
 Périphériques technologiques
IA
Évaluation de LeCun : Méta-évaluation de ConvNet et Transformer, laquelle est la plus forte ?
Périphériques technologiques
IA
Évaluation de LeCun : Méta-évaluation de ConvNet et Transformer, laquelle est la plus forte ?
Évaluation de LeCun : Méta-évaluation de ConvNet et Transformer, laquelle est la plus forte ?

Comment choisir un modèle visuel en fonction de besoins spécifiques ?
Comment les modèles ConvNet/ViT et supervisés/CLIP se comparent-ils sur des indicateurs autres qu'ImageNet ?
La dernière recherche publiée par des chercheurs du MABZUAI et Meta compare de manière exhaustive les modèles visuels courants sur des indicateurs « non standards ».

Adresse papier : https://arxiv.org/pdf/2311.09215.pdf
LeCun a fait l'éloge de cette recherche et l'a qualifiée d'excellente recherche. L'étude compare des architectures ConvNext et VIT de taille similaire, fournissant une comparaison complète de diverses propriétés lors d'une formation en mode supervisé et à l'aide des méthodes CLIP.

Au-delà de la précision d'ImageNet
Le paysage des modèles de vision par ordinateur devient de plus en plus diversifié et complexe.
Des premiers ConvNets à l'évolution des Vision Transformers, les types de modèles disponibles sont en constante expansion.
De même, les paradigmes de formation ont évolué de la formation supervisée sur ImageNet à l'apprentissage auto-supervisé et à la formation par paires image-texte comme CLIP.

Tout en marquant des progrès, cette explosion d'options pose un défi majeur aux praticiens : Comment choisir le modèle cible qui vous convient ?
La précision d'ImageNet a toujours été le principal indicateur pour évaluer les performances du modèle. Depuis qu’il a déclenché la révolution du deep learning, il a permis des avancées significatives dans le domaine de l’intelligence artificielle.
Cependant, il ne peut pas mesurer les nuances des modèles résultant de différentes architectures, paradigmes de formation et données.
Si on les juge uniquement par la précision d'ImageNet, les modèles avec des propriétés différentes peuvent se ressembler (Figure 1). Cette limitation devient plus apparente à mesure que le modèle commence à suradapter les fonctionnalités d'ImageNet et atteint la saturation en termes de précision.
Pour combler le fossé, les chercheurs ont mené une exploration approfondie du comportement du modèle au-delà de la précision d'ImageNet.
Afin d'étudier l'impact de l'architecture et des objectifs de formation sur les performances du modèle, Vision Transformer (ViT) et ConvNeXt ont été spécifiquement comparés. La précision de la validation ImageNet-1K et les exigences informatiques de ces deux architectures modernes sont comparables.
De plus, l'étude a comparé les modèles supervisés représentés par DeiT3-Base/16 et ConvNeXt-Base, ainsi que l'encodeur visuel d'OpenCLIP basé sur le modèle CLIP.

Analyse des résultats
L'analyse des chercheurs a été conçue pour étudier le comportement d'un modèle qui peut être évalué sans formation ni ajustement supplémentaire.
Cette approche est particulièrement importante pour les praticiens disposant de ressources informatiques limitées, car ils s'appuient souvent sur des modèles pré-entraînés.
Dans l'analyse spécifique, bien que les auteurs reconnaissent la valeur des tâches en aval telles que la détection d'objets, l'accent est mis sur les fonctionnalités qui fournissent des informations avec des exigences de calcul minimales et reflètent des comportements importants pour les applications du monde réel.
Erreurs de modèle
ImageNet-X est un ensemble de données qui étend ImageNet-1K avec une annotation manuelle détaillée de 16 facteurs changeants, permettant une analyse approfondie des erreurs de modèle dans la classification des images.
Il utilise le taux d'erreur (le plus faible est le mieux) pour quantifier les performances du modèle sur des facteurs spécifiques par rapport à la précision globale, permettant une analyse nuancée des erreurs du modèle. Les résultats sur ImageNet-X montrent :
