
 Périphériques technologiques
IA
ICLR'24 nouvelles idées sans images ! LaneSegNet : apprentissage cartographique basé sur la connaissance de la segmentation des voies
Périphériques technologiques
IA
ICLR'24 nouvelles idées sans images ! LaneSegNet : apprentissage cartographique basé sur la connaissance de la segmentation des voies
ICLR'24 nouvelles idées sans images ! LaneSegNet : apprentissage cartographique basé sur la connaissance de la segmentation des voies

Écrite devant et compréhension personnelle de l'auteur
En tant qu'information clé pour les applications en aval des systèmes de conduite autonome, les cartes sont généralement représentées par des voies ou des lignes centrales. Cependant, la littérature existante sur l’apprentissage cartographique se concentre principalement sur la détection des relations topologiques des voies basées sur la géométrie ou sur la détection des lignes médianes. Les deux méthodes ignorent la relation inhérente entre les lignes de voie et les lignes centrales, c'est-à-dire que les lignes de voie lient les lignes centrales. Bien que la simple prédiction de deux types de voies dans un modèle s'excluent mutuellement dans l'objectif d'apprentissage, cet article propose la segmentation des voies comme une nouvelle représentation qui combine de manière transparente les informations géométriques et topologiques, proposant ainsi LaneSegNet. Il s'agit du premier réseau cartographique de bout en bout qui génère des segments de voie pour obtenir une représentation complète de la structure routière. LaneSegNet comporte deux modifications clés. L'une est le module d'attention aux voies, qui est utilisé pour capturer les détails des zones clés dans l'espace des fonctionnalités longue distance. L'autre est la même stratégie d'initialisation du point de référence, qui améliore l'apprentissage des positions a priori pour l'attention sur la voie. Sur l'ensemble de données OpenLane-V2, LaneSegNet présente des avantages significatifs par rapport aux produits similaires précédents dans trois tâches, à savoir la détection des éléments cartographiques (+4,8 mAP), la perception de l'axe de la voie (+6,9 DETl) et la connaissance des segments de voie nouvellement définis (+5,6 mAP). De plus, il a atteint une vitesse d'inférence en temps réel de 14,7 FPS.
Lien Open source : https://github.com/OpenDriveLab/LaneSegNet
En résumé, les principales contributions de cet article sont les suivantes :
- Cet article introduit une nouvelle perception des segments de voie comme une nouvelle carte formule d'apprentissage. Il contient des éléments géométriques et topologiques. Nous espérons que cela apportera de nouvelles perspectives dans le domaine.
- Cet article propose LaneSegNet, un réseau de bout en bout proposé pour la connaissance des segments de voie. Deux nouvelles modifications ont été proposées, notamment un module d'attention aux voies avec un mécanisme tête-à-région pour capter l'attention à longue portée, et la même stratégie d'initialisation pour les points de référence afin d'améliorer l'emplacement avant l'étude des voies.
Examen des travaux connexes
Conscience de la ligne centrale : La conscience de la ligne centrale à partir des données des capteurs montés sur le véhicule (identique à l'apprentissage de la carte des voies dans cet article) a récemment attiré une attention particulière. STSU a proposé un réseau de type DETR pour détecter les lignes médianes, suivi d'un module de perceptron multicouche (MLP) pour déterminer leur connectivité. Sur la base du STSU, Can et al. ont introduit une requête de boucle minimale supplémentaire pour garantir le bon ordre des lignes qui se chevauchent. CenterLineDet traite les lignes centrales comme des sommets et conçoit un modèle de mise à jour de graphique entraîné par apprentissage par imitation. Il convient de noter que Tesla a proposé le concept de « langage des voies » pour exprimer la carte des voies sous forme de phrase. Leur modèle basé sur l’attention prédit de manière récursive le marquage des voies et leur connectivité. En plus de ces méthodes de segmentation, LaneGAP introduit également une méthode de chemin qui utilise un algorithme de transformation supplémentaire pour récupérer la carte des voies. TopoNet cible des graphiques de scènes de conduite complets et diversifiés, modélise explicitement la connectivité des lignes centrales au sein du réseau et intègre des éléments de trafic dans la tâche. Dans ce travail, nous adoptons la méthode des segments pour construire des graphiques de voies. Cependant, nous différons des méthodes précédentes dans la modélisation des segments de voie au lieu de prendre la ligne centrale comme sommet du graphique de voie, ce qui permet une intégration pratique des informations géométriques et sémantiques au niveau du segment.
