
 Périphériques technologiques
IA
UniVision introduit une nouvelle génération de framework unifié : les doubles tâches de détection BEV et d'occupation atteignent le niveau le plus avancé !
Périphériques technologiques
IA
UniVision introduit une nouvelle génération de framework unifié : les doubles tâches de détection BEV et d'occupation atteignent le niveau le plus avancé !
UniVision introduit une nouvelle génération de framework unifié : les doubles tâches de détection BEV et d'occupation atteignent le niveau le plus avancé !

Écrit devant et compréhension personnelle
Ces dernières années, la perception 3D centrée sur la vision dans la technologie de conduite autonome s'est développée rapidement. Bien que les modèles de perception 3D soient structurellement et conceptuellement similaires, il existe encore des lacunes dans la représentation des caractéristiques, les formats de données et les objectifs, ce qui pose un défi pour concevoir un cadre de perception 3D unifié et efficace. Par conséquent, les chercheurs doivent travailler dur pour combler ces lacunes afin de parvenir à des systèmes de conduite autonome plus précis et plus fiables. Grâce à la collaboration et à l’innovation, nous espérons améliorer encore la sécurité et les performances de la conduite autonome.
Surtout pour les tâches de détection et les tâches d'occupation sous BEV, il est très difficile de réaliser une formation conjointe et d'obtenir de bons résultats. Cela pose de gros problèmes à de nombreuses applications en raison de l'instabilité et des effets difficiles à contrôler. Cependant, UniVision est un framework simple et efficace qui unifie les deux tâches principales de la perception 3D centrée sur la vision, à savoir la prédiction d'occupation et la détection d'objets. Le cœur du framework est un module de transformation de vue explicite-implicite pour une transformation complémentaire de fonctionnalités 2D-3D. En outre, UniVision propose également un module local global d'extraction et de fusion de fonctionnalités pour une extraction, une amélioration et une interaction efficaces et adaptatives des fonctionnalités de voxel et BEV. En adoptant ces méthodes, UniVision est en mesure d'obtenir des résultats satisfaisants dans les tâches de détection et les tâches d'occupation sous BEV.
UniVision propose une stratégie conjointe d'amélioration des données de détection d'occupation et une stratégie d'ajustement progressif de la perte de poids pour améliorer l'efficacité et la stabilité de la formation du cadre multitâche. Des expériences approfondies sont menées sur quatre benchmarks publics, notamment la segmentation lidar sans scène, la détection sans scène, OpenOccupancy et Occ3D. Les résultats expérimentaux montrent qu'UniVision a réalisé des gains de +1,5 mIoU, +1,8 NDS, +1,5 mIoU et +1,8 mIoU respectivement sur chaque benchmark, atteignant le niveau SOTA. Par conséquent, le framework UniVision peut servir de base de référence hautes performances pour les tâches de perception 3D unifiées centrées sur la vision.
État actuel du domaine de la perception 3D
La perception 3D est la tâche principale des systèmes de conduite autonome. Son objectif est d'utiliser les données obtenues à partir d'une série de capteurs (tels que le lidar, le radar et les caméras) pour comprendre de manière globale. la scène de conduite pour la planification de l'utilisation et la prise de décision ultérieures. Dans le passé, le domaine de la perception 3D était dominé par les modèles basés sur le lidar en raison des informations 3D précises dérivées des données des nuages de points. Cependant, les systèmes basés sur lidar sont coûteux, sensibles aux intempéries et peu pratiques à déployer. En revanche, les systèmes basés sur la vision présentent de nombreux avantages, tels qu'un faible coût, un déploiement facile et une bonne évolutivité. Par conséquent, la perception tridimensionnelle centrée sur la vision a attiré l’attention des chercheurs.
