
 Périphériques technologiques
IA
Implémentation d'un modèle expert mixte (MoE) à l'aide de PyTorch
Périphériques technologiques
IA
Implémentation d'un modèle expert mixte (MoE) à l'aide de PyTorch
Implémentation d'un modèle expert mixte (MoE) à l'aide de PyTorch

Le lancement de Mixtral 8x7B a suscité une large attention dans le domaine de l'IA ouverte, en particulier le concept de mélange d'experts (MoE), bien connu de tous. Le concept d'expertise hybride (MoE) symbolise l'intelligence collaborative et incarne l'idée que le tout est supérieur à la somme de ses parties. Le modèle MoE intègre les avantages de plusieurs modèles experts pour fournir des prédictions plus précises. Il se compose d’un réseau fermé et d’un ensemble de réseaux d’experts, chacun étant capable de gérer différents aspects d’une tâche spécifique. En attribuant correctement les tâches et les pondérations, le modèle MoE peut tirer parti de l'expertise des experts, améliorant ainsi les performances globales de prévision. Ce modèle intelligent collaboratif a apporté de nouvelles avancées dans le développement du domaine de l'IA et jouera un rôle important dans les applications futures.
Cet article utilisera PyTorch pour implémenter le modèle MoE. Avant d’introduire le code spécifique, présentons brièvement l’architecture de l’expert hybride.
Architecture MoE
MoE se compose de deux types de réseaux : (1) réseau expert et (2) réseau fermé.
Expert Network est une méthode qui utilise un modèle propriétaire qui fonctionne bien sur un sous-ensemble de données. Son concept principal est de couvrir l’espace du problème grâce à plusieurs experts aux atouts complémentaires pour garantir une solution globale au problème. Chaque modèle expert est formé avec des capacités et une expérience uniques, améliorant ainsi les performances et l'efficacité globales du système. Grâce à l’utilisation de réseaux d’experts, des tâches et des besoins complexes peuvent être traités efficacement et de meilleures solutions peuvent être proposées.
Un réseau fermé est un réseau utilisé pour diriger, coordonner ou gérer les contributions d'experts. Il détermine quel réseau est le meilleur pour traiter une entrée spécifique en apprenant et en pesant les capacités de différents réseaux pour différents types d'entrées. Un réseau de contrôle bien formé peut évaluer de nouveaux vecteurs d’entrée et attribuer des tâches de traitement à l’expert ou à la combinaison d’experts le plus approprié en fonction de ses compétences. Le réseau de contrôle ajuste dynamiquement les pondérations en fonction de la pertinence des résultats de l'expert par rapport à l'entrée actuelle pour garantir des réponses personnalisées. Ce mécanisme d'ajustement dynamique des poids permet au réseau de contrôle de s'adapter de manière flexible aux différentes situations et besoins.
