
 Périphériques technologiques
IA
ReSimAD : Comment améliorer les performances de généralisation des modèles perceptuels grâce aux données virtuelles
Périphériques technologiques
IA
ReSimAD : Comment améliorer les performances de généralisation des modèles perceptuels grâce aux données virtuelles
ReSimAD : Comment améliorer les performances de généralisation des modèles perceptuels grâce aux données virtuelles

Écrit ci-dessus et compréhension personnelle de l'auteur
Les changements de domaine au niveau des capteurs des véhicules autonomes sont un phénomène très courant, comme les véhicules autonomes dans différentes scènes et emplacements, les véhicules autonomes sous différentes conditions d'éclairage et météorologiques, les véhicules autonomes équipés de différents équipements de capteurs, ce qui précède peut être considéré comme des différences classiques dans le domaine de la conduite autonome. Cette différence de domaine crée des défis pour la conduite autonome, principalement parce que les modèles de conduite autonome qui s'appuient sur d'anciennes connaissances de domaine sont difficiles à déployer directement dans un nouveau domaine jamais vu auparavant sans coût supplémentaire. Par conséquent, dans cet article, nous proposons un schéma de reconstruction-simulation-conscience (ReSimAD) pour fournir une nouvelle perspective et une nouvelle méthode de migration de domaine. Plus précisément, nous utilisons une technologie de reconstruction implicite pour obtenir des connaissances de domaine anciennes dans la scène de conduite. Le but du processus de reconstruction est d'étudier comment convertir les connaissances liées au domaine dans l'ancien domaine en représentations invariantes de domaine (représentations invariantes de domaine). Par exemple, nous pensons que les représentations de maillage 3D au niveau de la scène (représentations de maillage 3D) sont une représentation invariante au domaine. Sur la base des résultats reconstruits, nous utilisons en outre le simulateur pour générer un nuage de points de simulation plus réaliste similaire au domaine cible. Cette étape s'appuie sur les informations de fond reconstruites et la solution de capteur du domaine cible, réduisant ainsi le temps de collecte et d'étiquetage. le processus de détection ultérieur. Coût des nouvelles données de domaine.
Nous avons pris en compte différents paramètres inter-domaines dans la partie vérification expérimentale, notamment Waymo-to-KITTI, Waymo-to-nuScenes, Waymo-to-ONCE, etc. Tous les paramètres inter-domaines adoptent des paramètres expérimentaux sans tir, s'appuyant uniquement sur le maillage d'arrière-plan et les capteurs simulés du domaine source pour simuler des échantillons du domaine cible afin d'améliorer les capacités de généralisation du modèle. Les résultats montrent que ReSimAD peut grandement améliorer la capacité de généralisation du modèle de perception à la scène du domaine cible, encore mieux que certaines méthodes d'adaptation de domaine non supervisées.
Informations sur le papier

- Titre du papier : ReSimAD : Zero-Shot 3D Domain Transfer for Autonomous Driving with Source Reconstruction and Target Simulation
- ICLR-2024 accepté
- Unité de publication papier : Shanghai Artificial Intelligence Laboratory, Shanghai Université Jiao Tong, Université Fudan, Université Beihang
- Adresse papier : https://arxiv.org/abs/2309.05527
- Adresse code : Ensemble de données de simulation et partie perception, https://github.com/PJLab-ADG /3DTrans #resimad ; Partie reconstruction du domaine source, https://github.com/pjlab-ADG/neuralsim ; Partie simulation du domaine cible, https://github.com/PJLab-ADG/PCSim
Motivation de recherche
Défi : Bien que les modèles 3D puissent aider les voitures autonomes à reconnaître leur environnement, les modèles de base existants sont difficiles à généraliser à de nouveaux domaines (tels que différents paramètres de capteurs ou des villes invisibles). La vision à long terme dans le domaine de la conduite autonome est de permettre aux modèles de réaliser une migration de domaine à moindre coût, c'est-à-dire d'adapter avec succès un modèle entièrement formé sur le domaine source au scénario du domaine cible, où le domaine source et la cible Il existe respectivement deux domaines avec des différences évidentes de distribution des données. Par exemple, le domaine source est ensoleillé et le domaine cible est pluvieux ; le domaine source est un capteur à 64 faisceaux et le domaine cible est un capteur à 32 faisceaux.
