
 Périphériques technologiques
IA
L'Université du Zhejiang propose la nouvelle technologie SOTA SIFU : une seule image peut être utilisée pour reconstruire des modèles 3D de corps humain de haute qualité
Périphériques technologiques
IA
L'Université du Zhejiang propose la nouvelle technologie SOTA SIFU : une seule image peut être utilisée pour reconstruire des modèles 3D de corps humain de haute qualité
L'Université du Zhejiang propose la nouvelle technologie SOTA SIFU : une seule image peut être utilisée pour reconstruire des modèles 3D de corps humain de haute qualité

Dans de nombreux domaines tels que l'AR, la VR, l'impression 3D, la construction de scènes et la production de films, des modèles 3D de haute qualité du corps humain portant des vêtements sont très importants.
Créer des modèles par des méthodes traditionnelles demande beaucoup de temps et ne peut être réalisé que par du matériel et des techniciens professionnels.

En revanche, dans la vie quotidienne, nous utilisons généralement les appareils photo des téléphones portables ou les portraits trouvés sur les pages Web.
Par conséquent, une méthode capable de reconstruire avec précision un modèle humain 3D à partir d'une seule image peut réduire considérablement les coûts et simplifier le processus de création indépendant.
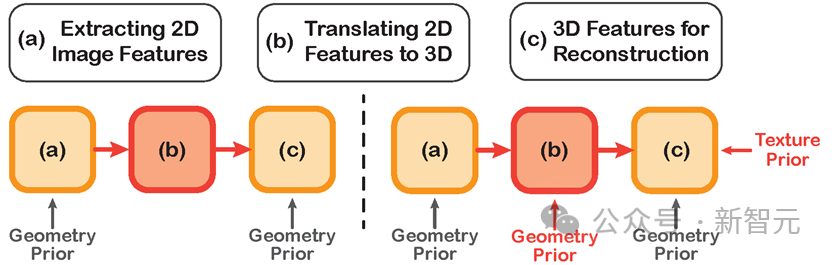 Comparaison du parcours technique des méthodes précédentes (à gauche) et de cette méthode (à droite)
Comparaison du parcours technique des méthodes précédentes (à gauche) et de cette méthode (à droite)
Les modèles de deep learning précédents utilisés pour la reconstruction 3D du corps humain nécessitent souvent trois étapes : extraire les caractéristiques 2D de l'image, Les caractéristiques 2D sont transférées dans l'espace 3D et les caractéristiques 3D sont utilisées pour la reconstruction du corps humain.
Cependant, ces méthodes ignorent souvent l'introduction des priorités du corps humain lors de l'étape de conversion des caractéristiques 2D en espace 3D, ce qui entraîne une extraction insuffisante des caractéristiques et divers défauts dans les résultats finaux de la reconstruction.
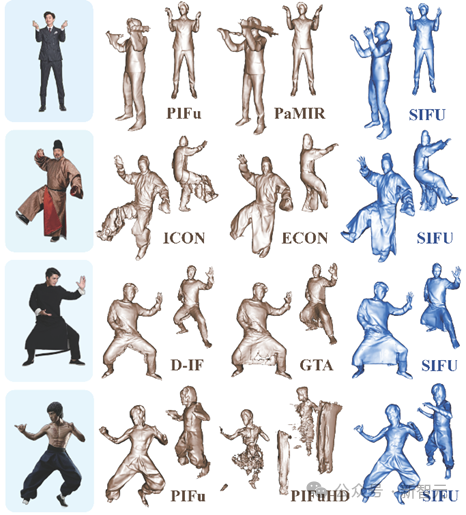 Comparaison de l'effet de reconstruction de SIFU et d'autres modèles SOTA
Comparaison de l'effet de reconstruction de SIFU et d'autres modèles SOTA
De plus, au stade de la prédiction de texture, les modèles précédents s'appuyaient uniquement sur les connaissances acquises dans l'ensemble d'entraînement et manquaient de connaissances préalables sur le le monde réel, ce qui aboutissait souvent à une prédiction de texture dans les zones invisibles, est médiocre.

SIFU introduit des connaissances préalables dans l'étape de prédiction de texture pour améliorer l'effet de texture des zones invisibles (dos, etc.).
À cet égard, des chercheurs du laboratoire ReLER de l'université du Zhejiang ont proposé le modèle SIFU, qui s'appuie sur la fonction implicite conditionnelle de la vue latérale pour reconstruire un modèle 3D du corps humain à partir d'une seule image.
