
 Périphériques technologiques
IA
TaskWeaver : un framework open source qui facilite l'analyse des données et la personnalisation sectorielle pour créer d'excellentes solutions d'agent
Périphériques technologiques
IA
TaskWeaver : un framework open source qui facilite l'analyse des données et la personnalisation sectorielle pour créer d'excellentes solutions d'agent
TaskWeaver : un framework open source qui facilite l'analyse des données et la personnalisation sectorielle pour créer d'excellentes solutions d'agent

L'analyse des données a toujours été un outil clé dans la société moderne, nous aidant à comprendre en profondeur l'essence, à découvrir des modèles et à guider la prise de décision. Cependant, le processus d’analyse des données est souvent complexe et prend du temps, c’est pourquoi nous attendons un assistant intelligent capable d’interagir directement avec les données. Avec le développement des grands modèles de langage (LLM), des assistants virtuels et des agents intelligents tels que Copilot sont apparus les uns après les autres, et leurs performances en matière de compréhension et de génération du langage naturel sont étonnantes. Malheureusement, les frameworks d'agents existants sont encore confrontés à des difficultés pour gérer des structures de données complexes (telles que DataFrame, ndarray, etc.) et introduire des connaissances de domaine, qui sont précisément l'exigence fondamentale dans l'analyse de données et dans les domaines professionnels.
Afin de mieux résoudre le problème de goulot d'étranglement des assistants vocaux lors de l'exécution de tâches, Microsoft a lancé un framework d'agents appelé TaskWeaver. Le framework est axé sur le code et peut convertir intelligemment les requêtes en langage naturel des utilisateurs en code exécutable, tout en prenant en charge une variété de structures de données et une sélection dynamique de plug-ins. De plus, TaskWeaver peut également être adapté professionnellement en fonction du processus de planification dans différents domaines, en utilisant pleinement le potentiel des grands modèles de langage. En tant que framework open source, TaskWeaver fournit des exemples et des plug-ins personnalisables pouvant intégrer des connaissances dans des domaines spécifiques, permettant aux utilisateurs de créer facilement des assistants virtuels personnalisés. Le lancement de TaskWeaver améliorera efficacement le niveau d'intelligence des assistants vocaux et répondra aux besoins croissants des utilisateurs en matière d'assistants virtuels personnalisés.

- Paper : TaskWeaver : A Code-First Agent Framework
- Adresse du papier : https://export.arxiv.org/abs/2311.17541
Le projet TaskWeaver est open source sur GitHub et est apparu sur la liste des tendances GitHub le jour de sa sortie. Actuellement, le projet a reçu 2,9 000 étoiles et a reçu de bonnes réponses. En outre, il existe également quelques cas pratiques sur des plateformes sociales telles que LinkedIn, comme l'utilisation de TaskWeaver pour l'analyse de données SAP. Ces cas démontrent l'utilité et la valeur de TaskWeaver.
- Project Home Page: https://microsoft.github.io/taskweaver/
- project Adresse: https://github.com/microsoft/taskweaver
Exemple d'histoire
Suivre les secrets cachés dans les données de vente
Xiaoya est une analyste commerciale, et l'une de ses tâches consiste à rechercher des anomalies dans les données de ventes récentes et, en fonction de ces anomalies, à guider l'entreprise pour ajuster son stratégie de soldes. Toutes les données de ventes sont stockées en toute sécurité dans une base de données SQL. Elle espère pouvoir extraire et analyser facilement des données grâce à une communication en langage naturel avec un assistant IA. Le fait que dans le monde de la vente, les anomalies sont uniques est particulièrement important. Elle espère donc que l'assistant IA pourra utiliser des algorithmes de détection d'anomalies personnalisés pour résoudre ce problème. Ce qui suit est l'enregistrement de discussion entre Xiaoya et l'assistant IA (Figure 1), montrant l'interaction entre eux. Xiaoya : Bonjour, j'ai besoin d'aide pour extraire les données de ventes de la base de données et les analyser. Assistant IA : OK, je vais tout de suite extraire les données correspondantes de la base de données. Je vous présenterai les données extraites plus tard pour confirmation. Xiaoya : Merci beaucoup. (Après un certain temps) Assistant IA : J'ai extrait les données de vente de la base de données. Voici un aperçu des données, veuillez confirmer. (Aperçu des données affichées par l'assistant AI) Xiaoya : Les données semblent bonnes, veuillez continuer la détection et l'analyse des anomalies. Assistant IA : Compris. J'effectuerai l'analyse à l'aide de notre algorithme de détection d'anomalies personnalisé et vous montrerai des visualisations intuitives dès que possible. (Après un certain temps) Assistant IA : analyse terminée. Veuillez consulter les résultats de visualisation suivants. (L'assistant IA affiche les résultats visuels) Xiaoya : Merci beaucoup pour votre aide ! Ces résultats me sont très précieux. Assistant IA : heureux de vous aider. Si vous avez d'autres questions ou avez besoin d'une analyse plus approfondie, n'hésitez pas à me le faire savoir. Xiaoya : Bien sûr, merci pour votre soutien.