Détection d'éléments cartographiques : Dans des travaux antérieurs, une attention particulière a été portée à l'élévation de la détection des éléments cartographiques du plan de la caméra vers l'espace 3D pour surmonter les erreurs de projection. Avec la tendance populaire de la détection BEV, des travaux récents se concentrent sur l'apprentissage de cartes HD à l'aide de méthodes de segmentation et de vectorisation. La segmentation de la carte prédit la sémantique de chaque grille BEV pure, telle que les voies, les passages pour piétons et les zones carrossables. Ces travaux diffèrent principalement par les modules de conversion de la vue perspective (PV) vers BEV. Cependant, les cartes segmentées ne fournissent pas d'informations directes utilisées par les modules en aval. HDMapNet résout ce problème en regroupant et en vectorisant des cartes de segmentation avec un post-traitement complexe.
Bien que la segmentation dense fournisse des informations au niveau des pixels, elle ne peut toujours pas toucher aux relations complexes des éléments qui se chevauchent. VectorMapNet propose de représenter chaque élément de la carte directement sous la forme d'une séquence de points, en utilisant des points clés grossiers pour décoder séquentiellement les emplacements des voies. MapTR explore une approche unifiée de modélisation de séquences de points basée sur la permutation pour éliminer l'ambiguïté de la modélisation et améliorer les performances et l'efficacité. PivotNet modélise en outre les éléments cartographiques à l'aide d'une représentation basée sur pivot dans un cadre de prédiction d'ensemble pour réduire la redondance et améliorer la précision. StreamMapNet utilise une attention multipoint et des informations temporelles pour améliorer la stabilité de la détection des éléments cartographiques à distance. En fait, puisque la vectorisation enrichit également les informations de direction des voies, les méthodes basées sur la vectorisation peuvent être facilement adaptées à la conscience de la ligne centrale grâce à une supervision alternée. Dans ce travail, nous proposons une représentation unifiée et facile à apprendre – la segmentation des voies – pour tous les éléments de carte HD sur une route.
Explication détaillée de LaneSegNet
Description de la tâche de sensibilisation à la segmentation des voies
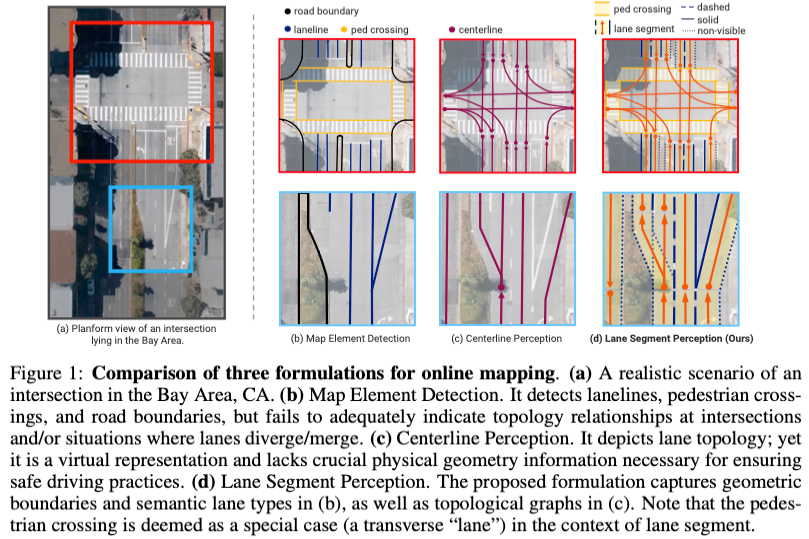
Les instances de segment de voie contiennent les aspects géométriques et sémantiques de la route. Quant à la géométrie, elle peut être représentée comme un segment de ligne constitué d'une ligne médiane vectorisée et de sa limite de voie correspondante : . Chaque ligne est définie comme une collection ordonnée de points dans l'espace 3D. Alternativement, la géométrie peut être décrite comme un polygone fermé qui définit la zone carrossable dans cette voie.
