

Principes fondamentaux de la synthèse vocale intelligente

Les méthodes de synthèse vocale paramétrique statistique ont attiré une large attention dans le domaine de la synthèse vocale en raison de leur flexibilité. Ces dernières années, l’application de modèles de réseaux neuronaux profonds dans le domaine de la recherche sur l’apprentissage automatique a permis d’obtenir des avantages significatifs par rapport aux méthodes traditionnelles. L'application de méthodes de modélisation basées sur les réseaux de neurones dans la synthèse vocale paramétrique statistique s'est progressivement approfondie et est devenue l'une des méthodes dominantes de synthèse vocale.
La modélisation acoustique backend pour la synthèse vocale paramétrique statistique fait l'objet de cet article.
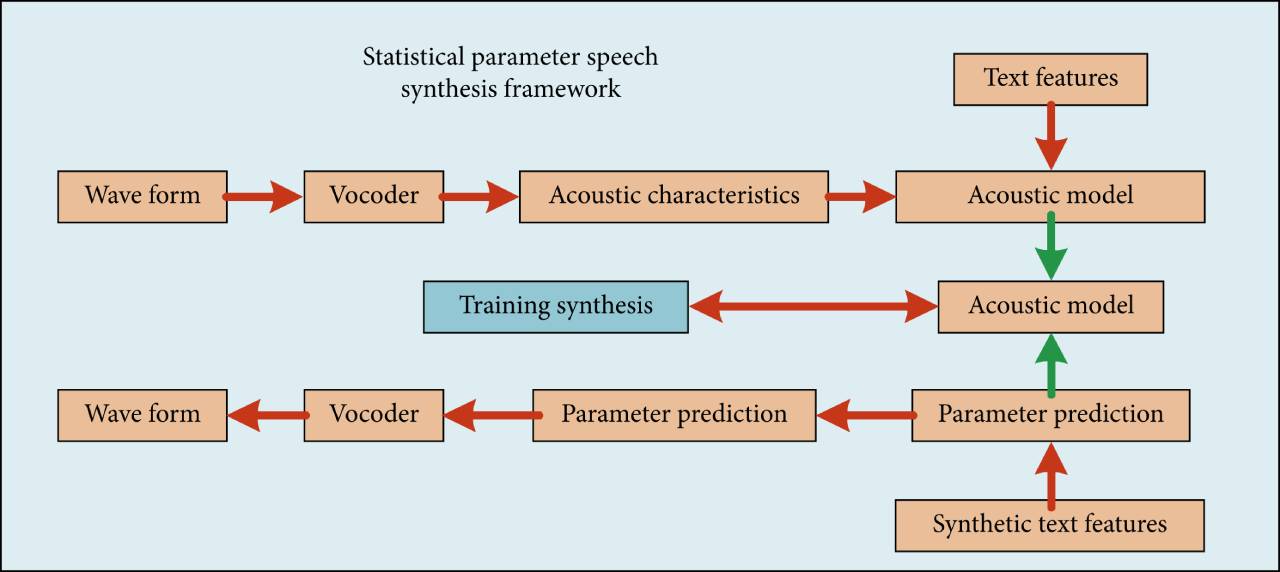
Le cadre backend de la synthèse vocale paramétrique
Comme le montre la figure, le cadre backend de la synthèse vocale paramétrique statistique est décrit, qui comprend principalement deux étapes : la formation et la synthèse.
Dans la phase de formation, les formes d'onde vocales et les caractéristiques textuelles correspondantes de la bibliothèque sonore sont utilisées comme entrée. Les formes d'onde vocales sont extraites via un vocodeur et combinées avec des fonctionnalités de texte pour la modélisation acoustique.
Dans l'étape de synthèse, selon le modèle acoustique entraîné, les caractéristiques du texte à synthétiser sont saisies et les caractéristiques acoustiques correspondantes sont prédites. Les caractéristiques acoustiques prédites sont ensuite converties en formes d'onde vocales à l'aide d'un vocodeur. Le vocodeur et les modèles acoustiques sont des composants clés des systèmes de synthèse vocale paramétrique statistique.
