
 développement back-end
Tutoriel Python
Résolvez facilement les problèmes de tri des données : guide de tri des pandas simple et facile à comprendre
développement back-end
Tutoriel Python
Résolvez facilement les problèmes de tri des données : guide de tri des pandas simple et facile à comprendre
Résolvez facilement les problèmes de tri des données : guide de tri des pandas simple et facile à comprendre


Tutoriel de tri des pandas simple et facile à comprendre : permet de traiter facilement les problèmes de tri des données, des exemples de code spécifiques sont nécessaires
Dans l'analyse et le traitement des données, il est souvent nécessaire de trier les données afin de mieux comprendre les caractéristiques et les modèles des données. En Python, la bibliothèque pandas est l'un des outils importants pour l'analyse et le traitement des données. Ce didacticiel explique comment utiliser pandas pour trier les données de manière rapide et flexible, et fournit des exemples de code spécifiques.
1. Concepts de base du tri des données
Avant le tri, nous devons comprendre les concepts de base du tri des données. Dans les pandas, il existe deux manières principales de trier les données : le tri par ligne et le tri par colonne.
Trier par ligne : Triez la ligne entière de données en fonction de la valeur d'une ou plusieurs colonnes spécifiques. Cela permet de connaître rapidement le classement d'une ou plusieurs colonnes de données.
Trier par colonne : Triez toute la colonne de données en fonction de la taille numérique. Cela trie les données selon une certaine caractéristique, ce qui les rend plus faciles à comprendre et à analyser.
2. Trier par lignes
1. Trier par colonne unique
Tout d'abord, nous devons créer un ensemble de données simple pour démontrer le processus de tri des données.
import pandas as pd
data = {'姓名': ['张三', '李四', '王五', '赵六'],
'年龄': [25, 32, 28, 19],
'分数': [80, 90, 85, 75]}
df = pd.DataFrame(data)Ensuite, nous pouvons trier les données à l'aide de la fonction "sort_values". Par défaut, cette fonction trie par ordre croissant selon la colonne spécifiée.
df_sorted = df.sort_values(by='年龄') print(df_sorted)
Les résultats courants sont les suivants :
姓名 年龄 分数 3 赵六 19 75 0 张三 25 80 2 王五 28 85 1 李四 32 90
Vous pouvez voir qu'après le tri par la colonne "âge", les données sont triées par ordre croissant.
2. Trier par plusieurs colonnes
Si nous devons trier par plusieurs colonnes, il nous suffit de transmettre plusieurs noms de colonnes dans le paramètre "par".
df_sorted = df.sort_values(by=['年龄', '分数']) print(df_sorted)
Les résultats en cours sont les suivants :
姓名 年龄 分数 3 赵六 19 75 0 张三 25 80 2 王五 28 85 1 李四 32 90
Vous pouvez voir que les données sont d'abord triées par la colonne "âge", puis triées par la colonne "score".
3. Trier par colonne
Le tri par colonne consiste principalement à trier la colonne entière de données en fonction de la taille numérique afin de mieux comprendre et analyser les données.
1. Trier par nom de colonne
Nous pouvons utiliser la fonction "sort_index" pour trier les colonnes. Par défaut, cette fonction trie par ordre alphabétique par nom de colonne.
df_sorted = df.sort_index(axis=1) print(df_sorted)
Les résultats en cours d'exécution sont les suivants :
分数 年龄 姓名 0 80 25 张三 1 90 32 李四 2 85 28 王五 3 75 19 赵六
Vous pouvez voir que les données sont triées par ordre alphabétique selon les noms de colonnes "Score", "Âge" et "Nom".
2. Trier par données de colonne
Nous pouvons également trier en fonction de la taille des données de colonne, il suffit de transmettre les données de colonne dans le paramètre "par".
df_sorted = df.sort_values(by='年龄', axis=1) print(df_sorted)
Les résultats d'exécution sont les suivants :
姓名 分数 年龄 0 张三 80 25 1 李四 90 32 2 王五 85 28 3 赵六 75 19
Vous pouvez voir que les données sont d'abord triées par la colonne "âge", puis triées par les données de la colonne correspondante.
4. Autres paramètres de tri
En plus de la méthode de tri de base, pandas fournit également d'autres paramètres de tri utiles, tels que le tri ascendant, le tri décroissant, le traitement des valeurs manquantes, etc.
Dans la fonction "sort_values", nous pouvons utiliser le paramètre "ascending" pour spécifier un tri croissant ou décroissant. Par défaut, ce paramètre est "True", qui trie par ordre croissant.
df_sorted = df.sort_values(by='年龄', ascending=False) print(df_sorted)
Les résultats en cours d'exécution sont les suivants :
姓名 年龄 分数 1 李四 32 90 2 王五 28 85 0 张三 25 80 3 赵六 19 75
Vous pouvez voir que les données sont triées par ordre décroissant selon la colonne "âge".