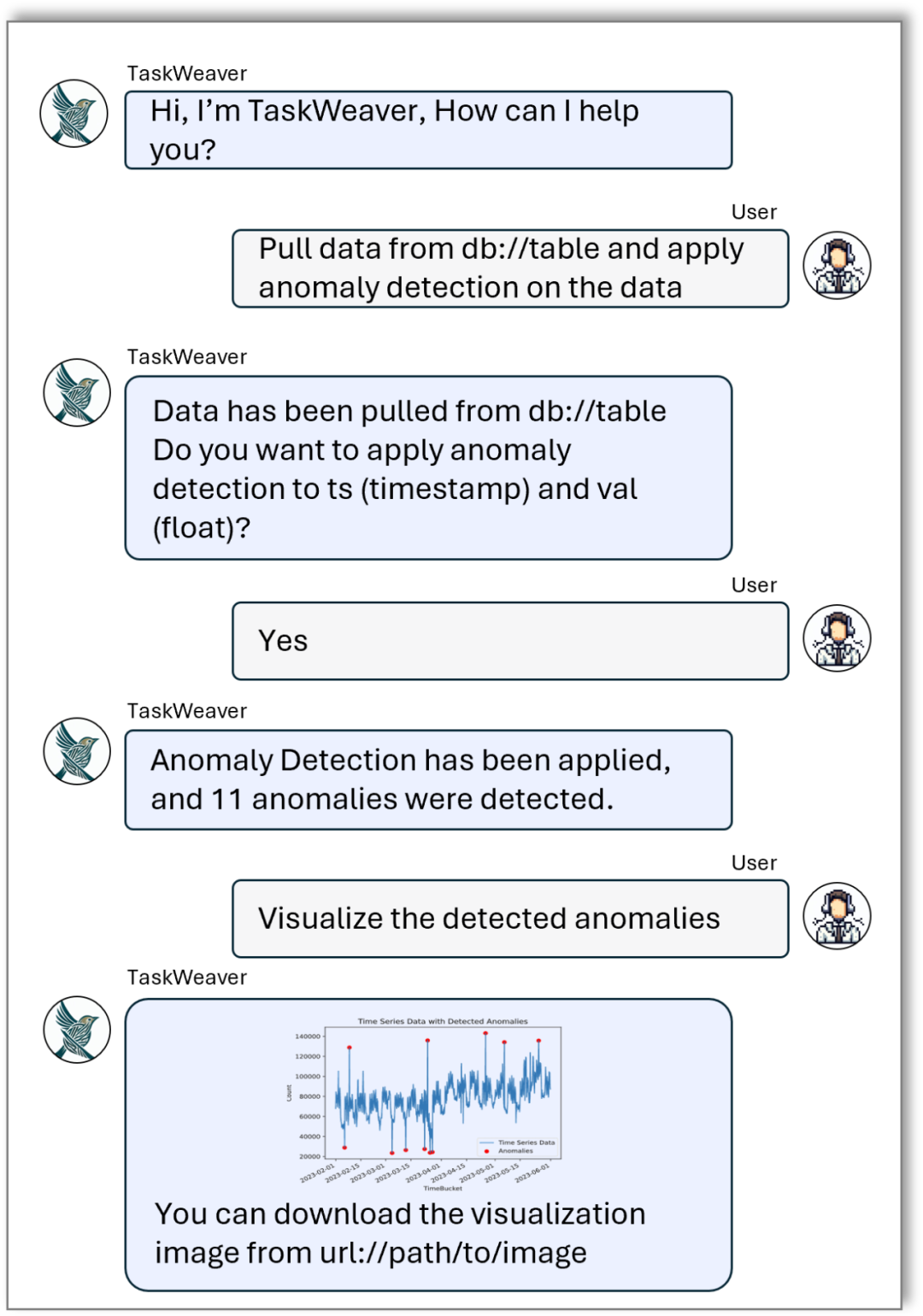
Figure 1. Transcription de la conversation dans l'exemple d'histoire
Quelles compétences sont requises pour le framework Agent ?
