
 Périphériques technologiques
IA
Application du codage positionnel dans Transformer : explorer les possibilités infinies de l'extrapolation de longueur
Périphériques technologiques
IA
Application du codage positionnel dans Transformer : explorer les possibilités infinies de l'extrapolation de longueur
Application du codage positionnel dans Transformer : explorer les possibilités infinies de l'extrapolation de longueur

Dans le domaine du traitement du langage naturel, le modèle Transformer a attiré beaucoup d'attention en raison de ses excellentes performances de modélisation de séquences. Cependant, en raison de la longueur limitée du contexte lors de sa formation, ni lui ni son grand modèle de langage basé sur celui-ci ne peuvent gérer efficacement les séquences dépassant cette limite de longueur. C'est ce qu'on appelle le manque de capacité « d'extrapolation de longueur effective ». Cela se traduit par des modèles de langage volumineux qui fonctionnent mal lors du traitement de textes longs, voire sont incapables de les gérer. Afin de résoudre ce problème, les chercheurs ont proposé une série de méthodes, telles que la méthode de troncature, la méthode segmentée et la méthode hiérarchique. Ces méthodes visent à améliorer les capacités d'extrapolation de longueur effective du modèle grâce à quelques astuces, afin qu'il puisse mieux gérer des séquences très longues. Bien que ces méthodes atténuent ce problème dans une certaine mesure, des recherches supplémentaires sont encore nécessaires pour améliorer davantage la capacité d'extrapolation de longueur effective du modèle afin de mieux s'adapter aux besoins des scénarios d'application pratiques.
La continuation du texte et l'extension du langage sont l'un des aspects importants de la capacité linguistique humaine. À l’ère des grands modèles, l’extrapolation de longueur est devenue une méthode importante pour appliquer efficacement les capacités du modèle aux données de séquences longues. La recherche sur cette question a une valeur théorique et pratique, c'est pourquoi des travaux connexes continuent d'émerger. Dans le même temps, une revue systématique est également nécessaire pour fournir une vue d’ensemble de ce domaine et repousser continuellement les limites des modèles linguistiques.
Des chercheurs de l'Institut de technologie de Harbin ont systématiquement examiné les progrès de la recherche sur le modèle Transformer en extrapolation de longueur du point de vue du codage de position. Les chercheurs se concentrent principalement sur les codes de position extrapolables et les méthodes d'extension basées sur ces codes pour améliorer la capacité d'extrapolation de longueur du modèle Transformer.

Lien papier : https://arxiv.org/abs/2312.17044
Codage de position extrapolable
Étant donné que le modèle Transformer lui-même ne peut pas capturer les informations de position de chaque mot dans la séquence, par conséquent le codage positionnel est devenu un ajout courant. Le codage de position peut être divisé en deux types : le codage de position absolue et le codage de position relative. Le codage de position absolue ajoute un vecteur de position à chaque mot de la séquence d'entrée pour représenter les informations de position absolue du mot dans la séquence. Le codage de position relative code la distance relative entre chaque paire de mots dans des positions différentes. Les deux méthodes de codage peuvent intégrer les informations sur l'ordre des éléments dans la séquence dans le modèle Transformer pour améliorer les performances du modèle.
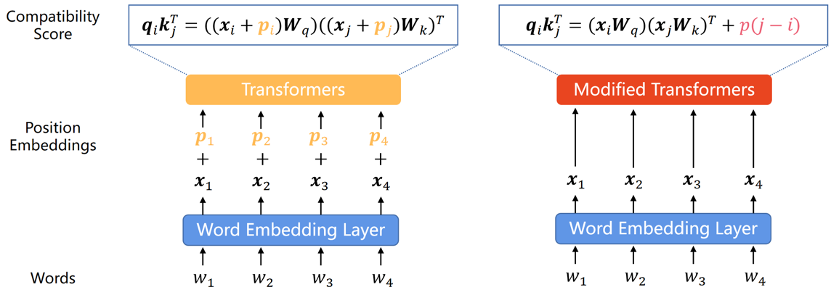
Étant donné que les recherches existantes montrent que cette classification est essentielle à la capacité d'extrapolation du modèle, nous diviserons cette section en fonction de cette classification.