En plus du tri ascendant et décroissant, nous pouvons également gérer les valeurs manquantes lors du processus de tri. Dans la fonction "sort_values", nous pouvons utiliser le paramètre "na_position" pour spécifier comment les valeurs manquantes sont gérées. Par défaut, ce paramètre est "last", qui trie les valeurs manquantes en dernier ; lorsque ce paramètre est défini sur "first", il trie les valeurs manquantes en premier.
data = {'姓名': ['张三', '李四', '王五', None],
'年龄': [25, None, 28, 19],
'分数': [80, 90, 85, 75]}
df = pd.DataFrame(data)
df_sorted = df.sort_values(by='年龄', na_position='first')
print(df_sorted)Les résultats en cours d'exécution sont les suivants :
姓名 年龄 分数 1 李四 NaN 90 3 None 19.0 75 0 张三 25.0 80 2 王五 28.0 85
Vous pouvez voir que lors du tri par la colonne "âge", les valeurs manquantes sont placées en premier.
Pour résumer, ce tutoriel présente un tutoriel de tri de pandas simple et facile à comprendre, comprenant le tri par ligne et le tri par colonne, et fournit des exemples de code spécifiques. En étudiant ce didacticiel, je pense que vous pouvez facilement résoudre les problèmes de tri des données et l'utiliser de manière flexible dans l'analyse et le traitement des données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Tutoriel sur l'utilisation de Dewu
Mar 21, 2024 pm 01:40 PM
Tutoriel sur l'utilisation de Dewu
Mar 21, 2024 pm 01:40 PM
Dewu APP est actuellement un logiciel d'achat de marque très populaire, mais la plupart des utilisateurs ne savent pas comment utiliser les fonctions de Dewu APP. Le guide didacticiel d'utilisation le plus détaillé est compilé ci-dessous. Ensuite, l'éditeur présente Dewuduo aux utilisateurs. tutoriels. Les utilisateurs intéressés peuvent venir y jeter un oeil ! Tutoriel sur l'utilisation de Dewu [2024-03-20] Comment utiliser l'achat à tempérament Dewu [2024-03-20] Comment obtenir des coupons Dewu [2024-03-20] Comment trouver le service client manuel Dewu [2024-03- 20] Comment vérifier le code de ramassage de Dewu [2024-03-20] Où trouver l'achat de Dewu [2024-03-20] Comment ouvrir Dewu VIP [2024-03-20] Comment demander le retour ou l'échange de Dewu
 En été, vous devez essayer de photographier un arc-en-ciel
Jul 21, 2024 pm 05:16 PM
En été, vous devez essayer de photographier un arc-en-ciel
Jul 21, 2024 pm 05:16 PM
Après la pluie en été, vous pouvez souvent voir une scène météorologique spéciale magnifique et magique : l'arc-en-ciel. C’est aussi une scène rare que l’on peut rencontrer en photographie, et elle est très photogénique. Il y a plusieurs conditions pour qu’un arc-en-ciel apparaisse : premièrement, il y a suffisamment de gouttelettes d’eau dans l’air, et deuxièmement, le soleil brille sous un angle plus faible. Par conséquent, il est plus facile de voir un arc-en-ciel l’après-midi, après que la pluie s’est dissipée. Cependant, la formation d'un arc-en-ciel est grandement affectée par les conditions météorologiques, la lumière et d'autres conditions, de sorte qu'il ne dure généralement que peu de temps, et la meilleure durée d'observation et de prise de vue est encore plus courte. Alors, lorsque vous rencontrez un arc-en-ciel, comment pouvez-vous l'enregistrer correctement et prendre des photos de qualité ? 1. Recherchez les arcs-en-ciel En plus des conditions mentionnées ci-dessus, les arcs-en-ciel apparaissent généralement dans la direction de la lumière du soleil, c'est-à-dire que si le soleil brille d'ouest en est, les arcs-en-ciel sont plus susceptibles d'apparaître à l'est.
 Tutoriel sur la façon de désactiver le son de paiement sur WeChat
Mar 26, 2024 am 08:30 AM
Tutoriel sur la façon de désactiver le son de paiement sur WeChat
Mar 26, 2024 am 08:30 AM
1. Ouvrez d’abord WeChat. 2. Cliquez sur [+] dans le coin supérieur droit. 3. Cliquez sur le code QR pour collecter le paiement. 4. Cliquez sur les trois petits points dans le coin supérieur droit. 5. Cliquez pour fermer le rappel vocal de l'arrivée du paiement.
