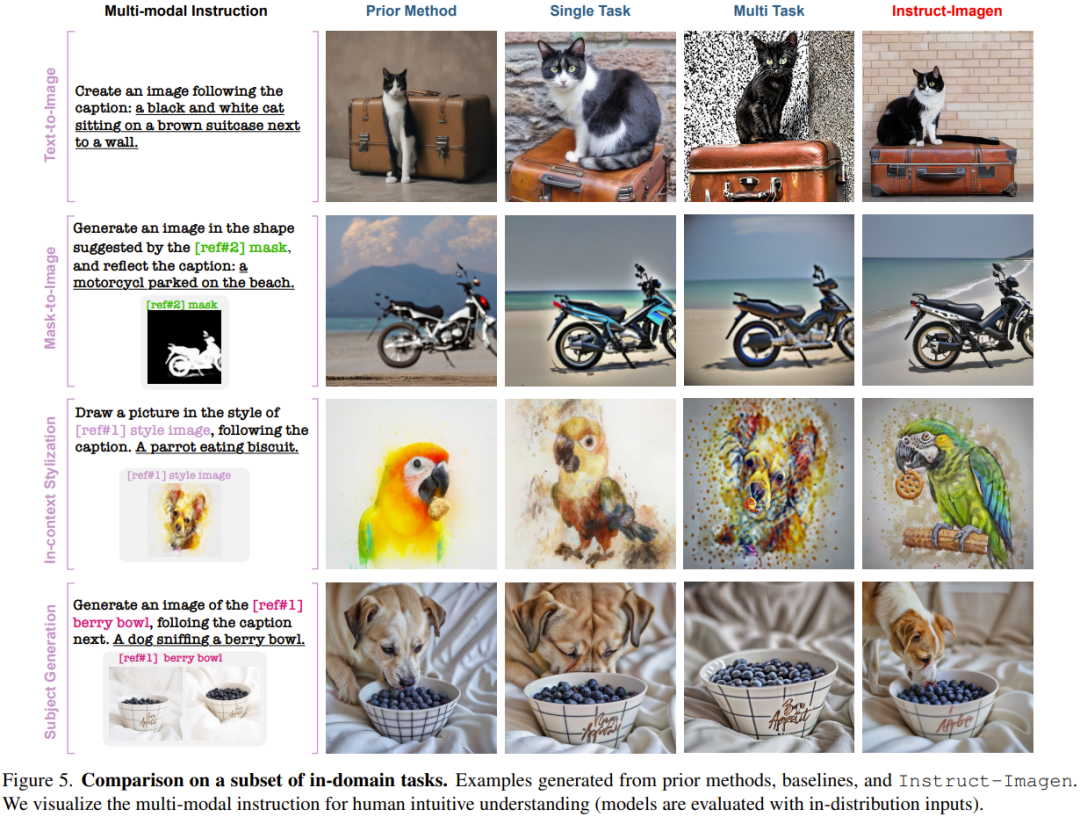
Contrairement aux méthodes ou formations actuelles qui reposent sur des tâches spécifiques, Instruct-Imagen peut gérer efficacement des tâches combinées (sans réglage fin, par exemple) en exploitant des instructions qui combinent les objectifs de différentes tâches et effectuent un raisonnement en contexte prend 18,2 secondes).
Comme le montre la figure 6, Instruct-Imagen surpasse toujours les autres modèles en termes de suivi des instructions et de qualité de sortie.

De plus, lorsqu'il existe plusieurs références dans un contexte multimodal, le modèle de base multitâche ne peut pas faire correspondre les instructions textuelles aux références, ce qui entraîne l'ignorance de certaines conditions multimodales. Ces résultats démontrent en outre l’efficacité du modèle nouvellement proposé.
Analyse du modèle et étude d'ablation
L'équipe a analysé les limites et les modes de défaillance du modèle.
Par exemple, l'équipe a découvert qu'Instruct-Imagen, optimisé, peut éditer des images. Comme le montre le tableau 2, en comparant l'inpainting SDXL précédent, l'Imagen affiné sur l'ensemble de données MagicBrush et l'Instruct-Imagen affiné, on peut constater que l'Instruct-Imagen affiné est nettement meilleur que l'Instruct-Imagen affiné. un spécialement conçu pour l’édition d’images basée sur un masque.
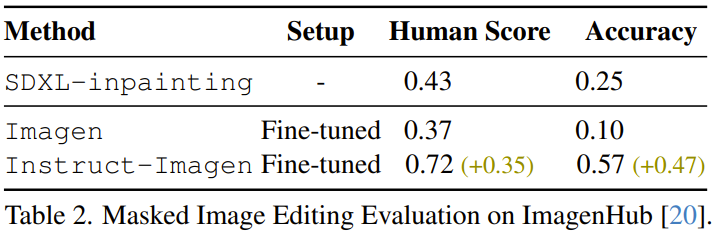
Cependant, l'Instruct-Imagen affiné produit des artefacts dans les images modifiées, en particulier la sortie haute résolution après l'étape de super-résolution, comme le montre la figure 7. Les chercheurs affirment que cela est dû au fait que le modèle n’a pas encore appris à copier avec précision les pixels directement à partir du contexte.