Codage de position absolue
Dans l'article original de Transformer, le codage de position a été généré par les fonctions sinus et cosinus. Cette méthode, bien qu'elle ne soit pas bien extrapolée, a servi de premier Transformer A PE, sinus APE. a eu un impact profond sur l’EP ultérieure.
Pour améliorer les capacités d'extrapolation des modèles Transformer, les chercheurs intègrent l'invariance de déplacement dans l'APE sinusoïdale via des déplacements aléatoires, ou génèrent des intégrations de position qui varient en douceur avec la position et s'attendent à ce que le modèle apprenne à déduire cette fonction variable. Les méthodes basées sur ces idées présentent des capacités d’extrapolation plus fortes que l’APE sinusoïdale, mais ne peuvent toujours pas atteindre le niveau du RPE. L'une des raisons est que l'APE mappe différentes positions à différentes intégrations de positions, et l'extrapolation signifie que le modèle doit déduire des intégrations de positions invisibles. Il s’agit cependant d’une tâche difficile pour le modèle. Étant donné qu'il existe un nombre limité d'intégrations de positions récurrentes au cours d'une pré-formation approfondie, en particulier dans le cas du LLM, le modèle est très susceptible d'être surajusté à ces codages de position. Encodage de position relative . Ces dernières années, le RPE est devenu la méthode dominante pour coder les informations de position.
Les premiers RPE provenaient de simples modifications des codages de position sinusoïdale, souvent combinées à des stratégies d'élagage ou de regroupement pour éviter les intégrations de positions hors distribution, considérées comme bénéfiques pour l'extrapolation. De plus, étant donné que RPE dissocie la correspondance biunivoque entre la position et la représentation de position, l'ajout du terme de biais directement à la formule d'attention devient un moyen réalisable, voire meilleur, d'intégrer les informations de position dans Transformer. Cette approche est beaucoup plus simple et démêle naturellement le vecteur de valeur et les informations de position. Cependant, bien que ces méthodes de biais aient de fortes propriétés d’extrapolation, elles ne peuvent pas représenter des fonctions de distance complexes comme dans RoPE (Rotary Position Embedding). Par conséquent, bien que RoPE ait une extrapolation médiocre, il est récemment devenu le codage de position le plus courant pour les LLM en raison de ses excellentes performances globales. Tous les PE extrapolables introduits dans l'article sont présentés dans le tableau 1.
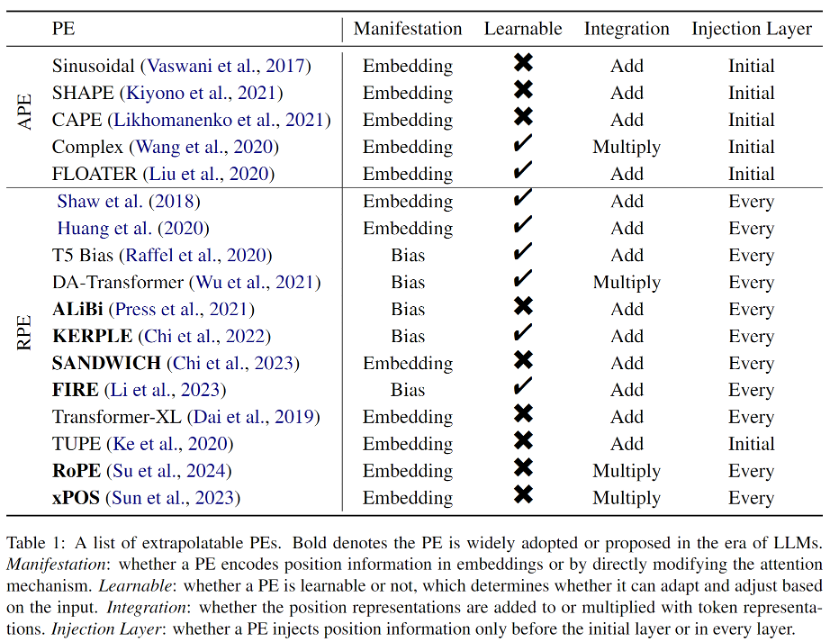
Méthodes d'extrapolation à l'ère des grands modèles
Afin d'améliorer les capacités d'extrapolation de longueur des LLM, les chercheurs ont proposé une variété de méthodes basées sur le codage de position existant, principalement divisées en interpolation de position (Position Interpolation) ) et codage de position aléatoire (Randomized Position Encoding) deux catégories.
