
 Périphériques technologiques
IA
Google lance ASPIRE, un cadre de formation de modèles qui permet à l'IA de juger de manière indépendante la précision des résultats.
Périphériques technologiques
IA
Google lance ASPIRE, un cadre de formation de modèles qui permet à l'IA de juger de manière indépendante la précision des résultats.
Google lance ASPIRE, un cadre de formation de modèles qui permet à l'IA de juger de manière indépendante la précision des résultats.


Google a récemment publié un communiqué de presse annonçant le lancement du framework de formation ASPIRE, spécialement conçu pour les grands modèles de langage. Ce cadre vise à améliorer les capacités de prédiction sélective des modèles d’IA.
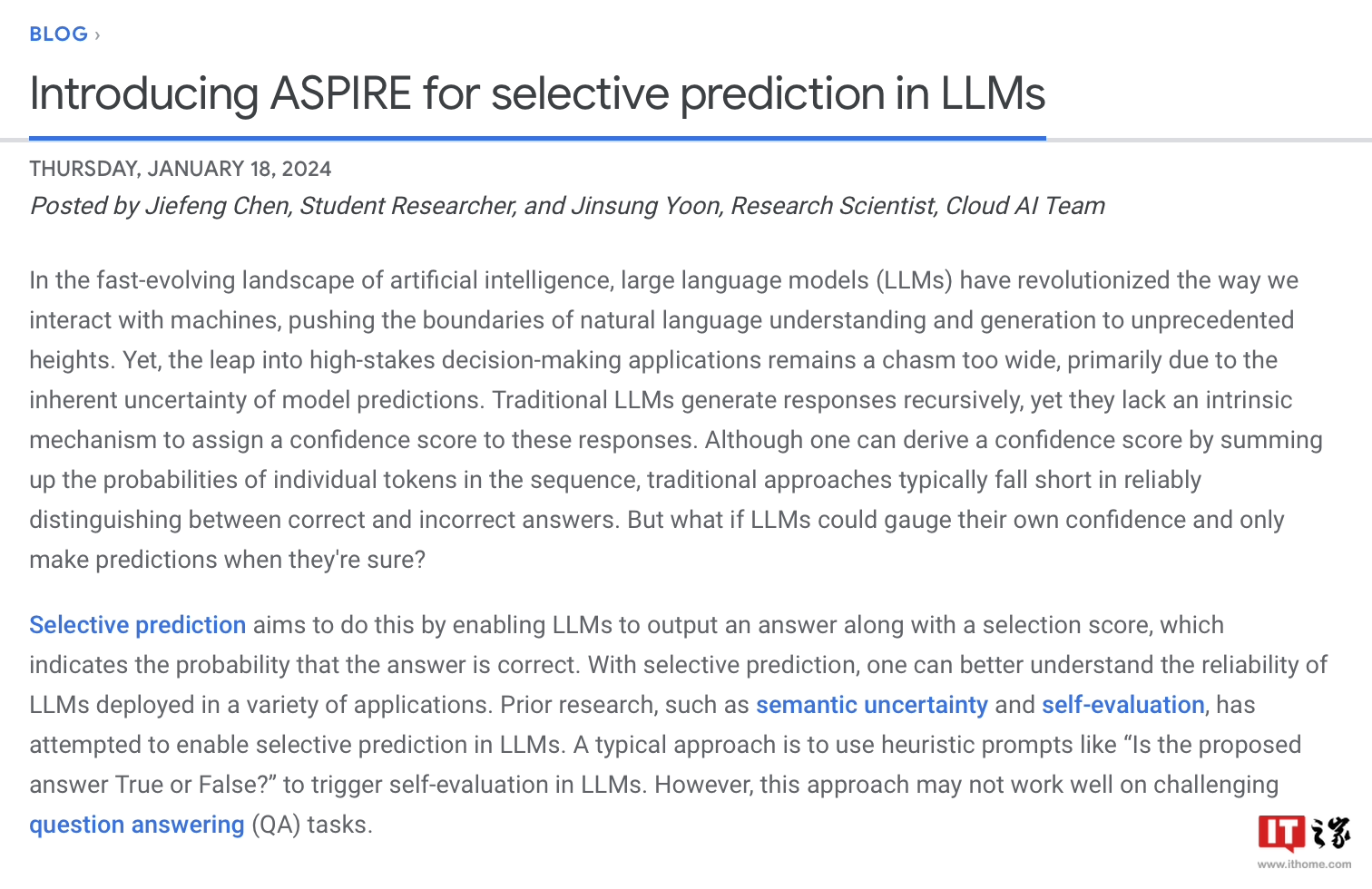
Google a mentionné que les grands modèles de langage se développent rapidement dans la compréhension du langage naturel et la génération de contenu, et ont été utilisés pour créer diverses applications innovantes, mais qu'il est toujours inapproprié de les appliquer à des situations décisionnelles à haut risque. Cela est dû à l'incertitude et à la possibilité d'« hallucinations » dans les prédictions du modèle. Par conséquent, Google a développé un cadre de formation ASPIRE, qui introduit un mécanisme de « crédibilité » dans une série de modèles. , chacune des réponses aura toutes un score de probabilité d'être correcte .