Récemment, la détection 3D basée sur la vision a fait des progrès significatifs grâce à une transformation améliorée de la représentation des caractéristiques, à la fusion temporelle et à la conception des signaux de supervision, et l'écart avec les modèles basés sur LiDAR continue de se réduire. En outre, les tâches d'occupation basées sur la vision se sont également développées rapidement ces dernières années. Contrairement à l'utilisation de boîtes 3D pour représenter des objets, l'occupation peut décrire les caractéristiques géométriques et sémantiques de la scène de conduite de manière plus complète et n'est pas limitée par la forme et la catégorie de l'objet.
Bien que les méthodes de détection et les méthodes d'occupation partagent des similitudes structurelles et conceptuelles, les recherches sur la gestion simultanée des deux tâches et l'exploration de leurs interrelations sont insuffisantes. Les modèles d'occupation et les modèles de détection extraient souvent différentes représentations de caractéristiques. La tâche de prédiction d'occupation nécessite des jugements sémantiques et géométriques exhaustifs, c'est pourquoi la représentation voxel est largement utilisée pour préserver les informations 3D à granularité fine. Cependant, dans les tâches de détection, la représentation BEV est préférable puisque la plupart des objets se trouvent sur le même plan horizontal avec un chevauchement plus petit.
Par rapport à la représentation BEV, la représentation voxel est plus fine mais moins efficace. De plus, de nombreux opérateurs avancés sont principalement conçus et optimisés pour les fonctionnalités 2D, ce qui rend leur intégration avec la représentation de voxels 3D pas si simple. La représentation BEV est plus avantageuse en termes d’efficacité temporelle et d’efficacité mémoire, mais elle n’est pas optimale pour la prédiction spatiale dense car les informations structurelles sont perdues dans la dimension hauteur. En plus de la représentation des caractéristiques, les différentes tâches de perception diffèrent également par les formats de données et les objectifs. Par conséquent, assurer l’uniformité et l’efficacité de la formation des cadres de perception 3D multitâches constitue un défi de taille.
Structure du réseau UniVision
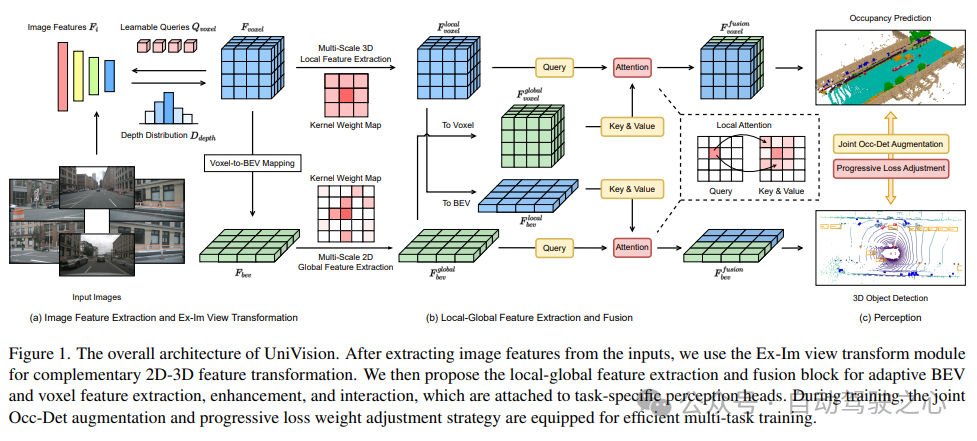
L'architecture globale du framework UniVision est présentée dans la figure 1. Le cadre reçoit des images multi-vues des N caméras environnantes en entrée et extrait les caractéristiques de l'image via un réseau d'extraction de caractéristiques d'image. Ensuite, le module de transformation de vue Ex-Im est utilisé pour convertir les caractéristiques de l'image 2D en caractéristiques de voxel 3D. Ce module combine une amélioration explicite des fonctionnalités guidée en profondeur et un échantillonnage de fonctionnalités implicite guidé par des requêtes. Après la transformation de la vue, les caractéristiques de voxel sont introduites dans le bloc d'extraction et de fusion de caractéristiques globales locales pour extraire respectivement les caractéristiques de voxel locales sensibles au contexte et les fonctionnalités BEV globales sensibles au contexte. Ensuite, des informations sont échangées sur les caractéristiques de voxel et les caractéristiques BEV pour différentes tâches de perception en aval via le module d'interaction des fonctionnalités de représentation croisée. Pendant le processus d'entraînement, le cadre UniVision utilise des stratégies combinées d'amélioration des données Occ-Det et d'ajustement progressif de la perte de poids pour un entraînement efficace. Ces stratégies peuvent améliorer l'effet de formation et la capacité de généralisation du cadre. En bref, le framework UniVision réalise la tâche de détection de l'environnement environnant grâce au traitement d'images multi-vues et de fonctionnalités de voxel 3D, ainsi qu'à l'application de modules d'interaction de fonctionnalités. Dans le même temps, grâce à l'application de stratégies d'amélioration des données et d'ajustement de la perte de poids, l'effet d'entraînement du cadre est efficacement amélioré.