En termes de sémantique, il inclut la catégorie C de segment de voie (par exemple, segment de voie, passage pour piétons) et le style de ligne de la limite de voie gauche/droite (par exemple, ligne invisible, continue ou pointillée) : {}. Ces détails fournissent aux véhicules autonomes des informations importantes sur les exigences de décélération et la faisabilité des changements de voie.
De plus, les informations topologiques jouent un rôle crucial dans la planification des chemins. Pour représenter ces informations, un graphique de voie est construit pour le segment de voie, représenté par G = (V, E). Chaque segment de voie est un nœud dans le graphique, représenté par l'ensemble V, et les arêtes de l'ensemble E décrivent la connectivité entre les segments de voie. Nous utilisons une matrice de contiguïté pour stocker ce graphique de voie, où l'élément de matrice (i, j) est défini sur 1 uniquement lorsque le j-ème segment de voie suit le i-ème segment de voie, sinon il reste 0.
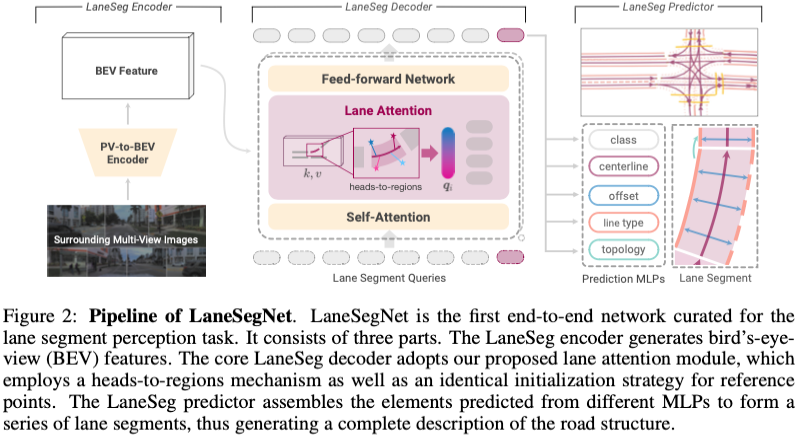
LaneSegNet Framework
Le cadre global de LaneSegNet est présenté dans la figure 2. LaneSegNet prend des images surround comme entrée pour percevoir les segments de voie dans une plage BEV spécifique. Dans cette section, nous présentons d'abord brièvement l'encodeur LaneSeg utilisé pour générer des fonctionnalités BEV. Ensuite, nous introduisons les décodeurs de segmentation de voie et l’attention aux voies. Enfin, nous proposons des prédicteurs de segmentation des voies ainsi que des pertes d'entraînement.
LaneSeg Encoder
L'encodeur convertit l'image surround en fonctionnalités BEV pour l'extraction de segments de voie. Nous utilisons le réseau fédérateur standard ResNet-50 pour dériver des cartes de caractéristiques à partir d'images brutes. Le module d'encodeur PV vers BEV utilisant BEVFormer est ensuite utilisé pour la conversion de vue.
LaneSeg Decoder
La méthode de détection basée sur le transformateur utilise le décodeur pour collecter les fonctionnalités des fonctionnalités BEV et met à jour la requête du décodeur à travers plusieurs couches. Chaque couche de décodeur utilise des mécanismes d'auto-attention, d'attention croisée et des réseaux de rétroaction pour mettre à jour la requête. De plus, des requêtes de localisation pouvant être apprises sont utilisées. La requête mise à jour est ensuite générée et transmise à l'étape suivante.