Idées de solutions couramment utilisées : Face aux différences de domaine ci-dessus, la solution la plus courante consiste à obtenir et à annoter des données pour la scène du domaine cible. Cette méthode peut éviter dans une certaine mesure la dégradation des performances du modèle causée par les différences de domaine. Problème, mais il y a d'énormes 1) coûts de collecte de données et 2) coûts d'étiquetage des données. Par conséquent, comme le montre la figure ci-dessous (voir les deux méthodes de base (a) et (b)), afin de réduire le coût de la collecte et de l'annotation des données pour un nouveau domaine, le moteur de simulation peut être utilisé pour restituer certaines simulations. des échantillons de nuages de points. Il s'agit d'idées de solutions courantes pour les travaux de recherche de la simulation au réel. Une autre idée est l'adaptation de domaine non supervisée (UDA pour 3D). Le but de ce type de travail est d'étudier comment réaliser un réglage fin approximativement entièrement supervisé à condition d'être exposé uniquement à des données de domaine cible non étiquetées (notez qu'il s'agit de données réelles). ) Si cela peut être réalisé, cela permettra effectivement d'économiser le coût d'étiquetage du domaine cible, mais la méthode UDA doit encore collecter une grande quantité de données réelles du domaine cible pour caractériser la distribution des données du domaine cible.
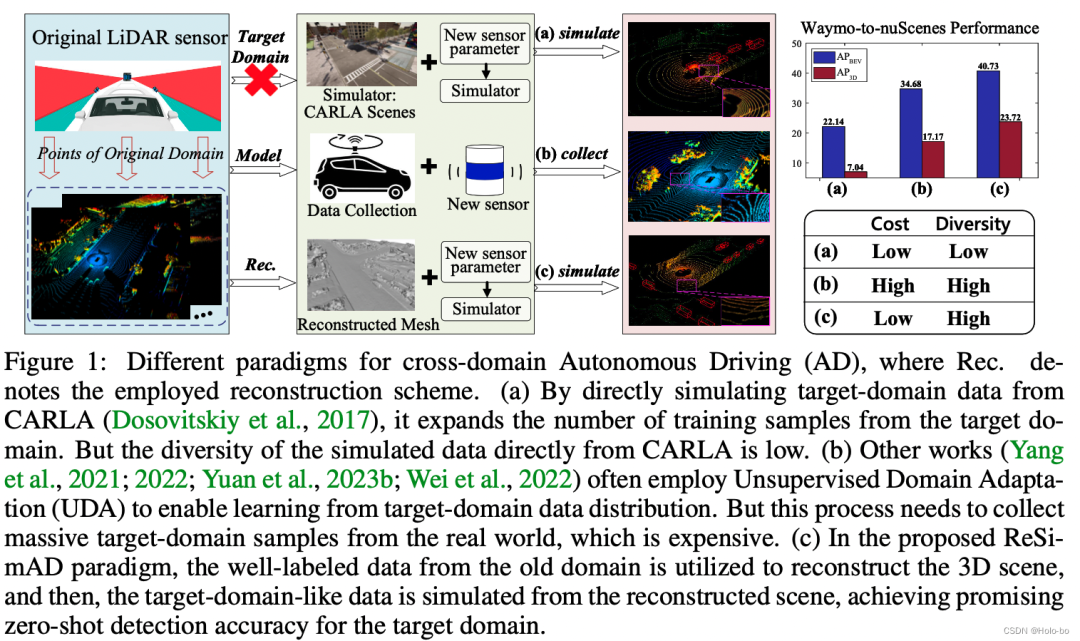 Figure 1 : Comparaison des différents paradigmes de formation
Figure 1 : Comparaison des différents paradigmes de formation
Notre idée : Différent des idées de recherche dans les deux catégories ci-dessus, comme le montre la figure ci-dessous (veuillez voir (c) processus de base), nous nous engageons dans la voie d'intégration de simulation-perception de données consistant à combiner le virtuel et le réel, dans lequel la réalité fait référence à : la construction d'une représentation invariante de domaine basée sur des données massives du domaine source étiquetées. Cette hypothèse a une signification pratique pour de nombreux scénarios, car après l'accumulation de données historiques à long terme, nous pouvons toujours penser que ces données du domaine source annotées existent. ; d'autre part, la simulation dans la combinaison de moyens virtuels et réels : après avoir construit une représentation invariante de domaine basée sur les données du domaine source, cette représentation peut être importée. Accédez au pipeline de rendu existant pour effectuer une simulation des données du domaine cible. Par rapport aux travaux de recherche actuels de simulation à réalité, notre méthode s'appuie sur des données réelles au niveau de la scène, y