Le modèle de filtre source de génération de parole est utilisé pour séparer le spectre de courte durée de la parole en fréquence fondamentale et enveloppe spectrale pendant le processus de paramétrage de la forme d'onde vocale. Habituellement, nous obtenons les caractéristiques d'excitation de la parole en analysant les formes d'onde du domaine temporel ou les harmoniques du domaine fréquentiel, puis supprimons la périodicité du temps et de la fréquence du spectre d'amplitude obtenu par la transformée de Fourier à court terme de la forme d'onde de la parole pour obtenir l'ensemble spectral de réseau de parole. Cette méthode peut nous aider à mieux comprendre et traiter les signaux vocaux.
En raison de la dimensionnalité plus élevée de l'enveloppe spectrale, la modélisation devient difficile, il est donc souvent nécessaire de réduire la dimensionnalité de l'enveloppe spectrale. La reconstruction de la forme d'onde de la parole est le processus inverse de récupération de la parole originale à partir des paramètres acoustiques de la parole. En tenant compte de la fréquence fondamentale, de l'enveloppe spectrale et des caractéristiques d'excitation de la parole, combinées à des contraintes de phase appropriées, le spectre d'amplitude STFT peut être reconstruit.
La modélisation de la durée est un autre module de synthèse vocale paramétrique statistique. La modélisation de durée ne nécessite pas de vocodeur. Le cadre de base est similaire à la modélisation acoustique. Des modèles statistiques sont utilisés pour modéliser la distribution de probabilité des durées correspondantes en fonction des caractéristiques du texte.
Après plus de 20 ans de développement, la méthode de synthèse vocale à paramètres statistiques basée sur HMM est devenue une méthode de synthèse vocale mature.
Cette section présentera le modèle de Markov caché et ses bases théoriques. Combiné avec certaines contraintes de phase, le spectre d'amplitude STFT est reconstruit. La modélisation de la durée est un autre module de la synthèse vocale paramétrique statistique. La modélisation de durée ne nécessite pas de vocodeur. Le cadre de base est similaire à la modélisation acoustique. Des modèles statistiques sont utilisés pour modéliser la distribution de probabilité des durées correspondantes en fonction des caractéristiques du texte. Après plus de 20 ans de développement, la méthode de synthèse vocale à paramètres statistiques basée sur HMM est devenue une méthode de synthèse vocale mature.
Le modèle de Markov caché est un modèle probabiliste pour la modélisation de séquences, qui consiste en un ensemble de variables d'état cachées et un ensemble de variables d'observation. Le modèle HMM repose sur deux hypothèses.
La variable d'état obéit à la chaîne de Markov du premier ordre ; c'est-à-dire que l'état actuel est uniquement lié à l'état précédent, comme le montre la formule (1).
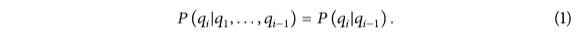
La distribution de probabilité d'une variable observée à un certain moment est uniquement liée à l'état du moment actuel et n'a rien à voir avec l'état ou les variables observées à d'autres moments, comme le montre l'équation (2) .
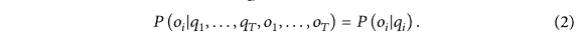
Habituellement, dans le modèle HMM
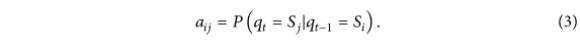
forme intelligemment la matrice de transition d'état A du HMM, et la densité de probabilité des variables observées est :
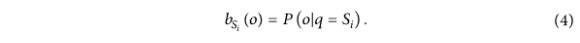
C'est il convient de noter que la probabilité de sortie HMM :
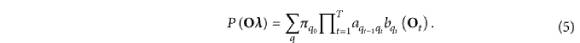
Le principe de base de la modélisation acoustique dans la méthode de synthèse vocale paramétrique statistique basée sur HMM est d'utiliser le modèle HMM pour modéliser de manière probabiliste la séquence de caractéristiques acoustiques de la parole dans une situation donnée. .
La configuration de l'ensemble du système comprend la sélection des caractéristiques acoustiques de la parole, la sélection des unités de modélisation et la configuration des modèles HMM. Les caractéristiques acoustiques des systèmes de synthèse vocale comprennent des caractéristiques d'excitation et des caractéristiques spectrales.
