
 Périphériques technologiques
IA
HuggingFace : Deux alpagas sont assemblés après avoir retiré leur tête et leur queue
Périphériques technologiques
IA
HuggingFace : Deux alpagas sont assemblés après avoir retiré leur tête et leur queue
HuggingFace : Deux alpagas sont assemblés après avoir retiré leur tête et leur queue

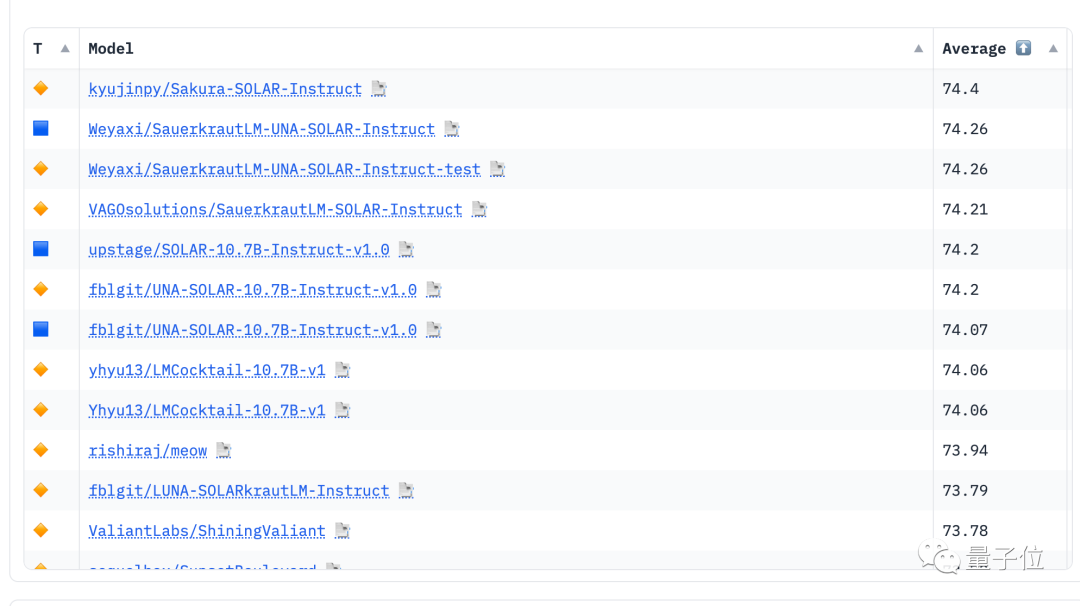
La liste de classement des grands modèles open source HuggingFace a de nouveau été éliminée.
La première rangée est occupée exclusivement par la version peaufinée SOLAR 10.7B, évinçant les différentes versions peaufinées Mixtral 8x7B d'il y a quelques semaines.
Quelle est l'origine du grand modèle SOLAIRE ?
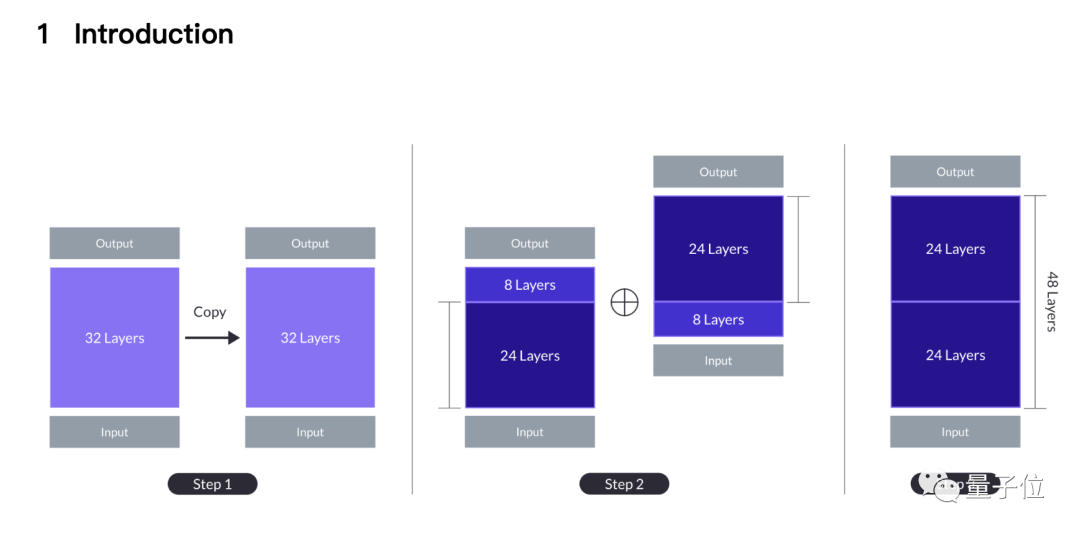
Un article connexe vient d'être téléchargé sur ArXiv, par la société coréenne Upstage AI, en utilisant une nouvelle méthode d'expansion de grand modèle augmentation de la profondeur (DUS).

