GPT-4 a démontré son extraordinaire capacité à générer des descriptions d’images détaillées et précises, marquant l’arrivée d’une nouvelle ère de langage et de traitement visuel. Par conséquent, les grands modèles de langage multimodaux (MLLM) similaires au GPT-4 ont récemment émergé et sont devenus un domaine de recherche émergent. Le cœur de ses recherches consiste à utiliser un LLM puissant comme outil pour effectuer des tâches cognitives multimodales. . Les performances inattendues et exceptionnelles du MLLM dépassent non seulement les méthodes traditionnelles, mais en font également l’un des moyens potentiels de parvenir à une intelligence artificielle générale. Afin de créer un MLLM utile, il est nécessaire d'utiliser des données image-texte appariées à grande échelle et des données de réglage visuel et linguistique pour former des LLM figés (tels que LLaMA et Vicuna) et des représentations visuelles (telles que CLIP et BLIP-2) Connecteurs (tels que MiniGPT-4, LLaVA et LLaMA-Adapter). La formation du MLLM est généralement divisée en deux étapes : l'étape de pré-formation et l'étape de mise au point. Le but de la pré-formation est de permettre au MLLM d'acquérir une grande quantité de connaissances, tandis que la mise au point est d'apprendre au modèle à mieux comprendre les intentions humaines et à générer des réponses précises. Afin d'améliorer la capacité de MLLM à comprendre le langage visuel et à suivre les instructions, une puissante technologie de réglage fin appelée réglage des instructions a récemment émergé. Cette technologie permet d'aligner les modèles sur les préférences humaines afin que le modèle produise les résultats souhaités par l'homme sous diverses instructions différentes. En termes de développement d'une technologie de réglage fin de l'enseignement, une direction assez constructive consiste à introduire l'annotation d'images, la réponse visuelle aux questions (VQA) et les ensembles de données de raisonnement visuel dans la phase de réglage fin. Des techniques antérieures telles que InstructBLIP et Otter utilisaient une série d’ensembles de données visuo-linguistiques pour affiner les instructions visuelles et ont également obtenu des résultats prometteurs. Cependant, il a été observé que les ensembles de données de réglage fin des instructions multimodales couramment utilisés contiennent un grand nombre d'instances de mauvaise qualité, c'est-à-dire où les réponses sont incorrectes ou non pertinentes. Ces données sont trompeuses et peuvent avoir un impact négatif sur les performances du modèle. Cette question a incité les chercheurs à explorer la possibilité : peut-on obtenir des performances robustes en utilisant de petites quantités de données de suivi d'instructions de haute qualité ? Certaines études récentes ont obtenu des résultats encourageants, indiquant que cette direction a du potentiel. Par exemple, Zhou et al. ont proposé LIMA, qui est un modèle de langage affiné à l'aide de données de haute qualité soigneusement sélectionnées par des experts humains. Cette étude montre que les grands modèles de langage peuvent obtenir des résultats satisfaisants même avec des quantités limitées de données de suivi d'instructions de haute qualité. Ainsi, les chercheurs ont conclu : Moins c’est plus en matière d’alignement. Cependant, il n’existe pas de lignes directrices claires sur la manière de sélectionner des ensembles de données appropriés de haute qualité pour affiner les modèles linguistiques multimodaux. Une équipe de recherche de l'Institut de recherche Qingyuan de l'Université Jiao Tong de Shanghai et de l'Université Lehigh a comblé cette lacune et proposé un sélecteur de données robuste et efficace. Ce sélecteur de données identifie et filtre automatiquement les données visuelles-verbales de faible qualité, garantissant que les échantillons les