1 Par rapport à sa précision ImageNet, le modèle CLIP fait moins d'erreurs que le modèle supervisé.
2. Tous les modèles sont principalement affectés par des facteurs complexes tels que l'occlusion.
3. La texture est le facteur le plus difficile de tous les modèles.
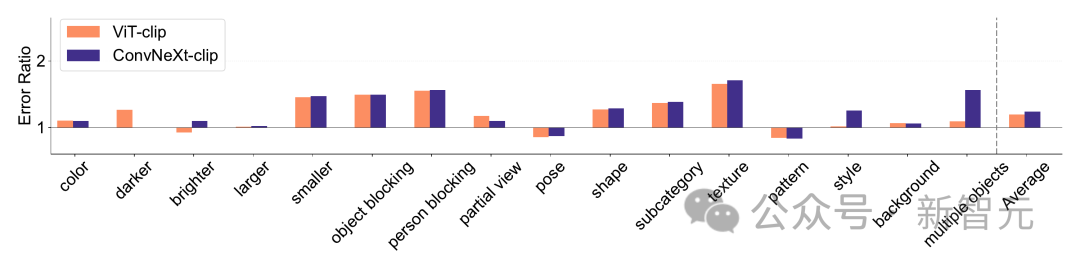
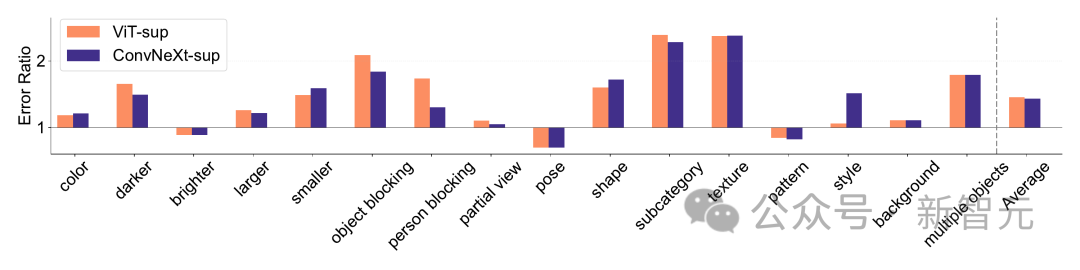
Biais de forme/texture
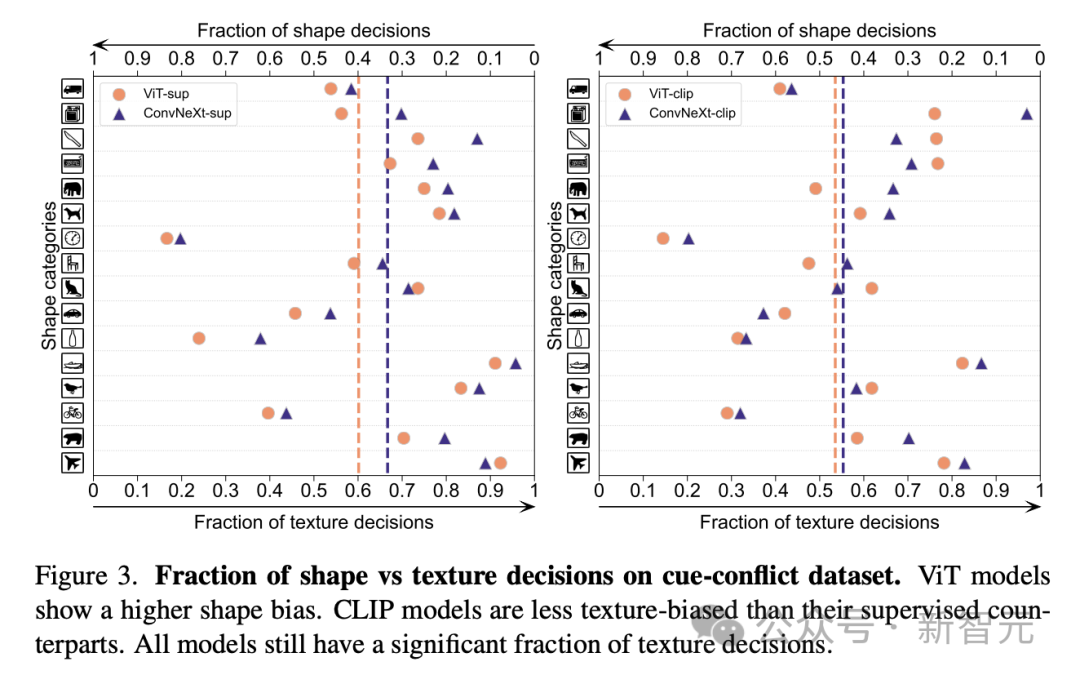
Biais de forme/texture vérifie si le modèle s'appuie sur des raccourcis de texture plutôt que sur des astuces de forme avancées.
