
 Périphériques technologiques
IA
Un guide pour l'application des machines Boltzmann dans l'extraction de caractéristiques
Périphériques technologiques
IA
Un guide pour l'application des machines Boltzmann dans l'extraction de caractéristiques
Un guide pour l'application des machines Boltzmann dans l'extraction de caractéristiques


Boltzmann Machine (BM) est un réseau neuronal basé sur des probabilités composé de plusieurs neurones avec des relations de connexion aléatoires entre les neurones. La tâche principale de BM est d'extraire des caractéristiques en apprenant la distribution de probabilité des données. Cet article présentera comment appliquer BM à l'extraction de fonctionnalités et fournira quelques exemples d'application pratiques.
1. La structure de base de BM
BM se compose de couches visibles et de couches cachées. La couche visible reçoit des données brutes et la couche cachée obtient une expression de fonctionnalités de haut niveau grâce à l'apprentissage.
En BM, chaque neurone a deux états, respectivement 0 et 1. Le processus d’apprentissage de BM peut être divisé en phase de formation et phase de test. Lors de la phase de formation, BM apprend la distribution de probabilité des données afin de générer de nouveaux échantillons de données lors de la phase de test. Pendant la phase de test, BM peut être appliqué à des tâches telles que l'extraction et la classification de fonctionnalités.
2. Processus de formation BM
La formation BM utilise généralement l'algorithme de rétro-propagation. Cet algorithme calcule les gradients de tous les poids du réseau et utilise ces gradients pour mettre à jour les poids. Le processus de formation de BM comprend les étapes suivantes : Premièrement, par propagation vers l'avant, les données d'entrée sont transmises de la couche d'entrée à la couche de sortie et la sortie du réseau est calculée. Ensuite, en comparant le résultat avec le résultat attendu, l’erreur du réseau est calculée. Ensuite, l'algorithme de rétropropagation est utilisé, à partir de la couche de sortie, le gradient de chaque poids est calculé couche par couche et les poids sont mis à jour à l'aide de la méthode de descente de gradient. Ce processus est répété plusieurs fois jusqu'à ce que l'erreur du réseau atteigne une plage acceptable.
1. Initialisez la matrice de poids et le vecteur de biais de BM.
2. Saisissez les échantillons de données dans la couche visible de BM.
3. Calculez l'état des neurones de la couche cachée grâce à la fonction d'activation aléatoire de BM (telle que la fonction sigmoïde).
4. Calculez la distribution de probabilité conjointe de la couche visible et de la couche cachée en fonction de l'état des neurones de la couche cachée.
5. Utilisez l'algorithme de rétropropagation pour calculer le gradient de la matrice de poids et du vecteur de biais, et mettre à jour leurs valeurs.
6. Répétez les étapes 2 à 5 jusqu'à ce que la matrice de poids et le vecteur de biais de BM convergent.
Pendant le processus de formation de BM, différents algorithmes d'optimisation peuvent être utilisés pour mettre à jour la matrice de poids et le vecteur de biais. Les algorithmes d'optimisation couramment utilisés incluent la descente de gradient stochastique (SGD), Adam, Adagrad, etc.
3. Application de BM dans l'extraction de caractéristiques
BM peut être utilisé pour des tâches d'extraction de caractéristiques. L'idée de base est d'extraire une représentation de caractéristiques de haut niveau des données en apprenant la distribution de probabilité des données. Plus précisément, les neurones de la couche cachée de BM peuvent être utilisés comme extracteurs de caractéristiques, et les états de ces neurones peuvent être utilisés comme représentations de caractéristiques de haut niveau des données.
Par exemple, dans les tâches de reconnaissance d'images, BM peut être utilisé pour extraire des représentations de caractéristiques de haut niveau d'images. Tout d’abord, les données d’image originales sont entrées dans la couche visible de BM. Par la suite, grâce au processus de formation BM, la distribution de probabilité des données d'image est apprise. Enfin, l’état des neurones de la couche cachée de BM est utilisé comme représentation caractéristique de haut niveau de l’image pour les tâches de classification ultérieures.
De même, dans les tâches de traitement du langage naturel, BM peut être utilisé pour extraire des représentations de fonctionnalités de haut niveau du texte. Tout d’abord, les données textuelles brutes sont saisies dans la couche visible de BM. Par la suite, grâce au processus de formation BM, la distribution de probabilité des données textuelles est apprise. Enfin, l'état des neurones de la couche cachée de BM est utilisé comme représentation caractéristique de haut niveau du texte pour la classification, le regroupement et d'autres tâches ultérieures.
Avantages et inconvénients de BM
En tant que modèle de réseau neuronal basé sur les probabilités, BM présente les avantages suivants :
1 Il peut apprendre la distribution de probabilité des données pour en extraire une représentation de caractéristiques de haut niveau. les données.