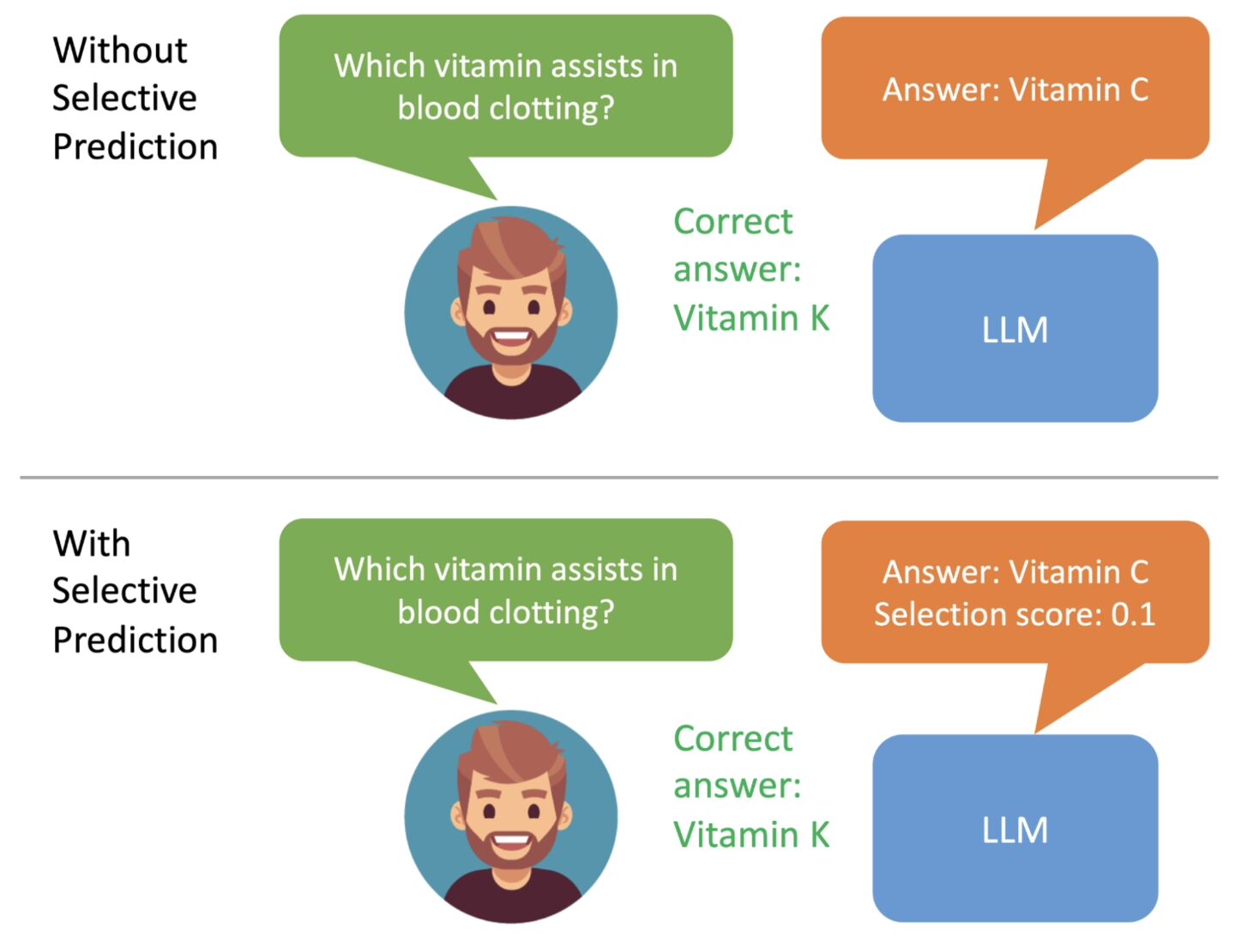
en se concentrant sur le renforcement des capacités de prédiction du modèle. Les chercheurs introduisent principalement une série de paramètres réglables dans le modèle et affinent le modèle de langage pré-entraîné sur l'ensemble de données d'entraînement de tâches spécifiques, améliorant ainsi les performances de prédiction du modèle et permettant au modèle de mieux résoudre des problèmes spécifiques.