Ce biais peut être étudié en combinant des images contradictoires de différentes catégories de formes et de textures.
Cette approche permet de comprendre dans quelle mesure les décisions du modèle sont basées sur la forme par rapport à la texture.
Les chercheurs ont évalué le biais de forme-texture sur l'ensemble de données de conflit de signaux et ont découvert que le biais de texture du modèle CLIP était inférieur à celui du modèle supervisé, tandis que le biais de forme du modèle ViT était supérieur à celui des ConvNets. .
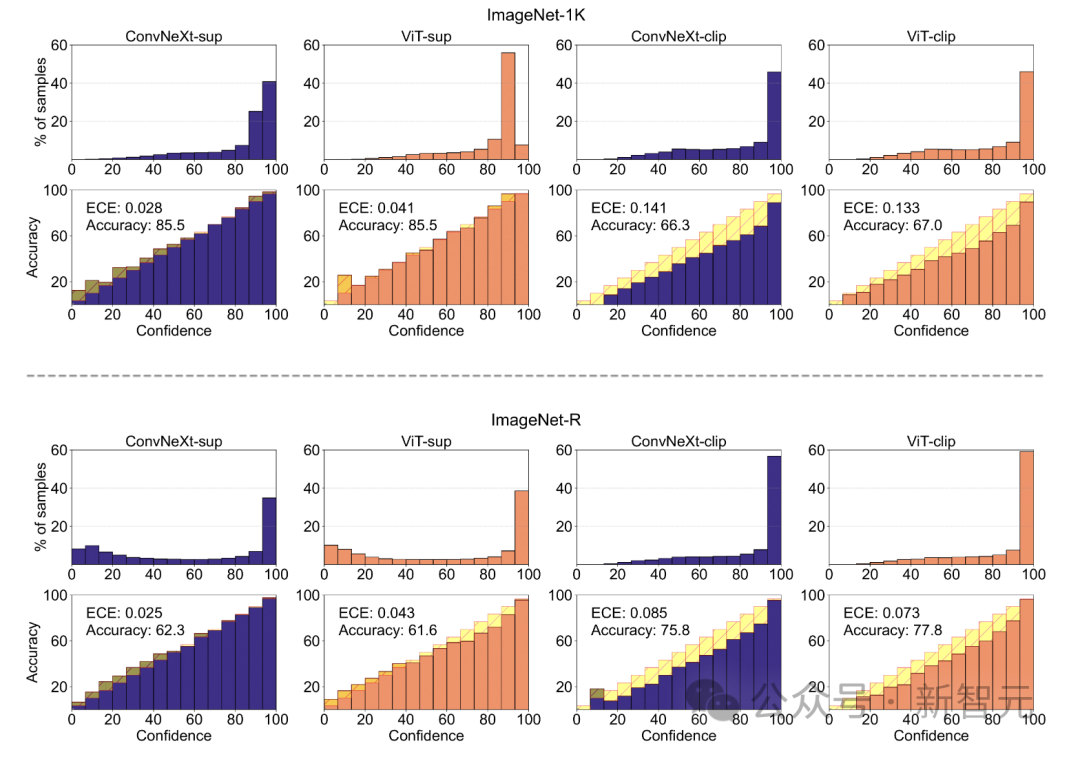
Calibrage du modèle
Le calibrage quantifie si la confiance de la prédiction d'un modèle est cohérente avec sa précision réelle.
Cela peut être évalué à l'aide de mesures telles que l'erreur d'étalonnage attendue (ECE), ainsi que d'outils de visualisation tels que des tracés de fiabilité et des histogrammes de confiance.
Les chercheurs ont évalué l'étalonnage sur ImageNet-1K et ImageNet-R, classant les prédictions en 15 niveaux. Dans l'expérience, les points suivants ont été observés :
- Le modèle CLIP a une confiance élevée, tandis que le modèle supervisé est légèrement insuffisant.
- ConvNeXt supervisé est mieux calibré que ViT supervisé.