Dans la sélection des caractéristiques spectrales, afin de réduire la difficulté de la modélisation HMM, des représentations spectrales de faible dimension qui suppriment la corrélation entre les dimensions sont généralement utilisées, telles que les caractéristiques de Mel cepstre et de paire de spectre de raies. Compte tenu des caractéristiques stationnaires à court terme des signaux vocaux et de la capacité de modélisation du HM, les HMM dans les systèmes de synthèse vocale modélisent généralement des unités au niveau du phonème, telles que les unités vocaliques en chinois. En raison des caractéristiques temporelles de la parole, la topologie du HMM dans la modélisation audio est souvent un état de parcours unidirectionnel de gauche à droite.
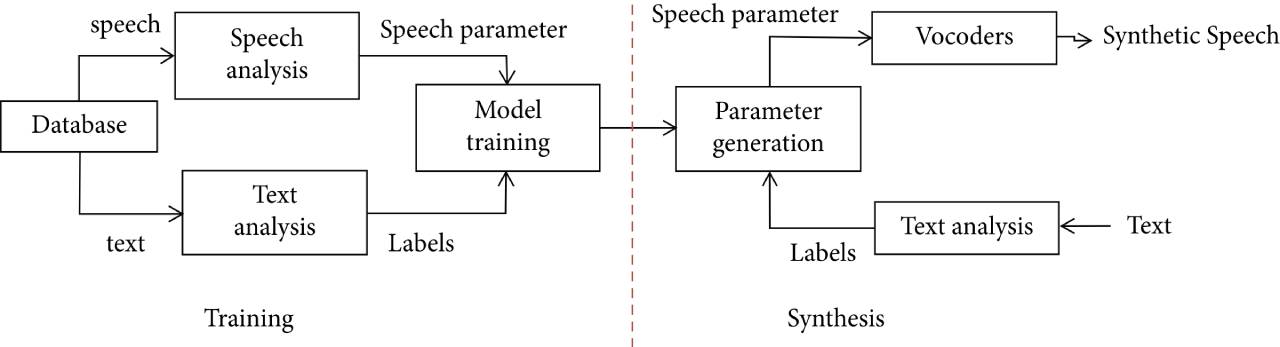
Cadre du système de synthèse vocale à paramètres statistiques basé sur HMM
La figure représente le cadre du système de synthèse vocale à paramètres statistiques basé sur HMM. Il est divisé en étape de formation et étape complète. La phase de formation comprend l'extraction des caractéristiques acoustiques de la parole et la formation du modèle HMM. Étant donné que le modèle HMM utilise des phonèmes comme unités de modélisation, trois phonèmes liés au contexte sont généralement modélisés pour améliorer la précision de la modélisation.
Dans le premier processus de formation du système, la limite inférieure de la variance du modèle HMM est estimée, puis le modèle HMM à tonalité unique est formé comme paramètre d'initialisation du modèle, puis le modèle HMM tri-phone lié au contexte est formé, et enfin le regroupement de pression Mn est effectué sur la base de l'arbre de décision.
Dans l'étape de synthèse, le texte est d'abord analysé, combiné à la durée prévue, la séquence du modèle HMM liée au contexte est déterminée en fonction de l'arbre de décision, puis la séquence de caractéristiques acoustiques continues est obtenue grâce à la génération de paramètres de vraisemblance maximale. Algorithme, et la forme d'onde vocale est synthétisée par le synthétiseur. Les systèmes de synthèse vocale paramétrique statistique basés sur HMM sont trop fluides ; l'une des raisons est la capacité de modélisation limitée de HMM.
Ces dernières années, en tant que branche de l'apprentissage automatique, l'apprentissage profond s'est développé rapidement. L'apprentissage profond fait référence à l'utilisation de modèles de réseau composés de plusieurs transformations non linéaires et de plusieurs couches de traitement, à savoir les réseaux de neurones. En raison des excellentes capacités de modélisation du DNN et du pouce, la méthode de modélisation acoustique basée sur DNN et RNN est appliquée à la synthèse vocale paramétrique statistique, et son effet est meilleur que la méthode de modélisation acoustique basée sur HMM.
C'est désormais devenu la méthode courante de modélisation acoustique par synthèse vocale paramétrique statistique. Les systèmes de synthèse vocale basés sur DNN et RNN sont similaires dans leur structure système.
