
 Périphériques technologiques
IA
Adaptateur I2V de la communauté SD : aucune configuration requise, plug and play, parfaitement compatible avec le plug-in vidéo Tusheng
Périphériques technologiques
IA
Adaptateur I2V de la communauté SD : aucune configuration requise, plug and play, parfaitement compatible avec le plug-in vidéo Tusheng
Adaptateur I2V de la communauté SD : aucune configuration requise, plug and play, parfaitement compatible avec le plug-in vidéo Tusheng

La tâche de génération d'image en vidéo (I2V) est un défi dans le domaine de la vision par ordinateur qui vise à convertir des images statiques en vidéos dynamiques. La difficulté de cette tâche est d'extraire et de générer des informations dynamiques dans la dimension temporelle à partir d'une seule image tout en conservant l'authenticité et la cohérence visuelle du contenu de l'image. Les méthodes I2V existantes nécessitent souvent des architectures de modèles complexes et de grandes quantités de données de formation pour atteindre cet objectif.
Récemment, un nouveau résultat de recherche « I2V-Adapter : A General Image-to-Video Adapter for Video Diffusion Models » dirigé par Kuaishou a été publié. Cette recherche introduit une méthode innovante de conversion image-vidéo et propose un module adaptateur léger, l'I2V-Adapter. Ce module adaptateur est capable de convertir des images statiques en vidéos dynamiques sans modifier la structure d'origine et les paramètres pré-entraînés des modèles de génération texte-vidéo (T2V) existants. Cette méthode a de larges perspectives d'application dans le domaine de la conversion d'image en vidéo et peut apporter davantage de possibilités à la création vidéo, à la communication médiatique et à d'autres domaines. La publication des résultats de la recherche revêt une grande importance pour promouvoir le développement de la technologie de l'image et de la vidéo et constitue un outil et une méthode efficaces pour les chercheurs dans des domaines connexes.

- Adresse papier : https://arxiv.org/pdf/2312.16693.pdf
- Page d'accueil du projet : https://i2v-adapter.github.io/index .html
- Adresse du code : https://github.com/I2V-Adapter/I2V-Adapter-repo
Par rapport aux méthodes existantes, I2V-Adapter a davantage de paramètres entraînables. D'énormes améliorations ont été réalisé, et le nombre de paramètres peut atteindre aussi bas que 22M, ce qui ne représente que 1% de la solution grand public Stable Video Diffusion. Dans le même temps, l'adaptateur est également compatible avec les modèles T2I personnalisés (tels que DreamBooth, Lora) et les outils de contrôle (tels que ControlNet) développés par la communauté Stable Diffusion. Grâce à des expériences, les chercheurs ont prouvé l'efficacité de l'I2V-Adapter pour générer du contenu vidéo de haute qualité, ouvrant ainsi de nouvelles possibilités d'applications créatives dans le domaine I2V.

Introduction à la méthode
Modélisation temporelle avec diffusion stable
Par rapport à la génération d'images, la génération vidéo est confrontée à un défi unique, à savoir modéliser la cohérence temporelle entre les images vidéo et le sexe. La plupart des méthodes actuelles sont basées sur des modèles T2I pré-entraînés, tels que Stable Diffusion et SDXL, en introduisant des modules de synchronisation pour modéliser les informations de synchronisation dans les vidéos. Inspiré d'AnimateDiff, un modèle initialement conçu pour les tâches T2V personnalisées, il modélise les informations de synchronisation en introduisant un module de synchronisation découplé du modèle T2I, et conserve la capacité du modèle T2I d'origine à générer des vidéos fluides. Par conséquent, les chercheurs pensent que le module temporel pré-entraîné peut être considéré comme une représentation temporelle universelle et peut être appliqué à d’autres scénarios de génération vidéo, tels que la génération I2V, sans aucun réglage précis. Par conséquent, les chercheurs ont directement utilisé le module de synchronisation AnimateDiff pré-entraîné et ont maintenu ses paramètres fixes.