plus pertinents et informatifs sont utilisés pour la formation du modèle. Adresse papier : https://arxiv.org/abs/2308.12067Le chercheur a déclaré que l'objectif de cette étude est d'explorer l'impact d'un enseignement restreint mais de haute qualité. données de réglage sur le réglage fin multi-mode L'efficacité des grands modèles de langage dynamiques. En plus de cela, cet article présente plusieurs nouvelles mesures spécifiquement conçues pour évaluer la qualité des données d'instructions multimodales. Après avoir effectué un regroupement spectral sur l'image, le sélecteur de données calcule un score pondéré qui combine le score CLIP, le score GPT, le score bonus et la longueur de réponse pour chaque élément de données visuelles-verbales. En utilisant ce sélecteur sur 3400 données brutes utilisées pour affiner MiniGPT-4, les chercheurs ont constaté que la plupart des données présentaient des problèmes de mauvaise qualité. Grâce à ce sélecteur de données, le chercheur a obtenu un sous-ensemble beaucoup plus petit de données conservées : seulement 200 données, soit seulement 6 % de l'ensemble de données d'origine. Ensuite, ils ont utilisé la même configuration de formation que MiniGPT-4 et l’ont peaufinée pour obtenir un nouveau modèle : InstructionGPT-4. Les chercheurs ont déclaré qu'il s'agissait d'une découverte passionnante car elle montre que la qualité des données est plus importante que la quantité pour affiner les instructions visuo-verbales. De plus, ce changement mettant davantage l’accent sur la qualité des données fournit un nouveau paradigme plus efficace qui peut améliorer le réglage fin du MLLM.Les chercheurs ont mené des expériences rigoureuses et l'évaluation expérimentale du MLLM affiné s'est concentrée sur sept ensembles de données multimodales à domaine ouvert divers et complexes, notamment Flick-30k, ScienceQA, VSR, etc. Ils ont comparé les performances d'inférence de modèles affinés à l'aide de différentes méthodes de sélection d'ensembles de données (utilisation de sélecteurs de données, échantillonnage aléatoire de l'ensemble de données, utilisation de l'ensemble de données complet) sur différentes tâches multimodales. Les résultats ont montré la supériorité de l'InstructionGPT-4. . De plus, il est à noter : l'évaluateur utilisé par le chercheur pour l'évaluation est GPT-4. Plus précisément, les chercheurs ont utilisé l'invite pour transformer GPT-4 en un évaluateur, capable de comparer les résultats de réponse d'InstructionGPT-4 et du MiniGPT-4 original à l'aide de l'ensemble de tests de LLaVA-Bench. Il a été constaté que bien que les données affinées utilisées par InstructionGPT-4 n'étaient que 6% inférieures aux données de conformité aux instructions originales utilisées par MiniGPT-4, ces dernières ont donné une réponse dans 73% des cas. pareil ou mieux. Les principales contributions de cet article comprennent :
- En sélectionnant 200 (environ 6 %) données de suivi d'instruction de haute qualité pour entraîner l'InstructionGPT-4, les chercheurs ont montré qu'il peut être utilisé pour plusieurs Les modèles de langage modaux à grande échelle utilisent moins de données d'instruction pour obtenir un meilleur alignement.
- Cet article propose un sélecteur de données qui utilise un principe simple et interprétable pour sélectionner des données de conformité aux instructions multimodales de haute qualité à des fins de réglage fin. Cette approche s'efforce d'atteindre la validité et la portabilité dans l'évaluation et l'ajustement des sous-ensembles de données.
- Les chercheurs ont montré par des expériences que cette technologie simple peut bien gérer différentes tâches. Par rapport au MiniGPT-4 d'origine, InstructionGPT-4, qui est affiné en utilisant seulement 6 % de données filtrées, permet d'obtenir de meilleures performances sur une variété de tâches.