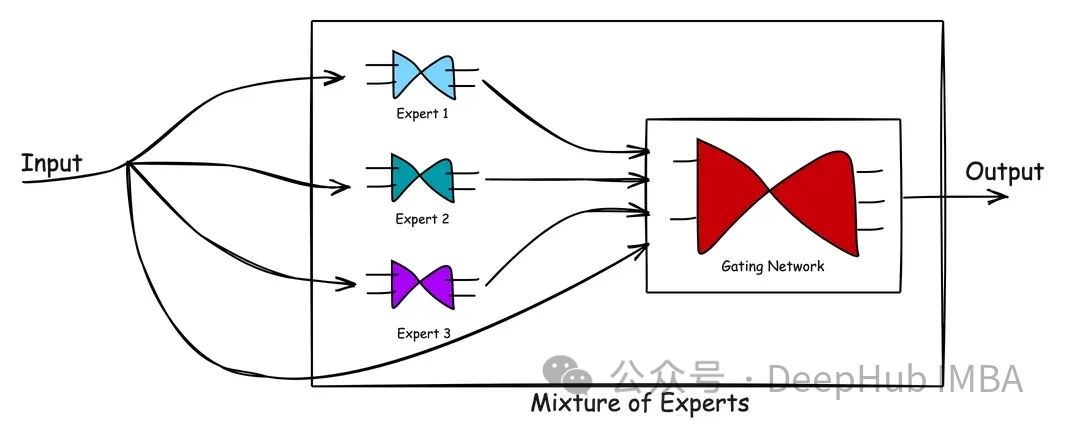
L'image ci-dessus montre le flux de traitement au sein du MoE. L’avantage du modèle expert mixte est sa simplicité. En apprenant l'espace complexe du problème et les réactions des experts tout en résolvant le problème, les modèles du MoE aident à produire de meilleures solutions qu'un seul expert. Le Gating Network agit comme un gestionnaire efficace, évaluant les scénarios et confiant les tâches aux meilleurs experts. Lorsque de nouvelles données sont saisies, le modèle peut s'adapter en réévaluant les points forts de l'expert par rapport à la nouvelle entrée, ce qui aboutit à une approche d'apprentissage flexible. En bref, le modèle du MoE exploite les connaissances et l’expérience de plusieurs experts pour résoudre des problèmes complexes. Grâce à la gestion d'un réseau sécurisé, le modèle peut sélectionner les experts les plus appropriés pour gérer les tâches selon différents scénarios. Les avantages de cette approche sont sa capacité à produire de meilleures solutions qu'un seul expert et sa flexibilité pour s'adapter aux nouvelles données d'entrée. Dans l’ensemble, le modèle MoE est une méthode efficace et simple qui peut être utilisée pour résoudre divers problèmes complexes.
MoE offre d'énormes avantages pour le déploiement de modèles d'apprentissage automatique. Voici deux avantages notables.
La principale force du MoE réside dans son réseau d’experts diversifiés et professionnels. Le paramétrage du MoE peut traiter des problèmes dans plusieurs domaines avec une grande précision, ce qui est difficile à réaliser avec un seul modèle.
MoE est intrinsèquement évolutif. À mesure que la complexité des tâches augmente, davantage d’experts peuvent être intégrés de manière transparente dans le système, élargissant ainsi la portée de l’expertise sans qu’il soit nécessaire de modifier d’autres modèles d’experts. En d’autres termes, le ministère de l’Éducation peut intégrer des experts pré-formés dans des systèmes d’apprentissage automatique pour aider les systèmes à faire face aux exigences croissantes des tâches.
Les modèles experts mixtes ont des applications dans de nombreux domaines, notamment les systèmes de recommandation, la modélisation du langage et diverses tâches de prédiction complexes. Il y a des rumeurs selon lesquelles GPT-4 serait composé de plusieurs experts. Bien que nous ne puissions pas le confirmer, un modèle comme gpt-4 fournira les meilleurs résultats en exploitant la puissance de plusieurs modèles grâce à l'approche MoE.
Code Pytorch
Nous n'allons pas discuter ici de la technologie MOE utilisée dans les grands modèles comme Mixtral 8x7B. Au lieu de cela, nous écrivons un MOE personnalisé simple qui peut être appliqué à n'importe quelle tâche. Nous pouvons le comprendre grâce au. code Le principe de fonctionnement de MOE est très utile pour comprendre comment MOE fonctionne dans les grands modèles.
Ci-dessous, nous présenterons l'implémentation du code de PyTorch pièce par pièce.
Importer la bibliothèque :
import torch import torch.nn as nn import torch.optim as optim
Définir le modèle expert :
class Expert(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim): super(Expert, self).__init__() self.layer1 = nn.Linear(input_dim, hidden_dim) self.layer2 = nn.Linear(hidden_dim, output_dim) def forward(self, x): x = torch.relu(self.layer1(x)) return torch.softmax(self.layer2(x), dim=1)
Ici, nous définissons un modèle expert simple, vous pouvez voir qu'il s'agit d'un mlp à 2 couches, utilisant l'activation de relu, et enfin utilisant les sorties softmax la probabilité de classification.