1) Ex-Im View Transform
Amélioration explicite des fonctionnalités guidée en profondeur. L'approche LSS est suivie ici :
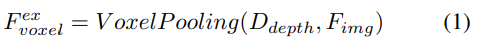
2) Échantillonnage de fonctionnalités implicites guidé par requête. Cependant, la représentation d’informations 3D présente certains inconvénients. La précision de est fortement corrélée à la précision de la distribution de profondeur estimée. De plus, les points générés par LSS ne sont pas répartis uniformément. Les points sont denses à proximité de la caméra et clairsemés à distance. Par conséquent, nous utilisons en outre l’échantillonnage de fonctionnalités guidé par des requêtes pour compenser les lacunes ci-dessus.
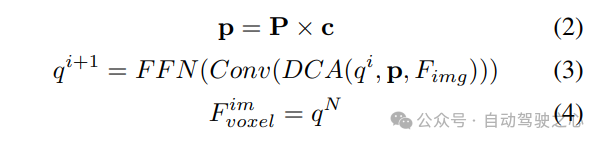
Par rapport aux points générés à partir de LSS, les requêtes voxels sont uniformément distribuées dans l'espace 3D et elles sont apprises à partir des propriétés statistiques de tous les échantillons d'entraînement, ce qui est indépendant de la profondeur des informations préalables utilisées dans LSS. Par conséquent, et se complètent les uns les autres, ils sont connectés en tant que caractéristiques de sortie du module de transformation de vue :
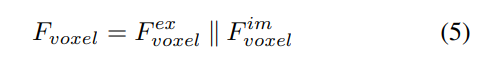
2) Extraction et fusion de caractéristiques globales locales
Étant donné les caractéristiques du voxel d'entrée, superposez d'abord les caractéristiques sur le Z -axis et utilisez des couches convolutives pour réduire les canaux afin d'obtenir les fonctionnalités BEV :
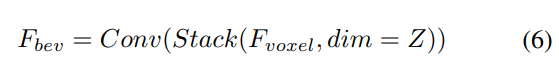
Ensuite, le modèle est divisé en deux branches parallèles pour l'extraction et l'amélioration des fonctionnalités. Extraction de fonctionnalités locales + extraction de fonctionnalités globales et interaction finale des fonctionnalités de représentation croisée ! Comme le montre la figure 1 (b).