compris des informations réelles telles que la structure de la route, les pentes ascendantes et descendantes, etc. Ces informations sont difficiles à obtenir en s'appuyant uniquement sur le moteur de simulation. lui-même. Après avoir obtenu des données dans le domaine cible, nous intégrons les données dans le meilleur modèle de perception actuelle, tel que PV-RCNN, pour la formation, puis vérifions l'exactitude du modèle dans le domaine cible. Veuillez consulter la figure ci-dessous pour le flux de travail détaillé global :
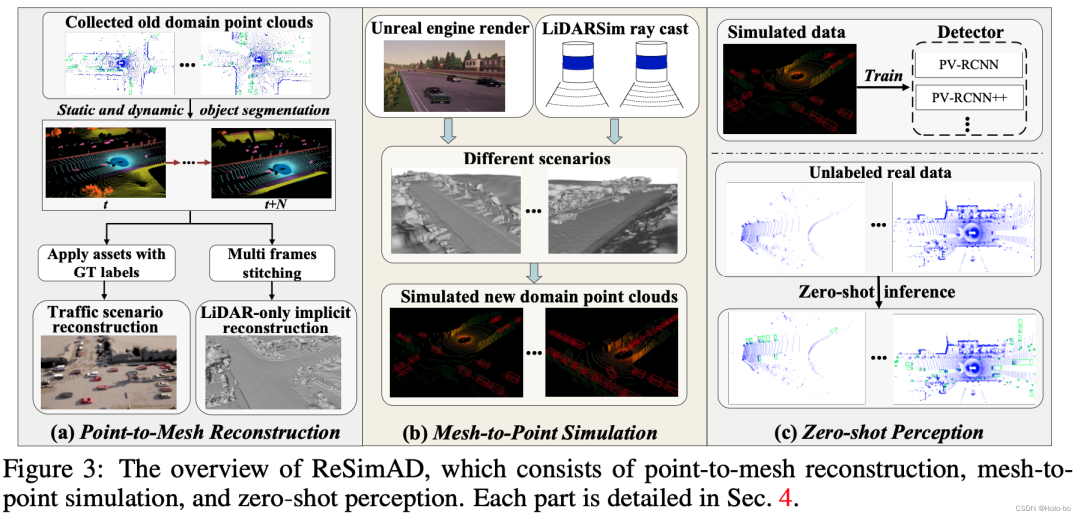 Figure 2 Organigramme de ReSimAD
Figure 2 Organigramme de ReSimAD
L'organigramme de ReSimAD est présenté dans la figure 2, qui comprend principalement a) Processus de reconstruction implicite point à maillage , b ) Processus de rendu du moteur de simulation maillage à point , c) Processus de perception sans échantillon .
ReSimAD : Paradigme de perception de la reconstruction par simulation
a) Processus de reconstruction implicite point à maillage : Inspirés de StreetSurf, nous utilisons uniquement la reconstruction lidar pour reconstruire des arrière-plans de scènes de rue réalistes et diversifiés, ainsi que des informations dynamiques sur les flux de trafic. Nous avons d'abord conçu un module de reconstruction SDF de nuage de points pur (LiDAR-only Implicit Neural Reconstruction, LINR). Son avantage est qu'il n'est pas affecté par certaines différences de domaine causées par la détection de la caméra, telles que : les changements d'éclairage, les changements de conditions météorologiques, etc. . Le module de reconstruction SDF de nuages de points purs prend les rayons LiDAR en entrée, puis prédit les informations de profondeur et construit enfin une représentation maillée 3D de la scène.
Plus précisément, pour la lumière 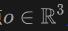 émise depuis l'origine
émise depuis l'origine 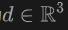 dans la direction
dans la direction 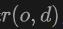 , nous appliquons le rendu de volume au lidar pour entraîner le réseau Signed Distance Field (SDF), et la profondeur de rendu D peut être formulée comme suit :
, nous appliquons le rendu de volume au lidar pour entraîner le réseau Signed Distance Field (SDF), et la profondeur de rendu D peut être formulée comme suit :
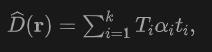
où est la La profondeur d'échantillonnage 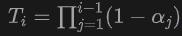 d'un point d'échantillonnage est la transmission accumulée, qui est obtenue en utilisant le modèle à courte portée dans NeuS.
d'un point d'échantillonnage est la transmission accumulée, qui est obtenue en utilisant le modèle à courte portée dans NeuS.