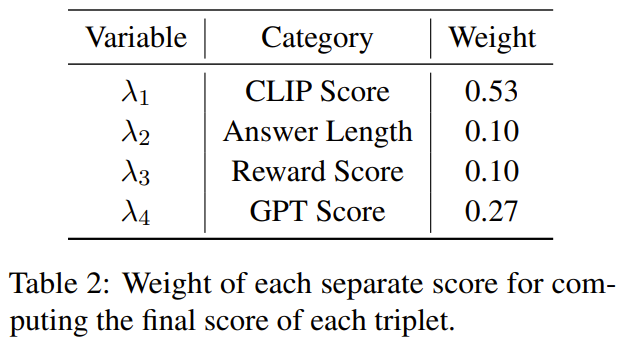
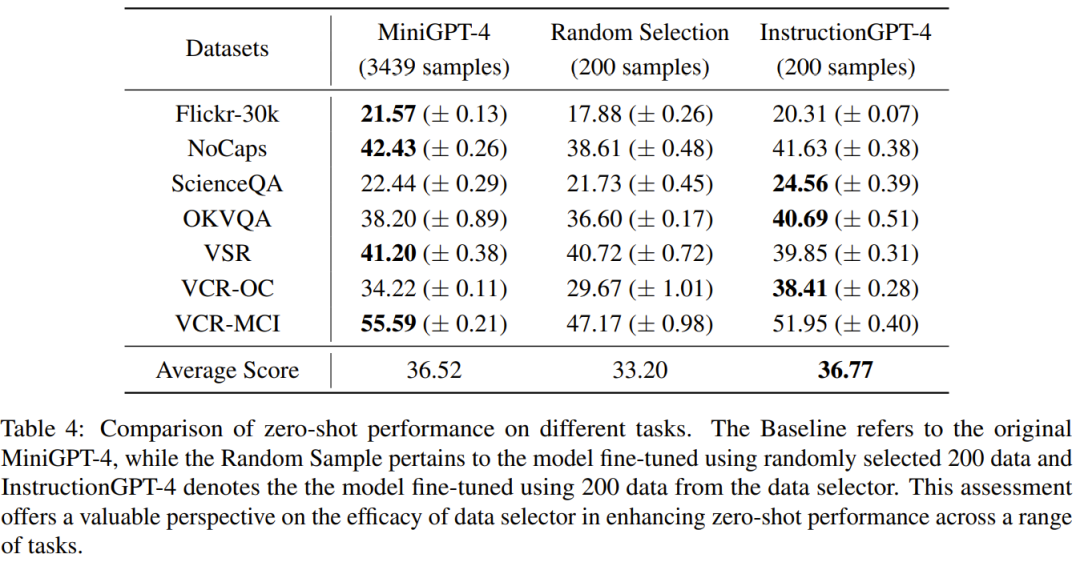
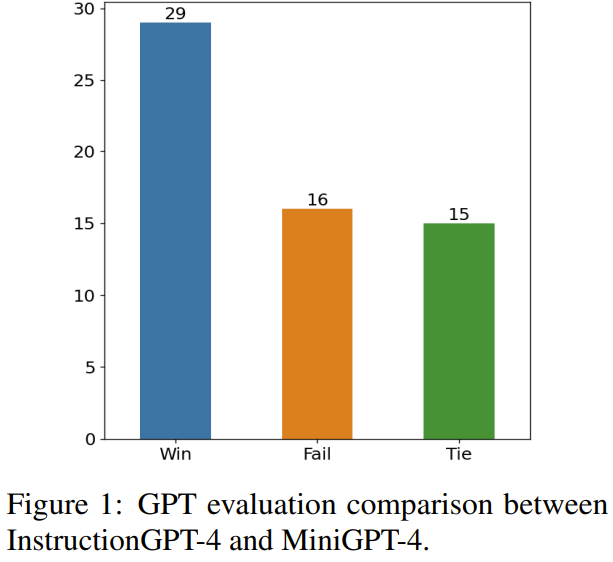
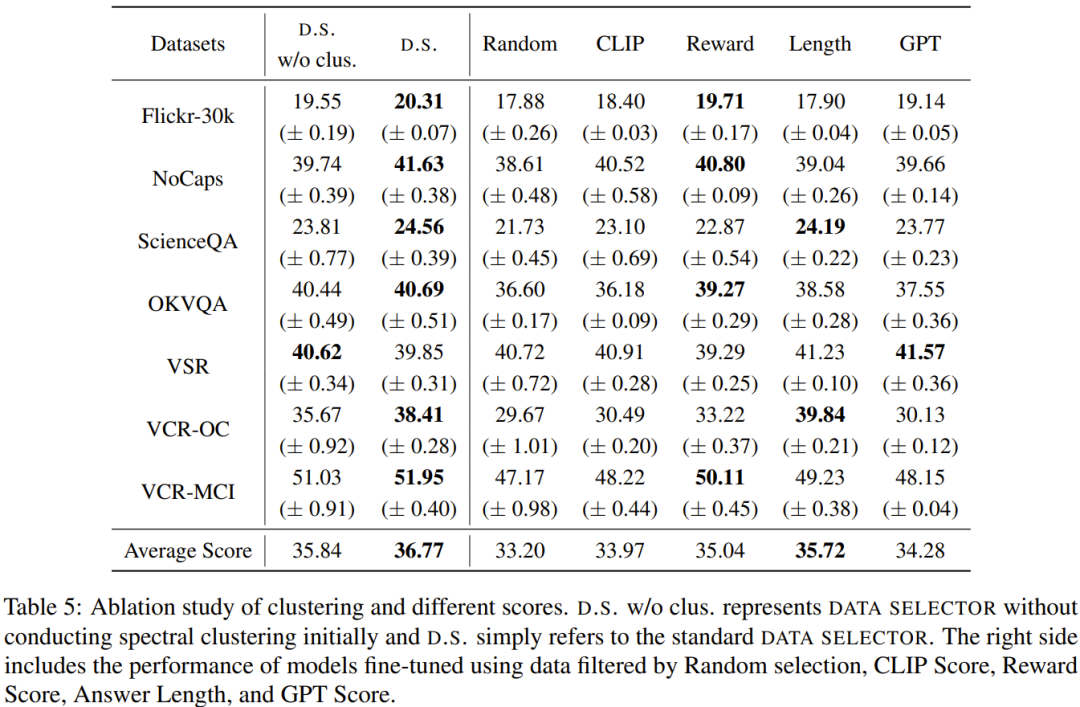
Le but de cette recherche est de proposer un sélecteur de données simple et portable qui peut sélectionner automatiquement un sous-ensemble de l'ensemble de données initial affiné. Pour cela, les chercheurs ont défini un principe de sélection axé sur la diversité et la qualité des ensembles de données multimodales. Une brève introduction sera donnée ci-dessous. Afin de former efficacement MLLM, il est crucial de sélectionner des données d'instruction multimodales utiles. Afin de sélectionner les données d’enseignement optimales, les chercheurs ont proposé deux principes clés : la diversité et la qualité. Pour plus de diversité, l'approche adoptée par les chercheurs consiste à regrouper les intégrations d'images pour séparer les données en différents groupes. Pour évaluer la qualité, les chercheurs ont adopté certains paramètres clés pour une évaluation efficace des données multimodales. Étant donné un ensemble de données d'instructions visuo-linguistiques et un MLLM pré-entraîné (tel que MiniGPT-4 et LLaVA), le but ultime du sélecteur de données est d'identifier un Un sous-ensemble utilisé pour affiner et permettre à ce sous-ensemble d'apporter des améliorations au MLLM pré-entraîné. Afin de sélectionner ce sous-ensemble et d'assurer sa diversité, les chercheurs ont d'abord utilisé un algorithme de clustering pour diviser l'ensemble de données d'origine en plusieurs catégories. Afin de garantir la qualité des données d'enseignement multimodal sélectionnées, les chercheurs ont développé un ensemble d'indicateurs d'évaluation, comme le montre le tableau 1 ci-dessous. Le tableau 2 montre le poids de chaque note différente lors du calcul de la note finale. L'algorithme 1 affiche l'intégralité du flux de travail du sélecteur de données. L'ensemble