

La 11e Conférence internationale sur l'apprentissage de la représentation (ICLR) devrait se tenir hors ligne à Kigali, la capitale du Rwanda, du 1er au 5 mai. Récemment, l'ICLR a annoncé les résultats d'acceptation des articles, dont un total de 3 articles de NetEase Fuxi. Parmi ces trois articles, l'un a été sélectionné comme article de présentation orale et les deux autres ont été sélectionnés comme articles de présentation phare. Le contenu de ces articles implique de nombreux domaines tels que l'apprentissage par renforcement et le traitement du langage naturel. L'article sélectionné cette fois constitue une réalisation importante de l'équipe de NetEase Fuxi dans ces domaines de recherche, et c'est également leur reconnaissance et leur contribution exceptionnelle dans le monde universitaire.

Les expériences montrent que le KLD est plus sensible aux points anormaux, tandis que le TCD est robuste.
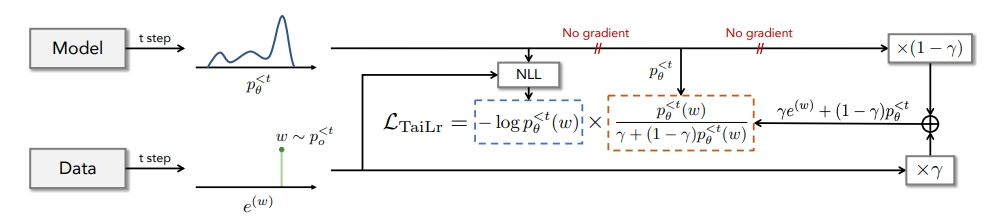
Pour équilibrer l'estimation de TVD, nous introduisons la cible TaiLr. TaiLr atteint cet objectif en réduisant le poids des échantillons de données réelles avec une faible probabilité de modèle, et le niveau de pénalité peut être ajusté selon les besoins. Les expériences démontrent que notre méthode atténue la surestimation des séquences dégénérées tout en conservant la diversité, et améliore la qualité de génération pour un large éventail de tâches de génération de texte.
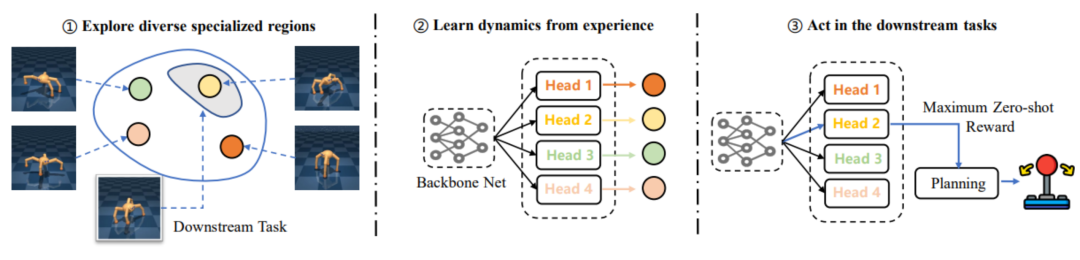
Cependant, les travaux antérieurs se concentrent souvent sur la pré-formation à une stratégie avec différentes compétences grâce à l'exploration de l'environnement. Cependant, il est difficile d'assurer l'amélioration des performances des tâches en aval grâce à des méthodes de pré-formation d'exploration diversifiée, et peuvent même conduire. à une plus grande consommation de pré-entraînement. Plus les performances sont faibles, le problème de « inadéquation ». Par conséquent, NetEase Fuxi et l'équipe du laboratoire d'apprentissage par renforcement profond de l'université de Tianjin ont proposé le cadre EUCLID, qui introduit un paradigme RL basé sur un modèle pour bénéficier de modèles dynamiques précis grâce à une pré-formation à long terme afin d'obtenir une adaptation rapide des tâches en aval et une efficacité d'échantillonnage plus élevée. Dans la phase de réglage fin, EUCLID utilise des modèles dynamiques pré-entraînés pour une planification guidée par les politiques. Ce paramètre peut éliminer les chocs de performances causés par des problèmes d'inadéquation et obtenir des améliorations de performances monotones.
Les résultats expérimentaux montrent que NECSA a obtenu les scores les plus élevés dans tous les environnements expérimentaux et atteint le niveau de pointe.
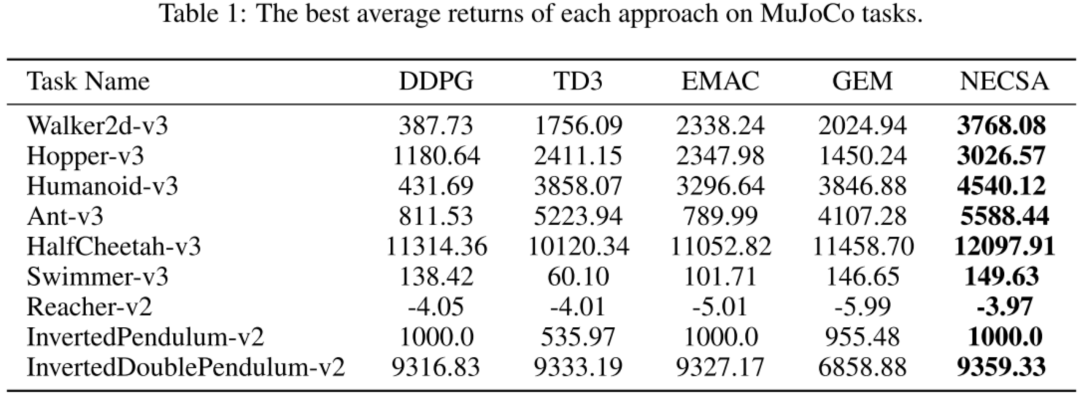
NECSA peut être facilement intégré aux algorithmes d'apprentissage par renforcement et possède une grande polyvalence. L'un des scénarios d'application typiques est la formation de robots de compétition de jeux. NECSA propose une nouvelle idée basée sur l'analyse d'état, qui peut améliorer l'effet d'apprentissage et est particulièrement adaptée à la représentation d'état de jeu complexe et de grande dimension. Grâce à NECSA, le niveau compétitif et l'anthropomorphisme du robot peuvent être optimisés mieux et plus rapidement, et une bonne interprétabilité du modèle peut être fournie. À l'avenir, NetEase Fuxi favorisera l'application pratique de la méthode NECSA dans plusieurs scénarios de jeu.