Méthode d'interpolation de position
La méthode d'interpolation de position met à l'échelle les codes de position pendant l'inférence, de sorte que les codes de position qui dépassent à l'origine la longueur d'entraînement du modèle tombent dans l'intervalle de position entraîné après interpolation. Les méthodes d'interpolation positionnelle ont suscité un large intérêt de la part de la communauté des chercheurs en raison de leurs excellentes performances d'extrapolation et de leur surcharge extrêmement faible. De plus, contrairement à d’autres méthodes d’extrapolation, les méthodes d’interpolation positionnelle ont été largement utilisées dans les modèles open source tels que Code Llama, Qwen-7B et Llama2. Cependant, les méthodes d'interpolation actuelles se concentrent uniquement sur RoPE, et il reste encore à explorer comment faire en sorte que le LLM utilisant d'autres PE ait de meilleures capacités d'extrapolation grâce à l'interpolation.
Encodage positionnel aléatoire
En termes simples, le PE aléatoire découple simplement les fenêtres contextuelles pré-entraînées des longueurs d'inférence plus longues en introduisant des positions aléatoires pendant l'entraînement, améliorant ainsi les performances à long terme de toutes les positions dans le. fenêtre contextuelle. Il est à noter que l'idée de l'EP randomisée est très différente de la méthode d'interpolation de positions. La première vise à faire observer au modèle toutes les positions possibles pendant l'entraînement, tandis que la seconde essaie d'interpoler les positions lors de l'inférence afin qu'elles tombent dans. un emplacement prédéterminé. Pour la même raison, les méthodes d'interpolation positionnelle sont pour la plupart plug-and-play, tandis que l'EP aléatoire nécessite souvent un réglage plus fin, ce qui rend l'interpolation positionnelle plus attrayante. Cependant, ces deux catégories de méthodes ne s’excluent pas mutuellement et peuvent donc être combinées pour améliorer encore les capacités d’extrapolation du modèle.
Défis et orientations futures
Ensembles de données d'évaluation et de référence : Dans les premières recherches, l'évaluation des capacités d'extrapolation de Transformer provenait des indicateurs d'évaluation des performances de diverses tâches en aval, telles que le BLEU de la traduction automatique ; À mesure que les modèles de langage tels que T5 et GPT2 unifient progressivement les tâches de traitement du langage naturel, la perplexité utilisée dans la modélisation du langage est devenue un indice d'évaluation pour l'extrapolation. Cependant, les dernières recherches ont montré que la perplexité ne peut pas révéler la performance des tâches en aval. Il existe donc un besoin urgent de jeux de données de référence et de mesures d'évaluation dédiés pour promouvoir le développement ultérieur dans le domaine de l'extrapolation de longueur.
Explication théorique : Les travaux actuels liés à l'extrapolation de longueur sont principalement empiriques. Bien qu'il existe quelques tentatives préliminaires pour expliquer l'extrapolation réussie du modèle, une base théorique solide n'a pas encore été établie. Et dans quelle mesure les performances d'extrapolation en longueur sont affectées reste une question ouverte.
Autres méthodes : Comme mentionné dans cet article, la plupart des travaux d'extrapolation de longueur existants se concentrent sur la perspective de codage positionnel, mais il n'est pas difficile de comprendre que l'extrapolation de longueur nécessite une conception systématique. Le codage positionnel est un élément clé, mais en aucun cas le seul, et une vision plus large stimulera davantage le problème.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Vue et Element-UI Cascade déroulante Boîte en V Mode en V
Apr 07, 2025 pm 08:06 PM
Vue et Element-UI Cascade déroulante Boîte en V Mode en V
Apr 07, 2025 pm 08:06 PM
Vue et Element-UI Boîtes déroulantes en cascade Points de fosse de liaison V-model: V-model lie un tableau représentant les valeurs sélectionnées à chaque niveau de la boîte de sélection en cascade, pas une chaîne; La valeur initiale de SelectOptions doit être un tableau vide, non nul ou non défini; Le chargement dynamique des données nécessite l'utilisation de compétences de programmation asynchrones pour gérer les mises à jour des données en asynchrone; Pour les énormes ensembles de données, les techniques d'optimisation des performances telles que le défilement virtuel et le chargement paresseux doivent être prises en compte.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