Pour faire simple, deux alpagas 7B sont pincés ainsi que leur queue, l'un est coupé les 8 premières couches, et l'autre est coupé les 8 dernières couches.
Les deux 24 couches restantes sont cousues ensemble La 24ème couche du premier modèle est épissée avec la 9ème couche du deuxième modèle, et devient finalement un nouveau grand modèle 10,7B à 48 couches.
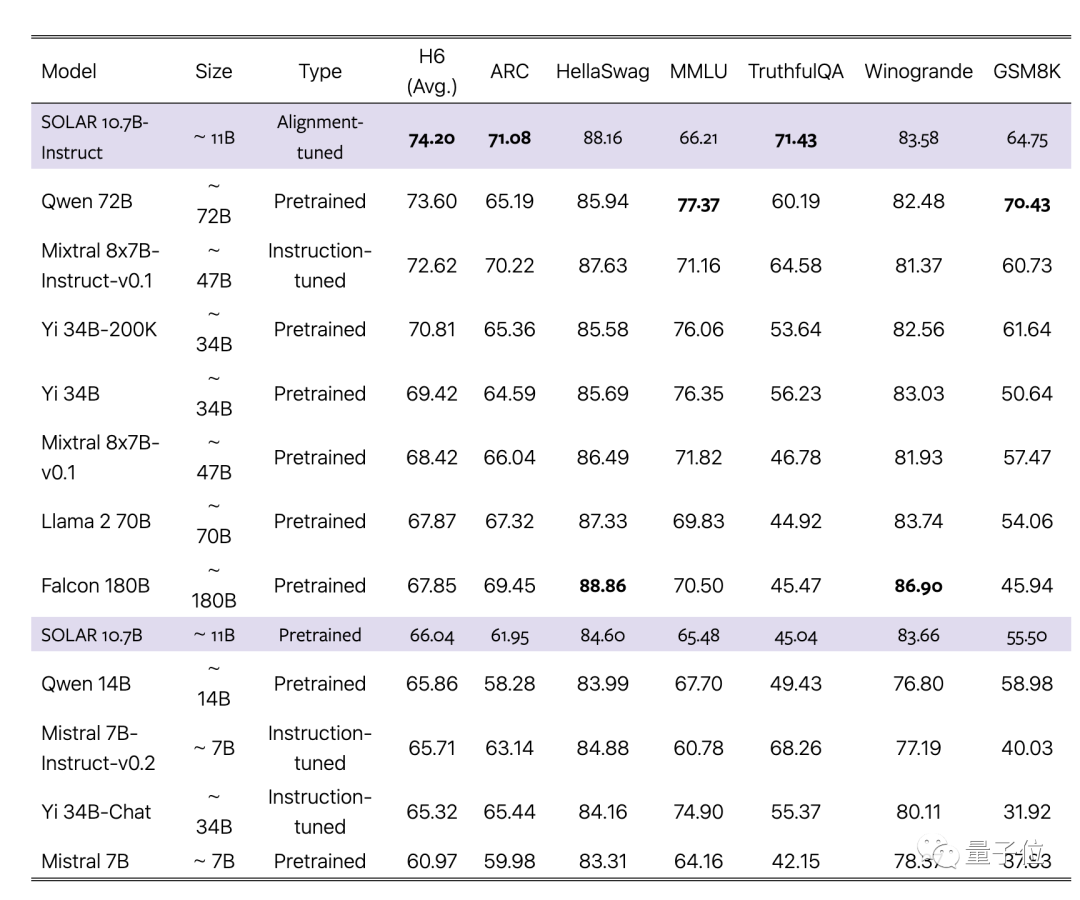
Le document affirme que la nouvelle méthode surpasse les méthodes d'extension traditionnelles telles que le MoE et peut utiliser exactement la même infrastructure que le grand modèle de base.
Il n'est pas nécessaire de modules supplémentaires tels que les réseaux fermés, le cadre de formation est optimisé pour MoE et il n'est pas nécessaire de personnaliser les noyaux CUDA pour une inférence rapide. Il peut être intégré de manière transparente aux méthodes existantes tout en conservant l'efficacité.
L'équipe a choisi le Mistral 7B, le grand modèle unique le plus résistant du 7B, comme matériau de base, et a utilisé de nouvelles méthodes pour l'assembler afin de surpasser la version originale et la version MoE.
Dans le même temps, la version Instruct alignée surpasse également la version MoE Instruct correspondante.
Réaliser la couture jusqu'au bout
Pourquoi cette méthode d'épissage ? L'introduction dans l'article vient d'une intuition.
Commencez par la méthode d'expansion la plus simple, qui consiste à répéter deux fois le grand modèle de base à 32 couches pour en faire 64 couches.
L'avantage est qu'il n'y a pas d'hétérogénéité, toutes les couches sont du grand modèle de base, mais les couches 32 et 33 (identique à la couche 1) ont des " couches plus grandes au niveau des coutures Distance” (distance des couches ).
Des recherches antérieures ont montré que différentes couches de Transformer font des choses différentes. Par exemple, les couches plus profondes sont plus efficaces pour traiter des concepts plus abstraits.
L'équipe estime qu'une distance excessive entre les couches peut entraver la capacité du modèle à utiliser efficacement les poids pré-entraînés.
Une solution potentielle est de sacrifier la couche intermédiaire, réduisant ainsi la différence au niveau des coutures, et c'est là qu'est née la méthode DHS.