En raison des géométries cartographiques complexes et allongées, la collecte de caractéristiques BEV à longue portée est cruciale pour les tâches de cartographie en ligne. Les travaux antérieurs utilisent des requêtes de décodeur hiérarchique (point d'instance) et une attention déformable pour extraire les caractéristiques locales pour chaque requête de point. Bien que cette approche évite de capturer des informations à longue distance, elle entraîne un coût de calcul élevé en raison du nombre croissant de requêtes.
Le segment de voie, en tant que représentation d'instance de voie pour la création de graphiques de scène, présente des caractéristiques supérieures au niveau de l'instance. Notre objectif n'est pas d'utiliser des requêtes multipoints, mais d'utiliser des requêtes à instance unique pour représenter les segments de voie. Par conséquent, le principal défi consiste à savoir comment utiliser des requêtes à instance unique pour se concentrer sur les fonctionnalités globales de BEV.
Lane Attention : Dans la détection de cible, l'attention déformable utilise la position avant la cible et se concentre uniquement sur une petite partie des valeurs d'attention proches du point de référence cible comme pré-filtre, ce qui accélère considérablement la convergence. Lors des itérations de couche, un point de référence est placé au centre de la cible de prédiction pour affiner les emplacements d'échantillonnage des valeurs d'attention, qui sont dispersées autour du point de référence via des décalages d'échantillonnage apprenables. L'initialisation intentionnelle du décalage d'échantillonnage inclut la géométrie devant la cible 2D. Ce faisant, le mécanisme multibranche peut bien capturer les caractéristiques de chaque direction, comme le montre la figure 3a.
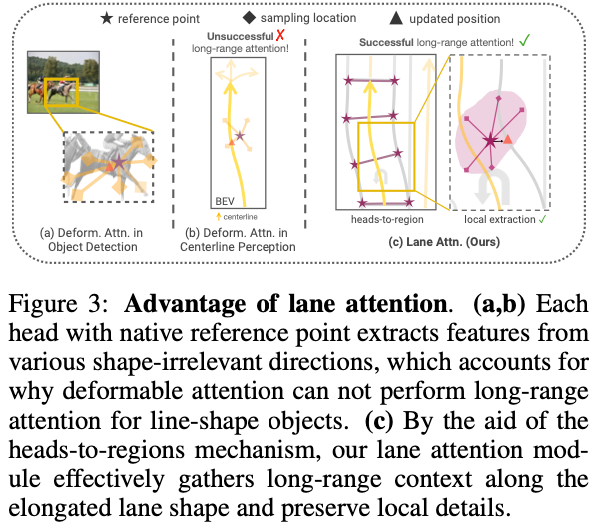
Dans le contexte de l'apprentissage des cartes, Li et al. ont utilisé une attention naïve et déformable pour prédire les lignes médianes. Cependant, comme le montre la figure 3b, en raison du placement naïf des points de référence, il se peut qu'il ne soit pas en mesure d'attirer l'attention sur une seule distance. De plus, en raison de la forme allongée de la cible et des repères visuels complexes (par exemple, prédire avec précision les points de rupture entre les lignes pleines et pointillées), ce processus nécessite une conception adaptative supplémentaire pour notre tâche. Compte tenu de toutes ces caractéristiques, il est nécessaire que le réseau ait la capacité non seulement de prêter attention aux informations contextuelles à longue portée, mais également d’extraire avec précision les détails locaux. Par conséquent, il est recommandé de répartir les emplacements d’échantillonnage sur une vaste zone pour percevoir efficacement les informations longue distance. D’un autre côté, les détails locaux doivent être facilement distinguables pour identifier les points clés. Il convient de noter que même s’il existe une relation de compétition entre les caractéristiques de valeur au sein d’une même tête d’attention, les caractéristiques de valeur entre différentes têtes peuvent être conservées au cours du processus d’attention. Il est donc prometteur d’exploiter explicitement cette propriété pour attirer l’attention sur les caractéristiques locales d’une région spécifique.
À cette fin, cet article propose d'établir un mécanisme tête-à-région. Nous répartissons d’abord plusieurs points de référence uniformément dans la zone du segment de voie. Les emplacements d'échantillonnage sont ensuite initialisés autour de chaque point de référence dans la zone locale. Pour préserver les détails locaux complexes, nous utilisons un mécanisme à plusieurs branches, dans lequel chaque tête se concentre sur un ensemble spécifique de sites d'échantillonnage dans une zone locale, comme le montre la figure 3c.
