
 web3.0
Introduction et comparaison de l'algorithme Firefly et de l'algorithme de résolution métaheuristique
web3.0
Introduction et comparaison de l'algorithme Firefly et de l'algorithme de résolution métaheuristique
Introduction et comparaison de l'algorithme Firefly et de l'algorithme de résolution métaheuristique

L'algorithme de luciole est un algorithme d'optimisation méta-heuristique inspiré du comportement de scintillement des lucioles et est conçu pour résoudre des problèmes d'optimisation continue.
Principe de l'algorithme de luciole
Dans l'algorithme de luciole, la fonction objectif est liée à l'intensité lumineuse à la queue de la luciole. En termes d'optimisation, l'attraction et le mouvement des lucioles peuvent inspirer des algorithmes, qui peuvent être suivis pour obtenir des solutions optimales.
Dans l'algorithme des lucioles, les lucioles font référence à des solutions réalisables générées aléatoirement. On leur attribue une intensité lumineuse proportionnelle à leur valeur fonctionnelle en fonction de leur performance dans la fonction objectif. Pour les problèmes de minimisation, la solution avec la plus petite valeur de fonction se verra attribuer l’intensité lumineuse la plus élevée. Une fois les intensités lumineuses de la solution réparties, chaque luciole suivra la luciole ayant l’intensité lumineuse la plus élevée. La luciole la plus brillante effectuera une recherche locale en se déplaçant aléatoirement autour d'elle.
Cet algorithme imite la façon dont les lucioles interagissent à l'aide de lampes de poche. Supposons que toutes les lucioles sont attirées par le sexe opposé, ce qui signifie que n'importe quelle luciole peut attirer toutes les autres lucioles. L'attractivité d'une luciole est directement proportionnelle à sa luminosité, qui dépend de la fonction objectif. Les lucioles plus brillantes attirent d’autres lucioles. De plus, selon la loi du carré inverse, la luminosité diminue progressivement avec la distance.
Algorithme de luciole et algorithme de résolution métaheuristique
Les lucioles utilisent les caractéristiques de scintillement pour communiquer, et il existe environ 2000 modèles de flash uniques. Ils produisent de brefs éclairs de lumière structurés.
Ce mode de communication flash est utilisé pour attirer les partenaires et avertir les prédateurs. Le bon partenaire communiquera en imitant le même schéma ou en répondant selon un schéma spécifique. Par conséquent, le flash d’une luciole provoque une réaction chez les lucioles proches.
La sélection naturelle et la survie des plus aptes sont les idées fondamentales des premiers algorithmes métaheuristiques. En raison de la complexité de la modélisation des algorithmes, la mise en œuvre de méthodes de résolution déterministes est un défi, favorisant ainsi le développement d’algorithmes de résolution métaheuristiques.
Les algorithmes métaheuristiques sont des solutions approximatives aux problèmes d'optimisation qui utilisent les propriétés du caractère aléatoire pour itérer et améliorer la qualité de la solution à partir d'un ensemble de solutions réalisables générées aléatoirement.
Bien que les algorithmes métaheuristiques ne soient pas garantis optimaux, ils ont été testés pour donner des solutions raisonnables et acceptables.
De plus, les algorithmes métaheuristiques ont l'avantage d'être insensibles aux comportements problématiques, ce qui les rend utiles dans de nombreux scénarios d'application.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Une analyse approfondie de l'algorithme d'optimisation Grey Wolf (GWO) et de ses forces et faiblesses
Jan 19, 2024 pm 07:48 PM
Une analyse approfondie de l'algorithme d'optimisation Grey Wolf (GWO) et de ses forces et faiblesses
Jan 19, 2024 pm 07:48 PM
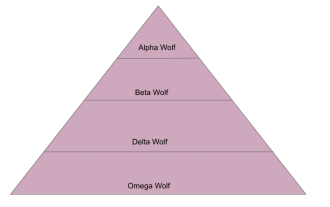
L'algorithme d'optimisation du loup gris (GWO) est un algorithme métaheuristique basé sur la population qui simule la hiérarchie de leadership et le mécanisme de chasse des loups gris dans la nature. Inspiration de l'algorithme du loup gris 1. Les loups gris sont considérés comme des prédateurs au sommet et se situent au sommet de la chaîne alimentaire. 2. Les loups gris aiment vivre en groupe (vivant en groupe), avec une moyenne de 5 à 12 loups dans chaque meute. 3. Les loups gris ont une hiérarchie de dominance sociale très stricte, comme indiqué ci-dessous : Loup alpha : Le loup alpha occupe une position dominante dans l'ensemble du groupe des loups gris et a le droit de commander l'ensemble du groupe des loups gris. Dans l'application des algorithmes, Alpha Wolf est l'une des meilleures solutions, la solution optimale produite par l'algorithme d'optimisation. Loup bêta : Beta wolf rend régulièrement compte à Alpha wolf et aide Alpha wolf à prendre les meilleures décisions. Dans les applications algorithmiques, Beta Wolf peut
 Explorez les principes de base et le processus de mise en œuvre des algorithmes d'échantillonnage imbriqués