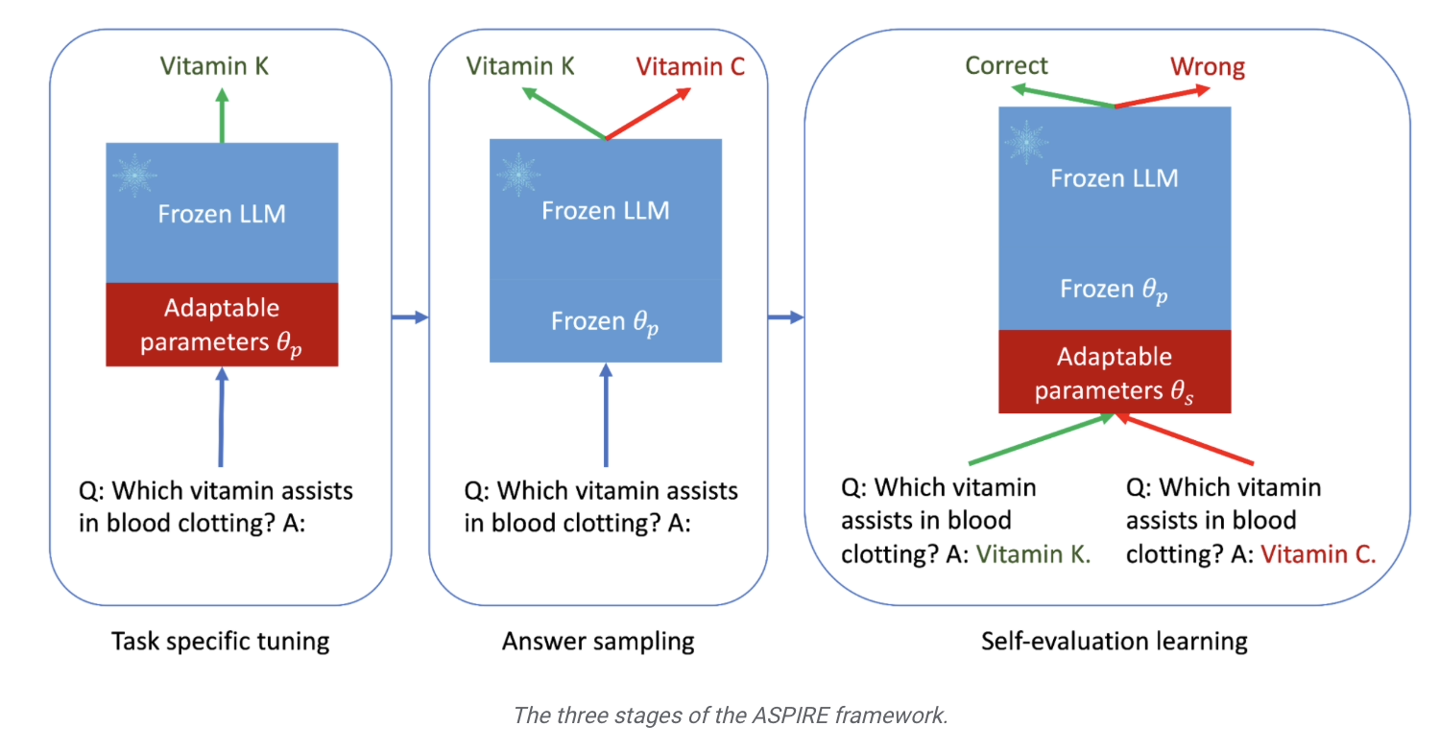
Les chercheurs ont également utilisé la méthode « Beam Search » et l'algorithme Rouge-L pour évaluer la qualité des réponses, et ont réintégré les réponses et les scores générés dans le modèle pour démarrer la troisième étape.