Adaptateur pour les couches d'attention
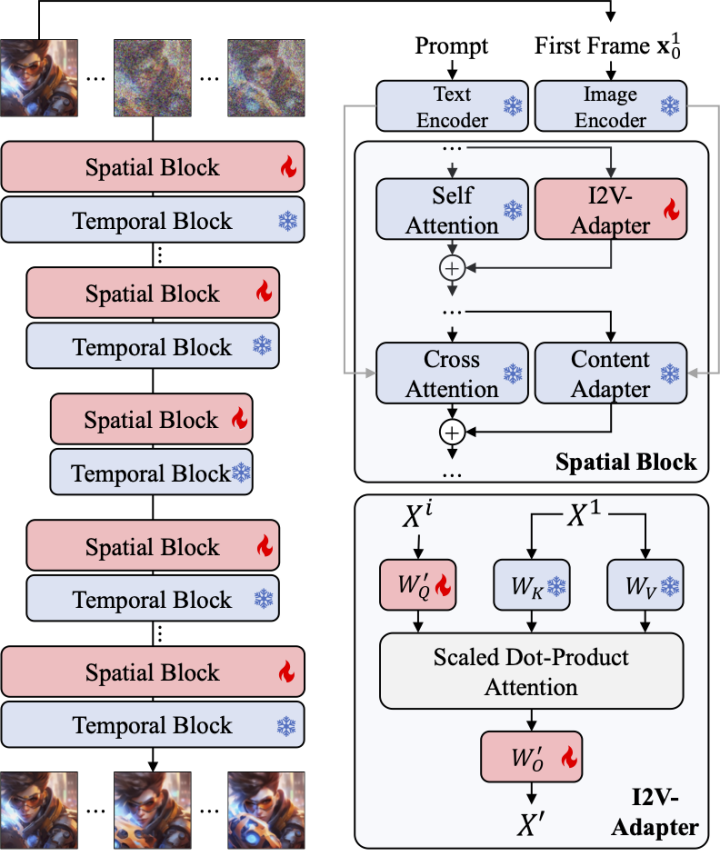
Un autre défi de la tâche I2V est de conserver les informations d'identification de l'image d'entrée. Il existe actuellement deux solutions principales : l'une consiste à utiliser un encodeur d'image pré-entraîné pour coder l'image d'entrée et à injecter les caractéristiques codées dans le modèle via un mécanisme d'attention croisée pour guider le processus de débruitage ; concaténés avec l'entrée bruyante dans la dimension du canal, puis introduits ensemble dans le réseau suivant. Cependant, la première méthode peut entraîner une modification de l'ID vidéo généré car il est difficile pour l'encodeur d'image de capturer les informations sous-jacentes, tandis que la seconde méthode nécessite souvent de modifier la structure et les paramètres du modèle T2I, ce qui entraîne des coûts de formation élevés et médiocres ; compatibilité.
Afin de résoudre les problèmes ci-dessus, les chercheurs ont proposé l'adaptateur I2V. Plus précisément, le chercheur entre l'image d'entrée et l'entrée bruitée dans le réseau en parallèle. Dans le bloc spatial du modèle, toutes les trames interrogeront en outre les informations de la première trame, c'est-à-dire que les caractéristiques clés et de valeur proviennent de la première trame sans bruit. , et la sortie Le résultat est ajouté à l'auto-attention du modèle d'origine. La matrice de mappage de sortie de ce module est initialisée avec des zéros et seules la matrice de mappage de sortie et la matrice de mappage de requêtes sont entraînées. Afin d'améliorer encore la compréhension du modèle des informations sémantiques de l'image d'entrée, les chercheurs ont introduit un adaptateur de contenu pré-entraîné (cet article utilise IP-Adapter [8]) pour injecter les caractéristiques sémantiques de l'image.
