
 Périphériques technologiques
IA
Utiliser des algorithmes de réduction de dimensionnalité pour réaliser la détection de cibles : conseils et étapes
Périphériques technologiques
IA
Utiliser des algorithmes de réduction de dimensionnalité pour réaliser la détection de cibles : conseils et étapes
Utiliser des algorithmes de réduction de dimensionnalité pour réaliser la détection de cibles : conseils et étapes


La détection d'objets est une tâche clé en vision par ordinateur, où le but est d'identifier et de localiser des objets d'intérêt dans des images ou des vidéos. L'algorithme de réduction de dimensionnalité est une méthode couramment utilisée pour la détection de cibles en convertissant des données d'image de grande dimension en représentation de caractéristiques de basse dimension. Ces fonctionnalités peuvent exprimer efficacement les informations clés de la cible, renforçant ainsi la précision et l'efficacité de la détection de la cible.
Étape 1 : Préparez l'ensemble de données
Tout d'abord, préparez un ensemble de données étiqueté contenant l'image originale et la région d'intérêt correspondante. Ces régions peuvent être annotées manuellement ou générées à l'aide d'algorithmes de détection d'objets existants. Chaque région doit être annotée avec un cadre de délimitation et des informations sur la catégorie.
Étape 2 : Construire le modèle
Afin de réaliser la tâche de détection de cible, il est généralement nécessaire de construire un modèle d'apprentissage en profondeur qui peut recevoir l'image originale en entrée et en sortie les coordonnées du cadre de délimitation de la zone d'intérêt. Une approche courante consiste à utiliser des modèles de régression basés sur des réseaux de neurones convolutifs (CNN). En entraînant ce modèle, le mappage des images aux coordonnées du cadre de délimitation peut être appris pour détecter les régions d'intérêt. Cet algorithme de réduction de dimensionnalité peut réduire efficacement la dimension des données d'entrée et extraire des informations de caractéristiques liées à la détection de cible, améliorant ainsi les performances de détection.
Étape 3 : Entraîner le modèle
Après avoir préparé l'ensemble de données et le modèle, vous pouvez commencer à entraîner le modèle. L’objectif de la formation est de permettre au modèle de prédire le plus précisément possible les coordonnées du cadre de délimitation de la région d’intérêt. Une fonction de perte courante est l'erreur quadratique moyenne (MSE), qui mesure la différence entre les coordonnées prévues du cadre de délimitation et les coordonnées réelles. Des algorithmes d'optimisation tels que la descente de gradient peuvent être utilisés pour minimiser la fonction de perte, mettant ainsi à jour les paramètres de poids du modèle.
Étape 4 : Tester le modèle
Une fois la formation terminée, vous pouvez utiliser l'ensemble de données de test pour évaluer les performances du modèle. Au moment du test, le modèle est appliqué aux images de l'ensemble de données de test et les coordonnées prévues du cadre de délimitation sont générées. Ensuite, les cadres englobants prédits sont comparés aux cadres englobants annotés par la vérité terrain pour évaluer la précision du modèle. Les indicateurs d'évaluation couramment utilisés incluent la précision, le rappel, le mAP, etc.
Étape 5 : Appliquer le modèle
Après avoir réussi le test, vous pouvez appliquer le modèle entraîné à la tâche de détection de cible réelle. Pour chaque image d'entrée, le modèle affichera les coordonnées du cadre de délimitation de la zone d'intérêt pour détecter l'objet cible. Si nécessaire, le cadre de délimitation de sortie peut être post-traité, tel qu'une suppression non maximale (NMS), etc., pour améliorer la précision des résultats de détection.
Parmi elles, l'étape 2 de la construction du modèle est une étape critique, qui peut être réalisée en utilisant des technologies d'apprentissage en profondeur telles que les réseaux de neurones convolutifs. Pendant le processus de formation et de test, des fonctions de perte et des mesures d'évaluation appropriées doivent être utilisées pour mesurer les performances du modèle. Enfin, grâce à une application pratique, une détection précise des objets cibles peut être obtenue.