Jan 22, 2024 pm 09:51 PM
Explorez les principes de base et le processus de mise en œuvre des algorithmes d'échantillonnage imbriqués
Jan 22, 2024 pm 09:51 PM
L'algorithme d'échantillonnage imbriqué est un algorithme d'inférence statistique bayésien efficace utilisé pour calculer l'intégrale ou la sommation sous des distributions de probabilité complexes. Il fonctionne en décomposant l'espace des paramètres en plusieurs hypercubes de volume égal, et en « poussant » progressivement et itérativement l'un des hypercubes de plus petit volume, puis en remplissant l'hypercube avec des échantillons aléatoires pour mieux estimer la valeur intégrale de la distribution de probabilité. Grâce à une itération continue, l'algorithme d'échantillonnage imbriqué peut obtenir des valeurs intégrales et des limites de l'espace des paramètres de haute précision, qui peuvent être appliquées à des problèmes statistiques tels que la comparaison de modèles, l'estimation des paramètres et la sélection de modèles. L'idée principale de cet algorithme est de transformer des problèmes d'intégration complexes en une série de problèmes d'intégration simples et d'approcher la véritable valeur intégrale en réduisant progressivement le volume de l'espace des paramètres. Chaque étape d'itération échantillonne aléatoirement dans l'espace des paramètres
 Analyser les principes, les modèles et la composition de l'algorithme de recherche Sparrow (SSA)
Jan 19, 2024 pm 10:27 PM
Analyser les principes, les modèles et la composition de l'algorithme de recherche Sparrow (SSA)
Jan 19, 2024 pm 10:27 PM
L'algorithme de recherche Sparrow (SSA) est un algorithme d'optimisation méta-heuristique basé sur le comportement anti-prédation et de recherche de nourriture des moineaux. Le comportement alimentaire des moineaux peut être divisé en deux types principaux : les producteurs et les charognards. Les producteurs recherchent activement de la nourriture, tandis que les charognards rivalisent pour obtenir de la nourriture auprès des producteurs. Principe de l'algorithme de recherche de moineau (SSA) Dans l'algorithme de recherche de moineau (SSA), chaque moineau porte une attention particulière au comportement de ses voisins. En employant différentes stratégies de recherche de nourriture, les individus sont capables d’utiliser efficacement l’énergie retenue pour rechercher davantage de nourriture. De plus, les oiseaux sont plus vulnérables aux prédateurs dans leur espace de recherche et doivent donc trouver des endroits plus sûrs. Les oiseaux au centre d’une colonie peuvent minimiser leur propre danger en restant proches de leurs voisins. Lorsqu'un oiseau repère un prédateur, il émet un cri d'alarme
 Quel est le rôle du gain d'information dans l'algorithme id3 ?
Jan 23, 2024 pm 11:27 PM
Quel est le rôle du gain d'information dans l'algorithme id3 ?
Jan 23, 2024 pm 11:27 PM
L'algorithme ID3 est l'un des algorithmes de base de l'apprentissage des arbres de décision. Il sélectionne le meilleur point de partage en calculant le gain d'informations de chaque fonctionnalité pour générer un arbre de décision. Le gain d'informations est un concept important dans l'algorithme ID3, utilisé pour mesurer la contribution des caractéristiques à la tâche de classification. Cet article présentera en détail le concept, la méthode de calcul et l'application du gain d'information dans l'algorithme ID3. 1. Le concept d'entropie de l'information L'entropie de l'information est un concept de la théorie de l'information qui mesure l'incertitude des variables aléatoires. Pour un nombre de variable aléatoire discrète, et p(x_i) représente la probabilité que la variable aléatoire X prenne la valeur x_i. lettre
 Introduction à l'algorithme Wu-Manber et aux instructions d'implémentation Python
Jan 23, 2024 pm 07:03 PM
Introduction à l'algorithme Wu-Manber et aux instructions d'implémentation Python
Jan 23, 2024 pm 07:03 PM
L'algorithme Wu-Manber est un algorithme de correspondance de chaînes utilisé pour rechercher efficacement des chaînes. Il s'agit d'un algorithme hybride qui combine les avantages des algorithmes de Boyer-Moore et de Knuth-Morris-Pratt pour fournir une correspondance de modèles rapide et précise. Étape 1 de l'algorithme Wu-Manber. Créez une table de hachage qui mappe chaque sous-chaîne possible du modèle à la position du modèle où cette sous-chaîne apparaît. 2. Cette table de hachage est utilisée pour identifier rapidement les emplacements de départ potentiels des modèles dans le texte. 3. Parcourez le texte et comparez chaque caractère au caractère correspondant dans le modèle. 4. Si les caractères correspondent, vous pouvez passer au caractère suivant et poursuivre la comparaison. 5. Si les caractères ne correspondent pas, vous pouvez utiliser une table de hachage pour déterminer le prochain caractère potentiel du modèle.