Frame Similarity Prior
Afin d'améliorer encore la stabilité des résultats générés, les chercheurs ont proposé une similarité inter-images avant de trouver un équilibre entre la stabilité et l'intensité du mouvement de la vidéo générée. L'hypothèse clé est qu'à un niveau de bruit gaussien relativement faible, la première image bruyante et les images suivantes bruyantes sont suffisamment proches, comme le montre la figure ci-dessous :
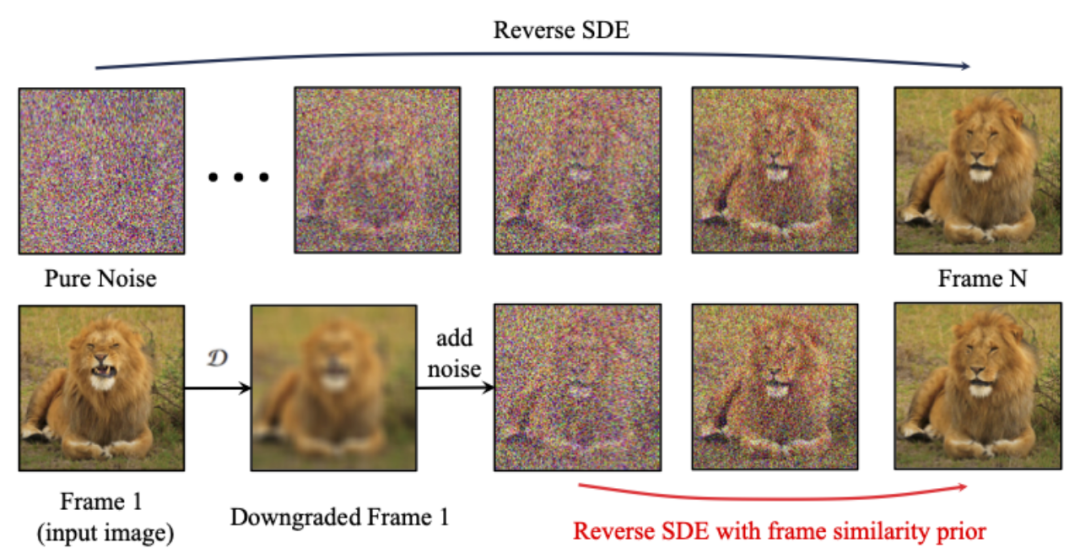
Ainsi, les chercheurs ont supposé que toutes les structures de trame étaient similaires. , et deviennent indiscernables après l'ajout d'une certaine quantité de bruit gaussien, de sorte que l'image d'entrée bruitée peut être utilisée comme entrée a priori pour les images suivantes. Afin d'éliminer le caractère trompeur des informations haute fréquence, les chercheurs ont également utilisé un opérateur de flou gaussien et un mélange de masques aléatoire. Plus précisément, l'opération est donnée par la formule suivante :

Résultats expérimentaux
Résultats quantitatifs
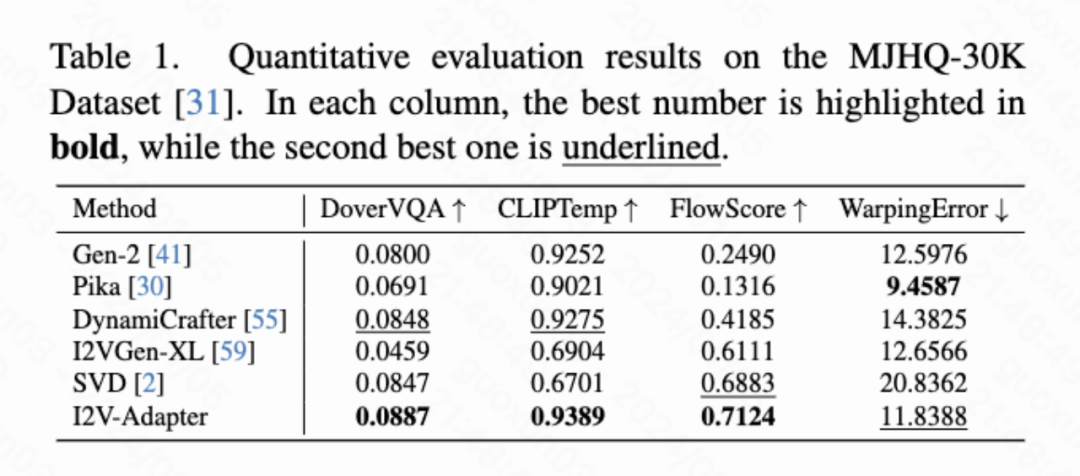
Cet article calcule quatre indicateurs quantitatifs, à savoir DoverVQA (score esthétique), CLIPTemp (premier Frame cohérence), FlowScore (amplitude de mouvement) et WarppingError (erreur de mouvement) sont utilisés pour évaluer la qualité de la vidéo générée. Le tableau 1 montre que l'adaptateur I2V a reçu le score esthétique le plus élevé et a également dépassé tous