
 Périphériques technologiques
IA
Le potentiel des VLM open source est libéré par le framework RoboFlamingo
Périphériques technologiques
IA
Le potentiel des VLM open source est libéré par le framework RoboFlamingo
Le potentiel des VLM open source est libéré par le framework RoboFlamingo

Ces dernières années, la recherche sur les grands modèles s'est accélérée et a progressivement démontré une compréhension multimodale et des capacités de raisonnement temporel et spatial dans diverses tâches. Diverses tâches opérationnelles incarnées des robots nécessitent naturellement des exigences élevées en matière de compréhension des commandes linguistiques, de perception des scènes et de planification spatio-temporelle. Cela conduit naturellement à une question : les capacités des grands modèles peuvent-elles être pleinement utilisées et migrées vers le domaine de la robotique ? planifier directement la séquence d'action sous-jacente ?
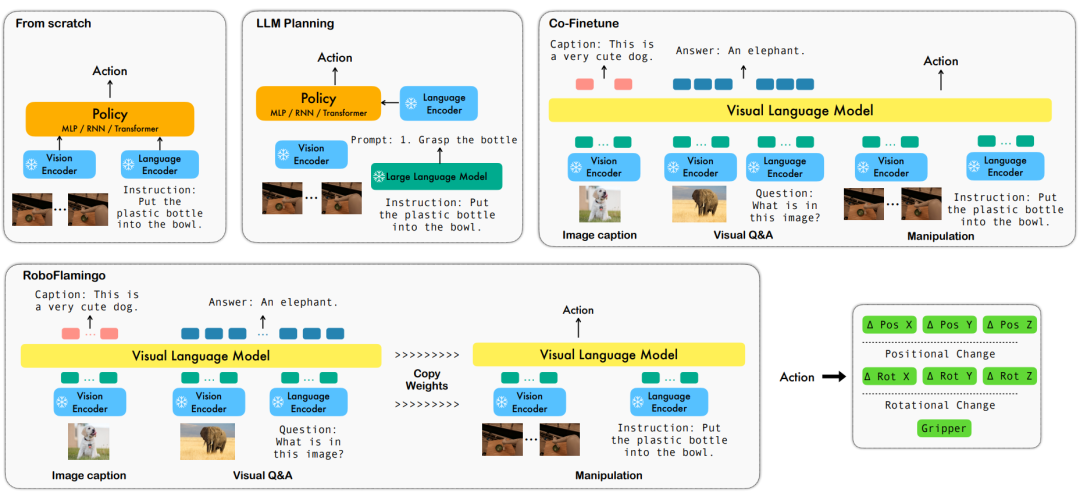
ByteDance Research utilise le grand modèle de vision de langage multimodal open source OpenFlamingo pour développer un modèle de fonctionnement de robot RoboFlamingo facile à utiliser qui ne nécessite qu'une formation sur une seule machine. Le VLM peut être transformé en VLM robotique grâce à un simple réglage fin, qui convient aux tâches d'exploitation des robots d'interaction linguistique.
Vérifié par OpenFlamingo sur l'ensemble de données de fonctionnement du robot CALVIN. Les résultats expérimentaux montrent que RoboFlamingo utilise seulement 1 % des données avec annotation linguistique et atteint les performances SOTA dans une série de tâches d'exploitation du robot. Avec l'ouverture de l'ensemble de données RT-X, RoboFlamingo, qui est pré-entraîné sur des données open source et affiné pour différentes plates-formes de robots, devrait devenir un processus de modèle de robot à grande échelle simple et efficace. L'article a également testé les performances de réglage précis de VLM avec différents chefs de stratégie, différents paradigmes de formation et différentes structures Flamingo sur les tâches du robot, et est parvenu à des conclusions intéressantes.

- Page d'accueil du projet : https://roboflamingo.github.io
- Adresse du code : https://github.com/RoboFlamingo/RoboFlamingo
- Adresse papier : https://arxiv.org/abs/2311.01378
Contexte de recherche
Le fonctionnement d'un robot basé sur le langage est une application importante dans le domaine de l'intelligence incorporée, impliquant des données multimodales. et le traitement, y compris la vision, le langage et le contrôle. Ces dernières années, les modèles basés sur le langage visuel (VLM) ont fait des progrès significatifs dans des domaines tels que la description d'images, la réponse visuelle aux questions et la génération d'images. Cependant, l’application de ces modèles aux opérations des robots se heurte encore à des défis, tels que la manière d’intégrer les informations visuelles et linguistiques et la manière de gérer la séquence temporelle des opérations des robots. La résolution de ces défis nécessite des améliorations dans de multiples aspects, tels que l'amélioration des capacités de représentation multimodale du modèle, la conception de mécanismes de fusion de modèles plus efficaces et l'introduction de structures et d'algorithmes de modèle qui s'adaptent à la nature séquentielle des opérations du robot. De plus, il est nécessaire de développer des ensembles de données robotiques plus riches pour former et évaluer ces modèles. Grâce à une recherche et à une innovation continues, les opérations robotisées basées sur le langage devraient jouer un rôle plus important dans les applications pratiques et fournir des services plus intelligents et plus pratiques aux humains.