 Principes d'optimisation numérique et analyse de l'algorithme d'optimisation des baleines (WOA)
Jan 19, 2024 pm 07:27 PM
Principes d'optimisation numérique et analyse de l'algorithme d'optimisation des baleines (WOA)
Jan 19, 2024 pm 07:27 PM
L'algorithme d'optimisation des baleines (WOA) est un algorithme d'optimisation métaheuristique inspiré de la nature qui simule le comportement de chasse des baleines à bosse et est utilisé pour l'optimisation de problèmes numériques. L'algorithme d'optimisation Whale (WOA) commence avec un ensemble de solutions aléatoires et optimise en fonction d'un agent de recherche sélectionné au hasard ou de la meilleure solution jusqu'à présent grâce à des mises à jour de position de l'agent de recherche à chaque itération. Inspiration de l'algorithme d'optimisation des baleines L'algorithme d'optimisation des baleines s'inspire du comportement de chasse des baleines à bosse. Les baleines à bosse préfèrent la nourriture trouvée près de la surface, comme le krill et les bancs de poissons. Par conséquent, les baleines à bosse rassemblent de la nourriture pour former un réseau de bulles en soufflant des bulles dans une spirale ascendante lorsqu’elles chassent. Dans une manœuvre de « spirale ascendante », la baleine à bosse plonge à environ 12 m, puis commence à former une bulle en spirale autour de sa proie et nage vers le haut.
 Algorithme SIFT (Scale Invariant Features)
Jan 22, 2024 pm 05:09 PM
Algorithme SIFT (Scale Invariant Features)
Jan 22, 2024 pm 05:09 PM
L'algorithme SIFT (Scale Invariant Feature Transform) est un algorithme d'extraction de caractéristiques utilisé dans les domaines du traitement d'images et de la vision par ordinateur. Cet algorithme a été proposé en 1999 pour améliorer les performances de reconnaissance et de correspondance d'objets dans les systèmes de vision par ordinateur. L'algorithme SIFT est robuste et précis et est largement utilisé dans la reconnaissance d'images, la reconstruction tridimensionnelle, la détection de cibles, le suivi vidéo et d'autres domaines. Il obtient l'invariance d'échelle en détectant les points clés dans plusieurs espaces d'échelle et en extrayant des descripteurs de caractéristiques locales autour des points clés. Les principales étapes de l'algorithme SIFT comprennent la construction d'un espace d'échelle, la détection des points clés, le positionnement des points clés, l'attribution de directions et la génération de descripteurs de caractéristiques. Grâce à ces étapes, l’algorithme SIFT peut extraire des fonctionnalités robustes et uniques, permettant ainsi un traitement d’image efficace.
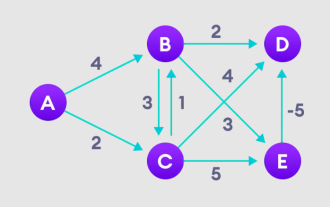 Explication détaillée de l'algorithme Bellman Ford et de sa mise en œuvre en Python
Jan 22, 2024 pm 07:39 PM
Explication détaillée de l'algorithme Bellman Ford et de sa mise en œuvre en Python
Jan 22, 2024 pm 07:39 PM
L'algorithme Bellman Ford peut trouver le chemin le plus court entre le nœud cible et les autres nœuds du graphique pondéré. Ceci est très similaire à l'algorithme de Dijkstra. L'algorithme de Bellman-Ford peut gérer des graphiques avec des poids négatifs et est relativement simple en termes de mise en œuvre. Explication détaillée du principe de l'algorithme de Bellman Ford L'algorithme de Bellman Ford trouve de manière itérative de nouveaux chemins plus courts que les chemins surestimés en surestimant les longueurs de chemin depuis le sommet de départ jusqu'à tous les autres sommets. Parce que nous voulons enregistrer la distance du trajet de chaque nœud, nous pouvons la stocker dans un tableau de taille n, où n représente également le nombre de nœuds. Exemple Figure 1. Sélectionnez le nœud de départ, attribuez-le à tous les autres sommets à l'infini et enregistrez la valeur du chemin. 2. Visitez chaque bord et effectuez des opérations de relaxation pour mettre à jour en permanence le chemin le plus court. 3. Nous avons besoin