Un merci tout spécial à l'équipe du professeur Huang Minlie de l'Université Tsinghua pour son importante contribution à la recherche sur "Adapter les modèles de génération de langage sous distance de variation totale". Leurs travaux de recherche ont apporté d'importantes contributions à la personnalisation des modèles de génération de langage, en fournissant de nouvelles idées et méthodes pour améliorer la technologie de traitement du langage naturel. Dans le même temps, nous tenons à remercier le Laboratoire d'apprentissage par renforcement profond de l'Université de Tianjin pour son importante contribution à la recherche sur « EUCLID : Towards Efficient Unsupervised Reinforcement Learning with Multi-choice Dynamics Model ». Leurs travaux de recherche se concentrent sur le domaine de l'apprentissage par renforcement non supervisé et proposent un modèle dynamique à choix multiples efficace, apportant d'importantes contributions au développement d'algorithmes d'apprentissage par renforcement. En outre, nous souhaitons également remercier le laboratoire Pangu de l'Université de Kyushu pour son importante contribution à la recherche sur le "Contrôle épisodique neuronal avec abstraction d'état". Leurs travaux de recherche se concentrent sur le contrôle de la mémoire neuronale et l'abstraction d'état, et proposent une nouvelle méthode de contrôle neuronal, qui fournit de nouvelles idées et un soutien technique pour le développement et l'application de systèmes intelligents. Les contributions de ces équipes de recherche sont non seulement importantes dans le monde universitaire, mais ont également des implications potentielles pour des applications pratiques. Nous leur exprimons notre sincère gratitude pour leur travail exceptionnel et attendons avec impatience leur succès continu dans leurs domaines respectifs. En tant que principale institution nationale de recherche et d'applications sur l'IA dans les jeux et le divertissement, NetEase Fuxi s'engage à ouvrir la technologie et les produits d'IA à davantage de personnes. partenaires. Promouvoir l’application de la technologie de l’intelligence artificielle dans divers domaines. Jusqu'à présent, plus de 200 clients ont choisi les services de NetEase Fuxi et le nombre d'appels dépasse les centaines de millions chaque jour.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Comment utiliser split en python
Comment utiliser split en python
 Racine du téléphone portable
Racine du téléphone portable
 Comment activer le service de stockage cloud
Comment activer le service de stockage cloud
 Combien de personnes pouvez-vous élever sur Douyin ?
Combien de personnes pouvez-vous élever sur Douyin ?
 Algorithme de planification de disque
Algorithme de planification de disque
 utilisation de la fonction de rééchantillonnage
utilisation de la fonction de rééchantillonnage








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



