
 Périphériques technologiques
IA
Analyse des méthodes d'apprentissage des réseaux de neurones artificiels en apprentissage profond
Périphériques technologiques
IA
Analyse des méthodes d'apprentissage des réseaux de neurones artificiels en apprentissage profond
Analyse des méthodes d'apprentissage des réseaux de neurones artificiels en apprentissage profond

Le deep learning est une branche de l'apprentissage automatique conçue pour simuler les capacités du cerveau en matière de traitement de données. Il résout les problèmes en créant des modèles de réseaux neuronaux artificiels qui permettent aux machines d’apprendre sans supervision. Cette approche permet aux machines d'extraire et de comprendre automatiquement des modèles et des fonctionnalités complexes. Grâce au deep learning, les machines peuvent apprendre à partir de grandes quantités de données et fournir des prédictions et des décisions très précises. Cela a permis à l’apprentissage profond de connaître de grands succès dans des domaines tels que la vision par ordinateur, le traitement du langage naturel et la reconnaissance vocale.
Pour comprendre le fonctionnement des réseaux neuronaux, considérons la transmission des impulsions dans les neurones. Une fois les données reçues de la dendrite terminale, elles sont pondérées (multipliées par w) dans le noyau, puis transmises le long de l'axone et connectées à une autre cellule nerveuse. Les axones (x) sont la sortie d'un neurone et deviennent l'entrée d'un autre neurone, assurant ainsi le transfert d'informations entre les nerfs.
Afin de modéliser et de s'entraîner sur l'ordinateur, nous devons comprendre l'algorithme de l'opération et obtenir le résultat en saisissant la commande.
Ici, nous l'exprimons par les mathématiques, comme suit :
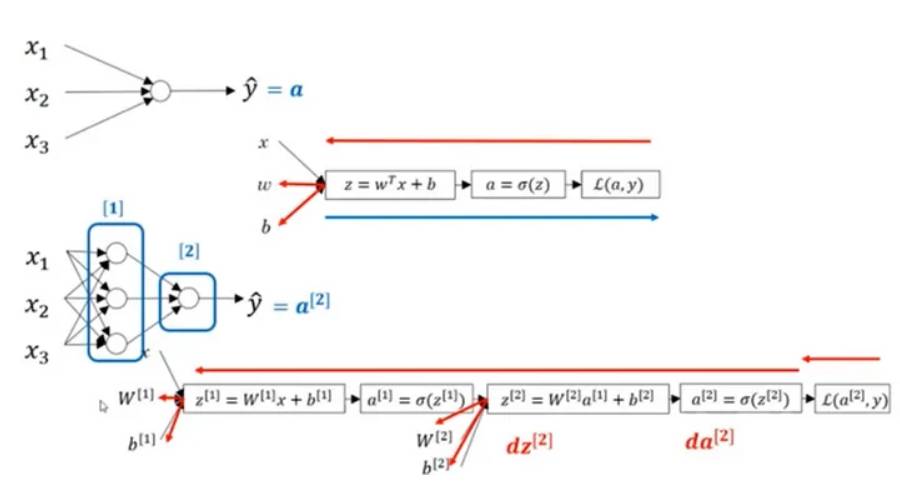
Dans la figure ci-dessus, un réseau neuronal à 2 couches est représenté, qui contient une couche cachée de 4 neurones et une couche de sortie contenant un seul neurone. Il convient de noter que le nombre de couches d'entrée n'affecte pas le fonctionnement du réseau neuronal. Le nombre de neurones dans ces couches et le nombre de valeurs d'entrée sont représentés par les paramètres w et b. Plus précisément, l’entrée de la couche cachée est x et l’entrée de la couche de sortie est la valeur de a.
Tangente hyperbolique, ReLU, Leaky ReLU et d'autres fonctions peuvent remplacer la sigmoïde en tant que fonction d'activation différentiable et être utilisées dans la couche, et les poids sont mis à jour via l'opération dérivée en rétropropagation.