Sur la base du compromis entre performances et taille du modèle, l'équipe a choisi de supprimer 8 couches de chaque modèle, et les coutures sont passées de 32 couches à la couche 1 à 24 couches à la couche 9.
Les performances du modèle simplement épissé seront toujours inférieures à celles du modèle de base d'origine au début, mais il peut récupérer rapidement après un pré-entraînement continu.
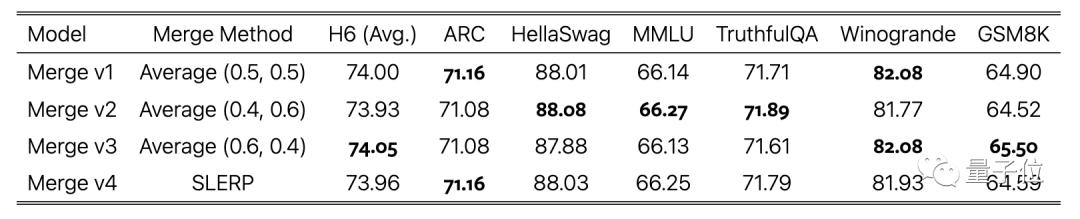
Dans la phase de mise au point des instructions, en plus d'utiliser des ensembles de données open source, nous avons également créé des ensembles de données mathématiquement améliorés et utilisé DPO dans la phase d'alignement.
La dernière étape consiste à pondérer la moyenne des versions de modèles entraînées à l'aide de différents ensembles de données, ce qui constitue également l'achèvement de l'assemblage.
Certains internautes ont remis en question la possibilité d'une fuite de données de test. L'équipe

a également pris cela en considération et a spécifiquement rapporté les résultats des tests de pollution des données dans l'annexe du document, qui ont montré un faible niveau.

Enfin, le modèle de base SOLAR 10.7B et le modèle affiné sont open source sous la licence Apache 2.0.
Les internautes qui l'ont essayé ont signalé qu'il fonctionnait bien dans l'extraction de données à partir de données au format JSON.

Adresse papier : https://arxiv.org/abs/2312.15166
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravelelognent Model Retrieval: Faconttement l'obtention de données de base de données Eloquentorm fournit un moyen concis et facile à comprendre pour faire fonctionner la base de données. Cet article présentera en détail diverses techniques de recherche de modèles éloquentes pour vous aider à obtenir efficacement les données de la base de données. 1. Obtenez tous les enregistrements. Utilisez la méthode All () pour obtenir tous les enregistrements dans la table de base de données: usApp \ Modèles \ Post; $ poters = post :: all (); Cela rendra une collection. Vous pouvez accéder aux données à l'aide de Foreach Loop ou d'autres méthodes de collecte: ForEach ($ PostsAs $ POST) {echo $ post->