En s'inspirant de StreetSurf, l'entrée du modèle du processus de reconstruction proposé dans cet article provient des rayons lidar, et le résultat est la profondeur prédite. Sur chaque faisceau lidar échantillonné  , nous appliquons une perte logarithmique L1 sur
, nous appliquons une perte logarithmique L1 sur  , c'est-à-dire la profondeur de rendu des modèles combinés proche et distant :
, c'est-à-dire la profondeur de rendu des modèles combinés proche et distant :

Cependant, les méthodes LINR sont encore confrontées à certains défis. En raison de la rareté inhérente des données acquises par lidar, une seule image de nuage de points lidar ne peut capturer qu'une partie des informations contenues dans une image RVB standard. Cette différence met en évidence les inconvénients potentiels du rendu de profondeur pour fournir les détails géométriques nécessaires à un entraînement efficace. Par conséquent, cela peut conduire à un grand nombre d’artefacts dans le maillage reconstruit résultant. Pour relever ce défi, nous proposons de fusionner toutes les images dans une séquence Waymo pour augmenter la densité du nuage de points.
En raison de la limitation du champ de vision vertical du Top LiDAR dans l'ensemble de données Waymo, seule l'obtention de nuages de points entre -17,6° et 2,4° présente des limites évidentes sur la reconstruction des immeubles de grande hauteur environnants. Pour relever ce défi, nous introduisons une solution qui intègre des nuages de points de Side LiDAR dans une séquence d'échantillonnage pour la reconstruction. Quatre radars de remplissage aveugle sont installés à l'avant, à l'arrière et sur les deux côtés du véhicule autonome, avec un champ de vision vertical atteignant [-90°, 30°], ce qui compense efficacement les défauts du champ de vision insuffisant de le lidar supérieur. En raison de la différence de densité des nuages de points entre le lidar latéral et le lidar supérieur, nous choisissons d'attribuer un poids d'échantillonnage plus élevé au lidar latéral pour améliorer la qualité de reconstruction des scènes de bâtiments de grande hauteur.
Évaluation de la qualité de la reconstruction : En raison de l'occlusion causée par les objets dynamiques et de l'impact du bruit lidar, une représentation implicite peut exister dans une certaine quantité de bruit pour la reconstruction. Par conséquent, nous avons évalué la précision de la reconstruction. Étant donné que nous pouvons obtenir des données de nuages de points annotées massives à partir de l'ancien domaine, nous pouvons obtenir les données de nuages de points simulées de l'ancien domaine en effectuant un nouveau rendu sur l'ancien domaine pour évaluer la précision du maillage reconstruit. Nous mesurons le nuage de points simulé et le nuage de points réel d'origine, en utilisant l'erreur quadratique moyenne (RMSE) et la distance de chanfrein (CD) :
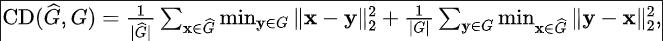
Le score de reconstruction de chaque séquence et la description de certains processus détaillés Veuillez vous référer à l'annexe originale.
b) Processus de rendu du moteur de simulation maillage à point : Après avoir obtenu le maillage d'arrière-plan statique via la méthode LINR ci-dessus, nous utilisons l'API Blender Python pour convertir les données de maillage du format .ply en 3D en .fbx formater les fichiers de modèle, et enfin charger le maillage d'arrière-plan en tant que bibliothèque d'actifs dans le simulateur open source CARLA.
Nous obtenons d'abord le fichier d'annotation de Waymo pour obtenir la catégorie de boîte englobante et la taille de l'objet tridimensionnel de chaque participant au trafic. Sur la base de ces informations, nous recherchons les participants au trafic dans la même catégorie avec la taille la plus proche dans la bibliothèque d'actifs numériques de CARLA. actifs et importez cet actif numérique en tant que modèle de participant au trafic. Sur la base des informations d'authenticité de la scène disponibles dans le simulateur CARLA, nous avons développé un outil d'extraction de boîte de détection pour chaque objet détectable dans la scène de circulation. Pour plus de détails, veuillez vous référer aux outils de développement PCSim.