 Photos
Photos
Adresse papier : https://arxiv.org/abs/2312.06704
Adresse du projet : https://github.com/River-Zhang/SIFU
Ce modèle est adopté dans Les caractéristiques 2D sont converties en espace 3D et la vue latérale du corps humain est introduite comme condition a priori pour améliorer l'effet de reconstruction géométrique. Et un modèle de diffusion pré-entraîné est introduit dans la phase d'optimisation de la texture pour résoudre le problème de la mauvaise texture dans les zones invisibles.
Structure du modèle
Le pipeline du modèle est le suivant :
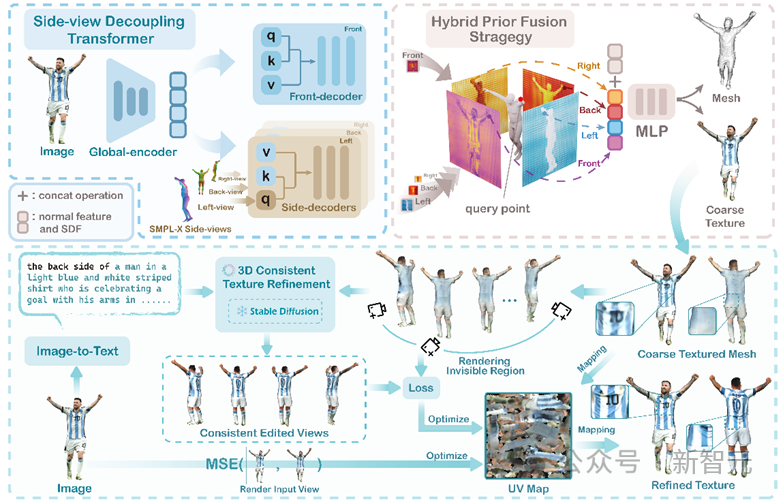 Images
Images
L'opération du modèle peut être divisée en deux étapes. La première étape utilise la fonction implicite latérale pour reconstruire la géométrie (. mesh) du corps humain et de la texture grossière, la deuxième étape utilise le modèle de diffusion pré-entraîné pour affiner la texture.
Dans la première étape, l'auteur a conçu un transformateur de découplage de vue latérale unique. Après avoir extrait les caractéristiques 2D via l'encodeur global, la vue latérale du modèle antérieur SMPL-X du corps humain a été introduite comme requête dans le décodeur, ainsi. Les caractéristiques 3D du corps humain dans différentes directions (avant, arrière, gauche et droite) sont découplées des caractéristiques 2D de l'image et finalement utilisées pour la reconstruction.
Cette méthode combine avec succès les connaissances préalables du corps humain lors de la conversion de caractéristiques 2D en espace 3D, ce qui entraîne un meilleur effet de reconstruction du modèle.
Dans la deuxième étape, l'auteur propose un processus de raffinement de texture cohérent en 3D. Tout d'abord, les zones invisibles du corps humain (côtés, dos) peuvent être différenciées en un ensemble d'images avec des angles de vision continus, puis avec les angles de vue continus. L'aide d'un modèle de diffusion qui apprend des connaissances préalables à partir de données massives permet une édition cohérente d'images de texture grossière pour obtenir des résultats plus raffinés. Enfin, la carte de texture du modèle 3D est optimisée en calculant la perte des images avant et après raffinement.
Partie expérimentale
Précision de reconstruction plus élevée
Dans la partie expérimentale, les auteurs testent leur modèle à l'aide d'un ensemble de tests très diversifié, notamment CAPE-NFP, CAPE-FP et THuman2.0, et le comparent à précédents modèles SOTA de reconstruction du corps humain à image unique publiés lors de grandes conférences. Après des tests quantitatifs, le modèle SIFU a montré les meilleurs résultats en matière de reconstruction géométrique et de reconstruction de texture.
