
 Périphériques technologiques
IA
Deux bons conseils pour améliorer l'efficacité de votre code Pandas
Périphériques technologiques
IA
Deux bons conseils pour améliorer l'efficacité de votre code Pandas
Deux bons conseils pour améliorer l'efficacité de votre code Pandas

Si vous avez déjà utilisé Pandas avec des données tabulaires, vous connaissez peut-être le processus d'importation des données, de nettoyage et de transformation, puis de leur utilisation comme entrée dans le modèle. Cependant, lorsque vous devez faire évoluer et mettre votre code en production, votre pipeline Pandas commencera très probablement à planter et à fonctionner lentement. Dans cet article, je partagerai 2 conseils pour vous aider à accélérer l'exécution du code Pandas, à améliorer l'efficacité du traitement des données et à éviter les pièges courants.

Astuce 1 : Opérations de vectorisation
Dans Pandas, les opérations de vectorisation sont un outil efficace qui peut traiter les colonnes de l'ensemble du bloc de données de manière plus concise sans boucler ligne par ligne.
Comment ça marche ?
La diffusion est un élément clé de la manipulation vectorisée, permettant de manipuler intuitivement des objets de formes différentes.
eg1 : Un tableau a avec 3 éléments est multiplié par un scalaire b, ce qui donne un tableau de même forme que Source.
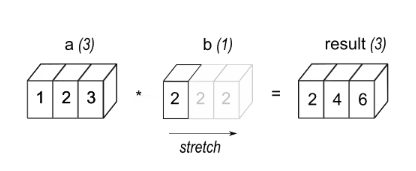
eg2 : Lors de l'opération d'addition, ajoutez le tableau a avec la forme (4,1) et le tableau b avec la forme (3,). Le résultat sera un tableau avec la forme (4,3).
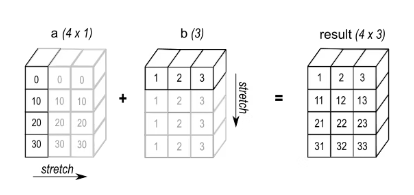
De nombreux articles ont abordé ce sujet, notamment dans le domaine de l'apprentissage profond où les multiplications matricielles à grande échelle sont courantes. Cet article présentera deux brefs exemples.
Tout d’abord, disons que vous souhaitez compter le nombre de fois qu’un entier donné apparaît dans une colonne. Voici 2 méthodes possibles.
"""计算DataFrame X 中 "column_1" 列中等于目标值 target 的元素个数。参数:X: DataFrame,包含要计算的列 "column_1"。target: int,目标值。返回值:int,等于目标值 target 的元素个数。"""# 使用循环计数def count_loop(X, target: int) -> int:return sum(x == target for x in X["column_1"])# 使用矢量化操作计数def count_vectorized(X, target: int) -> int:return (X["column_1"] == target).sum()
Supposons maintenant que vous ayez un DataFrame avec une colonne de date et que vous souhaitiez le décaler d'un nombre de jours donné. Le calcul utilisant des opérations vectorisées est le suivant :
def offset_loop(X, days: int) -> pd.DataFrame:d = pd.Timedelta(days=days)X["column_const"] = [x + d for x in X["column_10"]]return Xdef offset_vectorized(X, days: int) -> pd.DataFrame:X["column_const"] = X["column_10"] + pd.Timedelta(days=days)return X
Astuce 2 : Itérer
"boucle for"
La première et la plus intuitive façon d'itérer est d'utiliser une boucle for Python.
def loop(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:res = []i_remove_col = df.columns.get_loc(remove_col)i_words_to_remove_col = df.columns.get_loc(words_to_remove_col)for i_row in range(df.shape[0]):res.append(remove_words(df.iat[i_row, i_remove_col], df.iat[i_row, i_words_to_remove_col]))return result
「apply」
def apply(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df.apply(func=lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1).tolist()
À chaque itération de df.apply, la fonction appelable fournie obtient une série dont l'index est df.columns et dont les valeurs sont des lignes. Cela signifie que les pandas doivent générer la séquence dans chaque boucle, ce qui coûte cher. Pour réduire les coûts, il est préférable d'appeler apply sur un sous-ensemble de df que vous savez que vous utiliserez, comme ceci :
def apply_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df[[remove_col, words_to_remove_col]].apply(func=lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1)
「Combinaison de listes + itertuples」
Il est définitivement préférable d'itérer en utilisant des itertuples combinés avec des listes. itertuples génère des tuples (nommés) avec des données de ligne.