les schémas de comparaison en termes de cohérence de la première image. De plus, la vidéo générée par I2V-Adapter présente la plus grande amplitude de mouvement et une erreur de mouvement relativement faible, ce qui indique que ce modèle est capable de générer des vidéos plus dynamiques tout en conservant la précision du mouvement temporel.
Résultats qualitatifs
Animation d'image (gauche est l'entrée, droite est la sortie) :



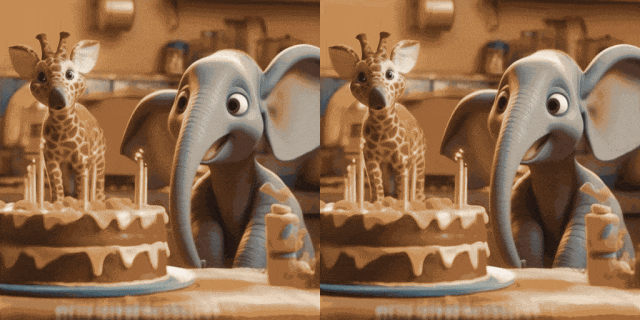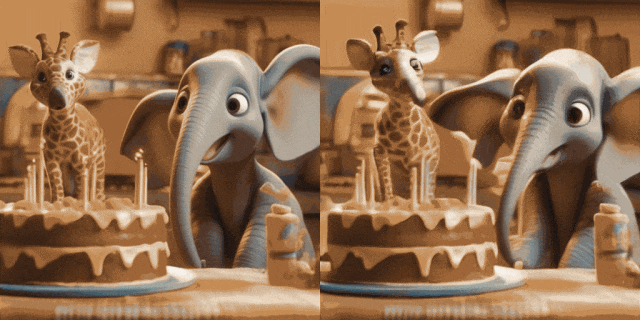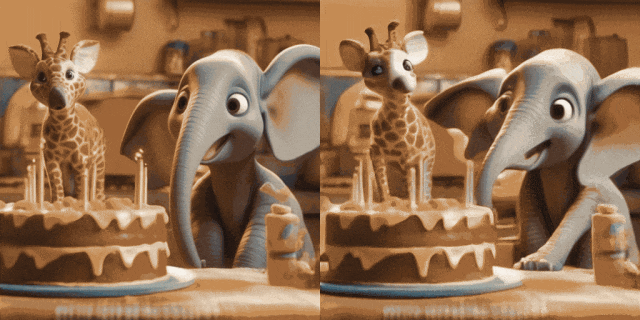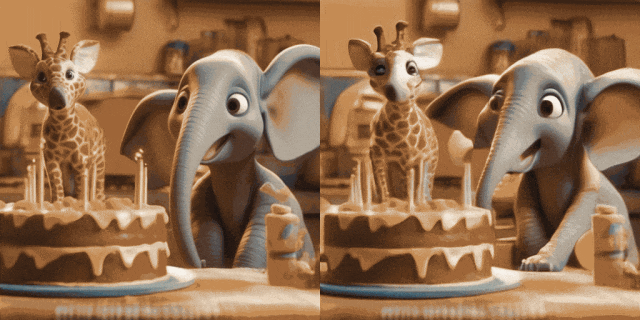
avec T2I personnalisés (sur le Entrée gauche, droite est la sortie) :




w/ ControlNet (gauche est l'entrée, droite est la sortie) :



Résumé
Cet article propose I2V-Adapter, un module léger plug-and-play pour les tâches de génération d'image en vidéo. Cette méthode maintient fixes les structures et les paramètres des blocs spatiaux et des blocs de mouvement du modèle T2V d'origine, entre la première image sans bruit et les images suivantes avec du bruit en parallèle, et permet à toutes les images d'interagir avec la première image sans bruit via le mécanisme d'attention. , produisez ainsi une vidéo temporellement cohérente et cohérente avec la première image. Les chercheurs ont démontré l’efficacité de cette méthode sur des tâches I2V à travers des expérimentations quantitatives et qualitatives. De plus, sa conception découplée permet à la solution d'être directement combinée avec des modules tels que DreamBooth, Lora et ControlNet, prouvant la compatibilité de la solution et favorisant la recherche sur la génération d'image en vidéo personnalisée et contrôlable.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1658
1658
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

 Où sont stockés les fichiers vidéo dans le cache du navigateur ?
Feb 19, 2024 pm 05:09 PM
Où sont stockés les fichiers vidéo dans le cache du navigateur ?
Feb 19, 2024 pm 05:09 PM
Dans quel dossier le navigateur met-il la vidéo en cache ? Lorsque nous utilisons le navigateur Internet quotidiennement, nous regardons souvent diverses vidéos en ligne, comme regarder des clips vidéo sur YouTube ou regarder des films sur Netflix. Ces vidéos seront mises en cache par le navigateur pendant le processus de chargement afin qu'elles puissent être chargées rapidement lors d'une nouvelle lecture ultérieure. La question est donc de savoir dans quel dossier ces vidéos mises en cache sont réellement stockées ? Différents navigateurs stockent les dossiers vidéo mis en cache à différents emplacements. Ci-dessous, nous présenterons plusieurs navigateurs courants et leurs
 Est-ce une infraction de publier des vidéos d'autres personnes sur Douyin ? Comment éditer des vidéos sans infraction ?
Mar 21, 2024 pm 05:57 PM
Est-ce une infraction de publier des vidéos d'autres personnes sur Douyin ? Comment éditer des vidéos sans infraction ?