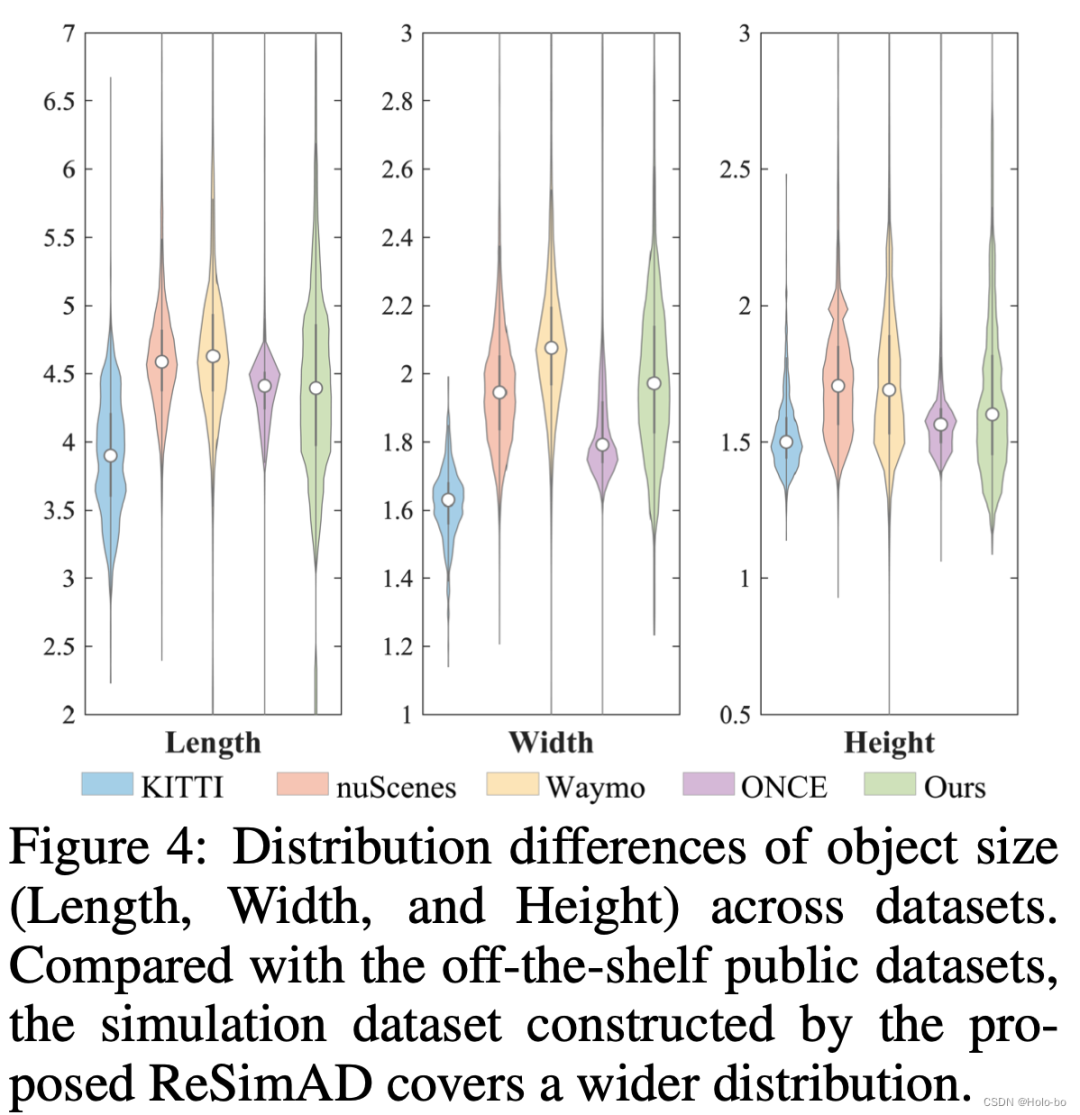
Figure 3 Répartition des tailles d'objets (longueur, largeur, hauteur) des usagers de la route dans différents ensembles de données. Comme le montre la figure 3, la diversité de distribution des tailles d'objets simulées à l'aide de cette méthode est très large, dépassant les ensembles de données actuellement publiés tels que KITTI, nuScenes, Waymo, ONCE, etc.
Ensemble de données de reconstruction-simulation ReSimAD
Nous utilisons Waymo comme données de domaine source et les reconstruisons sur Waymo pour obtenir un maillage 3D plus réaliste. Dans le même temps, nous utilisons KITTI, nuScenes et ONCE comme scénarios de domaine cible et vérifions les performances zéro obtenues par notre méthode dans ces scénarios de domaine cible.