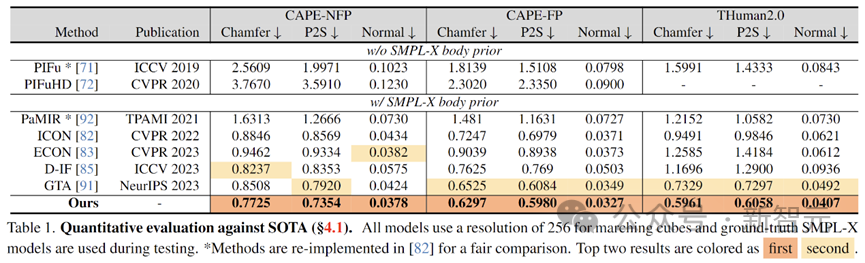 Évaluer quantitativement la précision de la reconstruction géométrique
Évaluer quantitativement la précision de la reconstruction géométrique
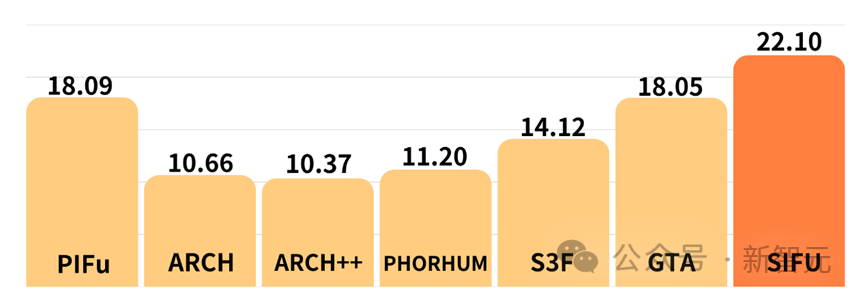 Évaluer quantitativement l'effet de reconstruction de texture
Évaluer quantitativement l'effet de reconstruction de texture
 Utiliser des images publiques sur Internet comme entrée pour la démonstration de l'effet qualitatif
Utiliser des images publiques sur Internet comme entrée pour la démonstration de l'effet qualitatif
Robuste plus forte
Lorsque les modèles précédents appliquent des données autres que l'ensemble d'apprentissage, parce que le modèle SMPL/SMPL-X antérieur estimé du corps humain n'est pas suffisamment précis, les résultats de la reconstruction sont souvent très différents des images d'entrée, ce qui rend difficile leur mise en application pratique.
À cet égard, l'auteur a spécifiquement testé la robustesse du modèle en ajoutant des perturbations aux paramètres du modèle antérieur de vérité terrain pour compenser la pose, l'auteur a simulé l'estimation SMPL-X inexacte dans des scènes réelles. précision de la reconstruction du modèle. Les résultats montrent que le modèle SIFU présente toujours la meilleure précision de reconstruction dans ce cas.
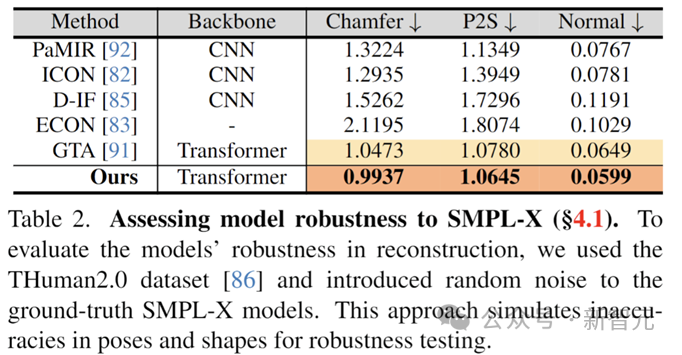 Évaluez la robustesse du modèle face à un modèle antérieur erroné du corps humain
Évaluez la robustesse du modèle face à un modèle antérieur erroné du corps humain
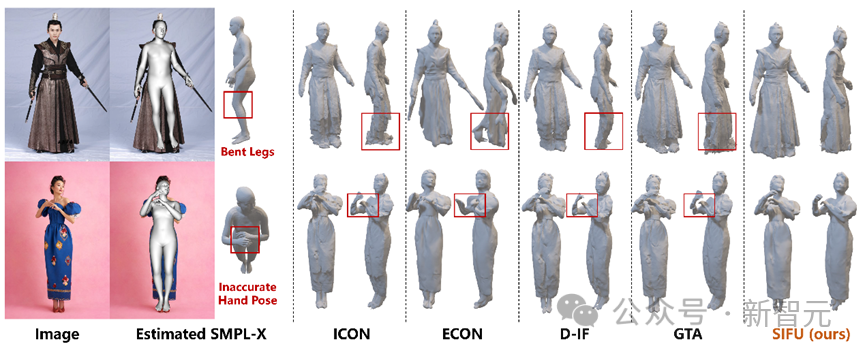 En utilisant des images du monde réel, SIFU fonctionne toujours lorsque l'estimation du modèle antérieur du corps humain est inexacte Meilleur effet de reconstruction
En utilisant des images du monde réel, SIFU fonctionne toujours lorsque l'estimation du modèle antérieur du corps humain est inexacte Meilleur effet de reconstruction
Scénarios d'application plus larges
L'effet de reconstruction de haute précision et de haute qualité du modèle SIFU le rend adapté à une variété de scénarios d'application, notamment l'impression 3D, la création de scènes, l'édition de textures, etc. Modèle de corps humain reconstruit SIFU imprimé en 3D
 Avec l'aide des données de séquence d'action publique , vous pouvez Piloter le modèle reconstruit SIFU
Avec l'aide des données de séquence d'action publique , vous pouvez Piloter le modèle reconstruit SIFU

Référence :
https://arxiv.org/abs/2312.06704
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment écrire un roman dans l'application Tomato Free Novel Partagez le tutoriel sur la façon d'écrire un roman dans l'application Tomato Novel
Mar 28, 2024 pm 12:50 PM
Comment écrire un roman dans l'application Tomato Free Novel Partagez le tutoriel sur la façon d'écrire un roman dans l'application Tomato Novel
Mar 28, 2024 pm 12:50 PM
Tomato Novel est un logiciel de lecture de romans très populaire. Nous avons souvent de nouveaux romans et bandes dessinées à lire dans Tomato Novel. De nombreux amis souhaitent également gagner de l'argent de poche et éditer le contenu de leur roman. Je veux écrire dans du texte. Alors, comment pouvons-nous y écrire le roman ? Mes amis ne le savent pas, alors allons ensemble sur ce site. Prenons le temps de regarder une introduction à la façon d'écrire un roman. Partagez le didacticiel du roman Tomato sur la façon d'écrire un roman. 1. Ouvrez d'abord l'application de roman gratuite Tomato sur votre téléphone mobile et cliquez sur Personal Center - Writer Center 2. Accédez à la page Tomato Writer Assistant - cliquez sur Créer un nouveau livre. à la fin du roman.