Grâce à l'histoire de Xiaoya mentionnée ci-dessus, nous avons identifié plusieurs fonctionnalités de base que le framework Agent devrait avoir :
1. Prise en charge du plug-in : Dans l'histoire ci-dessus, l'agent doit obtenir des données de la base de données, puis utiliser l'algorithme de détection d'anomalies spécifié. Afin d'accomplir ces tâches, l'assistant intelligent doit être capable de définir et d'appeler des plugins personnalisés, tels que le plugin "query_database" et le plugin "anomaly_detection".
2. Prise en charge de structures de données riches : l'agent doit traiter des structures de données complexes, telles que des tableaux, des matrices, des données de table, etc., pour effectuer en douceur un traitement de données avancé, tel que la prédiction, le clustering, etc. De plus, ces données doivent être transmises de manière transparente entre les différents plugins. Cependant, la plupart des frameworks d'agents existants convertissent les résultats intermédiaires de l'analyse des données en texte dans Prompt, ou les enregistrent d'abord sous forme de fichiers locaux, puis les lisent si nécessaire. Cependant, ces pratiques sont sujettes à des erreurs et dépassent la limite de mots d'invite.
3. Exécution avec état : l'agent doit souvent interagir avec l'utilisateur pendant plusieurs séries d'itérations, et générer et exécuter du code en fonction des entrées de l'utilisateur. Par conséquent, l’état d’exécution de ces codes doit être conservé tout au long de la session jusqu’à la fin de celle-ci.
4. Raisonnez d'abord puis agissez (ReAct) : L'agent doit avoir la capacité de ReAct, c'est-à-dire observer d'abord le raisonnement puis agir, ce qui est très nécessaire dans certains scénarios d'incertitude. Par exemple, dans l'exemple ci-dessus, étant donné que le schéma de données dans la base de données est généralement diversifié, l'agent doit d'abord obtenir les informations sur le schéma de données et comprendre quelles colonnes sont appropriées (et confirmer avec l'utilisateur), puis la colonne correspondante peut être nommée est entré dans l’algorithme de détection d’anomalies.
5. Générer du code arbitraire : Parfois, les plug-ins prédéfinis ne peuvent pas répondre à la demande de l'utilisateur, et l'agent doit être capable de générer du code pour répondre aux besoins temporaires de l'utilisateur. Dans l'exemple ci-dessus, l'agent doit générer du code pour visualiser les anomalies détectées, et ce processus est réalisé sans l'aide d'aucun plug-in.
6. Intégrer les connaissances du domaine : L'agent doit fournir une solution systématique pour intégrer les connaissances dans des domaines spécifiques. Cela aidera LLM à mieux planifier et à utiliser avec précision des outils pour produire des résultats fiables, en particulier dans des scénarios adaptés à l'industrie.
Révéler l'architecture de base de TaskWeaver
La figure 2 montre l'architecture globale de TaskWeaver, y compris le planificateur, l'interpréteur de code et le module de mémoire.
Le planificateur est comme le cerveau du système. Il a deux responsabilités principales : 1) Élaborer un plan, c'est-à-dire diviser les besoins de l'utilisateur en sous-tâches, envoyer ces sous-tâches une par une à l'interpréteur de code et les utiliser. tout au long du plan Il ajustera automatiquement le plan selon les besoins pendant le processus d'exécution ; 2) Répondra à l'utilisateur, il convertira les résultats des commentaires de l'interpréteur de code en réponses faciles à comprendre pour l'utilisateur et les enverra à l'utilisateur. .