Nous générons des données de maillage au niveau de la scène 3D basées sur l'ensemble de données Waymo conformément à l'introduction du chapitre ci-dessus, et utilisons les critères d'évaluation ci-dessus pour déterminer quels maillages 3D sont de haute qualité dans le domaine Waymo, et sélectionnons les 146 les plus élevés. maillages basés sur les scores. Le processus de simulation du domaine cible ultérieur.
 Résultats de l'évaluation
Résultats de l'évaluation
 Résultats de l'évaluation
Résultats de l'évaluationQuelques exemples de visualisation sur l'ensemble de données ResimAD sont présentés ci-dessous :
 Résultats de l'évaluation
Résultats de l'évaluation
Chapitre expérimental
Configuration expérimentale
- Sélection de base : Nous comparons le ReSimAD proposé avec trois croix typiques -les lignes de base de domaine sont comparées : a) une ligne de base qui utilise directement le moteur de simulation pour la simulation de données ; b) une ligne de base qui effectue une simulation de données en modifiant les paramètres du capteur dans le moteur de simulation ; c) une ligne de base d'adaptation de domaine (UDA).
- Métrique : nous alignons les normes d'évaluation actuelles pour la détection d'objets inter-domaines 3D, en utilisant respectivement l'AP basé sur BEV et basé sur 3D comme métriques d'évaluation.
- Paramètres : pour plus de détails, veuillez vous référer à l'article.
Résultats expérimentaux
Seuls les principaux résultats expérimentaux sont présentés ici. Pour plus de résultats, veuillez vous référer à notre article.
Performance d'adaptation des modèles PV-RCNN/PV-RCNN++ sous trois paramètres inter-domaines
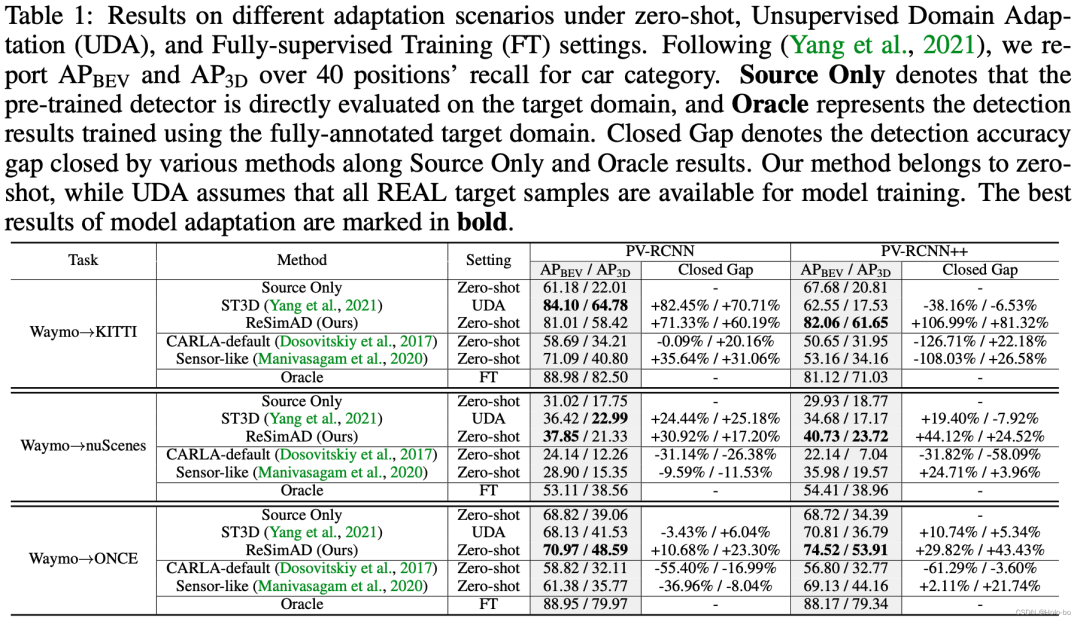
À partir du tableau ci-dessus, nous pouvons observer : La principale différence entre UDA et ReSimAD utilisant la technologie d'adaptation de domaine non supervisée (UDA) est que le premier utilise des échantillons du domaine cible scènes réelles pour la migration du domaine modèle, tandis que les paramètres expérimentaux de ReSimAD It nécessite qu'il ne puisse pas accéder à des données réelles de nuages de points dans le domaine cible. Comme le montre le tableau ci-dessus, les résultats inter-domaines obtenus par notre ReSimAD sont comparables à ceux obtenus par la méthode UDA. Ce résultat montre que lorsque le capteur lidar doit être mis à niveau à des fins commerciales, notre méthode peut réduire considérablement le coût de la collecte de données et raccourcir davantage le cycle de recyclage et de redéveloppement du modèle en raison des différences de domaine.