def itertuples_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x[0], x[1])for x in df[[remove_col, words_to_remove_col]].itertuples(index=False, name=None)]
「Combinaison liste + zip」
zip accepte un objet itérable et génère un tuple, où le i-ième tuple contient tous les i-ième éléments de l'objet itérable donné dans l'ordre.
def zip_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x, y) for x, y in zip(df[remove_col], df[words_to_remove_col])]
「Combinaison liste + to_dict」
def to_dict_only_used_columns(df: pd.DataFrame) -> list[str]:return [remove_words(row[remove_col], row[words_to_remove_col])for row in df[[remove_col, words_to_remove_col]].to_dict(orient="records")]
「Caching」
En plus des techniques itératives dont nous avons parlé, deux autres méthodes peuvent aider à améliorer les performances du code : la mise en cache et la parallélisation. La mise en cache est particulièrement utile si vous appelez plusieurs fois une fonction pandas avec les mêmes paramètres. Par exemple, si remove_words est appliqué à un ensemble de données comportant de nombreuses valeurs en double, vous pouvez utiliser functools.lru_cache pour stocker les résultats de la fonction et éviter de les recalculer à chaque fois. Pour utiliser lru_cache, ajoutez simplement le décorateur @lru_cache à la déclaration de remove_words, puis appliquez la fonction à votre ensemble de données en utilisant votre méthode d'itération préférée. Cela peut améliorer considérablement la vitesse et l’efficacité de votre code. Prenons le code suivant comme exemple :
@lru_cachedef remove_words(...):... # Same implementation as beforedef zip_only_used_cols_cached(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x, y) for x, y in zip(df[remove_col], df[words_to_remove_col])]
L'ajout de ce décorateur génère une fonction qui "se souvient" de la sortie de l'entrée précédemment rencontrée, éliminant ainsi le besoin de réexécuter tout le code.
"Parallélisation"
Le dernier atout est d'utiliser pandarallel pour paralléliser nos appels de fonction sur plusieurs blocs df indépendants. L'outil est facile à utiliser : il vous suffit de l'importer et de l'initialiser, puis de remplacer tous les .applys par .parallel_applys.
from pandarallel import pandarallelpandarallel.initialize(nb_workers=min(os.cpu_count(), 12))def parapply_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df[[remove_col, words_to_remove_col]].parallel_apply(lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Que faire si le code d'écran bleu 0x0000001 apparaît
Feb 23, 2024 am 08:09 AM
Que faire si le code d'écran bleu 0x0000001 apparaît
Feb 23, 2024 am 08:09 AM
Que faire avec le code d'écran bleu 0x0000001. L'erreur d'écran bleu est un mécanisme d'avertissement en cas de problème avec le système informatique ou le matériel. Le code 0x0000001 indique généralement une panne de matériel ou de pilote. Lorsque les utilisateurs rencontrent soudainement une erreur d’écran bleu lors de l’utilisation de leur ordinateur, ils peuvent se sentir paniqués et perdus. Heureusement, la plupart des erreurs d’écran bleu peuvent être dépannées et traitées en quelques étapes simples. Cet article présentera aux lecteurs certaines méthodes pour résoudre le code d'erreur d'écran bleu 0x0000001. Tout d'abord, lorsque nous rencontrons une erreur d'écran bleu, nous pouvons essayer de redémarrer
 Résoudre les problèmes courants d'installation de pandas : interprétation et solutions aux erreurs d'installation
Feb 19, 2024 am 09:19 AM
Résoudre les problèmes courants d'installation de pandas : interprétation et solutions aux erreurs d'installation
Feb 19, 2024 am 09:19 AM
Tutoriel d'installation de Pandas : analyse des erreurs d'installation courantes et de leurs solutions, des exemples de code spécifiques sont requis Introduction : Pandas est un puissant outil d'analyse de données largement utilisé dans le nettoyage des données, le traitement des données et la visualisation des données, il est donc très respecté dans le domaine de la science des données. Cependant, en raison de problèmes de configuration de l'environnement et de dépendances, vous pouvez rencontrer des difficultés et des erreurs lors de l'installation de pandas. Cet article vous fournira un didacticiel d'installation de pandas et analysera certaines erreurs d'installation courantes et leurs solutions. 1. Installez les pandas
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Résoudre l'erreur du code 0xc000007b
Feb 18, 2024 pm 07:34 PM
Résoudre l'erreur du code 0xc000007b