Robustesse et portabilité
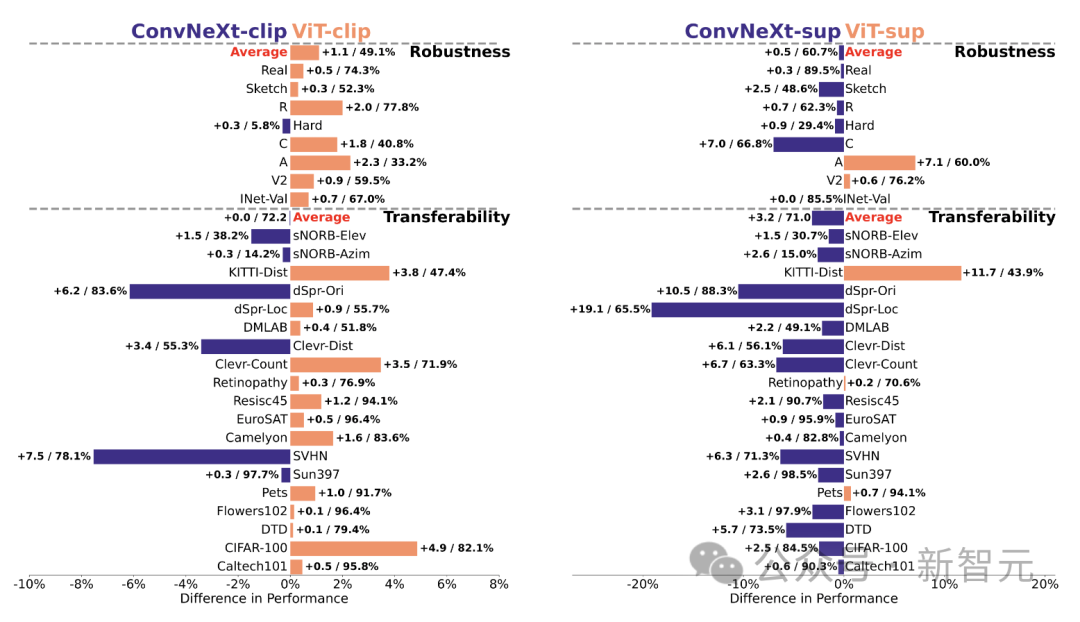
La robustesse et la portabilité du modèle sont la clé pour s'adapter aux changements de répartition des données et aux nouvelles tâches.
Les chercheurs ont évalué la robustesse en utilisant différentes variantes d'ImageNet et ont constaté que même si les modèles ViT et ConvNeXt avaient des performances moyennes similaires, à l'exception d'ImageNet-R et ImageNet-Sketch, les modèles supervisés surpassaient généralement en termes de robustesse.
En termes de portabilité, évalué sur 19 jeux de données à l'aide du benchmark VTAB, ConvNeXt supervisé surpasse ViT et est presque à égalité avec les performances du modèle CLIP.
Les données synthétiques
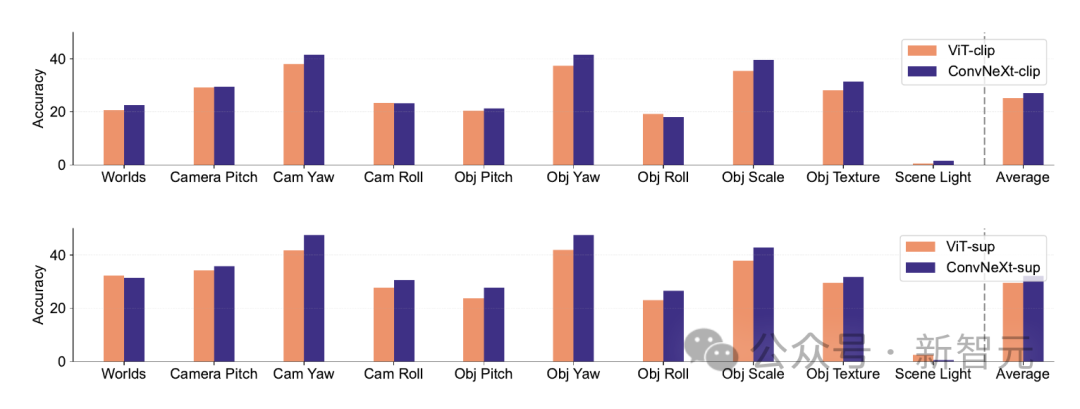
Les ensembles de données synthétiques comme PUG-ImageNet, qui peuvent contrôler avec précision des facteurs tels que l'angle et la texture de la caméra, sont devenus une voie de recherche prometteuse, c'est pourquoi les chercheurs se basent sur les performances synthétiques de l'analyse des données des modèles.
PUG-ImageNet contient des images ImageNet photoréalistes avec des variations systématiques d'éclairage et d'autres facteurs, avec des performances mesurées comme la plus haute précision absolue.