La fonction d'activation ReLU est largement utilisée dans l'apprentissage profond. Puisque les parties de la fonction ReLU inférieures à 0 ne sont pas différenciables, elles n'apprennent pas pendant l'entraînement. La fonction d'activation Leaky ReLU résout ce problème. Elle est différenciable en parties inférieures à 0 et apprendra dans tous les cas. Cela rend Leaky ReLU plus efficace que ReLU dans certains scénarios.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Dans la vague actuelle de changements technologiques rapides, l'intelligence artificielle (IA), l'apprentissage automatique (ML) et l'apprentissage profond (DL) sont comme des étoiles brillantes, à la tête de la nouvelle vague des technologies de l'information. Ces trois mots apparaissent fréquemment dans diverses discussions de pointe et applications pratiques, mais pour de nombreux explorateurs novices dans ce domaine, leurs significations spécifiques et leurs connexions internes peuvent encore être entourées de mystère. Alors regardons d'abord cette photo. On constate qu’il existe une corrélation étroite et une relation progressive entre l’apprentissage profond, l’apprentissage automatique et l’intelligence artificielle. Le deep learning est un domaine spécifique du machine learning, et le machine learning
 Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Près de 20 ans se sont écoulés depuis que le concept d'apprentissage profond a été proposé en 2006. L'apprentissage profond, en tant que révolution dans le domaine de l'intelligence artificielle, a donné naissance à de nombreux algorithmes influents. Alors, selon vous, quels sont les 10 meilleurs algorithmes pour l’apprentissage profond ? Voici les meilleurs algorithmes d’apprentissage profond, à mon avis. Ils occupent tous une position importante en termes d’innovation, de valeur d’application et d’influence. 1. Contexte du réseau neuronal profond (DNN) : Le réseau neuronal profond (DNN), également appelé perceptron multicouche, est l'algorithme d'apprentissage profond le plus courant lorsqu'il a été inventé pour la première fois, jusqu'à récemment en raison du goulot d'étranglement de la puissance de calcul. années, puissance de calcul, La percée est venue avec l'explosion des données. DNN est un modèle de réseau neuronal qui contient plusieurs couches cachées. Dans ce modèle, chaque couche transmet l'entrée à la couche suivante et
 Une étude de cas sur l'utilisation du modèle LSTM bidirectionnel pour la classification de texte
Jan 24, 2024 am 10:36 AM
Une étude de cas sur l'utilisation du modèle LSTM bidirectionnel pour la classification de texte
Jan 24, 2024 am 10:36 AM
Le modèle LSTM bidirectionnel est un réseau neuronal utilisé pour la classification de texte. Vous trouverez ci-dessous un exemple simple montrant comment utiliser le LSTM bidirectionnel pour les tâches de classification de texte. Tout d'abord, nous devons importer les bibliothèques et modules requis : importosimportnumpyasnpfromkeras.preprocessing.textimportTokenizerfromkeras.preprocessing.sequenceimportpad_sequencesfromkeras.modelsimportSequentialfromkeras.layersimportDense,Em
 AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
Editeur | Radis Skin Depuis la sortie du puissant AlphaFold2 en 2021, les scientifiques utilisent des modèles de prédiction de la structure des protéines pour cartographier diverses structures protéiques dans les cellules, découvrir des médicaments et dresser une « carte cosmique » de chaque interaction protéique connue. Tout à l'heure, Google DeepMind a publié le modèle AlphaFold3, capable d'effectuer des prédictions de structure conjointe pour des complexes comprenant des protéines, des acides nucléiques, de petites molécules, des ions et des résidus modifiés. La précision d’AlphaFold3 a été considérablement améliorée par rapport à de nombreux outils dédiés dans le passé (interaction protéine-ligand, interaction protéine-acide nucléique, prédiction anticorps-antigène). Cela montre qu’au sein d’un cadre unique et unifié d’apprentissage profond, il est possible de réaliser