Exemple d'utilisation d'un algorithme de réduction de dimensionnalité pour réaliser la détection de cible
Après avoir présenté les méthodes et étapes spécifiques, regardons l'exemple de mise en œuvre. Voici un exemple simple écrit en Python qui illustre comment implémenter la détection d'objets à l'aide d'un algorithme de réduction de dimensionnalité :
import numpy as np
import cv2
# 准备数据集
image_path = 'example.jpg'
annotation_path = 'example.json'
image = cv2.imread(image_path)
with open(annotation_path, 'r') as f:
annotations = np.array(json.load(f))
# 构建模型
model = cv2.dnn.readNetFromCaffe('deploy.prototxt', 'res101_iter_70000.caffemodel')
blob = cv2.dnn.blobFromImage(image, scalefactor=0.007843, size=(224, 224), mean=(104.0, 117.0, 123.0), swapRB=False, crop=False)
model.setInput(blob)
# 训练模型
output = model.forward()
indices = cv2.dnn.NMSBoxes(output, score_threshold=0.5, nms_threshold=0.4)
# 应用模型
for i in indices[0]:
box = output[i, :4] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
cv2.rectangle(image, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), (0, 255, 0), 2)
cv2.imshow('Output', image)
cv2.waitKey(0)Cet exemple de code utilise la bibliothèque OpenCV pour implémenter la détection d'objets. Tout d’abord, un ensemble de données étiquetées doit être préparé, contenant les images originales et leurs régions d’intérêt correspondantes. Dans cet exemple, nous supposons que nous disposons déjà d'un fichier JSON contenant des informations d'annotation. Ensuite, créez un modèle d'apprentissage en profondeur, ici en utilisant le modèle ResNet101 pré-entraîné. Ensuite, le modèle est appliqué à l’image d’entrée pour obtenir les coordonnées prédites du cadre de délimitation. Enfin, les cadres de délimitation prédits sont appliqués à l’image et la sortie est affichée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



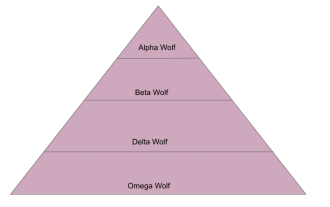 Une analyse approfondie de l'algorithme d'optimisation Grey Wolf (GWO) et de ses forces et faiblesses
Jan 19, 2024 pm 07:48 PM
Une analyse approfondie de l'algorithme d'optimisation Grey Wolf (GWO) et de ses forces et faiblesses
Jan 19, 2024 pm 07:48 PM
L'algorithme d'optimisation du loup gris (GWO) est un algorithme métaheuristique basé sur la population qui simule la hiérarchie de leadership et le mécanisme de chasse des loups gris dans la nature. Inspiration de l'algorithme du loup gris 1. Les loups gris sont considérés comme des prédateurs au sommet et se situent au sommet de la chaîne alimentaire. 2. Les loups gris aiment vivre en groupe (vivant en groupe), avec une moyenne de 5 à 12 loups dans chaque meute. 3. Les loups gris ont une hiérarchie de dominance sociale très stricte, comme indiqué ci-dessous : Loup alpha : Le loup alpha occupe une position dominante dans l'ensemble du groupe des loups gris et a le droit de commander l'ensemble du groupe des loups gris. Dans l'application des algorithmes, Alpha Wolf est l'une des meilleures solutions, la solution optimale produite par l'algorithme d'optimisation. Loup bêta : Beta wolf rend régulièrement compte à Alpha wolf et aide Alpha wolf à prendre les meilleures décisions. Dans les applications algorithmiques, Beta Wolf peut
 La différence entre les algorithmes de détection de cible à une étape et à deux étapes
Jan 23, 2024 pm 01:48 PM
La différence entre les algorithmes de détection de cible à une étape et à deux étapes
Jan 23, 2024 pm 01:48 PM
La détection d'objets est une tâche importante dans le domaine de la vision par ordinateur, utilisée pour identifier des objets dans des images ou des vidéos et localiser leur emplacement. Cette tâche est généralement divisée en deux catégories d'algorithmes, à une étape et à deux étapes, qui diffèrent en termes de précision et de robustesse. Algorithme de détection de cible en une seule étape L'algorithme de détection de cible en une seule étape convertit la détection de cible en un problème de classification. Son avantage est qu'il est rapide et peut terminer la détection en une seule étape. Cependant, en raison d'une simplification excessive, la précision n'est généralement pas aussi bonne que celle de l'algorithme de détection d'objets en deux étapes. Les algorithmes courants de détection d'objets en une seule étape incluent YOLO, SSD et FasterR-CNN. Ces algorithmes prennent généralement l’image entière en entrée et exécutent un classificateur pour identifier l’objet cible. Contrairement aux algorithmes traditionnels de détection de cibles en deux étapes, ils n'ont pas besoin de définir des zones à l'avance, mais de prédire directement