L'interpréteur de code est principalement composé de deux composants : le générateur de code (Code Generator) recevra les sous-tâches envoyées par le planificateur, et combinera les plug-ins disponibles existants et les exemples de tâches spécifiques au domaine pour générer les blocs de code correspondants ; Code Executor est responsable de l'exécution du code généré et du maintien de l'état d'exécution tout au long de la session. De ce fait, des structures de données complexes peuvent être transmises en mémoire sans passer par les invites ou le système de fichiers. C'est comme la programmation en Python dans Jupyter Notebook, où l'utilisateur saisit un extrait de code dans une cellule, et l'état interne du programme est préservé lors de l'exécution séquentielle et peut être référencé par les processus ultérieurs. En termes de mise en œuvre, dans chaque session, l'exécuteur de code disposera d'un processus Python indépendant pour exécuter le code, prenant ainsi en charge plusieurs utilisateurs en même temps.
Le module de mémoire stocke principalement des informations utiles lors du fonctionnement de l'ensemble du système, telles que les résultats d'exécution, etc., et peut être écrite et lue par différents modules. La mémoire à court terme comprend principalement les enregistrements de communication entre l'utilisateur et TaskWeaver dans la session en cours, ainsi que les enregistrements de communication entre les modules. La mémoire à long terme comprend des connaissances de domaine qui peuvent être personnalisées à l'avance par l'utilisateur, ainsi que certaines expériences résumées au cours du processus d'interaction, etc.
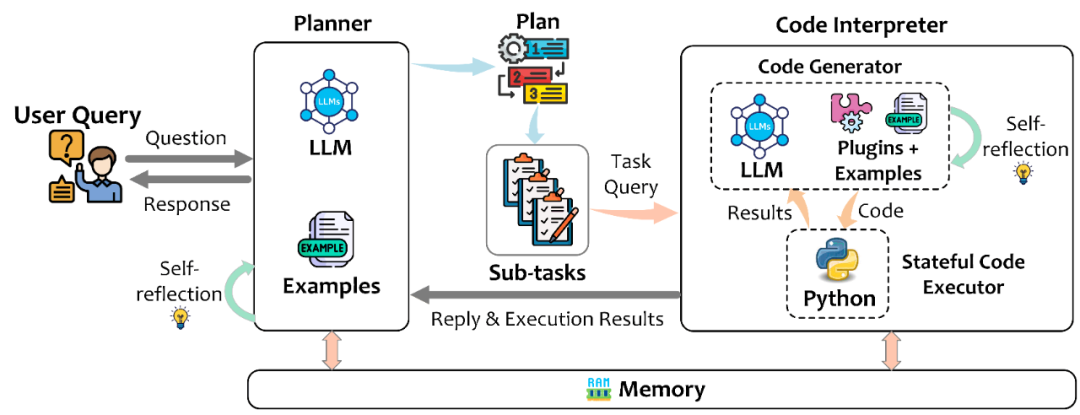
Figure 2. Schéma d'architecture globale de TaskWeaver
En plus de l'architecture de base, TaskWeaver propose également de nombreuses conceptions uniques. Par exemple, la compression de session réduit la taille du texte, permettant ainsi plus de tours de conversation, et la sélection dynamique de plug-ins sélectionne automatiquement les plug-ins appropriés en fonction des demandes des utilisateurs, permettant ainsi l'intégration de plug-ins plus personnalisés. De plus, TaskWeaver prend également en charge la fonction de sauvegarde d'expérience, qui peut être déclenchée par les utilisateurs saisissant des commandes pendant l'utilisation. Elle résumera l'expérience et les leçons de l'utilisateur dans la session en cours, évitera de répéter les erreurs lors de la session suivante et réalisera une véritable personnalisation. En termes de sécurité, TaskWeaver est également soigneusement conçu. Par exemple, les utilisateurs peuvent spécifier une liste blanche de modules Python. Si le code généré fait référence à des modules en dehors de la liste blanche, une erreur sera déclenchée, réduisant ainsi les risques de sécurité.