3) Fonction de perte et tête de détection
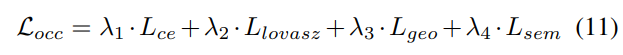
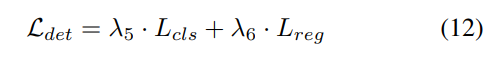
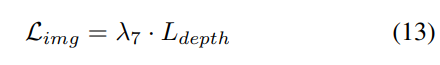
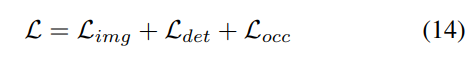
Stratégie d'ajustement progressif du poids de perte. En pratique, il s’avère que l’intégration directe des pertes ci-dessus entraîne souvent l’échec du processus de formation et l’échec de la convergence du réseau. Dans les premiers stades de la formation, les caractéristiques du voxel Fvoxel sont distribuées de manière aléatoire, et la supervision dans la tête d'occupation et la tête de détection contribue moins que les autres pertes de convergence. Dans le même temps, les éléments de perte tels que les pertes de classification Lcls dans la tâche de détection sont très importants et dominent le processus de formation, ce qui rend difficile l'optimisation du modèle. Pour surmonter ce problème, une stratégie d’ajustement progressif du poids perdu est proposée pour ajuster dynamiquement le poids perdu. Plus précisément, le paramètre de contrôle δ est ajouté aux pertes non liées à l'image (c'est-à-dire la perte d'occupation et la perte de détection) pour ajuster le poids de perte à différentes époques d'entraînement. Le poids de contrôle δ est fixé à une petite valeur Vmin au début et augmente progressivement jusqu'à Vmax au cours de N époques d'entraînement :
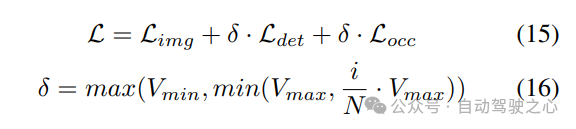
4) Amélioration combinée des données spatiales Occ-Det
Dans les tâches de détection 3D, en plus de l'amélioration courante des données au niveau de l'image, l'amélioration des données au niveau spatial est également efficace pour améliorer les performances du modèle. Cependant, appliquer l’amélioration du niveau spatial aux tâches d’occupation n’est pas simple. Lorsque nous appliquons une augmentation des données (telle qu'une mise à l'échelle et une rotation aléatoires) à des étiquettes d'occupation discrètes, il est difficile de déterminer la sémantique des voxels résultante. Par conséquent, les méthodes existantes n’appliquent qu’une simple augmentation spatiale telle qu’un retournement aléatoire dans les tâches d’occupation.
Pour résoudre ce problème, UniVision propose une augmentation conjointe des données spatiales Occ-Det pour permettre l'amélioration simultanée des tâches de détection 3D et des tâches d'occupation dans le cadre. Étant donné que les étiquettes de boîte 3D sont des valeurs continues et que la boîte 3D améliorée peut être directement calculée pour la formation, la méthode d'amélioration de BEVDet est suivie pour la détection. Bien que les étiquettes d'occupation soient discrètes et difficiles à manipuler, les caractéristiques des voxels peuvent être traitées comme continues et traitées par des opérations telles que l'échantillonnage et l'interpolation. Il est donc recommandé de transformer les caractéristiques des voxels au lieu d'opérer directement sur les étiquettes d'occupation pour augmenter les données.
Plus précisément, l'augmentation des données spatiales est d'abord échantillonnée et la matrice de transformation 3D correspondante est calculée. Pour les étiquettes d'occupation et leurs indices voxels , nous calculons leurs coordonnées tridimensionnelles. Ensuite, il sera appliqué et normalisé pour obtenir les indices de voxel dans les fonctionnalités de voxel améliorées :
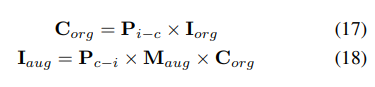
Comparaison des résultats expérimentaux
Utilisation de plusieurs ensembles de données pour la vérification, segmentation NuScenes LiDAR, détection d'objets 3D NuScenes, OpenOccupancy et Occ3D.