 Explorez les principes de base et le processus de mise en œuvre des algorithmes d'échantillonnage imbriqués
Jan 22, 2024 pm 09:51 PM
Explorez les principes de base et le processus de mise en œuvre des algorithmes d'échantillonnage imbriqués
Jan 22, 2024 pm 09:51 PM
L'algorithme d'échantillonnage imbriqué est un algorithme d'inférence statistique bayésien efficace utilisé pour calculer l'intégrale ou la sommation sous des distributions de probabilité complexes. Il fonctionne en décomposant l'espace des paramètres en plusieurs hypercubes de volume égal, et en « poussant » progressivement et itérativement l'un des hypercubes de plus petit volume, puis en remplissant l'hypercube avec des échantillons aléatoires pour mieux estimer la valeur intégrale de la distribution de probabilité. Grâce à une itération continue, l'algorithme d'échantillonnage imbriqué peut obtenir des valeurs intégrales et des limites de l'espace des paramètres de haute précision, qui peuvent être appliquées à des problèmes statistiques tels que la comparaison de modèles, l'estimation des paramètres et la sélection de modèles. L'idée principale de cet algorithme est de transformer des problèmes d'intégration complexes en une série de problèmes d'intégration simples et d'approcher la véritable valeur intégrale en réduisant progressivement le volume de l'espace des paramètres. Chaque étape d'itération échantillonne aléatoirement dans l'espace des paramètres
 Comment utiliser la technologie IA pour restaurer d'anciennes photos (avec exemples et analyse de code)
Jan 24, 2024 pm 09:57 PM
Comment utiliser la technologie IA pour restaurer d'anciennes photos (avec exemples et analyse de code)
Jan 24, 2024 pm 09:57 PM
La restauration de photos anciennes est une méthode d'utilisation de la technologie de l'intelligence artificielle pour réparer, améliorer et améliorer de vieilles photos. Grâce à des algorithmes de vision par ordinateur et d’apprentissage automatique, la technologie peut identifier et réparer automatiquement les dommages et les imperfections des anciennes photos, les rendant ainsi plus claires, plus naturelles et plus réalistes. Les principes techniques de la restauration de photos anciennes incluent principalement les aspects suivants : 1. Débruitage et amélioration de l'image Lors de la restauration de photos anciennes, elles doivent d'abord être débruitées et améliorées. Des algorithmes et des filtres de traitement d'image, tels que le filtrage moyen, le filtrage gaussien, le filtrage bilatéral, etc., peuvent être utilisés pour résoudre les problèmes de bruit et de taches de couleur, améliorant ainsi la qualité des photos. 2. Restauration et réparation d'images Les anciennes photos peuvent présenter certains défauts et dommages, tels que des rayures, des fissures, une décoloration, etc. Ces problèmes peuvent être résolus par des algorithmes de restauration et de réparation d’images
 Application de la technologie de l'IA à la reconstruction d'images en super-résolution
Jan 23, 2024 am 08:06 AM
Application de la technologie de l'IA à la reconstruction d'images en super-résolution
Jan 23, 2024 am 08:06 AM
La reconstruction d'images en super-résolution est le processus de génération d'images haute résolution à partir d'images basse résolution à l'aide de techniques d'apprentissage en profondeur, telles que les réseaux neuronaux convolutifs (CNN) et les réseaux contradictoires génératifs (GAN). Le but de cette méthode est d'améliorer la qualité et les détails des images en convertissant des images basse résolution en images haute résolution. Cette technologie trouve de nombreuses applications dans de nombreux domaines, comme l’imagerie médicale, les caméras de surveillance, les images satellites, etc. Grâce à la reconstruction d’images en super-résolution, nous pouvons obtenir des images plus claires et plus détaillées, ce qui permet d’analyser et d’identifier plus précisément les cibles et les caractéristiques des images. Méthodes de reconstruction Les méthodes de reconstruction d'images en super-résolution peuvent généralement être divisées en deux catégories : les méthodes basées sur l'interpolation et les méthodes basées sur l'apprentissage profond. 1) Méthode basée sur l'interpolation Reconstruction d'images en super-résolution basée sur l'interpolation