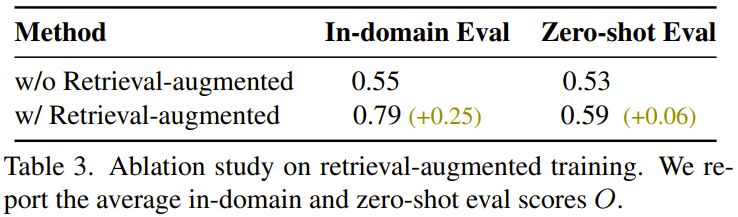
L'équipe a également constaté qu'un entraînement amélioré par la récupération contribuait à améliorer la capacité de généralisation, et les résultats sont présentés dans le tableau 3.
Concernant le mode d'échec d'Instruct-Imagen, les chercheurs ont constaté que lorsque les instructions multimodales sont plus complexes (au moins 3 conditions multimodales), Instruct-Imagen a du mal à générer des résultats conformes aux instructions. La figure 8 donne deux exemples.

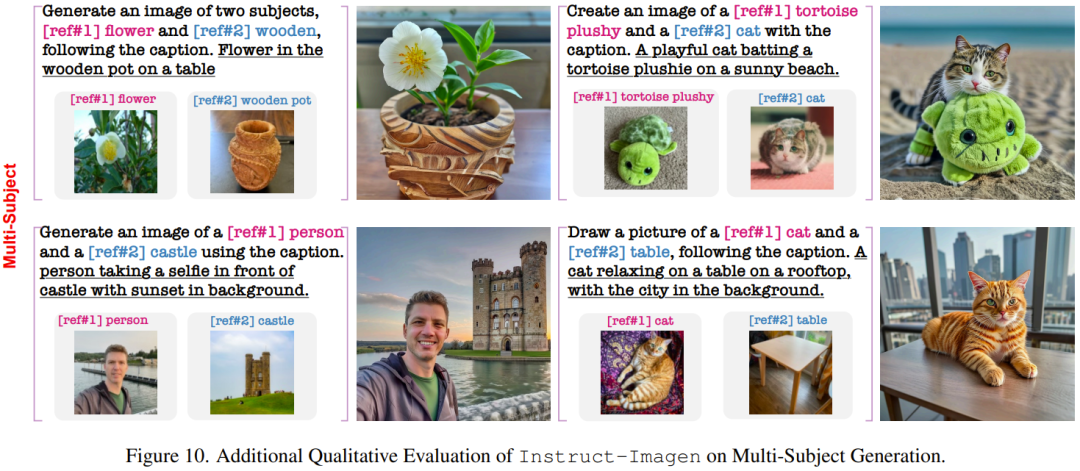
Ce qui suit montre quelques résultats sur des tâches complexes qui n'ont pas été vus lors de la formation.


L'équipe a également mené des études d'ablation pour prouver l'importance de ses composants de conception.
Cependant, pour des raisons de sécurité, Google n'a pas encore publié le code et l'API de cette recherche.
Veuillez vous référer au document original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment résoudre le problème que les CSS ne peuvent pas être chargés
Comment résoudre le problème que les CSS ne peuvent pas être chargés
 Dogecoin prix d'aujourd'hui
Dogecoin prix d'aujourd'hui
 Que comprend le stockage par cryptage des données ?
Que comprend le stockage par cryptage des données ?
 403solution interdite
403solution interdite
 Comment ralentir la vidéo sur Douyin
Comment ralentir la vidéo sur Douyin
 Comment utiliser les macros Excel
Comment utiliser les macros Excel
 Le rôle de l'interface VGA
Le rôle de l'interface VGA
 Comment créer un index bitmap dans MySQL
Comment créer un index bitmap dans MySQL
 À quel point le Dimensity 6020 est-il équivalent à Snapdragon ?
À quel point le Dimensity 6020 est-il équivalent à Snapdragon ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