de données utilisé dans l'évaluation expérimentale est présenté dans le tableau 3 ci-dessous. Le tableau 4 compare les performances du modèle de base MiniGPT-4, du MiniGPT-4 affiné à l'aide de données échantillonnées de manière aléatoire et de l'InstructionGPT-4 affiné à l'aide de sélecteurs de données. .On peut observer que la performance moyenne d'InstructionGPT-4 est la meilleure. Plus précisément, InstructionGPT-4 surpasse le modèle de base de 2,12 % sur ScienceQA, et surpasse le modèle de base de 2,49 % et 4,19 % sur OKVQA et VCR-OC respectivement. De plus, InstructionGPT-4 surpasse les modèles entraînés avec des échantillons aléatoires sur toutes les autres tâches à l'exception de VSR. En évaluant et en comparant ces modèles sur une gamme de tâches, il est possible de discerner leurs capacités respectives et de déterminer l'efficacité des sélecteurs de données nouvellement proposés qui identifient efficacement les données de haute qualité. Une analyse aussi complète montre qu'une sélection judicieuse des données peut améliorer les performances zéro du modèle sur une variété de tâches différentes. 1) Gagner : InstructionGPT-4 Gagner dans les deux situations ou gagner une fois et égaliser une fois 2) Tirage au sort : InstructionGPT ; -4 et MiniGPT-4 font match nul deux fois ou gagnent une fois et perdent une fois 3) Perdent : InstructionGPT-4 perd deux fois ou perd une fois et fait match nul une fois ; La figure 1 montre les résultats de cette méthode d'évaluation. Sur 60 questions, InstructionGPT-4 a remporté 29 matchs, perdu 16 matchs et égalisé dans les 15 matchs restants. Cela suffit pour prouver qu'InstructionGPT-4 est nettement meilleur que MiniGPT-4 en termes de qualité de réponse. Le tableau 5 donne les résultats d'analyse des expériences d'ablation, à partir desquels l'importance de l'algorithme de regroupement et des divers scores d'évaluation peut être constatée. Afin de mieux comprendre la capacité d'InstructionGPT-4 à comprendre les entrées visuelles et à générer des réponses raisonnables, les chercheurs ont également mené une évaluation d'InstructionGPT-4. 