Afin de résoudre ces problèmes, l'équipe de recherche en robotique de ByteDance Research a affiné le VLM (Visual Language Model) open source existant - OpenFlamingo, et a conçu un nouveau cadre de manipulation du langage visuel appelé RoboFlamingo. La caractéristique de ce cadre est qu'il utilise VLM pour parvenir à une compréhension du langage visuel en une seule étape et traite les informations historiques via un module de tête de politique supplémentaire. Grâce à des méthodes simples de réglage fin, RoboFlamingo peut être adapté aux tâches d'exploitation de robots basées sur le langage. L’introduction de ce cadre devrait résoudre une série de problèmes existants dans les opérations actuelles des robots.
RoboFlamingo a été vérifié sur l'ensemble de données de fonctionnement du robot basé sur le langage CALVIN. Les résultats expérimentaux montrent que RoboFlamingo n'utilise que 1 % des données annotées par le langage et atteint des performances SOTA (plus de 10 %) sur une série d'opérations de robot. tâches.Le taux de réussite de la séquence de tâches de l'apprentissage des tâches est de 66 %, le nombre moyen de tâches terminées est de 4,09, la méthode de base est de 38 %, le nombre moyen de tâches terminées est de 3,06 ; %, le nombre moyen de tâches terminées est de 2,48, la méthode de référence est de 1 %, le nombre moyen de tâches terminées est de 0,67), et peut obtenir une réponse en temps réel grâce à un contrôle en boucle ouverte, et peut être déployé de manière flexible sur des niveaux inférieurs. plateformes de performances. Ces résultats démontrent que RoboFlamingo est une méthode efficace de manipulation de robot et peut constituer une référence utile pour les futures applications robotiques.
Méthode
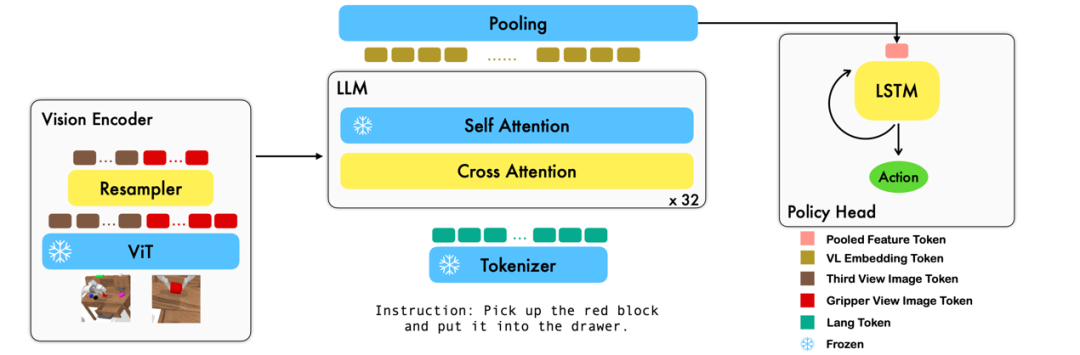
Ce travail utilise le modèle de base du langage visuel existant basé sur des paires image-texte pour générer les actions relatives de chaque étape du robot grâce à un entraînement de bout en bout. Le modèle se compose de trois modules principaux : l'encodeur de vision, le décodeur de fusion de fonctionnalités et le responsable de la politique. Dans le module d'encodeur Vision, l'observation visuelle actuelle est d'abord entrée dans ViT, puis le jeton sorti par ViT est sous-échantillonné via le ré-échantillonneur. Cette étape permet de réduire la dimension d'entrée du modèle, améliorant ainsi l'efficacité de la formation. Le module de décodeur de fusion de fonctionnalités prend des jetons de texte en entrée et utilise la sortie de l'encodeur visuel comme requête via un mécanisme d'attention croisée, réalisant ainsi la fusion des fonctionnalités visuelles et linguistiques. Dans chaque couche, le décodeur de fusion de caractéristiques effectue d'abord l'opération d'attention croisée, puis exécute l'opération d'auto-attention. Ces opérations permettent d'extraire des corrélations entre le langage et les caractéristiques visuelles pour mieux générer les actions du robot. Sur la base des séquences de jetons actuelles et historiques émises par le décodeur de fusion de fonctionnalités, le responsable de la politique génère directement les actions relatives actuelles à 7 DoF, y compris la pose d'extrémité du bras du robot à 6 dimensions et l'ouverture/fermeture de la pince à 1 dimension. Enfin, effectuez un pooling maximum sur le décodeur de fusion de fonctionnalités et envoyez-le au responsable de la politique pour générer des actions relatives. De cette manière, notre modèle est capable de fusionner efficacement les informations visuelles et linguistiques pour générer des mouvements précis du robot. Cela offre de larges perspectives d’application dans des domaines tels que le contrôle des robots et la navigation autonome.