 Comment entrer dans le bios sur la carte mère Colorful ? Apprenez-vous deux méthodes
Mar 13, 2024 pm 06:01 PM
Comment entrer dans le bios sur la carte mère Colorful ? Apprenez-vous deux méthodes
Mar 13, 2024 pm 06:01 PM
Les cartes mères colorées jouissent d'une grande popularité et d'une part de marché élevée sur le marché intérieur chinois, mais certains utilisateurs de cartes mères colorées ne savent toujours pas comment accéder au BIOS pour les paramètres ? En réponse à cette situation, l'éditeur vous a spécialement proposé deux méthodes pour accéder au bios coloré de la carte mère. Venez l'essayer ! Méthode 1 : utilisez la touche de raccourci de démarrage du disque U pour accéder directement au système d'installation du disque U. La touche de raccourci de la carte mère Colorful pour démarrer le disque U en un seul clic est ESC ou F11. Tout d'abord, utilisez Black Shark Installation Master pour créer un Black. Disque de démarrage Shark U, puis allumez l'ordinateur lorsque vous voyez l'écran de démarrage, appuyez continuellement sur la touche ESC ou F11 du clavier pour accéder à une fenêtre de sélection de la séquence d'éléments de démarrage. Déplacez le curseur à l'endroit où "USB. " s'affiche, puis
 Comment récupérer des contacts supprimés sur WeChat (un tutoriel simple vous explique comment récupérer des contacts supprimés)
May 01, 2024 pm 12:01 PM
Comment récupérer des contacts supprimés sur WeChat (un tutoriel simple vous explique comment récupérer des contacts supprimés)
May 01, 2024 pm 12:01 PM
Malheureusement, les gens suppriment souvent certains contacts accidentellement pour certaines raisons. WeChat est un logiciel social largement utilisé. Pour aider les utilisateurs à résoudre ce problème, cet article explique comment récupérer les contacts supprimés de manière simple. 1. Comprendre le mécanisme de suppression des contacts WeChat. Cela nous offre la possibilité de récupérer les contacts supprimés. Le mécanisme de suppression des contacts dans WeChat les supprime du carnet d'adresses, mais ne les supprime pas complètement. 2. Utilisez la fonction intégrée « Récupération du carnet de contacts » de WeChat. WeChat fournit une « Récupération du carnet de contacts » pour économiser du temps et de l'énergie. Les utilisateurs peuvent récupérer rapidement les contacts précédemment supprimés grâce à cette fonction. 3. Accédez à la page des paramètres WeChat et cliquez sur le coin inférieur droit, ouvrez l'application WeChat « Moi » et cliquez sur l'icône des paramètres dans le coin supérieur droit pour accéder à la page des paramètres.
 Résumé des méthodes pour obtenir les droits d'administrateur dans Win11
Mar 09, 2024 am 08:45 AM
Résumé des méthodes pour obtenir les droits d'administrateur dans Win11
Mar 09, 2024 am 08:45 AM
Un résumé de la façon d'obtenir les droits d'administrateur Win11 Dans le système d'exploitation Windows 11, les droits d'administrateur sont l'une des autorisations très importantes qui permettent aux utilisateurs d'effectuer diverses opérations sur le système. Parfois, nous pouvons avoir besoin d'obtenir des droits d'administrateur pour effectuer certaines opérations, telles que l'installation de logiciels, la modification des paramètres du système, etc. Ce qui suit résume quelques méthodes pour obtenir les droits d'administrateur Win11, j'espère que cela pourra vous aider. 1. Utilisez les touches de raccourci. Dans le système Windows 11, vous pouvez ouvrir rapidement l'invite de commande via les touches de raccourci.