Les données ReSimAD sont utilisées comme données de démarrage à froid du domaine cible, et l'effet qui peut être obtenu sur le domaine cible
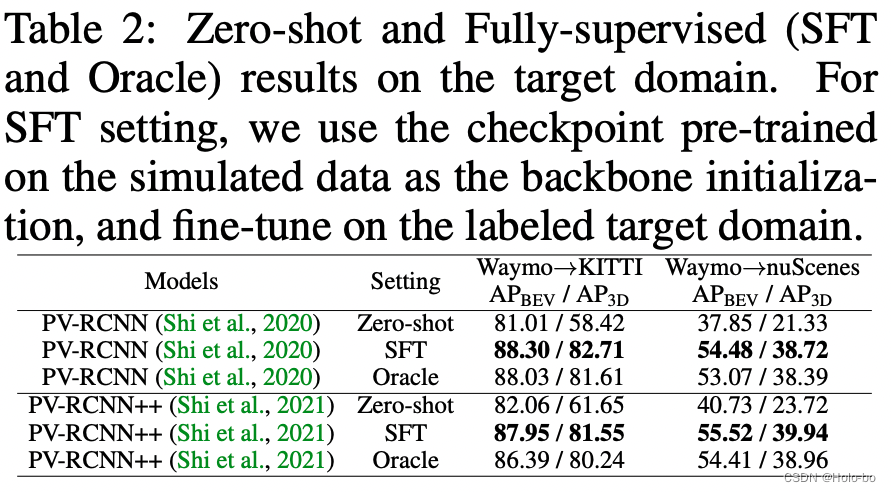
Un autre avantage de l'utilisation des données générées par ReSimAD est qu'elles peuvent être utilisées sans accéder toute distribution de données réelles du domaine cible peut être obtenue en même temps. Ce processus est en fait similaire au processus de « démarrage à froid » du modèle de conduite autonome dans les nouveaux scénarios.
Le tableau ci-dessus rapporte les résultats expérimentaux dans le domaine cible entièrement supervisé. Oracle représente le résultat de l'entraînement du modèle sur la quantité totale de données du domaine cible étiqueté, tandis que SFT représente que les paramètres d'initialisation du réseau du modèle de base sont fournis par les poids entraînés sur les données de simulation ReSimAD. Le tableau expérimental ci-dessus montre que le nuage de points simulé à l'aide de notre méthode ReSimAD peut obtenir des paramètres de poids d'initialisation plus élevés et que ses performances dépassent les paramètres expérimentaux d'Oracle.
Les données ReSimAD sont utilisées comme ensemble de données générales pour utiliser les performances de la méthode de pré-entraînement AD-PT sur différentes tâches en aval
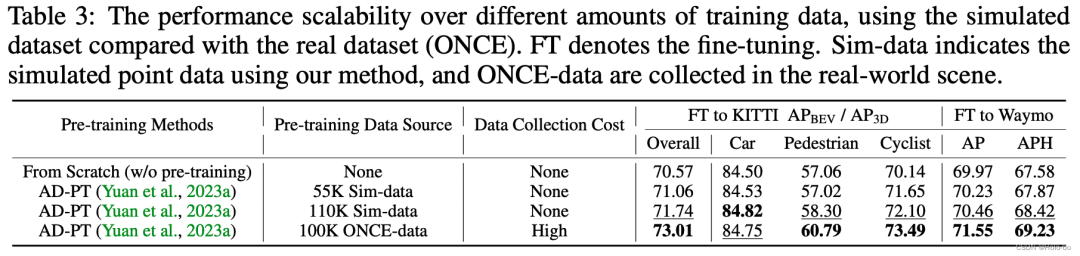
Afin de vérifier si ReSimAD peut générer plus de données de nuage de points pour aider à la pré-formation 3D -formation, nous concevons Les expériences suivantes ont été menées : AD-PT (une méthode récemment proposée pour pré-entraîner les réseaux fédérateurs dans des scénarios de conduite autonome) a été utilisé pour pré-entraîner le backbone 3D sur le nuage de points simulé, puis le réel en aval les données de scène ont été utilisées pour le réglage précis des paramètres.