Une description mathématique du module d'attention aux voies est désormais fournie. Étant donné les caractéristiques BEV, la i-ème fonctionnalité de requête de segment de voie qi et un ensemble de points de référence pi en entrée, l'attention sur la voie est calculée comme suit :
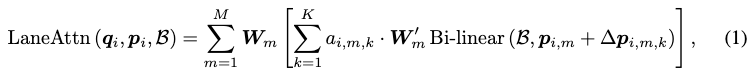
Même initialisation des points de référence : La position du point de référence est l'attention sur la voie facteurs déterminants de la fonction du module. Afin d'aligner la zone d'intérêt de chaque requête d'instance avec sa géométrie et son emplacement réels, le point de référence p dans chaque requête d'instance est distribué en fonction de la prédiction du segment de voie de la couche précédente, comme le montre la figure 3c. et affiner les prédictions de manière itérative.
Des travaux antérieurs soutenaient que les points de référence fournis à la première couche devaient être initialisés individuellement avec des a priori apprenables dérivés des intégrations de requêtes de position. Cependant, étant donné que la requête de localisation est indépendante de l'image d'entrée, cette méthode d'initialisation peut à son tour limiter la capacité du modèle à mémoriser les priorités géométriques et de localisation, et des emplacements d'initialisation incorrectement générés peuvent également constituer un obstacle à la formation.
Par conséquent, pour la première couche du décodeur Lane Segment, nous proposons la même stratégie d'initialisation. Dans la première couche, chaque tête prend le même point de référence généré par la requête de position. Par rapport à l'initialisation distribuée des points de référence dans les méthodes traditionnelles (c'est-à-dire l'initialisation de plusieurs points de référence pour chaque requête), la même initialisation rendra l'apprentissage des positions a priori plus stable en filtrant l'interférence des géométries complexes. Notez que la même initialisation peut sembler contre-intuitive, mais il a été observé qu'elle fonctionne.
LaneSeg Predictor
Nous utilisons MLP dans plusieurs branches de prédiction pour générer le segment de voie final prédit à partir de la requête Lane Segment, en tenant compte des aspects géométriques, sémantiques et topologiques.
Pour la géométrie, nous avons d'abord conçu une branche de régression de la ligne centrale pour régresser la position du point vectorisé de la ligne centrale en coordonnées tridimensionnelles. Le format de sortie est . En raison de la symétrie des limites des voies gauche et droite, nous introduisons une branche de décalage pour prédire le décalage, dont le format est . Par conséquent, les coordonnées des limites des voies gauche et droite peuvent être calculées à l'aide de
En supposant que les segments de voie peuvent être conceptualisés comme des zones carrossables, nous intégrons la branche de segmentation d'instance dans le prédicteur. En termes de sémantique, trois branches de classification prédisent le score de classification de C, et le score de C en parallèle. La branche topologique prend les fonctionnalités de requête mises à jour en entrée et génère une matrice de contiguïté pondérée du graphe de voies G à l'aide de MLP.
Training Loss
LaneSegNet adopte un paradigme de type DETR, en utilisant l'algorithme hongrois pour calculer efficacement une allocation optimale un à un entre les prédictions et la vérité terrain. La perte de formation est ensuite calculée sur la base des résultats de distribution. La fonction de perte se compose de quatre parties : perte géométrique, perte de classification, perte de classification de ligne de voie et perte topologique.
La perte géométrique supervise la géométrie de chaque segment de voie prévu. Selon le résultat de la correspondance binaire, un segment de voie GT est attribué à chaque segment de voie vectorisé prédit. La perte géométrique vectorisée est définie comme la distance de Manhattan calculée entre les paires de segments de voie assignées.