 Quel logiciel est Photoshop5 ? -tutoriel d'utilisation de Photoshopcs5
Mar 19, 2024 am 09:04 AM
Quel logiciel est Photoshop5 ? -tutoriel d'utilisation de Photoshopcs5
Mar 19, 2024 am 09:04 AM
PhotoshopCS est l'abréviation de Photoshop Creative Suite. C'est un logiciel produit par Adobe et est largement utilisé dans la conception graphique et le traitement d'images. En tant que novice apprenant PS, laissez-moi vous expliquer aujourd'hui ce qu'est le logiciel photoshopcs5 et comment l'utiliser. 1. Qu'est-ce que Photoshop CS5 ? Adobe Photoshop CS5 Extended est idéal pour les professionnels des domaines du cinéma, de la vidéo et du multimédia, les graphistes et web designers qui utilisent la 3D et l'animation, ainsi que les professionnels des domaines de l'ingénierie et des sciences. Rendu une image 3D et fusionnez-la dans une image composite 2D. Modifiez facilement des vidéos
 Les experts vous apprennent ! La bonne façon de couper de longues images sur les téléphones mobiles Huawei
Mar 22, 2024 pm 12:21 PM
Les experts vous apprennent ! La bonne façon de couper de longues images sur les téléphones mobiles Huawei
Mar 22, 2024 pm 12:21 PM
Avec le développement continu des téléphones intelligents, les fonctions des téléphones mobiles sont devenues de plus en plus puissantes, parmi lesquelles la fonction de prise de photos longues est devenue l'une des fonctions importantes utilisées par de nombreux utilisateurs dans la vie quotidienne. De longues captures d'écran peuvent aider les utilisateurs à enregistrer une longue page Web, un enregistrement de conversation ou une image en même temps pour une visualisation et un partage faciles. Parmi les nombreuses marques de téléphones mobiles, les téléphones mobiles Huawei sont également l'une des marques les plus respectées par les utilisateurs, et leur fonction de recadrage de longues images est également très appréciée. Cet article vous présentera la bonne méthode pour prendre de longues photos sur les téléphones mobiles Huawei, ainsi que quelques conseils d'experts pour vous aider à mieux utiliser les téléphones mobiles Huawei.
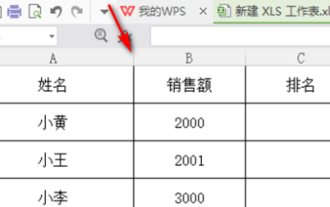 Comment trier les scores WPS
Mar 20, 2024 am 11:28 AM
Comment trier les scores WPS
Mar 20, 2024 am 11:28 AM
Dans notre travail, nous utilisons souvent le logiciel wps. Il existe de nombreuses façons de traiter les données dans le logiciel wps, et les fonctions sont également très puissantes. Nous utilisons souvent des fonctions pour trouver des moyennes, des résumés, etc. des méthodes qui peuvent être utilisées pour les données statistiques ont été préparées pour tout le monde dans la bibliothèque du logiciel WPS. Ci-dessous, nous présenterons les étapes à suivre pour trier les scores dans WPS. Après avoir lu ceci, vous pourrez tirer les leçons de cette expérience. 1. Ouvrez d’abord le tableau qui doit être classé. Comme indiqué ci-dessous. 2. Entrez ensuite la formule =rank(B2, B2 : B5, 0) et assurez-vous de saisir 0. Comme indiqué ci-dessous. 3. Après avoir saisi la formule, appuyez sur la touche F4 du clavier de l'ordinateur. Cette étape consiste à changer la référence relative en référence absolue.
 Tutoriel PHP : Comment convertir un type int en chaîne
Mar 27, 2024 pm 06:03 PM
Tutoriel PHP : Comment convertir un type int en chaîne
Mar 27, 2024 pm 06:03 PM
Tutoriel PHP : Comment convertir un type Int en chaîne En PHP, la conversion de données entières en chaîne est une opération courante. Ce didacticiel expliquera comment utiliser les fonctions intégrées de PHP pour convertir le type int en chaîne, tout en fournissant des exemples de code spécifiques. Utiliser cast : En PHP, vous pouvez utiliser cast pour convertir des données entières en chaîne. Cette méthode est très simple. Il vous suffit d'ajouter (string) avant les données entières pour les convertir en chaîne. Vous trouverez ci-dessous un exemple de code simple
 Honorez le didacticiel de mise à niveau du système du téléphone mobile Hongmeng
Mar 23, 2024 pm 12:45 PM
Honorez le didacticiel de mise à niveau du système du téléphone mobile Hongmeng
Mar 23, 2024 pm 12:45 PM
Les téléphones mobiles Honor ont toujours été favorisés par les consommateurs en raison de leurs excellentes performances et de leur système stable. Récemment, les téléphones mobiles Honor ont lancé un nouveau système Hongmeng, qui a attiré l'attention et les attentes de nombreux utilisateurs. Le système Hongmeng est connu comme le système qui « unifie le monde ». Il offre une expérience de fonctionnement plus fluide et une sécurité plus élevée, permettant aux utilisateurs de découvrir un tout nouveau monde de smartphones. De nombreux utilisateurs ont exprimé leur souhait de mettre à niveau leur système de téléphonie mobile Honor vers le système Hongmeng. Jetons donc un coup d'œil au didacticiel de mise à niveau du système Hongmeng du téléphone mobile Honor. premièrement, je