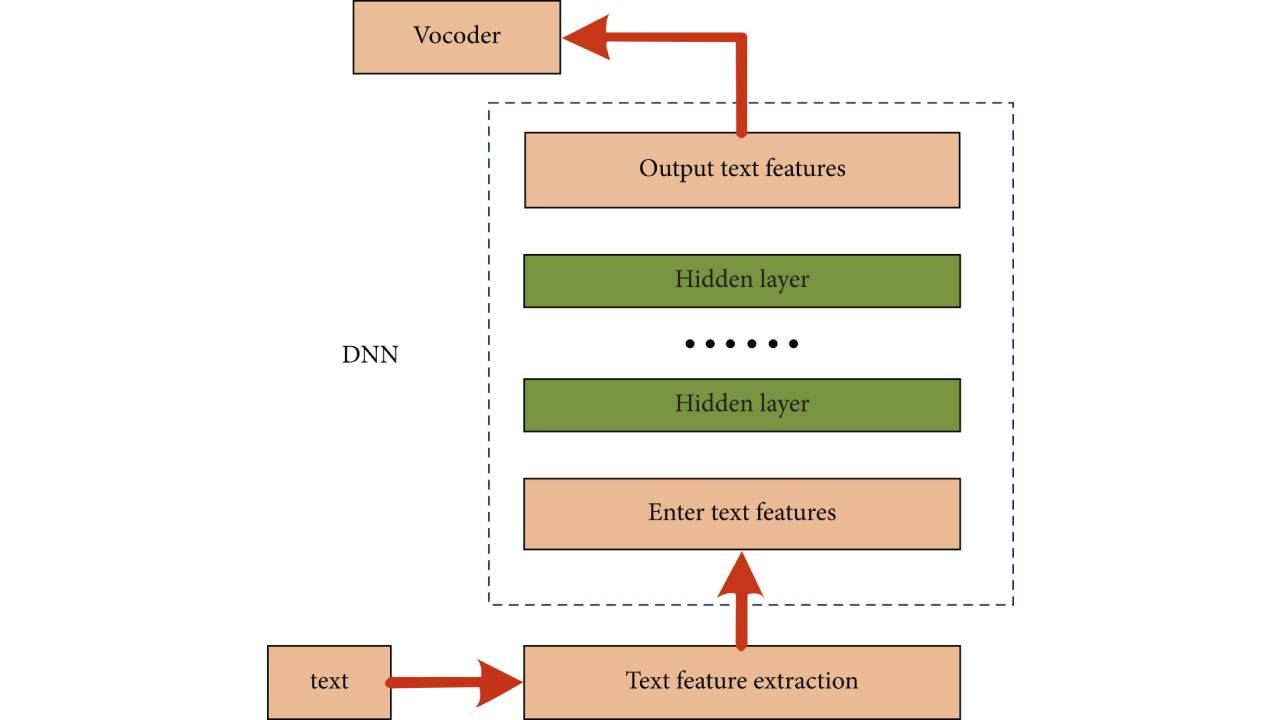
Diagramme cadre d'une méthode de synthèse vocale basée sur un réseau neuronal
Comme le montre la figure, les caractéristiques d'entrée dans la figure sont des caractéristiques extraites du texte, c'est-à-dire que des caractéristiques numériques discrètes ou continues sont utilisées pour décrire le ; texte.
La formation des systèmes de synthèse vocale paramétrique statistique basée sur DNN et RNN adopte généralement des critères de formation et utilise l'algorithme BP et l'algorithme SGD pour mettre à jour les paramètres du modèle afin que les paramètres acoustiques prédits soient aussi proches que possible des paramètres acoustiques naturels. Au cours de l'étape de synthèse, les caractéristiques du texte sont extraites du texte synthétisé, puis les paramètres acoustiques correspondants sont prédits via DNN ou RNN, et enfin la forme d'onde vocale est synthétisée via le vocodeur.