Définir le modèle de déclenchement :
# Define the gating model class Gating(nn.Module): def __init__(self, input_dim,num_experts, dropout_rate=0.1): super(Gating, self).__init__() # Layers self.layer1 = nn.Linear(input_dim, 128) self.dropout1 = nn.Dropout(dropout_rate) self.layer2 = nn.Linear(128, 256) self.leaky_relu1 = nn.LeakyReLU() self.dropout2 = nn.Dropout(dropout_rate) self.layer3 = nn.Linear(256, 128) self.leaky_relu2 = nn.LeakyReLU() self.dropout3 = nn.Dropout(dropout_rate) self.layer4 = nn.Linear(128, num_experts) def forward(self, x): x = torch.relu(self.layer1(x)) x = self.dropout1(x) x = self.layer2(x) x = self.leaky_relu1(x) x = self.dropout2(x) x = self.layer3(x) x = self.leaky_relu2(x) x = self.dropout3(x) return torch.softmax(self.layer4(x), dim=1)
门控模型更复杂,有三个线性层和dropout层用于正则化以防止过拟合。它使用ReLU和LeakyReLU激活函数引入非线性。最后一层的输出大小等于专家的数量,并对这些输出应用softmax函数。输出权重,这样可以将专家的输出与之结合。
说明:其实门控网络,或者叫路由网络是MOE中最复杂的部分,因为它涉及到控制输入到那个专家模型,所以门控网络也有很多个设计方案,例如(如果我没记错的话)Mixtral 8x7B 只是取了8个专家中的top2。所以我们这里不详细讨论各种方案,只是介绍其基本原理和代码实现。
完整的MOE模型:
class MoE(nn.Module): def __init__(self, trained_experts): super(MoE, self).__init__() self.experts = nn.ModuleList(trained_experts) num_experts = len(trained_experts) # Assuming all experts have the same input dimension input_dim = trained_experts[0].layer1.in_features self.gating = Gating(input_dim, num_experts) def forward(self, x): # Get the weights from the gating network weights = self.gating(x) # Calculate the expert outputs outputs = torch.stack([expert(x) for expert in self.experts], dim=2) # Adjust the weights tensor shape to match the expert outputs weights = weights.unsqueeze(1).expand_as(outputs) # Multiply the expert outputs with the weights and # sum along the third dimension return torch.sum(outputs * weights, dim=2)
这里主要看前向传播的代码,通过输入计算出权重和每个专家给出输出的预测,最后使用权重将所有专家的结果求和最终得到模型的输出。
这个是不是有点像“集成学习”。
测试
下面我们来对我们的实现做个简单的测试,首先生成一个简单的数据集:
# Generate the dataset num_samples = 5000 input_dim = 4 hidden_dim = 32 # Generate equal numbers of labels 0, 1, and 2 y_data = torch.cat([ torch.zeros(num_samples // 3), torch.ones(num_samples // 3), torch.full((num_samples - 2 * (num_samples // 3),), 2)# Filling the remaining to ensure exact num_samples ]).long() # Biasing the data based on the labels x_data = torch.randn(num_samples, input_dim) for i in range(num_samples): if y_data[i] == 0: x_data[i, 0] += 1# Making x[0] more positive elif y_data[i] == 1: x_data[i, 1] -= 1# Making x[1] more negative elif y_data[i] == 2: x_data[i, 0] -= 1# Making x[0] more negative # Shuffle the data to randomize the order indices = torch.randperm(num_samples) x_data = x_data[indices] y_data = y_data[indices] # Verify the label distribution y_data.bincount() # Shuffle the data to ensure x_data and y_data remain aligned shuffled_indices = torch.randperm(num_samples) x_data = x_data[shuffled_indices] y_data = y_data[shuffled_indices] # Splitting