Le but de cette étape est de permettre au modèle d'apprendre à « juger par lui-même l'exactitude de la réponse de sortie », de sorte que lorsque le grand modèle de langage génère la réponse, il attachera également le score de probabilité correct de la réponse.
Les chercheurs de Google ont utilisé trois ensembles de données de questions et réponses, CoQA, TriviaQA et SQuAD, pour vérifier les résultats du cadre de formation ASPIRE. On dit que « le petit modèle OPT-2.7B ajusté par ASPIRE surpasse de loin le plus grand OPT- ». Modèle 30B." Les résultats expérimentaux montrent également qu’avec des ajustements appropriés, même un petit modèle de langage peut surpasser un grand modèle de langage dans certains scénarios.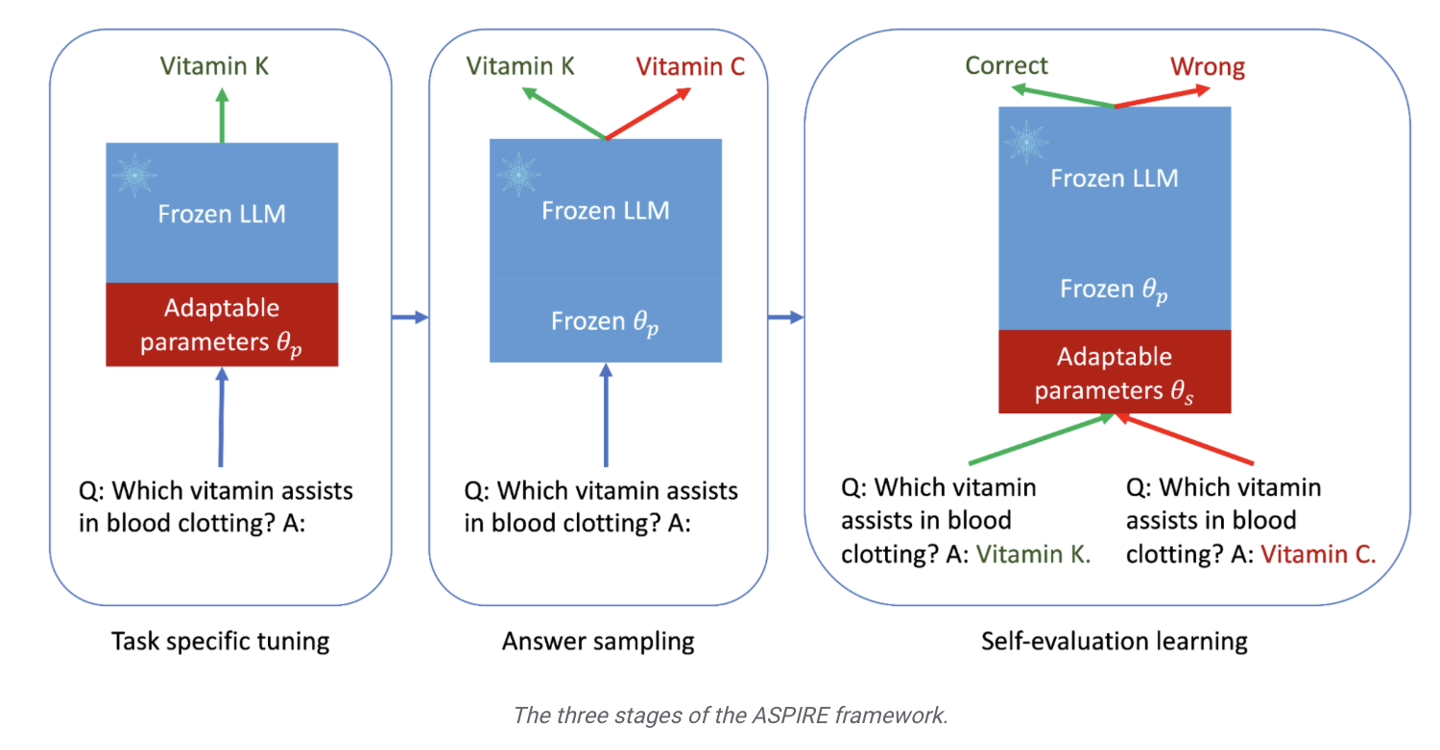
La formation au framework ASPIRE peut améliorer considérablement la précision de sortie des grands modèles de langage, et que même des modèles plus petits peuvent faire des prédictions « précises et sûres » après un réglage fin.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Sony confirme la possibilité d'utiliser des GPU spéciaux sur PS5 Pro pour développer une IA avec AMD
Apr 13, 2025 pm 11:45 PM
Sony confirme la possibilité d'utiliser des GPU spéciaux sur PS5 Pro pour développer une IA avec AMD
Apr 13, 2025 pm 11:45 PM
Mark Cerny, architecte en chef de SonyInterActiveTeretment (SIE, Sony Interactive Entertainment), a publié plus de détails matériels de l'hôte de nouvelle génération PlayStation5Pro (PS5PRO), y compris un GPU AMDRDNA2.x architecture amélioré sur les performances, et un programme d'apprentissage de l'intelligence machine / artificielle "AmethylSt" avec AMD. L'amélioration des performances de PS5PRO est toujours sur trois piliers, y compris un GPU plus puissant, un traçage avancé des rayons et une fonction de super-résolution PSSR alimentée par AI. GPU adopte une architecture AMDRDNA2 personnalisée, que Sony a nommé RDNA2.x, et il a une architecture RDNA3.