Actuellement, les méthodes de modélisation basées sur DNN et RNN sont principalement appliquées aux paramètres acoustiques de la parole, notamment la fréquence fondamentale et les paramètres spectraux. Les informations sur la durée doivent encore être obtenues via d’autres systèmes. De plus, les fonctionnalités d’entrée et de sortie des modèles DNN et RNN doivent être alignées dans le temps.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
L'annotation d'images est le processus consistant à associer des étiquettes ou des informations descriptives à des images pour donner une signification et une explication plus profondes au contenu de l'image. Ce processus est essentiel à l’apprentissage automatique, qui permet d’entraîner les modèles de vision à identifier plus précisément les éléments individuels des images. En ajoutant des annotations aux images, l'ordinateur peut comprendre la sémantique et le contexte derrière les images, améliorant ainsi la capacité de comprendre et d'analyser le contenu de l'image. L'annotation d'images a un large éventail d'applications, couvrant de nombreux domaines, tels que la vision par ordinateur, le traitement du langage naturel et les modèles de vision graphique. Elle a un large éventail d'applications, telles que l'assistance aux véhicules pour identifier les obstacles sur la route, en aidant à la détection. et le diagnostic des maladies grâce à la reconnaissance d'images médicales. Cet article recommande principalement de meilleurs outils d'annotation d'images open source et gratuits. 1.Makesens
 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
En termes simples, un modèle d’apprentissage automatique est une fonction mathématique qui mappe les données d’entrée à une sortie prédite. Plus précisément, un modèle d'apprentissage automatique est une fonction mathématique qui ajuste les paramètres du modèle en apprenant à partir des données d'entraînement afin de minimiser l'erreur entre la sortie prédite et la véritable étiquette. Il existe de nombreux modèles dans l'apprentissage automatique, tels que les modèles de régression logistique, les modèles d'arbre de décision, les modèles de machines à vecteurs de support, etc. Chaque modèle a ses types de données et ses types de problèmes applicables. Dans le même temps, il existe de nombreux points communs entre les différents modèles, ou il existe une voie cachée pour l’évolution du modèle. En prenant comme exemple le perceptron connexionniste, en augmentant le nombre de couches cachées du perceptron, nous pouvons le transformer en un réseau neuronal profond. Si une fonction noyau est ajoutée au perceptron, elle peut être convertie en SVM. celui-ci
 Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Cet article présentera comment identifier efficacement le surajustement et le sous-apprentissage dans les modèles d'apprentissage automatique grâce à des courbes d'apprentissage. Sous-ajustement et surajustement 1. Surajustement Si un modèle est surentraîné sur les données de sorte qu'il en tire du bruit, alors on dit que le modèle est en surajustement. Un modèle surajusté apprend chaque exemple si parfaitement qu'il classera mal un exemple inédit/inédit. Pour un modèle surajusté, nous obtiendrons un score d'ensemble d'entraînement parfait/presque parfait et un score d'ensemble/test de validation épouvantable. Légèrement modifié : "Cause du surajustement : utilisez un modèle complexe pour résoudre un problème simple et extraire le bruit des données. Parce qu'un petit ensemble de données en tant qu'ensemble d'entraînement peut ne pas représenter la représentation correcte de toutes les données."
 L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
Dans les années 1950, l’intelligence artificielle (IA) est née. C’est à ce moment-là que les chercheurs ont découvert que les machines pouvaient effectuer des tâches similaires à celles des humains, comme penser. Plus tard, dans les années 1960, le Département américain de la Défense a financé l’intelligence artificielle et créé des laboratoires pour poursuivre son développement. Les chercheurs trouvent des applications à l’intelligence artificielle dans de nombreux domaines, comme l’exploration spatiale et la survie dans des environnements extrêmes. L'exploration spatiale est l'étude de l'univers, qui couvre l'ensemble de l'univers au-delà de la terre. L’espace est classé comme environnement extrême car ses conditions sont différentes de celles de la Terre. Pour survivre dans l’espace, de nombreux facteurs doivent être pris en compte et des précautions doivent être prises. Les scientifiques et les chercheurs pensent qu'explorer l'espace et comprendre l'état actuel de tout peut aider à comprendre le fonctionnement de l'univers et à se préparer à d'éventuelles crises environnementales.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
MetaFAIR s'est associé à Harvard pour fournir un nouveau cadre de recherche permettant d'optimiser le biais de données généré lors de l'apprentissage automatique à grande échelle. On sait que la formation de grands modèles de langage prend souvent des mois et utilise des centaines, voire des milliers de GPU. En prenant comme exemple le modèle LLaMA270B, sa formation nécessite un total de 1 720 320 heures GPU. La formation de grands modèles présente des défis systémiques uniques en raison de l’ampleur et de la complexité de ces charges de travail. Récemment, de nombreuses institutions ont signalé une instabilité dans le processus de formation lors de la formation des modèles d'IA générative SOTA. Elles apparaissent généralement sous la forme de pics de pertes. Par exemple, le modèle PaLM de Google a connu jusqu'à 20 pics de pertes au cours du processus de formation. Le biais numérique est à l'origine de cette imprécision de la formation,