Le processus spécifique de TaskWeaver
La figure 3 nous montre une partie du processus par lequel TaskWeaver accomplit les exemples de tâches susmentionnées.
Tout d'abord, le planificateur reçoit les commentaires de l'utilisateur et génère un plan spécifique basé sur la description fonctionnelle de chaque module et des exemples de planification. Le plan contient quatre sous-tâches, dont la première consiste à extraire les données de la base de données et à décrire le schéma de données.
Le générateur de code génère ensuite un morceau de code basé sur la description de ses capacités et la définition de tous les plugins pertinents. Ce code appelle le plugin sql_pull_data pour enregistrer les données dans un DataFrame et fournir une description du schéma de données.
Enfin, le code généré sera envoyé à l'exécuteur de code pour exécution, et les résultats complétés seront envoyés au planificateur pour mettre à jour le plan ou passer à la sous-tâche suivante. Les résultats d'exécution dans la figure montrent qu'il y a deux colonnes dans le DataFrame, à savoir la date et la valeur. Le planificateur peut en outre confirmer auprès de l'utilisateur si ces colonnes sont correctes, ou passer directement à l'étape suivante consistant à appeler le plug-in anomaly_detection.
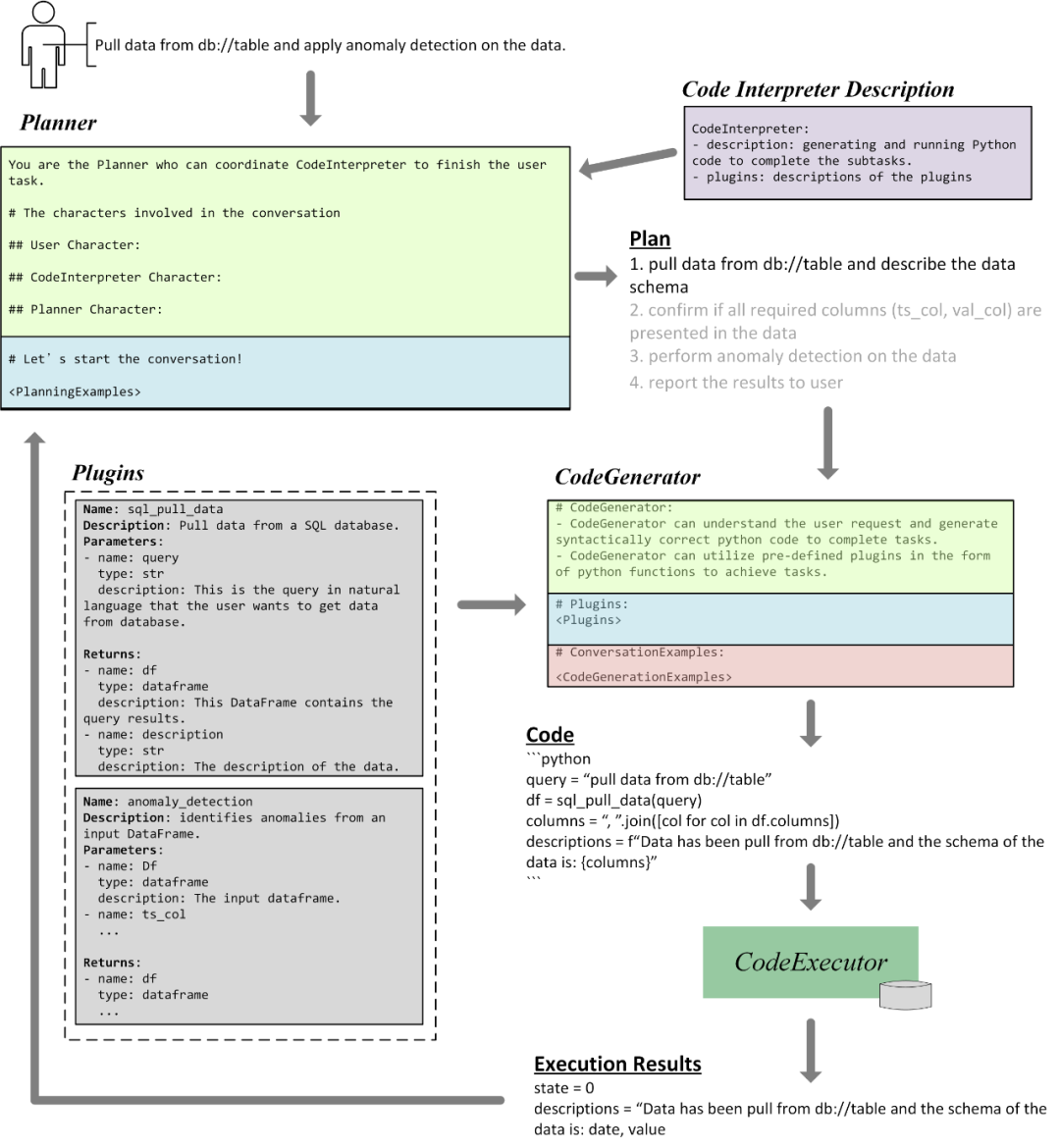
Figure 3. Workflow interne de TaskWeaver
Comment injecter des connaissances de domaine dans TaskWeaver ?