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Le réglage des performances de Zookeeper sur CentOS peut commencer à partir de plusieurs aspects, notamment la configuration du matériel, l'optimisation du système d'exploitation, le réglage des paramètres de configuration, la surveillance et la maintenance, etc. Assez de mémoire: allouez suffisamment de ressources de mémoire à Zookeeper pour éviter la lecture et l'écriture de disques fréquents. CPU multi-core: utilisez un processeur multi-core pour vous assurer que Zookeeper peut le traiter en parallèle.
 Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Une formation efficace des modèles Pytorch sur les systèmes CentOS nécessite des étapes, et cet article fournira des guides détaillés. 1. Préparation de l'environnement: Installation de Python et de dépendance: le système CentOS préinstalle généralement Python, mais la version peut être plus ancienne. Il est recommandé d'utiliser YUM ou DNF pour installer Python 3 et Mettez PIP: sudoyuMupDatePython3 (ou sudodnfupdatepython3), pip3install-upradepip. CUDA et CUDNN (accélération GPU): Si vous utilisez Nvidiagpu, vous devez installer Cudatool
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Enfin changé! La fonction de recherche Microsoft Windows inaugurera une nouvelle mise à jour
Apr 13, 2025 pm 11:42 PM
Enfin changé! La fonction de recherche Microsoft Windows inaugurera une nouvelle mise à jour
Apr 13, 2025 pm 11:42 PM
Les améliorations de Microsoft aux fonctions de recherche Windows ont été testées sur certains canaux d'initiés Windows dans l'UE. Auparavant, la fonction de recherche Windows intégrée a été critiquée par les utilisateurs et avait une mauvaise expérience. Cette mise à jour divise la fonction de recherche en deux parties: recherche locale et recherche Web basée sur Bing pour améliorer l'expérience utilisateur. La nouvelle version de l'interface de recherche effectue la recherche de fichiers locale par défaut. Si vous devez rechercher en ligne, vous devez cliquer sur l'onglet "Microsoft Bingwebsearch" pour changer. Après le changement, la barre de recherche affichera "Microsoft BingWebsearch:", où les utilisateurs peuvent entrer des mots clés. Ce mouvement évite efficacement le mélange des résultats de recherche locaux avec les résultats de recherche Bing