 Analyser les principes, les modèles et la composition de l'algorithme de recherche Sparrow (SSA)
Jan 19, 2024 pm 10:27 PM
Analyser les principes, les modèles et la composition de l'algorithme de recherche Sparrow (SSA)
Jan 19, 2024 pm 10:27 PM
L'algorithme de recherche Sparrow (SSA) est un algorithme d'optimisation méta-heuristique basé sur le comportement anti-prédation et de recherche de nourriture des moineaux. Le comportement alimentaire des moineaux peut être divisé en deux types principaux : les producteurs et les charognards. Les producteurs recherchent activement de la nourriture, tandis que les charognards rivalisent pour obtenir de la nourriture auprès des producteurs. Principe de l'algorithme de recherche de moineau (SSA) Dans l'algorithme de recherche de moineau (SSA), chaque moineau porte une attention particulière au comportement de ses voisins. En employant différentes stratégies de recherche de nourriture, les individus sont capables d’utiliser efficacement l’énergie retenue pour rechercher davantage de nourriture. De plus, les oiseaux sont plus vulnérables aux prédateurs dans leur espace de recherche et doivent donc trouver des endroits plus sûrs. Les oiseaux au centre d’une colonie peuvent minimiser leur propre danger en restant proches de leurs voisins. Lorsqu'un oiseau repère un prédateur, il émet un cri d'alarme
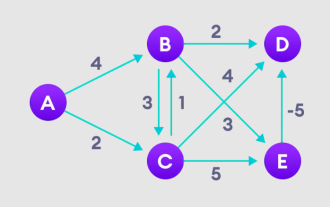 Explication détaillée de l'algorithme Bellman Ford et de sa mise en œuvre en Python
Jan 22, 2024 pm 07:39 PM
Explication détaillée de l'algorithme Bellman Ford et de sa mise en œuvre en Python
Jan 22, 2024 pm 07:39 PM
L'algorithme Bellman Ford peut trouver le chemin le plus court entre le nœud cible et les autres nœuds du graphique pondéré. Ceci est très similaire à l'algorithme de Dijkstra. L'algorithme de Bellman-Ford peut gérer des graphiques avec des poids négatifs et est relativement simple en termes de mise en œuvre. Explication détaillée du principe de l'algorithme de Bellman Ford L'algorithme de Bellman Ford trouve de manière itérative de nouveaux chemins plus courts que les chemins surestimés en surestimant les longueurs de chemin depuis le sommet de départ jusqu'à tous les autres sommets. Parce que nous voulons enregistrer la distance du trajet de chaque nœud, nous pouvons la stocker dans un tableau de taille n, où n représente également le nombre de nœuds. Exemple Figure 1. Sélectionnez le nœud de départ, attribuez-le à tous les autres sommets à l'infini et enregistrez la valeur du chemin. 2. Visitez chaque bord et effectuez des opérations de relaxation pour mettre à jour en permanence le chemin le plus court. 3. Nous avons besoin
 Principes d'optimisation numérique et analyse de l'algorithme d'optimisation des baleines (WOA)
Jan 19, 2024 pm 07:27 PM
Principes d'optimisation numérique et analyse de l'algorithme d'optimisation des baleines (WOA)
Jan 19, 2024 pm 07:27 PM
L'algorithme d'optimisation des baleines (WOA) est un algorithme d'optimisation métaheuristique inspiré de la nature qui simule le comportement de chasse des baleines à bosse et est utilisé pour l'optimisation de problèmes numériques. L'algorithme d'optimisation Whale (WOA) commence avec un ensemble de solutions aléatoires et optimise en fonction d'un agent de recherche sélectionné au hasard ou de la meilleure solution jusqu'à présent grâce à des mises à jour de position de l'agent de recherche à chaque itération. Inspiration de l'algorithme d'optimisation des baleines L'algorithme d'optimisation des baleines s'inspire du comportement de chasse des baleines à bosse. Les baleines à bosse préfèrent la nourriture trouvée près de la surface, comme le krill et les bancs de poissons. Par conséquent, les baleines à bosse rassemblent de la nourriture pour former un réseau de bulles en soufflant des bulles dans une spirale ascendante lorsqu’elles chassent. Dans une manœuvre de « spirale ascendante », la baleine à bosse plonge à environ 12 m, puis commence à former une bulle en spirale autour de sa proie et nage vers le haut.