Pendant le processus de formation, RoboFlamingo utilise les paramètres ViT, LLM et Cross Attention pré-entraînés et affine uniquement les paramètres du rééchantillonneur, de l'attention croisée et du responsable de la politique.
Résultats expérimentaux
Ensemble de données :
CALVIN (Composing Actions from Language and Vision) est une référence de simulation open source pour l'apprentissage de tâches opérationnelles à long horizon basées sur le langage. Par rapport aux ensembles de données de tâches visuo-linguistiques existants, les tâches de CALVIN sont plus complexes en termes de longueur de séquence, d'espace d'action et de langage, et prennent en charge une spécification flexible des entrées des capteurs. CALVIN est divisé en quatre divisions ABCD, chaque division correspond à un contexte et une disposition différents.
Analyse quantitative :
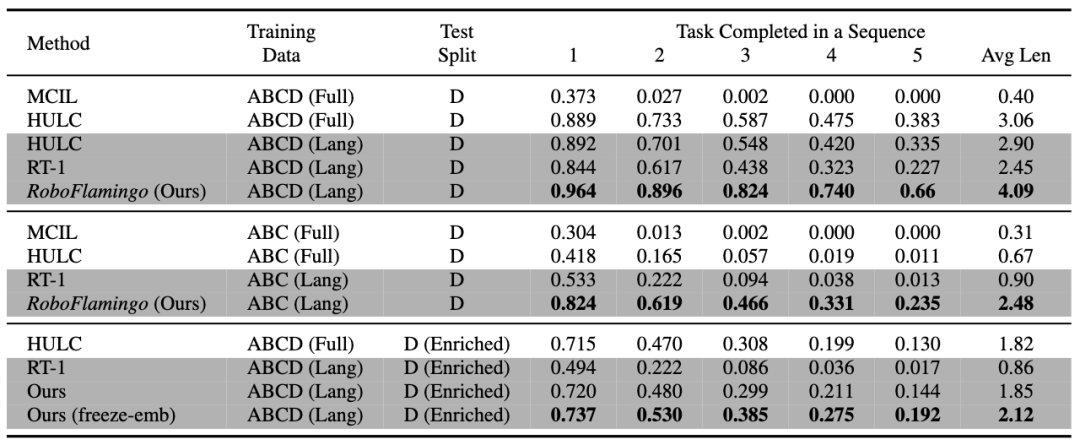
RoboFlamingo a les meilleures performances dans tous les paramètres et indicateurs, ce qui montre qu'il a une forte capacité d'imitation, une capacité de généralisation visuelle et une capacité de généralisation linguistique. Full et Lang indiquent si le modèle a été formé à l'aide de données visuelles non appariées (c'est-à-dire des données visuelles sans appariement de langues) ; Freeze-emb fait référence au gel de la couche d'intégration du décodeur fusionné ; Enriched indique l'utilisation d'instructions améliorées GPT-4 ;
Expériences d'ablation :
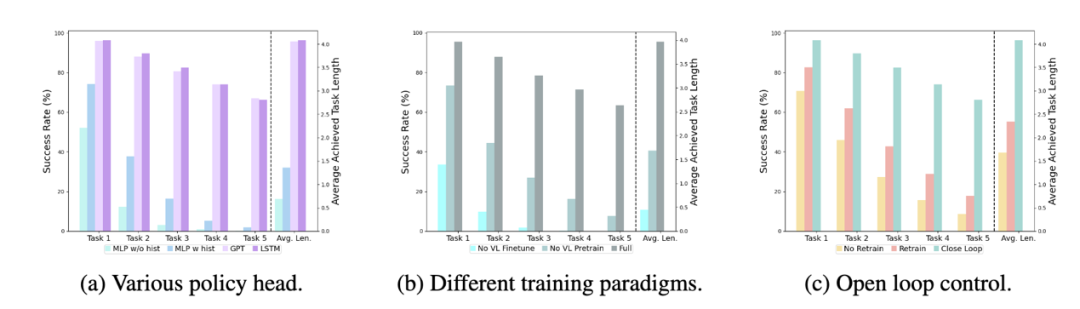
Différents chefs de politique :
Les expériences ont examiné quatre chefs de politique différents : MLP sans hist, MLP avec hist, GPT et LSTM. Parmi eux, MLP sans hist prédit directement l'historique sur la base des observations actuelles, et ses performances sont les pires avec la fusion des observations historiques du côté de l'encodeur de vision et prédit les actions, et les performances sont améliorées. au niveau du responsable politique respectivement, conserve implicitement les informations historiques et ses performances sont les meilleures, ce qui illustre l'efficacité de la fusion des informations historiques via le responsable politique.