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Le secret de l'éclosion des œufs de dragon mobiles est révélé (étape par étape pour vous apprendre à réussir l'éclosion des œufs de dragon mobiles)
May 04, 2024 pm 06:01 PM
Le secret de l'éclosion des œufs de dragon mobiles est révélé (étape par étape pour vous apprendre à réussir l'éclosion des œufs de dragon mobiles)
May 04, 2024 pm 06:01 PM
Les jeux mobiles font désormais partie intégrante de la vie des gens avec le développement de la technologie. Il a attiré l'attention de nombreux joueurs avec sa jolie image d'œuf de dragon et son processus d'éclosion intéressant, et l'un des jeux qui a beaucoup attiré l'attention est la version mobile de Dragon Egg. Pour aider les joueurs à mieux cultiver et faire grandir leurs propres dragons dans le jeu, cet article vous présentera comment faire éclore des œufs de dragon dans la version mobile. 1. Choisissez le type d'œuf de dragon approprié. Les joueurs doivent choisir soigneusement le type d'œuf de dragon qu'ils aiment et qui leur conviennent, en fonction des différents types d'attributs et de capacités d'œuf de dragon fournis dans le jeu. 2. Améliorez le niveau de la machine d'incubation. Les joueurs doivent améliorer le niveau de la machine d'incubation en accomplissant des tâches et en collectant des accessoires. Le niveau de la machine d'incubation détermine la vitesse d'éclosion et le taux de réussite de l'éclosion. 3. Collectez les ressources nécessaires à l'éclosion. Les joueurs doivent être dans le jeu.
 Comment définir la taille de la police sur le téléphone mobile (ajustez facilement la taille de la police sur le téléphone mobile)
May 07, 2024 pm 03:34 PM
Comment définir la taille de la police sur le téléphone mobile (ajustez facilement la taille de la police sur le téléphone mobile)
May 07, 2024 pm 03:34 PM
La définition de la taille de la police est devenue une exigence de personnalisation importante à mesure que les téléphones mobiles deviennent un outil important dans la vie quotidienne des gens. Afin de répondre aux besoins des différents utilisateurs, cet article présentera comment améliorer l'expérience d'utilisation du téléphone mobile et ajuster la taille de la police du téléphone mobile grâce à des opérations simples. Pourquoi avez-vous besoin d'ajuster la taille de la police de votre téléphone mobile - L'ajustement de la taille de la police peut rendre le texte plus clair et plus facile à lire - Adapté aux besoins de lecture des utilisateurs d'âges différents - Pratique pour les utilisateurs malvoyants qui souhaitent utiliser la taille de la police fonction de configuration du système de téléphonie mobile - Comment accéder à l'interface des paramètres du système - Dans Rechercher et entrez l'option "Affichage" dans l'interface des paramètres - recherchez l'option "Taille de la police" et ajustez-la. application - téléchargez et installez une application prenant en charge l'ajustement de la taille de la police - ouvrez l'application et entrez dans l'interface des paramètres appropriée - en fonction de l'individu
 Maîtrisez rapidement : comment ouvrir deux comptes WeChat sur les téléphones mobiles Huawei révélé !
Mar 23, 2024 am 10:42 AM
Maîtrisez rapidement : comment ouvrir deux comptes WeChat sur les téléphones mobiles Huawei révélé !
Mar 23, 2024 am 10:42 AM
Dans la société actuelle, les téléphones portables sont devenus un élément indispensable de nos vies. En tant qu'outil important pour notre communication, notre travail et notre vie quotidienne, WeChat est souvent utilisé. Cependant, il peut être nécessaire de séparer deux comptes WeChat lors du traitement de différentes transactions, ce qui nécessite que le téléphone mobile prenne en charge la connexion à deux comptes WeChat en même temps. En tant que marque nationale bien connue, les téléphones mobiles Huawei sont utilisés par de nombreuses personnes. Alors, quelle est la méthode pour ouvrir deux comptes WeChat sur les téléphones mobiles Huawei ? Dévoilons le secret de cette méthode. Tout d'abord, vous devez utiliser deux comptes WeChat en même temps sur votre téléphone mobile Huawei. Le moyen le plus simple est de le faire.