 Comment utiliser les modèles hybrides CNN et Transformer pour améliorer les performances
Jan 24, 2024 am 10:33 AM
Comment utiliser les modèles hybrides CNN et Transformer pour améliorer les performances
Jan 24, 2024 am 10:33 AM
Convolutional Neural Network (CNN) et Transformer sont deux modèles d'apprentissage en profondeur différents qui ont montré d'excellentes performances sur différentes tâches. CNN est principalement utilisé pour les tâches de vision par ordinateur telles que la classification d'images, la détection de cibles et la segmentation d'images. Il extrait les caractéristiques locales de l'image via des opérations de convolution et effectue une réduction de dimensionnalité des caractéristiques et une invariance spatiale via des opérations de pooling. En revanche, Transformer est principalement utilisé pour les tâches de traitement du langage naturel (NLP) telles que la traduction automatique, la classification de texte et la reconnaissance vocale. Il utilise un mécanisme d'auto-attention pour modéliser les dépendances dans des séquences, évitant ainsi le calcul séquentiel dans les réseaux neuronaux récurrents traditionnels. Bien que ces deux modèles soient utilisés pour des tâches différentes, ils présentent des similitudes dans la modélisation des séquences.
 Pipeline d'inférence de modèle de cadre d'apprentissage profond TensorFlow pour l'inférence de découpe de portrait
Mar 26, 2024 pm 01:00 PM
Pipeline d'inférence de modèle de cadre d'apprentissage profond TensorFlow pour l'inférence de découpe de portrait
Mar 26, 2024 pm 01:00 PM
Présentation Afin de permettre aux utilisateurs de ModelScope d'utiliser rapidement et facilement divers modèles fournis par la plateforme, un ensemble de bibliothèques Python entièrement fonctionnelles est fourni, qui comprend la mise en œuvre des modèles officiels de ModelScope, ainsi que les outils nécessaires à l'utilisation de ces modèles à des fins d'inférence. , réglage fin et autres tâches liées au prétraitement des données, au post-traitement, à l'évaluation des effets et à d'autres fonctions, tout en fournissant également une API simple et facile à utiliser et des exemples d'utilisation riches. En appelant la bibliothèque, les utilisateurs peuvent effectuer des tâches telles que l'inférence de modèle, la formation et l'évaluation en écrivant seulement quelques lignes de code. Ils peuvent également effectuer rapidement un développement secondaire sur cette base pour concrétiser leurs propres idées innovantes. Le modèle d'algorithme actuellement fourni par la bibliothèque est :
 Débruitage d'image à l'aide de réseaux de neurones convolutifs
Jan 23, 2024 pm 11:48 PM
Débruitage d'image à l'aide de réseaux de neurones convolutifs
Jan 23, 2024 pm 11:48 PM
Les réseaux de neurones convolutifs fonctionnent bien dans les tâches de débruitage d'images. Il utilise les filtres appris pour filtrer le bruit et restaurer ainsi l'image originale. Cet article présente en détail la méthode de débruitage d'image basée sur un réseau neuronal convolutif. 1. Présentation du réseau neuronal convolutif Le réseau neuronal convolutif est un algorithme d'apprentissage en profondeur qui utilise une combinaison de plusieurs couches convolutives, des couches de regroupement et des couches entièrement connectées pour apprendre et classer les caractéristiques de l'image. Dans la couche convolutive, les caractéristiques locales de l'image sont extraites via des opérations de convolution, capturant ainsi la corrélation spatiale dans l'image. La couche de pooling réduit la quantité de calcul en réduisant la dimension des fonctionnalités et conserve les principales fonctionnalités. La couche entièrement connectée est responsable du mappage des fonctionnalités et des étiquettes apprises pour mettre en œuvre la classification des images ou d'autres tâches. La conception de cette structure de réseau rend les réseaux de neurones convolutifs utiles dans le traitement et la reconnaissance d'images.