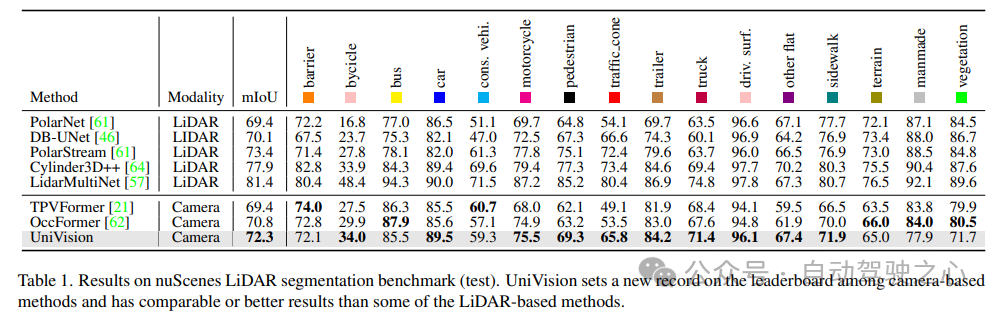
Segmentation LiDAR NuScenes : selon les récents OccFormer et TPVFormer, les images de caméra sont utilisées comme entrée pour la tâche de segmentation lidar, et les données lidar ne sont utilisées que pour fournir des emplacements 3D pour interroger les entités de sortie. Utilisez mIoU comme métrique d’évaluation.
Détection d'objets 3D NuScenes : pour les tâches de détection, utilisez la métrique officielle de nuScenes, le nuScene Detection Score (NDS), qui est la somme pondérée du mAP moyen et de plusieurs métriques, notamment l'erreur de traduction moyenne (ATE), l'erreur d'échelle moyenne ( ASE) ), l'erreur d'orientation moyenne (AOE), l'erreur de vitesse moyenne (AVE) et l'erreur d'attribut moyenne (AAE).
OpenOccupancy : le benchmark OpenOccupancy est basé sur l'ensemble de données nuScenes et fournit des étiquettes d'occupation sémantiques à une résolution de 512 × 512 × 40. Les classes étiquetées sont les mêmes que celles de la tâche de segmentation lidar, en utilisant mIoU comme métrique d'évaluation !
Occ3D : le benchmark Occ3D est basé sur l'ensemble de données nuScenes et fournit des étiquettes d'occupation sémantiques à une résolution de 200×200×16. Occ3D fournit en outre des masques visibles pour la formation et l'évaluation. Les classes étiquetées sont les mêmes que celles de la tâche de segmentation lidar, en utilisant mIoU comme métrique d'évaluation !
1) Segmentation Nuscenes LiDAR
Le tableau 1 montre les résultats du benchmark de segmentation nuScenes LiDAR. UniVision surpasse considérablement la méthode de pointe basée sur la vision OccFormer de 1,5 % mIoU et établit un nouveau record pour les modèles basés sur la vision au classement. Notamment, UniVision surpasse également certains modèles basés sur lidar tels que PolarNe et DB-UNet.
2) Tâche de détection d'objets 3D NuScenes
Comme le montre le tableau 2, UniVision surpasse les autres méthodes lorsqu'il utilise les mêmes paramètres d'entraînement pour une comparaison équitable. Par rapport à BEVDepth à une résolution d’image de 512 × 1 408, UniVision réalise des gains de 2,4 % et 1,1 % respectivement en mAP et NDS. Lorsque le modèle est mis à l'échelle et qu'UniVision est combiné avec une entrée temporelle, il surpasse encore les détecteurs temporels basés sur SOTA par des marges significatives. UniVision y parvient avec une résolution d'entrée plus petite et n'utilise pas CBGS.