Mar 21, 2024 pm 05:57 PM
Avec l'essor des plateformes de vidéos courtes, Douyin est devenu un élément indispensable de la vie quotidienne de chacun. Sur TikTok, nous pouvons voir des vidéos intéressantes du monde entier. Certaines personnes aiment publier les vidéos d’autres personnes, ce qui soulève une question : Douyin enfreint-il la publication de vidéos d’autres personnes ? Cet article abordera ce problème et vous expliquera comment éditer des vidéos sans infraction et comment éviter les problèmes d'infraction. 1. Cela porte-t-il atteinte à la publication par Douyin de vidéos d'autres personnes ? Selon les dispositions de la loi sur le droit d'auteur de mon pays, l'utilisation non autorisée des œuvres du titulaire du droit d'auteur sans l'autorisation du titulaire du droit d'auteur constitue une infraction. Par conséquent, publier des vidéos d’autres personnes sur Douyin sans l’autorisation de l’auteur original ou du titulaire des droits d’auteur constitue une infraction. 2. Comment monter une vidéo sans contrefaçon ? 1. Utilisation de contenu du domaine public ou sous licence : Public
 Comment supprimer le filigrane vidéo dans Wink
Feb 23, 2024 pm 07:22 PM
Comment supprimer le filigrane vidéo dans Wink
Feb 23, 2024 pm 07:22 PM
Comment supprimer les filigranes des vidéos dans Wink ? Il existe un outil pour supprimer les filigranes des vidéos dans winkAPP, mais la plupart des amis ne savent pas comment supprimer les filigranes des vidéos dans Wink. Voici ensuite l'image de la façon de supprimer les filigranes des vidéos dans Wink. apporté par l'éditeur Tutoriel texte, les utilisateurs intéressés viennent y jeter un oeil ! Comment supprimer le filigrane vidéo dans Wink 1. Ouvrez d'abord l'application Wink et sélectionnez la fonction [Supprimer le filigrane] dans la zone de la page d'accueil ; 2. Sélectionnez ensuite la vidéo dont vous souhaitez supprimer le filigrane dans l'album ; dans le coin supérieur droit après avoir édité la vidéo [√] ; 4. Enfin, cliquez sur [Imprimer en un clic] comme indiqué dans la figure ci-dessous, puis cliquez sur [Traiter].
 Comment publier les œuvres vidéo de Xiaohongshu ? À quoi dois-je faire attention lorsque je publie des vidéos ?
Mar 23, 2024 pm 08:50 PM
Comment publier les œuvres vidéo de Xiaohongshu ? À quoi dois-je faire attention lorsque je publie des vidéos ?
Mar 23, 2024 pm 08:50 PM
Avec l'essor des plateformes de vidéos courtes, Xiaohongshu est devenue une plateforme permettant à de nombreuses personnes de partager leur vie, de s'exprimer et de gagner du trafic. Sur cette plateforme, la publication d’œuvres vidéo est un moyen d’interaction très prisé. Alors, comment publier les œuvres vidéo de Xiaohongshu ? 1. Comment publier les œuvres vidéo de Xiaohongshu ? Tout d’abord, assurez-vous d’avoir un contenu vidéo prêt à partager. Vous pouvez utiliser votre téléphone portable ou un autre équipement photo pour prendre des photos, mais vous devez faire attention à la qualité de l'image et à la clarté du son. 2. Editer la vidéo : Afin de rendre le travail plus attrayant, vous pouvez éditer la vidéo. Vous pouvez utiliser un logiciel de montage vidéo professionnel, tel que Douyin, Kuaishou, etc., pour ajouter des filtres, de la musique, des sous-titres et d'autres éléments. 3. Choisissez une couverture : La couverture est la clé pour inciter les utilisateurs à cliquer. Choisissez une image claire et intéressante comme couverture pour inciter les utilisateurs à cliquer dessus.
 2 façons de supprimer le ralenti des vidéos sur iPhone
Mar 04, 2024 am 10:46 AM
2 façons de supprimer le ralenti des vidéos sur iPhone
Mar 04, 2024 am 10:46 AM
Sur les appareils iOS, l'application Appareil photo vous permet de filmer des vidéos au ralenti, voire à 240 images par seconde si vous possédez le dernier iPhone. Cette capacité vous permet de capturer une action à grande vitesse avec des détails riches. Mais parfois, vous souhaiterez peut-être lire des vidéos au ralenti à vitesse normale afin de mieux apprécier les détails et l'action de la vidéo. Dans cet article, nous expliquerons toutes les méthodes pour supprimer le ralenti des vidéos existantes sur iPhone. Comment supprimer le ralenti des vidéos sur iPhone [2 méthodes] Vous pouvez utiliser l'application Photos ou l'application iMovie pour supprimer le ralenti des vidéos sur votre appareil. Méthode 1 : ouvrir sur iPhone à l’aide de l’application Photos
 Comment gagner de l'argent en publiant des vidéos sur Douyin ? Comment un débutant peut-il gagner de l'argent sur Douyin ?