Les chercheurs fournissent des résultats pour différents facteurs dans PUG-ImageNet et constatent que ConvNeXt surpasse ViT dans presque tous les facteurs.
Cela montre que ConvNeXt surpasse ViT sur les données synthétiques, tandis que l'écart du modèle CLIP est plus petit, car la précision du modèle CLIP est inférieure à celle du modèle supervisé, ce qui peut être lié à la moindre précision de l'ImageNet d'origine. . L'invariance des caractéristiques fait référence à la capacité du modèle à produire des représentations cohérentes qui ne sont pas affectées par les transformations d'entrée, préservant ainsi la sémantique, telle que la mise à l'échelle ou le mouvement.
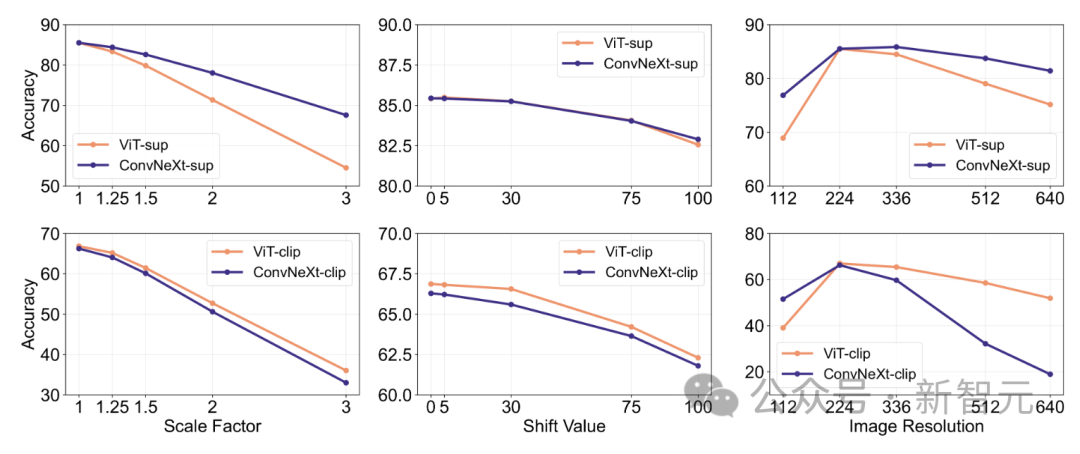
 Cette fonctionnalité permet au modèle de bien généraliser à travers des entrées différentes mais sémantiquement similaires.
Cette fonctionnalité permet au modèle de bien généraliser à travers des entrées différentes mais sémantiquement similaires.
L’approche des chercheurs comprend le redimensionnement des images pour l’invariance d’échelle, le déplacement des recadrages pour l’invariance de position et l’ajustement de la résolution du modèle ViT à l’aide d’intégrations positionnelles interpolées.
ConvNeXt surpasse ViT en entraînement supervisé.
Dans l'ensemble, le modèle est plus robuste aux transformations d'échelle/résolution qu'aux mouvements. Pour les applications qui nécessitent une grande robustesse en matière de mise à l’échelle, de déplacement et de résolution, les résultats suggèrent que ConvNeXt supervisé peut être le meilleur choix.
Les chercheurs ont découvert que chaque modèle possède ses propres avantages.
Cela suggère que la sélection du modèle devrait dépendre du cas d'utilisation cible, car les mesures de performances standard peuvent négliger les nuances critiques pour la mission.
De plus, de nombreux benchmarks existants sont dérivés d'ImageNet, ce qui biaise l'évaluation. Le développement de nouveaux benchmarks avec différentes distributions de données est crucial pour évaluer les modèles dans un contexte représentatif plus réaliste.
ConvNet vs Transformer
- Dans de nombreux benchmarks, ConvNeXt supervisé a de meilleures performances que VIT supervisé : il est mieux calibré, invariant aux transformations de données, montre de meilleures performances Bonne transférabilité et robustesse.
- ConvNeXt surpasse ViT sur les données synthétiques.
- ViT a un biais de forme plus élevé.
Supervisé vs CLIP
- Bien que le modèle CLIP soit meilleur en termes de transférabilité, ConvNeXt supervisé a montré des performances compétitives sur cette tâche. Cela démontre le potentiel des modèles supervisés.
- Les modèles supervisés sont meilleurs pour les tests de robustesse, probablement parce que ces modèles sont des variantes d'ImageNet.
- Le modèle CLIP a un biais de forme plus élevé et moins d'erreurs de classification par rapport à sa précision ImageNet.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