- Nous utilisons ReSimAD pour générer des données avec une distribution plus large de nuages de points. Pour une comparaison équitable avec les résultats de pré-entraînement dans AD-PT, le volume cible de données de nuages de points simulés générées par ReSimAD est d'environ . Dans le tableau ci-dessus, nos détecteurs de base sont pré-entraînés en 3D sur des données de pré-entraînement réelles (ensemble de données ONCE) et des données de pré-entraînement simulées (fournies par ReSimAD), en utilisant la méthode AD-PT, et sur les ensembles de données KITTI et Waymo. réglage fin en aval. Les résultats du tableau ci-dessus montrent que l'utilisation de données de simulation de pré-entraînement de différentes tailles peut améliorer continuellement les performances du modèle en aval. De plus, on peut voir que le coût d'acquisition des données de pré-entraînement obtenues par ReSimAD est très faible, par rapport à l'utilisation de ONCE pour le pré-entraînement du modèle, et les performances de pré-entraînement obtenues par ReSimAD sont comparables à celles de pré-entraînement. performances sur l’ensemble de données ONCE Comparaison de.
Simulation reconstruite à l'aide de ReSimAD et comparaison visuelle à l'aide de la simulation par défaut CARLA
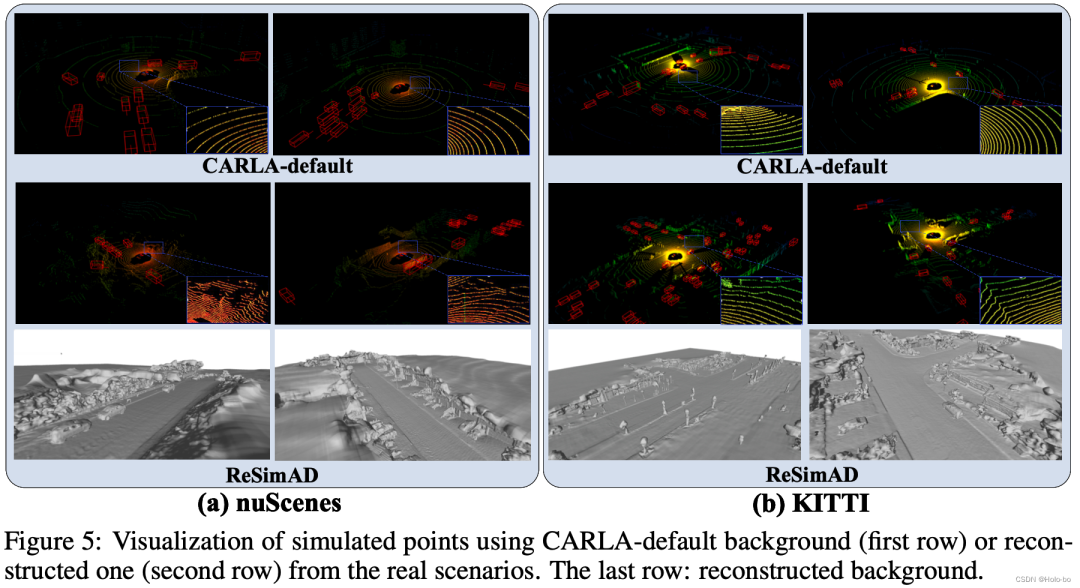
Comparaison visuelle du maillage que nous avons reconstruit sur la base de l'ensemble de données Waymo et reconstruit à l'aide de VDBFusion

Summ ary
dans ce travail, nous nous engageons à étudier comment expérimenter des tâches de transfert de modèle de domaine cible à échantillon nul. Cette tâche nécessite que le modèle puisse transférer avec succès le modèle pré-entraîné du domaine source vers la cible sans être exposé à aucun. exemples d'informations sur les données du scénario de domaine cible. Contrairement aux travaux précédents, nous avons exploré pour la première fois une technologie de génération de données 3D basée sur la reconstruction implicite du domaine source et la simulation de diversité du domaine cible, et avons vérifié que cette technologie permet d'obtenir un meilleur modèle sans être exposée à la distribution des données de le domaine cible. Les performances de migration sont encore meilleures que certaines méthodes d’adaptation de domaine non supervisées (UDA).

Lien original : https://mp.weixin.qq.com/s/pmHFDvS7nXy-6AQBhvVzSw
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