Feb 18, 2024 pm 07:34 PM
Code de terminaison 0xc000007b Lors de l'utilisation de votre ordinateur, vous rencontrez parfois divers problèmes et codes d'erreur. Parmi eux, le code de terminaison est le plus inquiétant, notamment le code de terminaison 0xc000007b. Ce code indique qu'une application ne peut pas démarrer correctement, provoquant des désagréments pour l'utilisateur. Tout d’abord, comprenons la signification du code de terminaison 0xc000007b. Ce code est un code d'erreur du système d'exploitation Windows qui se produit généralement lorsqu'une application 32 bits tente de s'exécuter sur un système d'exploitation 64 bits. Cela signifie que ça devrait
 Programme de codes à distance universels GE sur n'importe quel appareil
Mar 02, 2024 pm 01:58 PM
Programme de codes à distance universels GE sur n'importe quel appareil
Mar 02, 2024 pm 01:58 PM
Si vous devez programmer un appareil à distance, cet article vous aidera. Nous partagerons les meilleurs codes de télécommande universelle GE pour programmer n’importe quel appareil. Qu'est-ce qu'une télécommande GE ? GEUniversalRemote est une télécommande qui peut être utilisée pour contrôler plusieurs appareils tels que les téléviseurs intelligents, LG, Vizio, Sony, Blu-ray, DVD, DVR, Roku, AppleTV, lecteurs multimédias en streaming et plus encore. Les télécommandes GEUniversal sont disponibles en différents modèles avec différentes caractéristiques et fonctions. GEUniversalRemote peut contrôler jusqu'à quatre appareils. Les meilleurs codes de télécommande universels à programmer sur n'importe quel appareil. Les télécommandes GE sont livrées avec un ensemble de codes qui leur permettent de fonctionner avec différents appareils. vous pouvez
 Que représente le code écran bleu 0x000000d1 ?
Feb 18, 2024 pm 01:35 PM
Que représente le code écran bleu 0x000000d1 ?
Feb 18, 2024 pm 01:35 PM
Que signifie le code d'écran bleu 0x000000d1 ? Ces dernières années, avec la popularisation des ordinateurs et le développement rapide d'Internet, les problèmes de stabilité et de sécurité du système d'exploitation sont devenus de plus en plus importants. Les erreurs d’écran bleu sont un problème courant, le code 0x000000d1 en fait partie. Une erreur d'écran bleu, ou « Écran bleu de la mort », est une condition qui se produit lorsqu'un ordinateur subit une panne système grave. Lorsque le système ne parvient pas à récupérer de l'erreur, le système d'exploitation Windows affiche un écran bleu avec le code d'erreur à l'écran. Ces codes d'erreur
 Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Dans la vague actuelle de changements technologiques rapides, l'intelligence artificielle (IA), l'apprentissage automatique (ML) et l'apprentissage profond (DL) sont comme des étoiles brillantes, à la tête de la nouvelle vague des technologies de l'information. Ces trois mots apparaissent fréquemment dans diverses discussions de pointe et applications pratiques, mais pour de nombreux explorateurs novices dans ce domaine, leurs significations spécifiques et leurs connexions internes peuvent encore être entourées de mystère. Alors regardons d'abord cette photo. On constate qu’il existe une corrélation étroite et une relation progressive entre l’apprentissage profond, l’apprentissage automatique et l’intelligence artificielle. Le deep learning est un domaine spécifique du machine learning, et le machine learning
 Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Près de 20 ans se sont écoulés depuis que le concept d'apprentissage profond a été proposé en 2006. L'apprentissage profond, en tant que révolution dans le domaine de l'intelligence artificielle, a donné naissance à de nombreux algorithmes influents. Alors, selon vous, quels sont les 10 meilleurs algorithmes pour l’apprentissage profond ? Voici les meilleurs algorithmes d’apprentissage profond, à mon avis. Ils occupent tous une position importante en termes d’innovation, de valeur d’application et d’influence. 1. Contexte du réseau neuronal profond (DNN) : Le réseau neuronal profond (DNN), également appelé perceptron multicouche, est l'algorithme d'apprentissage profond le plus courant lorsqu'il a été inventé pour la première fois, jusqu'à récemment en raison du goulot d'étranglement de la puissance de calcul. années, puissance de calcul, La percée est venue avec l'explosion des données. DNN est un modèle de réseau neuronal qui contient plusieurs couches cachées. Dans ce modèle, chaque couche transmet l'entrée à la couche suivante et
