

简述MySQL排序原理的实例详解

这篇文章主要介绍了浅谈MySQL排序原理与案例分析的相关资料,需要的朋友可以参考下
前言
排序是数据库中的一个基本功能,MySQL也不例外。用户通过Order by语句即能达到将指定的结果集排序的目的,其实不仅仅是Order by语句,Group by语句,Distinct语句都会隐含使用排序。本文首先会简单介绍SQL如何利用索引避免排序代价,然后会介绍MySQL实现排序的内部原理,并介绍与排序相关的参数,最后会给出几个“奇怪”排序例子,来谈谈排序一致性问题,并说明产生现象的本质原因。
1.排序优化与索引使用
为了优化SQL语句的排序性能,最好的情况是避免排序,合理利用索引是一个不错的方法。因为索引本身也是有序的,如果在需要排序的字段上面建立了合适的索引,那么就可以跳过排序的过程,提高SQL的查询速度。下面我通过一些典型的SQL来说明哪些SQL可以利用索引减少排序,哪些SQL不能。假设t1表存在索引key1(key_part1,key_part2),key2(key2)
a.可以利用索引避免排序的SQL
SELECT * FROM t1 ORDER BY key_part1,key_part2; SELECT * FROM t1 WHERE key_part1 = constant ORDER BY key_part2; SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1 ASC; SELECT * FROM t1 WHERE key_part1 = constant1 AND key_part2 > constant2 ORDER BY key_part2;
b.不能利用索引避免排序的SQL
//排序字段在多个索引中,无法使用索引排序 SELECT * FROM t1 ORDER BY key_part1,key_part2, key2; //排序键顺序与索引中列顺序不一致,无法使用索引排序 SELECT * FROM t1 ORDER BY key_part2, key_part1; //升降序不一致,无法使用索引排序 SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC; //key_part1是范围查询,key_part2无法使用索引排序 SELECT * FROM t1 WHERE key_part1> constant ORDER BY key_part2;
2.排序实现的算法
对于不能利用索引避免排序的SQL,数据库不得不自己实现排序功能以满足用户需求,此时SQL的执行计划中会出现“Using filesort”,这里需要注意的是filesort并不意味着就是文件排序,其实也有可能是内存排序,这个主要由sort_buffer_size参数与结果集大小确定。MySQL内部实现排序主要有3种方式,常规排序,优化排序和优先队列排序,主要涉及3种排序算法:快速排序、归并排序和堆排序。假设表结构和SQL语句如下:
CREATE TABLE t1(id int, col1 varchar(64), col2 varchar(64), col3 varchar(64), PRIMARY KEY(id),key(col1,col2)); SELECT col1,col2,col3 FROM t1 WHERE col1>100 ORDER BY col2;
a.常规排序
(1).从表t1中获取满足WHERE条件的记录
(2).对于每条记录,将记录的主键+排序键(id,col2)取出放入sort buffer
(3).如果sort buffer可以存放所有满足条件的(id,col2)对,则进行排序;否则sort buffer满后,进行排序并固化到临时文件中。(排序算法采用的是快速排序算法)
(4).若排序中产生了临时文件,需要利用归并排序算法,保证临时文件中记录是有序的
(5).循环执行上述过程,直到所有满足条件的记录全部参与排序
(6).扫描排好序的(id,col2)对,并利用id去捞取SELECT需要返回的列(col1,col2,col3)
(7).将获取的结果集返回给用户。
从上述流程来看,是否使用文件排序主要看sort buffer是否能容下需要排序的(id,col2)对,这个buffer的大小由sort_buffer_size参数控制。此外一次排序需要两次IO,一次是捞(id,col2),第二次是捞(col1,col2,col3),由于返回的结果集是按col2排序,因此id是乱序的,通过乱序的id去捞(col1,col2,col3)时会产生大量的随机IO。对于第二次MySQL本身一个优化,即在捞之前首先将id排序,并放入缓冲区,这个缓存区大小由参数read_rnd_buffer_size控制,然后有序去捞记录,将随机IO转为顺序IO。
b.优化排序
常规排序方式除了排序本身,还需要额外两次IO。优化的排序方式相对于常规排序,减少了第二次IO。主要区别在于,放入sort buffer不是(id,col2),而是(col1,col2,col3)。由于sort buffer中包含了查询需要的所有字段,因此排序完成后可以直接返回,无需二次捞数据。这种方式的代价在于,同样大小的sort buffer,能存放的(col1,col2,col3)数目要小于(id,col2),如果sort buffer不够大,可能导致需要写临时文件,造成额外的IO。当然MySQL提供了参数max_length_for_sort_data,只有当排序元组小于max_length_for_sort_data时,才能利用优化排序方式,否则只能用常规排序方式。
c.优先队列排序
为了得到最终的排序结果,无论怎样,我们都需要将所有满足条件的记录进行排序才能返回。那么相对于优化排序方式,是否还有优化空间呢?5.6版本针对Order by limit M,N语句,在空间层面做了优化,加入了一种新的排序方式--优先队列,这种方式采用堆排序实现。堆排序算法特征正好可以解limit M,N 这类排序的问题,虽然仍然需要所有元素参与排序,但是只需要M+N个元组的sort buffer空间即可,对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素。
3.排序不一致问题
案例1
Mysql从5.5迁移到5.6以后,发现分页出现了重复值。
测试表与数据:
create table t1(id int primary key, c1 int, c2 varchar(128)); insert into t1 values(1,1,'a'); insert into t1 values(2,2,'b'); insert into t1 values(3,2,'c'); insert into t1 values(4,2,'d'); insert into t1 values(5,3,'e'); insert into t1 values(6,4,'f'); insert into t1 values(7,5,'g');
假设每页3条记录,第一页limit 0,3和第二页limit 3,3查询结果如下:

我们可以看到 id为4的这条记录居然同时出现在两次查询中,这明显是不符合预期的,而且在5.5版本中没有这个问题。产生这个现象的原因就是5.6针对limit M,N的语句采用了优先队列,而优先队列采用堆实现,比如上述的例子order by c1 asc limit 0,3 需要采用大小为3的大顶堆;limit 3,3需要采用大小为6的大顶堆。由于c1为2的记录有3条,而堆排序是非稳定的(对于相同的key值,无法保证排序后与排序前的位置一致),所以导致分页重复的现象。为了避免这个问题,我们可以在排序中加上唯一值,比如主键id,这样由于id是唯一的,确保参与排序的key值不相同。将SQL写成如下:
select * from t1 order by c1,id asc limit 0,3; select * from t1 order by c1,id asc limit 3,3;
案例2
两个类似的查询语句,除了返回列不同,其它都相同,但排序的结果不一致。
测试表与数据:
create table t2(id int primary key, status int, c1 varchar(255),c2 varchar(255),c3 varchar(255),key(c1)); insert into t2 values(7,1,'a',repeat('a',255),repeat('a',255)); insert into t2 values(6,2,'b',repeat('a',255),repeat('a',255)); insert into t2 values(5,2,'c',repeat('a',255),repeat('a',255)); insert into t2 values(4,2,'a',repeat('a',255),repeat('a',255)); insert into t2 values(3,3,'b',repeat('a',255),repeat('a',255)); insert into t2 values(2,4,'c',repeat('a',255),repeat('a',255)); insert into t2 values(1,5,'a',repeat('a',255),repeat('a',255));
分别执行SQL语句:
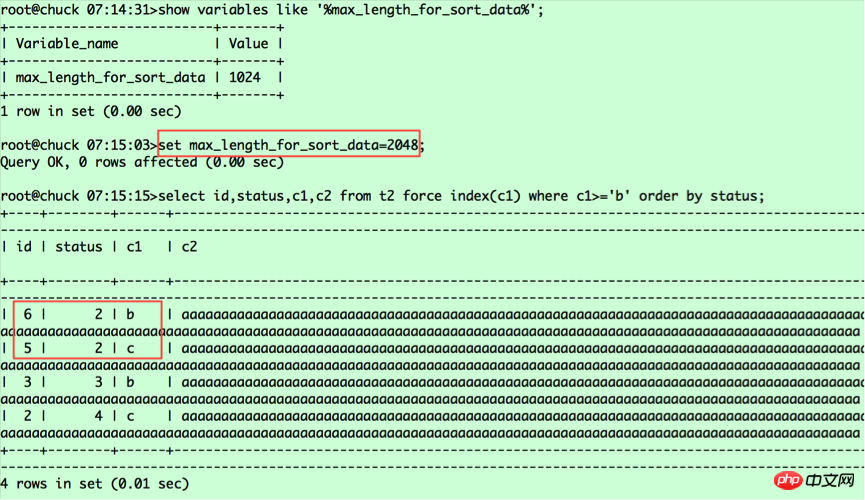
select id,status,c1,c2 from t2 force index(c1) where c1>='b' order by status; select id,status from t2 force index(c1) where c1>='b' order by status;
执行结果如下:

看看两者的执行计划是否相同

为了说明问题,我在语句中加了force index的hint,确保能走上c1列索引。语句通过c1列索引捞取id,然后去表中捞取返回的列。根据c1列值的大小,记录在c1索引中的相对位置如下:
(c1,id)===(b,6),(b,3),(5,c),(c,2),对应的status值分别为2 3 2 4。从表中捞取数据并按status排序,则相对位置变为(6,2,b),(5,2,c),(3,3,c),(2,4,c),这就是第二条语句查询返回的结果,那么为什么第一条查询语句(6,2,b),(5,2,c)是调换顺序的呢?这里要看我之前提到的a.常规排序和b.优化排序中标红的部分,就可以明白原因了。由于第一条查询返回的列的字节数超过了max_length_for_sort_data,导致排序采用的是常规排序,而在这种情况下MYSQL将rowid排序,将随机IO转为顺序IO,所以返回的是5在前,6在后;而第二条查询采用的是优化排序,没有第二次捞取数据的过程,保持了排序后记录的相对位置。对于第一条语句,若想采用优化排序,我们将max_length_for_sort_data设置调大即可,比如2048。
下面是本人关于mysql 自定义排序(field,INSTR,locate)的一点心得,希望对大家有所帮助
首先说明这里有三个函数(order by field,ORDER BY INSTR,ORDER BY locate)
原表:
id user pass aaa aaa bbb bbb ccc ccc ddd ddd eee eee fff fff
下面是我执行后的结果:
SELECT * FROM `user` order by field(2,3,5,4,id) asc
id user pass aaa aaa ccc ccc ddd ddd eee eee fff fff bbb bbb
根据结果分析:order by field(2,3,5,4,1,6) 结果显示顺序为:1 3 4 5 6 2
SELECT * FROM `user` order by field(2,3,5,4,id) desc
id user pass bbb bbb aaa aaa ccc ccc ddd ddd eee eee fff fff
根据结果分析:order by field(2,3,5,4,1,6) 结果显示顺序为:2 1 3 4 5 6
SELECT * FROM `user` ORDER BY INSTR( '2,3,5,4', id ) ASC
id user pass aaa aaa fff fff bbb bbb ccc ccc eee eee ddd ddd
根据结果分析:order by INSTR(2,3,5,4,1,6) 结果显示顺序为:1 6 2 3 5 4
SELECT * FROM `user` ORDER BY INSTR( '2,3,5,4', id ) DESC
id user pass ddd ddd eee eee ccc ccc bbb bbb aaa aaa fff fff
根据结果分析:order by INSTR(2,3,5,4,1,6) 结果显示顺序为:4 5 3 2 1 6
SELECT * FROM `user` ORDER BY locate( id, '2,3,5,4' ) ASC
id user pass
aaa aaa fff fff bbb bbb ccc ccc eee eee ddd ddd
根据结果分析:order by locate(2,3,5,4,1,6) 结果显示顺序为:1 6 2 3 5 4
SELECT * FROM `user` ORDER BY locate( id, '2,3,5,4' ) DESC
id user pass ddd ddd eee eee ccc ccc bbb bbb aaa aaa fff fff
根据结果分析:order by locate(2,3,5,4,1,6) 结果显示顺序为:4 5 3 2 1 6
如我想要查找的数据库中的ID顺序首先是(2,3,5,4)然后在是其它的ID顺序,你首先要把他降序排即(4 5 3 2),然后在 SELECT * FROM `user` ORDER BY INSTR( '4,5,3,2', id ) DESC limit 0,10 或用 SELECT * FROM `user` ORDER BY locate( id, '4,5,3,2' ) DESC 就得到你想要的结果了。
id user pass bbb bbb ccc ccc eee eee ddd ddd aaa aaa fff fff
【相关推荐】
1. 特别推荐:“php程序员工具箱”V0.1版本下载
2. MySQL免费视频教程

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
La construction d'une base de données SQL comprend 10 étapes: sélectionner des SGBD; Installation de SGBD; créer une base de données; créer une table; insérer des données; récupération de données; Mise à jour des données; supprimer des données; gérer les utilisateurs; sauvegarde de la base de données.