data for training individual experts # Use the first half samples for training individual experts x_train_experts = x_data[:int(num_samples/2)] y_train_experts = y_data[:int(num_samples/2)] mask_expert1 = (y_train_experts == 0) | (y_train_experts == 1) mask_expert2 = (y_train_experts == 1) | (y_train_experts == 2) mask_expert3 = (y_train_experts == 0) | (y_train_experts == 2) # Select an almost equal number of samples for each expert num_samples_per_expert = \ min(mask_expert1.sum(), mask_expert2.sum(), mask_expert3.sum()) x_expert1 = x_train_experts[mask_expert1][:num_samples_per_expert] y_expert1 = y_train_experts[mask_expert1][:num_samples_per_expert] x_expert2 = x_train_experts[mask_expert2][:num_samples_per_expert] y_expert2 = y_train_experts[mask_expert2][:num_samples_per_expert] x_expert3 = x_train_experts[mask_expert3][:num_samples_per_expert] y_expert3 = y_train_experts[mask_expert3][:num_samples_per_expert] # Splitting the next half samples for training MoE model and for testing x_remaining = x_data[int(num_samples/2)+1:] y_remaining = y_data[int(num_samples/2)+1:] split = int(0.8 * len(x_remaining)) x_train_moe = x_remaining[:split] y_train_moe = y_remaining[:split] x_test = x_remaining[split:] y_test = y_remaining[split:] print(x_train_moe.shape,"\n", x_test.shape,"\n", x_expert1.shape,"\n", x_expert2.shape,"\n", x_expert3.shape)
这段代码创建了一个合成数据集,其中包含三个类标签——0、1和2。基于类标签对特征进行操作,从而在数据中引入一些模型可以学习的结构。
数据被分成针对个别专家的训练集、MoE模型和测试集。我们确保专家模型是在一个子集上训练的,这样第一个专家在标签0和1上得到很好的训练,第二个专家在标签1和2上得到更好的训练,第三个专家看到更多的标签2和0。
我们期望的结果是:虽然每个专家对标签0、1和2的分类准确率都不令人满意,但通过结合三位专家的决策,MoE将表现出色。
模型初始化和训练设置:
# Define hidden dimension output_dim = 3 hidden_dim = 32 epochs = 500 learning_rate = 0.001 # Instantiate the experts expert1 = Expert(input_dim, hidden_dim, output_dim) expert2 = Expert(input_dim, hidden_dim, output_dim) expert3 = Expert(input_dim, hidden_dim, output_dim) # Set up loss criterion = nn.CrossEntropyLoss() # Optimizers for experts optimizer_expert1 = optim.Adam(expert1.parameters(), lr=learning_rate) optimizer_expert2 = optim.Adam(expert2.parameters(), lr=learning_rate) optimizer_expert3 = optim.Adam(expert3.parameters(), lr=learning_rate)
实例化了专家模型和MoE模型。定义损失函数来计算训练损失,并为每个模型设置优化器,在训练过程中执行权重更新。
训练的步骤也非常简单
# Training loop for expert 1 for epoch in range(epochs):optimizer_expert1.zero_grad()outputs_expert1 = expert1(x_expert1)loss_expert1 = criterion(outputs_expert1, y_expert1)loss_expert1.backward()optimizer_expert1.step() # Training loop for expert 2 for epoch in range(epochs):optimizer_expert2.zero_grad()outputs_expert2 = expert2(x_expert2)loss_expert2 = criterion(outputs_expert2, y_expert2)loss_expert2.backward()optimizer_expert2.step() # Training loop for expert 3 for epoch in range(epochs):optimizer_expert3.zero_grad()outputs_expert3 = expert3(x_expert3)loss_expert3 = criterion(outputs_expert3, y_expert3)loss_expert3.backward()
每个专家使用基本的训练循环在不同的数据子集上进行单独的训练。循环迭代指定数量的epoch。