Résultats expérimentaux
Structure expérimentale principale
Perception du segment de voie : Dans le tableau 1, nous comparons LaneSegNet avec plusieurs méthodes de pointe, MapTR, MapTRv2 et TopoNet. Recycler leur modèle avec nos étiquettes Lane Segment. LaneSegNet surpasse les autres méthodes jusqu'à 9,6 % en mAP, et l'erreur de distance moyenne est relativement réduite de 12,5 %. LaneSegNet-mini surpasse également les méthodes précédentes avec un FPS plus élevé de 16,2.

Les résultats qualitatifs sont présentés dans la figure 4 :

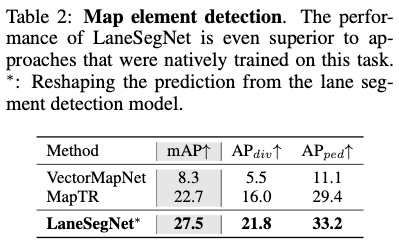
Détection d'éléments cartographiques : Pour une comparaison plus juste avec les méthodes de détection d'éléments cartographiques, nous décomposons le segment de voie prédit de LaneSegNet en paires de voies. par rapport aux méthodes de pointe utilisant des métriques de détection d’éléments cartographiques. Nous alimentons les lignes de voie démontées et les étiquettes de passage pour piétons dans plusieurs méthodes de recyclage de pointe. Les résultats expérimentaux sont présentés dans le tableau 2, montrant que LaneSegNet surpasse toujours les autres méthodes dans les tâches de détection d'éléments cartographiques. En comparaison équitable, LaneSegNet récupère mieux la géométrie de la route avec une supervision supplémentaire. Cela montre que la représentation d'apprentissage des segments de voie est efficace pour capturer les informations géométriques de la route.
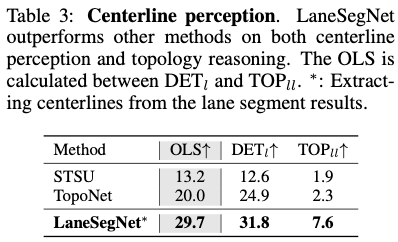
Conscience de la ligne centrale : nous comparons également LaneSegNet avec les méthodes de pointe de connaissance de la ligne centrale dans le tableau 3. Par souci de cohérence, les lignes centrales sont également extraites du segment de voie à des fins de recyclage. On peut conclure que les performances de LaneSegNet dans la tâche de perception de la carte des voies sont nettement supérieures à celles des autres méthodes. Avec une surveillance géographique supplémentaire, LaneSegNet démontre également des capacités de raisonnement topologique supérieures. Il est prouvé que la capacité de raisonnement est étroitement liée à de fortes capacités de positionnement et de détection.
Expérience d'ablation
Formule de segment de voie : dans le tableau 4, nous fournissons l'ablation pour vérifier les avantages de conception et l'efficacité de la formation de notre formule d'apprentissage de segment de voie proposée. Par rapport aux modèles entraînés séparément dans les deux premières rangées, l'entraînement conjoint des lignes centrales et des éléments cartographiques apporte une amélioration moyenne globale de 1,3 sur les deux mesures principales, comme le montre la rangée 4, démontrant la faisabilité d'un entraînement multitâche. Cependant, l'approche courante consistant à former les lignes centrales et les éléments de carte dans une seule branche en ajoutant des catégories supplémentaires entraîne une dégradation significative des performances. Par rapport à la méthode naïve à branche unique ci-dessus, notre modèle entraîné avec les étiquettes de segment de voie obtient une amélioration significative des performances (+7,2 sur OLS et +4,4 sur mAP pour la comparaison entre les lignes 3 et 5). Cela vérifie l'interaction positive entre diverses informations