L'impact du pré-entraînement visuel-langage :
Le pré-entraînement joue un rôle clé dans l'amélioration des performances de RoboFlamingo. Les expériences montrent que RoboFlamingo est plus performant dans les tâches robotiques grâce à un pré-entraînement sur un vaste ensemble de données visuo-linguistiques.
Taille et performances du modèle :
Alors que les modèles généralement plus grands conduisent à de meilleures performances, les résultats expérimentaux montrent que même des modèles plus petits peuvent rivaliser avec de grands modèles sur certaines tâches.
Impact du réglage fin des instructions :
Le réglage fin des instructions est une technique puissante, et les résultats expérimentaux montrent qu'elle peut encore améliorer les performances du modèle.
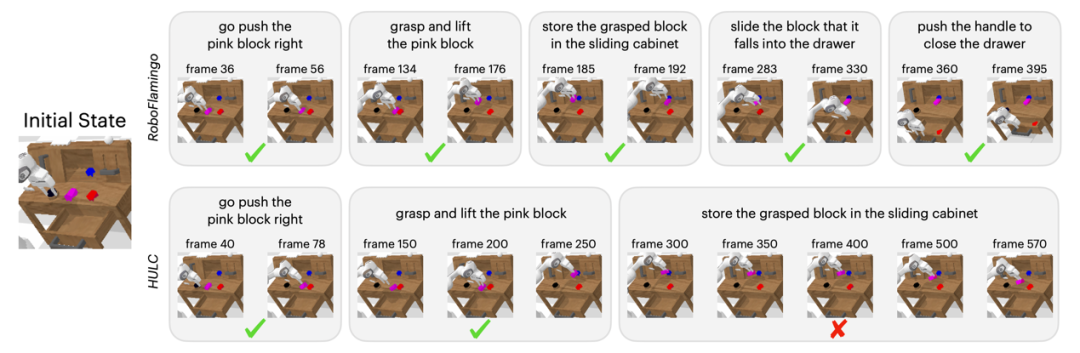
Résultats qualitatifs
Par rapport à la méthode de base, RoboFlamingo a non seulement exécuté complètement 5 sous-tâches consécutives, mais a également pris beaucoup moins d'étapes pour les deux premières sous-tâches qui ont exécuté avec succès la page de base.
Résumé
Ce travail fournit un nouveau cadre basé sur des VLM open source existants pour les stratégies d'exploitation de robots interactifs avec un langage, qui peuvent obtenir d'excellents résultats avec de simples ajustements. RoboFlamingo fournit aux chercheurs en robotique un puissant framework open source qui peut exploiter plus facilement le potentiel des VLM open source. Les riches résultats expérimentaux de ces travaux peuvent fournir une expérience et des données précieuses pour l'application pratique de la robotique et contribuer à la recherche et au développement technologique futurs.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Vue et Element-UI Cascade déroulante Boîte en V Mode en V
Apr 07, 2025 pm 08:06 PM
Vue et Element-UI Cascade déroulante Boîte en V Mode en V
Apr 07, 2025 pm 08:06 PM
Vue et Element-UI Boîtes déroulantes en cascade Points de fosse de liaison V-model: V-model lie un tableau représentant les valeurs sélectionnées à chaque niveau de la boîte de sélection en cascade, pas une chaîne; La valeur initiale de SelectOptions doit être un tableau vide, non nul ou non défini; Le chargement dynamique des données nécessite l'utilisation de compétences de programmation asynchrones pour gérer les mises à jour des données en asynchrone; Pour les énormes ensembles de données, les techniques d'optimisation des performances telles que le défilement virtuel et le chargement paresseux doivent être prises en compte.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