4 et MiniGPT-4 La compréhension des images et les capacités conversationnelles ont été évaluées de manière comparative. L'analyse est basée sur un exemple frappant impliquant une description et une compréhension plus approfondie de l'image, et les résultats sont présentés dans le tableau 6. InstructionGPT-4 est plus efficace pour fournir des descriptions d'images complètes et identifier les aspects intéressants des images. Par rapport au MiniGPT-4, InstructionGPT-4 est plus capable de reconnaître le texte présent dans les images. Ici, InstructionGPT-4 est capable de souligner correctement qu'il y a une phrase dans l'image : lundi, juste lundi.Voir l'article original pour plus de détails. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!






 Comment définir le style de la barre de défilement HTML
Comment définir le style de la barre de défilement HTML
 Quels sont les logiciels de gestion de serveur ?
Quels sont les logiciels de gestion de serveur ?
 Migrer les données d'un téléphone Android vers un téléphone Apple
Migrer les données d'un téléphone Android vers un téléphone Apple
 Introduction à la signification de += en langage C
Introduction à la signification de += en langage C
 Prix de la devise Eth Prix du marché actuel USD
Prix de la devise Eth Prix du marché actuel USD
 Comment mettre à niveau Douyin
Comment mettre à niveau Douyin
 Comment créer un wifi virtuel dans Win7
Comment créer un wifi virtuel dans Win7
 Comment définir la zone de texte en lecture seule
Comment définir la zone de texte en lecture seule


![Premiers pas avec le développement pratique PHP : création rapide de PHP [Small Business Forum]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)






![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