Mar 21, 2024 pm 08:17 PM
Comment gagner de l'argent en publiant des vidéos sur Douyin ? Comment un débutant peut-il gagner de l'argent sur Douyin ?
Mar 21, 2024 pm 08:17 PM
Douyin, la plateforme nationale de courtes vidéos, nous permet non seulement de profiter d'une variété de courtes vidéos intéressantes et originales pendant notre temps libre, mais nous donne également une scène pour nous montrer et réaliser nos valeurs. Alors, comment gagner de l’argent en postant des vidéos sur Douyin ? Cet article répondra à cette question en détail et vous aidera à gagner plus d’argent sur TikTok. 1. Comment gagner de l’argent en publiant des vidéos sur Douyin ? Après avoir posté une vidéo et obtenu un certain nombre de vues sur Douyin, vous aurez la possibilité de participer au plan de partage publicitaire. Cette méthode de revenus est l’une des plus connues des utilisateurs de Douyin et constitue également la principale source de revenus pour de nombreux créateurs. Douyin décide d'offrir ou non des opportunités de partage de publicités en fonction de divers facteurs tels que le poids du compte, le contenu vidéo et les commentaires du public. La plateforme TikTok permet aux téléspectateurs de soutenir leurs créateurs préférés en envoyant des cadeaux,
 Comment publier des vidéos sur Weibo sans compresser la qualité de l'image_Comment publier des vidéos sur Weibo sans compresser la qualité de l'image
Mar 30, 2024 pm 12:26 PM
Comment publier des vidéos sur Weibo sans compresser la qualité de l'image_Comment publier des vidéos sur Weibo sans compresser la qualité de l'image
Mar 30, 2024 pm 12:26 PM
1. Ouvrez d'abord Weibo sur votre téléphone mobile et cliquez sur [Moi] dans le coin inférieur droit (comme indiqué sur l'image). 2. Cliquez ensuite sur [Gear] dans le coin supérieur droit pour ouvrir les paramètres (comme indiqué sur l'image). 3. Ensuite, recherchez et ouvrez [Paramètres généraux] (comme indiqué sur l'image). 4. Entrez ensuite l'option [Video Follow] (comme indiqué sur l'image). 5. Ensuite, ouvrez le paramètre [Résolution de téléchargement vidéo] (comme indiqué sur l'image). 6. Enfin, sélectionnez [Qualité d'image originale] pour éviter la compression (comme indiqué sur l'image).
 Comment convertir des vidéos téléchargées par le navigateur UC en vidéos locales
Feb 29, 2024 pm 10:19 PM
Comment convertir des vidéos téléchargées par le navigateur UC en vidéos locales
Feb 29, 2024 pm 10:19 PM
Comment transformer les vidéos téléchargées par le navigateur UC en vidéos locales ? De nombreux utilisateurs de téléphones mobiles aiment utiliser UC Browser. Ils peuvent non seulement naviguer sur le Web, mais également regarder diverses vidéos et programmes télévisés en ligne et télécharger leurs vidéos préférées sur leurs téléphones mobiles. En fait, nous pouvons convertir des vidéos téléchargées en vidéos locales, mais beaucoup de gens ne savent pas comment le faire. Par conséquent, l'éditeur vous propose spécialement une méthode pour convertir les vidéos mises en cache par le navigateur UC en vidéos locales. J'espère que cela pourra vous aider. Méthode pour convertir les vidéos mises en cache du navigateur uc en vidéos locales 1. Ouvrez le navigateur uc et cliquez sur l'option "Menu". 2. Cliquez sur « Télécharger/Vidéo ». 3. Cliquez sur « Vidéo mise en cache ». 4. Appuyez longuement sur n'importe quelle vidéo, lorsque les options apparaissent, cliquez sur « Ouvrir le répertoire ». 5. Cochez ceux que vous souhaitez télécharger