2. Il peut être utilisé pour générer de nouveaux échantillons de données et possède certaines capacités de génération.
3. Peut gérer des données incomplètes ou bruyantes et possède une certaine robustesse.
Cependant, BM présente également quelques lacunes :
1 Le processus de formation est relativement complexe et nécessite l'utilisation d'algorithmes d'optimisation tels que des algorithmes de rétropropagation pour la formation.
2. La formation est longue et nécessite beaucoup de ressources informatiques et de temps.
3. Le nombre de neurones de la couche cachée doit être déterminé à l'avance, ce qui n'est pas propice à l'expansion et à l'application du modèle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Explorez les concepts, les différences, les avantages et les inconvénients de RNN, LSTM et GRU
Jan 22, 2024 pm 07:51 PM
Explorez les concepts, les différences, les avantages et les inconvénients de RNN, LSTM et GRU
Jan 22, 2024 pm 07:51 PM
Dans les données de séries chronologiques, il existe des dépendances entre les observations, elles ne sont donc pas indépendantes les unes des autres. Cependant, les réseaux de neurones traditionnels traitent chaque observation comme indépendante, ce qui limite la capacité du modèle à modéliser des données de séries chronologiques. Pour résoudre ce problème, le réseau neuronal récurrent (RNN) a été introduit, qui a introduit le concept de mémoire pour capturer les caractéristiques dynamiques des données de séries chronologiques en établissant des dépendances entre les points de données du réseau. Grâce à des connexions récurrentes, RNN peut transmettre des informations antérieures à l'observation actuelle pour mieux prédire les valeurs futures. Cela fait de RNN un outil puissant pour les tâches impliquant des données de séries chronologiques. Mais comment RNN parvient-il à obtenir ce type de mémoire ? RNN réalise la mémoire via la boucle de rétroaction dans le réseau neuronal. C'est la différence entre RNN et le réseau neuronal traditionnel.
 Calcul des opérandes à virgule flottante (FLOPS) pour les réseaux de neurones
Jan 22, 2024 pm 07:21 PM
Calcul des opérandes à virgule flottante (FLOPS) pour les réseaux de neurones
Jan 22, 2024 pm 07:21 PM
FLOPS est l'une des normes d'évaluation des performances informatiques, utilisée pour mesurer le nombre d'opérations en virgule flottante par seconde. Dans les réseaux de neurones, FLOPS est souvent utilisé pour évaluer la complexité informatique du modèle et l'utilisation des ressources informatiques. C'est un indicateur important utilisé pour mesurer la puissance de calcul et l'efficacité d'un ordinateur. Un réseau de neurones est un modèle complexe composé de plusieurs couches de neurones utilisées pour des tâches telles que la classification, la régression et le clustering des données. La formation et l'inférence des réseaux de neurones nécessitent un grand nombre de multiplications matricielles, de convolutions et d'autres opérations de calcul, la complexité de calcul est donc très élevée. FLOPS (FloatingPointOperationsperSecond) peut être utilisé pour mesurer la complexité de calcul des réseaux de neurones afin d'évaluer l'efficacité d'utilisation des ressources de calcul du modèle. FIASCO
 Définition et analyse structurelle du réseau neuronal flou
Jan 22, 2024 pm 09:09 PM
Définition et analyse structurelle du réseau neuronal flou
Jan 22, 2024 pm 09:09 PM
Le réseau de neurones flous est un modèle hybride qui combine la logique floue et les réseaux de neurones pour résoudre des problèmes flous ou incertains difficiles à gérer avec les réseaux de neurones traditionnels. Sa conception s'inspire du flou et de l'incertitude de la cognition humaine, c'est pourquoi il est largement utilisé dans les systèmes de contrôle, la reconnaissance de formes, l'exploration de données et d'autres domaines. L'architecture de base du réseau neuronal flou se compose d'un sous-système flou et d'un sous-système neuronal. Le sous-système flou utilise la logique floue pour traiter les données d'entrée et les convertir en ensembles flous pour exprimer le flou et l'incertitude des données d'entrée. Le sous-système neuronal utilise des réseaux de neurones pour traiter des ensembles flous pour des tâches telles que la classification, la régression ou le clustering. L'interaction entre le sous-système flou et le sous-système neuronal confère au réseau neuronal flou des capacités de traitement plus puissantes et peut
 Une étude de cas sur l'utilisation du modèle LSTM bidirectionnel pour la classification de texte
Jan 24, 2024 am 10:36 AM
Une étude de cas sur l'utilisation du modèle LSTM bidirectionnel pour la classification de texte
Jan 24, 2024 am 10:36 AM