下面是我们MOE的训练
# Create the MoE model with the trained experts moe_model = MoE([expert1, expert2, expert3]) # Train the MoE model optimizer_moe = optim.Adam(moe_model.parameters(), lr=learning_rate) for epoch in range(epochs):optimizer_moe.zero_grad()outputs_moe = moe_model(x_train_moe)loss_moe = criterion(outputs_moe, y_train_moe)loss_moe.backward()optimizer_moe.step()
MoE模型是由先前训练过的专家创建的,然后在单独的数据集上进行训练。训练过程类似于单个专家的训练,但现在门控网络的权值在训练过程中更新。
最后我们的评估函数:
# Evaluate all models def evaluate(model, x, y):with torch.no_grad():outputs = model(x)_, predicted = torch.max(outputs, 1)correct = (predicted == y).sum().item()accuracy = correct / len(y)return accuracy
evaluate函数计算模型在给定数据上的精度(x代表样本,y代表预期标签)。准确度计算为正确预测数与预测总数之比。
结果如下:
accuracy_expert1 = evaluate(expert1, x_test, y_test) accuracy_expert2 = evaluate(expert2, x_test, y_test) accuracy_expert3 = evaluate(expert3, x_test, y_test) accuracy_moe = evaluate(moe_model, x_test, y_test) print("Expert 1 Accuracy:", accuracy_expert1) print("Expert 2 Accuracy:", accuracy_expert2) print("Expert 3 Accuracy:", accuracy_expert3) print("Mixture of Experts Accuracy:", accuracy_moe) #Expert 1 Accuracy: 0.466 #Expert 2 Accuracy: 0.496 #Expert 3 Accuracy: 0.378 #Mixture of Experts Accuracy: 0.614可以看到
专家1正确预测了测试数据集中大约46.6%的样本的类标签。
专家2表现稍好,正确预测率约为49.6%。
专家3在三位专家中准确率最低,正确预测的样本约为37.8%。
而MoE模型显著优于每个专家,总体准确率约为61.4%。
总结
我们测试的输出结果显示了混合专家模型的强大功能。该模型通过门控网络将各个专家模型的优势结合起来,取得了比单个专家模型更高的精度。门控网络有效地学习了如何根据输入数据权衡每个专家的贡献,以产生更准确的预测。混合专家利用了各个模型的不同专业知识,在测试数据集上提供了更好的性能。
同时也说明我们可以在现有的任务上尝试使用MOE来进行测试,也可以得到更好的结果。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 PRO | Pourquoi les grands modèles basés sur le MoE méritent-ils davantage d'attention ?
Aug 07, 2024 pm 07:08 PM
PRO | Pourquoi les grands modèles basés sur le MoE méritent-ils davantage d'attention ?
Aug 07, 2024 pm 07:08 PM
En 2023, presque tous les domaines de l’IA évoluent à une vitesse sans précédent. Dans le même temps, l’IA repousse constamment les limites technologiques de domaines clés tels que l’intelligence embarquée et la conduite autonome. Sous la tendance multimodale, le statut de Transformer en tant qu'architecture dominante des grands modèles d'IA sera-t-il ébranlé ? Pourquoi l'exploration de grands modèles basés sur l'architecture MoE (Mixture of Experts) est-elle devenue une nouvelle tendance dans l'industrie ? Les modèles de grande vision (LVM) peuvent-ils constituer une nouvelle avancée dans la vision générale ? ...Dans la newsletter des membres PRO 2023 de ce site publiée au cours des six derniers mois, nous avons sélectionné 10 interprétations spéciales qui fournissent une analyse approfondie des tendances technologiques et des changements industriels dans les domaines ci-dessus pour vous aider à atteindre vos objectifs dans le nouveau année. Cette interprétation provient de la Week50 2023
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