routières dans notre formulation d’apprentissage cartographique. Notre modèle surpasse même les méthodes multibranches, notamment en termes de conscience de la ligne centrale (OLS de +4,8). Cela montre que la géométrie peut guider le raisonnement topologique dans notre formulation d'apprentissage cartographique, où le modèle multi-branches ne surpasse que légèrement le modèle CL uniquement (+0,6 OLS entre les lignes 1 et 4). Quant à la petite diminution, elle provient du processus de remodelage de nos résultats de prédiction, qui est causé par l'erreur de classification des lignes,
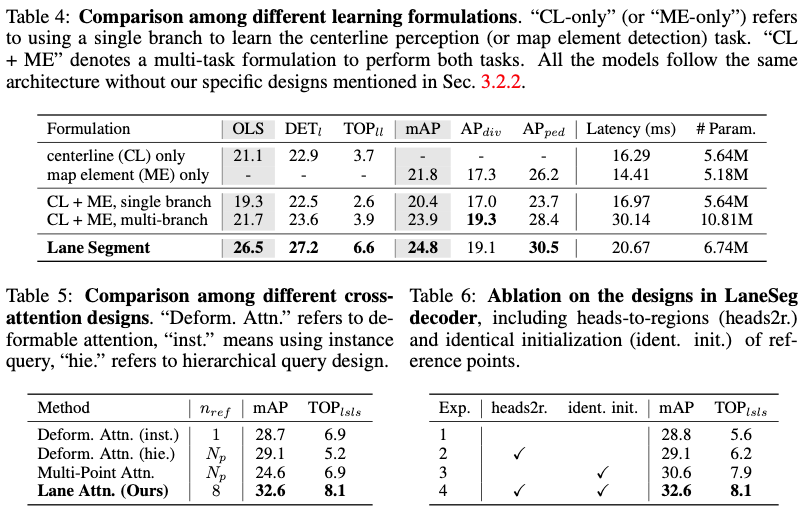
Module d'attention de voie : L'ablation du module d'attention que nous démontrons est présentée dans le tableau 5. Pour faciliter une comparaison équitable, nous remplaçons le module d'attention de voie dans le cadre par une conception d'attention alternative. Grâce à notre conception soignée, LaneSegNet avec attention aux voies surpasse considérablement ces méthodes, montrant des améliorations significatives (mAP amélioré de 3,9 et TOPll amélioré de 1,2 par rapport à la ligne 1). De plus, la latence du décodeur peut être encore réduite (de 23,45 ms à 20,96 ms) en raison de la réduction du nombre de requêtes par rapport à la conception de requêtes hiérarchique.
Conclusion
Cet article propose la sensibilisation aux segments de voie comme nouvelle formule d'apprentissage cartographique et propose LaneSegNet, un réseau de bout en bout spécifiquement ciblé sur ce problème. En plus du réseau, deux améliorations innovantes sont proposées, notamment un module d'attention aux voies qui utilise un mécanisme tête-à-région pour capter l'attention à longue distance, et la même stratégie d'initialisation des points de référence pour améliorer la localisation de l'attention aux voies. apprentissage. Les résultats expérimentaux sur l'ensemble de données OpenLane-V2 démontrent l'efficacité de notre conception.
Limitations et travaux futurs. En raison de limitations informatiques, nous n'étendons pas le LaneSegNet proposé à davantage de réseaux fédérateurs supplémentaires. La formulation de la connaissance des segments de voie et de LaneSegNet peut bénéficier aux tâches en aval et mérite d'être explorée à l'avenir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Que se passe-t-il lorsque le réseau ne parvient pas à se connecter au wifi ?
Apr 03, 2024 pm 12:11 PM
Que se passe-t-il lorsque le réseau ne parvient pas à se connecter au wifi ?
Apr 03, 2024 pm 12:11 PM
1. Vérifiez le mot de passe wifi : assurez-vous que le mot de passe wifi que vous avez saisi est correct et faites attention à la casse. 2. Confirmez si le wifi fonctionne correctement : Vérifiez si le routeur wifi fonctionne normalement. Vous pouvez connecter d'autres appareils au même routeur pour déterminer si le problème vient de l'appareil. 3. Redémarrez l'appareil et le routeur : Parfois, il y a un dysfonctionnement ou un problème de réseau avec l'appareil ou le routeur, et le redémarrage de l'appareil et du routeur peut résoudre le problème. 4. Vérifiez les paramètres de l'appareil : assurez-vous que la fonction sans fil de l'appareil est activée et que la fonction Wi-Fi n'est pas désactivée.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