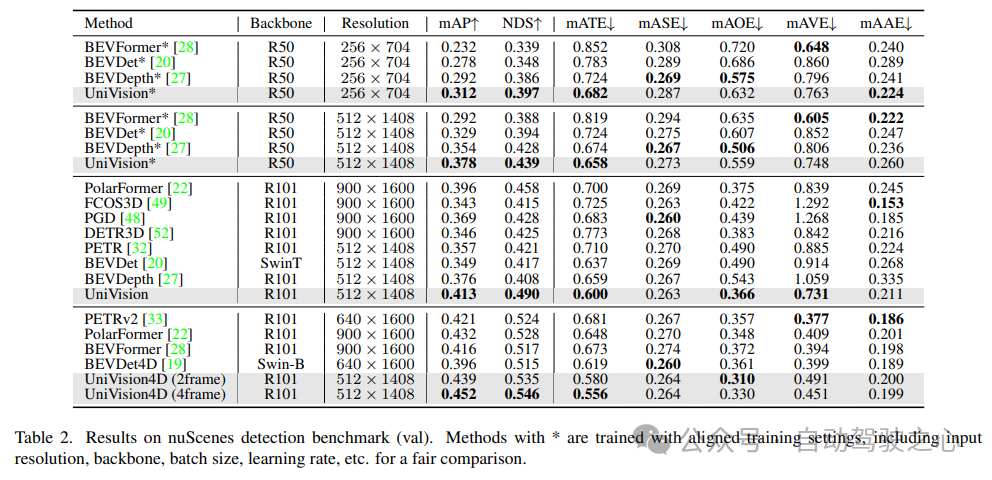
3) Comparaison des résultats d'OpenOccupancy
Les résultats du test de référence OpenOccupancy sont présentés dans le tableau 3. UniVision surpasse considérablement les méthodes récentes d'occupation basées sur la vision, notamment MonoScene, TPVFormer et C-CONet en termes de mIoU de 7,3 %, 6,5 % et 1,5 %, respectivement. De plus, UniVision surpasse certaines méthodes basées sur lidar telles que LMSCNet et JS3C-Net.
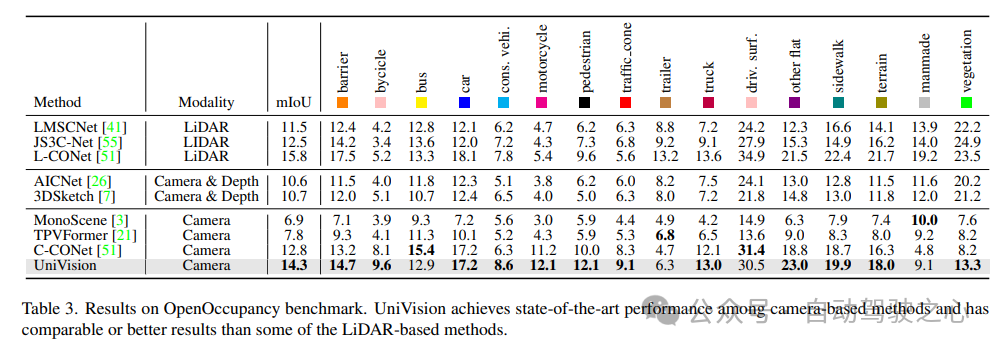
4) Résultats expérimentaux Occ3D
Le tableau 4 répertorie les résultats du benchmark Occ3D. UniVision surpasse considérablement les méthodes récentes basées sur la vision en termes de mIoU sous différentes résolutions d'image d'entrée, de plus de 2,7 % et 1,8 % respectivement. Il convient de noter que BEVFormer et BEVDet-stereo chargent des poids pré-entraînés et utilisent des entrées temporelles dans l'inférence, tandis qu'UniVision ne les utilise pas mais obtient quand même de meilleures performances.