Le modèle LSTM bidirectionnel est un réseau neuronal utilisé pour la classification de texte. Vous trouverez ci-dessous un exemple simple montrant comment utiliser le LSTM bidirectionnel pour les tâches de classification de texte. Tout d'abord, nous devons importer les bibliothèques et modules requis : importosimportnumpyasnpfromkeras.preprocessing.textimportTokenizerfromkeras.preprocessing.sequenceimportpad_sequencesfromkeras.modelsimportSequentialfromkeras.layersimportDense,Em
 Débruitage d'image à l'aide de réseaux de neurones convolutifs
Jan 23, 2024 pm 11:48 PM
Débruitage d'image à l'aide de réseaux de neurones convolutifs
Jan 23, 2024 pm 11:48 PM
Les réseaux de neurones convolutifs fonctionnent bien dans les tâches de débruitage d'images. Il utilise les filtres appris pour filtrer le bruit et restaurer ainsi l'image originale. Cet article présente en détail la méthode de débruitage d'image basée sur un réseau neuronal convolutif. 1. Présentation du réseau neuronal convolutif Le réseau neuronal convolutif est un algorithme d'apprentissage en profondeur qui utilise une combinaison de plusieurs couches convolutives, des couches de regroupement et des couches entièrement connectées pour apprendre et classer les caractéristiques de l'image. Dans la couche convolutive, les caractéristiques locales de l'image sont extraites via des opérations de convolution, capturant ainsi la corrélation spatiale dans l'image. La couche de pooling réduit la quantité de calcul en réduisant la dimension des fonctionnalités et conserve les principales fonctionnalités. La couche entièrement connectée est responsable du mappage des fonctionnalités et des étiquettes apprises pour mettre en œuvre la classification des images ou d'autres tâches. La conception de cette structure de réseau rend les réseaux de neurones convolutifs utiles dans le traitement et la reconnaissance d'images.
 Réseau de neurones jumeaux : analyse des principes et des applications
Jan 24, 2024 pm 04:18 PM
Réseau de neurones jumeaux : analyse des principes et des applications
Jan 24, 2024 pm 04:18 PM
Le réseau neuronal siamois est une structure de réseau neuronal artificiel unique. Il se compose de deux réseaux de neurones identiques partageant les mêmes paramètres et poids. Dans le même temps, les deux réseaux partagent également les mêmes données d’entrée. Cette conception a été inspirée par des jumeaux, car les deux réseaux de neurones sont structurellement identiques. Le principe du réseau neuronal siamois est d'accomplir des tâches spécifiques, telles que la correspondance d'images, la correspondance de textes et la reconnaissance de visages, en comparant la similitude ou la distance entre deux données d'entrée. Pendant la formation, le réseau tente de mapper des données similaires vers des régions adjacentes et des données différentes vers des régions distantes. De cette manière, le réseau peut apprendre à classer ou à faire correspondre différentes données pour obtenir des résultats correspondants.
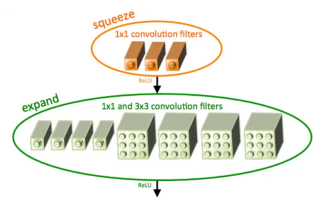 Introduction à SqueezeNet et ses caractéristiques
Jan 22, 2024 pm 07:15 PM
Introduction à SqueezeNet et ses caractéristiques
Jan 22, 2024 pm 07:15 PM
SqueezeNet est un algorithme petit et précis qui établit un bon équilibre entre haute précision et faible complexité, ce qui le rend idéal pour les systèmes mobiles et embarqués aux ressources limitées. En 2016, des chercheurs de DeepScale, de l'Université de Californie à Berkeley et de l'Université de Stanford ont proposé SqueezeNet, un réseau neuronal convolutif (CNN) compact et efficace. Ces dernières années, les chercheurs ont apporté plusieurs améliorations à SqueezeNet, notamment SqueezeNetv1.1 et SqueezeNetv2.0. Les améliorations apportées aux deux versions augmentent non seulement la précision, mais réduisent également les coûts de calcul. Précision de SqueezeNetv1.1 sur l'ensemble de données ImageNet
 réseau neuronal convolutif causal
Jan 24, 2024 pm 12:42 PM
réseau neuronal convolutif causal
Jan 24, 2024 pm 12:42 PM
Le réseau neuronal convolutif causal est un réseau neuronal convolutif spécial conçu pour les problèmes de causalité dans les données de séries chronologiques. Par rapport aux réseaux de neurones convolutifs conventionnels, les réseaux de neurones convolutifs causals présentent des avantages uniques en ce qu'ils conservent la relation causale des séries chronologiques et sont largement utilisés dans la prédiction et l'analyse des données de séries chronologiques. L'idée centrale du réseau neuronal convolutionnel causal est d'introduire la causalité dans l'opération de convolution. Les réseaux neuronaux convolutifs traditionnels peuvent percevoir simultanément les données avant et après le point temporel actuel, mais dans la prévision des séries chronologiques, cela peut entraîner des problèmes de fuite d'informations. Parce que le résultat de la prédiction à l’heure actuelle sera affecté par les données à l’heure future. Le réseau neuronal convolutionnel causal résout ce problème. Il ne peut percevoir que le point temporel actuel et les données précédentes, mais ne peut pas percevoir les données futures.