Dans les applications de grands modèles, l'objectif principal de l'intégration de connaissances spécifiques à un domaine est d'améliorer les performances de généralisation du LLM dans la personnalisation industrielle. TaskWeaver propose trois méthodes pour injecter des connaissances de domaine dans le modèle :
-
Personnalisation à l'aide de plug-ins : les utilisateurs peuvent intégrer des connaissances de domaine sous la forme de plug-ins personnalisés. Les plug-ins peuvent prendre de nombreuses formes, comme l'appel d'une API, la récupération de données d'une base de données spécifique ou l'exécution d'un algorithme ou d'un modèle d'apprentissage automatique spécifique. La personnalisation du plug-in est relativement simple. Il vous suffit de fournir des informations de base sur le plug-in (y compris le nom du plug-in, la description de la fonction, les paramètres d'entrée et les valeurs de retour) et l'implémentation Python.
-
Personnaliser à l'aide d'exemples : TaskWeaver fournit également aux utilisateurs une interface systématique (au format YAML) pour configurer des exemples afin d'apprendre à LLM comment répondre aux demandes des utilisateurs. Plus précisément, les exemples peuvent être divisés en deux types, utilisés pour la planification dans le planificateur et la programmation de code dans le générateur de code.
- Sauvegarde d'expérience : TaskWeaver aide les utilisateurs à résumer et à stocker le processus de session en cours dans une mémoire à long terme. Les utilisateurs peuvent « enseigner » à TaskWeaver leurs connaissances du domaine sous forme de conversations, puis enregistrer les conversations sous forme d'expériences. Dans le processus d'utilisation ultérieur, vous pouvez charger dynamiquement l'expérience pour mieux résoudre les problèmes du domaine professionnel.
Comment utiliser TaskWeaver ?
Le code complet de TaskWeaver est désormais open source sur GitHub. Actuellement, trois solutions sont prises en charge, à savoir le démarrage en ligne de commande, le service Web et l'importation sous forme de bibliothèque Python. Après une installation simple, les utilisateurs n'ont qu'à configurer quelques paramètres clés, tels que l'adresse de l'API LLM, la clé et le nom du modèle, pour démarrer facilement le service TaskWeaver.