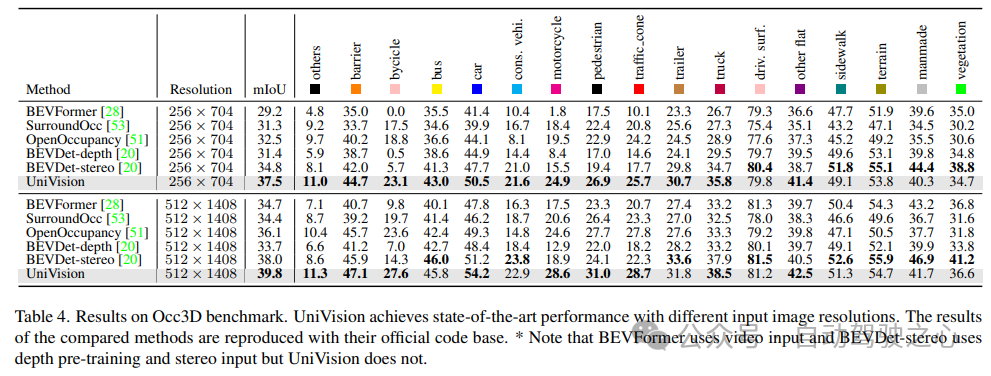
5) Efficacité des composants dans les tâches de détection
L'étude d'ablation des tâches de détection est présentée dans le tableau 5. Lorsque la branche d'extraction de fonctionnalités globale basée sur BEV est insérée dans le modèle de base, les performances s'améliorent de 1,7 % mAP et de 3,0 % NDS. Lorsque la tâche d'occupation basée sur les voxels est ajoutée au détecteur en tant que tâche auxiliaire, le gain mAP du modèle augmente de 1,6 %. Lorsque les interactions de représentation croisée sont explicitement introduites à partir des fonctionnalités de voxel, le modèle obtient les meilleures performances, améliorant respectivement mAP et NDS de 3,5 % et 4,2 % par rapport à la ligne de base.
6) Occupant les composants de la tâche ; de
est présenté dans le tableau 6 pour l'étude d'ablation sur la tâche d'occupation. Le réseau d'extraction de caractéristiques locales basé sur des voxels apporte une amélioration de 1,96 % du gain en mIoU au modèle de base. Lorsque la tâche de détection est introduite comme signal de supervision auxiliaire, les performances du modèle s'améliorent de 0,4 % mIoU.

7) Autres
Le Tableau 5 et le Tableau 6 montrent que dans le cadre UniVision, les tâches de détection et les tâches d'occupation sont complémentaires les unes des autres. Pour les tâches de détection, la supervision de l'occupation peut améliorer les métriques mAP et mATE, indiquant que l'apprentissage sémantique des voxels améliore efficacement la perception par le détecteur de la géométrie de l'objet, c'est-à-dire sa centralité et son échelle. Pour la tâche d'occupation, la supervision de détection améliore considérablement les performances de la catégorie de premier plan (c'est-à-dire la catégorie de détection), ce qui entraîne une amélioration globale.
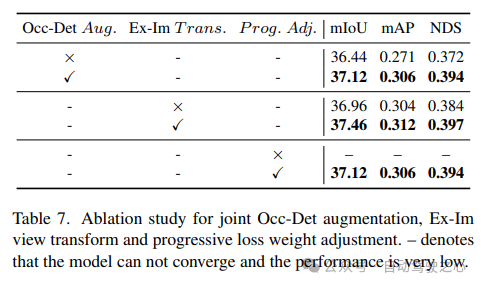
L'efficacité de l'amélioration spatiale combinée Occ-Det, du module de conversion de vue Ex-Im et de la stratégie d'ajustement de perte de poids progressive est démontrée dans le tableau 7. Avec l'augmentation spatiale proposée et le module de transformation de vue proposé, il montre des améliorations significatives dans les tâches de détection et les tâches d'occupation sur les métriques mIoU, mAP et NDS. La stratégie d'ajustement de la perte de poids peut entraîner efficacement le cadre multitâche. Sans cela, la formation du cadre unifié ne peut pas converger et les performances sont très faibles.
Lien original : https://mp.weixin.qq.com/s/8jpS_I-wn1-svR3UlCF7KQ
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