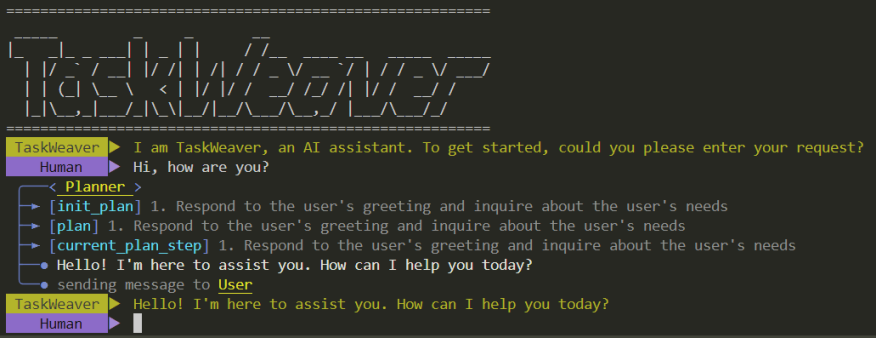
Figure 4. Interface de démarrage en ligne de commande
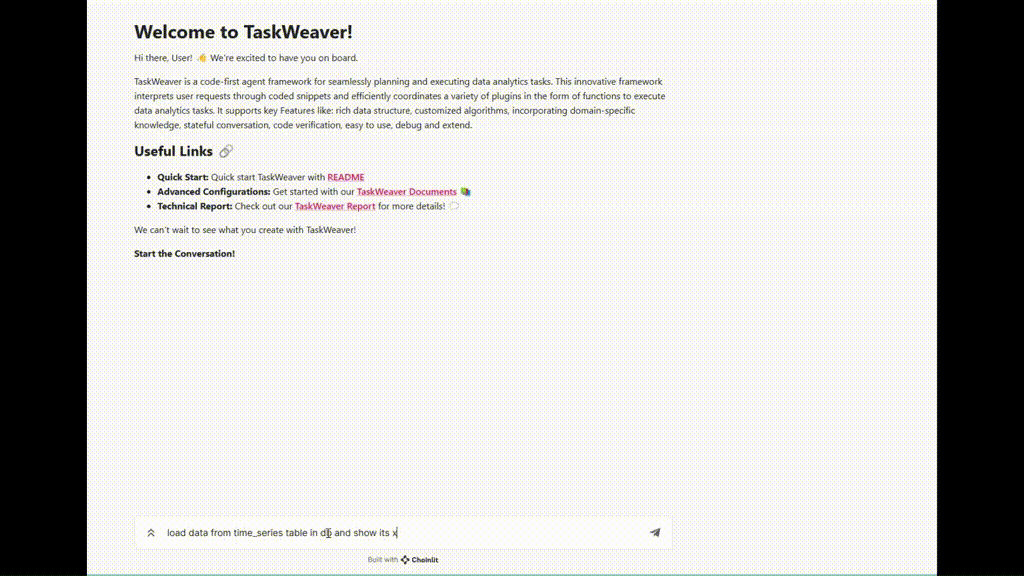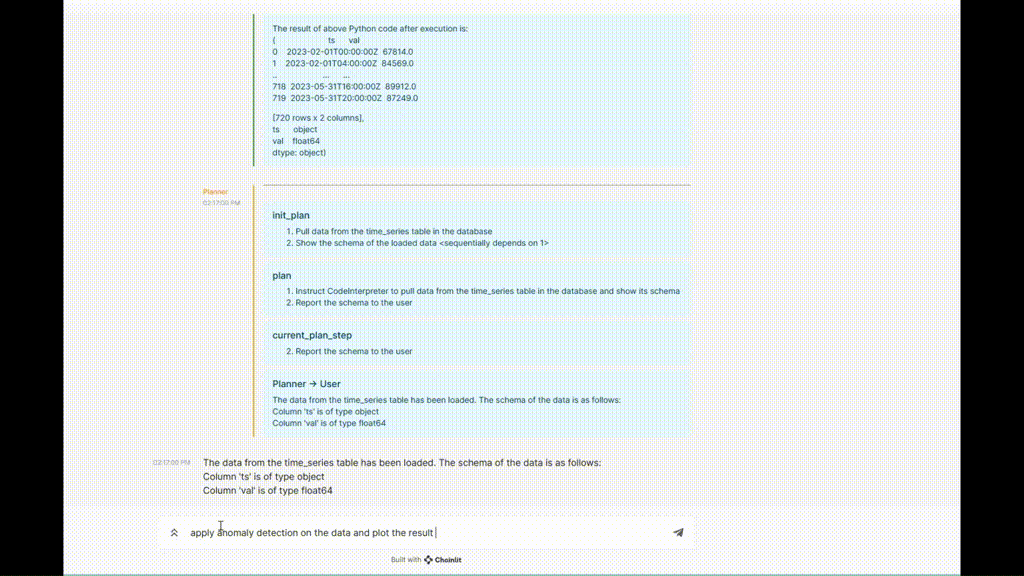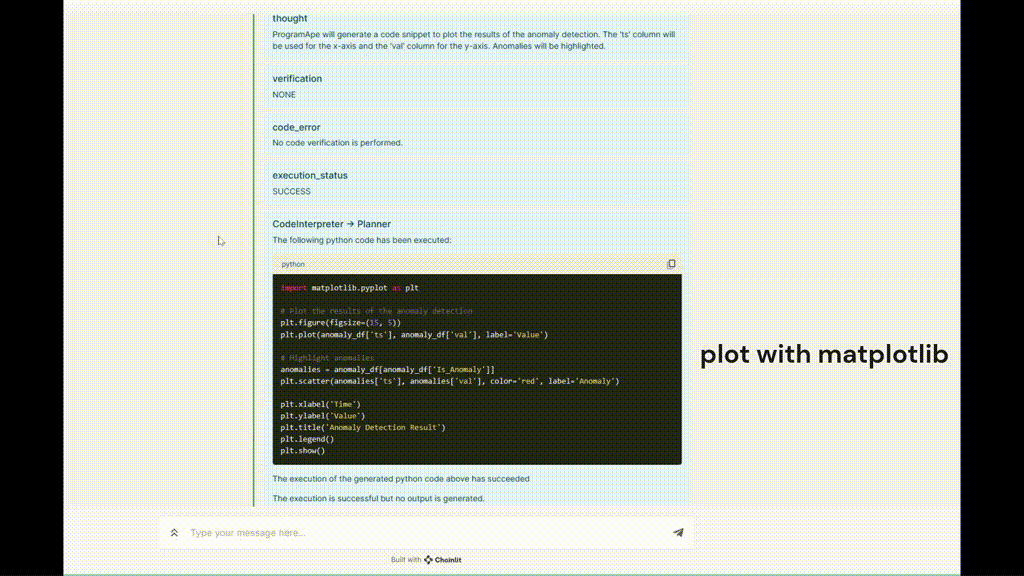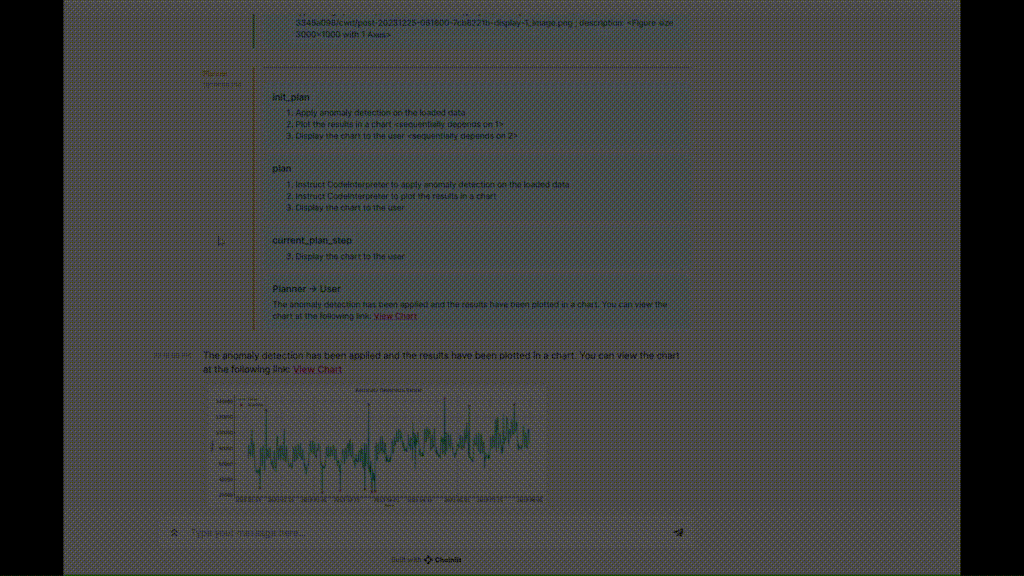
Figure 5. Exemple d'exécution de TaskWeaver
TaskWeaver est une nouvelle solution de framework d'agent conçue pour répondre aux besoins d'analyse de données et de scénarios de personnalisation de l'industrie. En convertissant le langage utilisateur en langage de programmation, « parler aux données » ne sera plus un rêve, mais une réalité.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
