
 Périphériques technologiques
IA
Transformateur simple et efficace (moteur d'inférence en ligne de très grand modèle de NetEase)
Périphériques technologiques
IA
Transformateur simple et efficace (moteur d'inférence en ligne de très grand modèle de NetEase)
Transformateur simple et efficace (moteur d'inférence en ligne de très grand modèle de NetEase)
Jan 24, 2024 am 10:45 AM
Le cadre d'accélération d'inférence open source de NetEase pour les modèles basés sur des transformateurs prend en charge l'inférence hautes performances sur une seule carte de dizaines de milliards de modèles sur l'architecture Ampere de milieu à bas de gamme.
Contexte du projet
Les modèles à grande échelle basés sur des transformateurs se sont révélés efficaces dans diverses tâches dans de nombreux domaines. Cependant, son application à la production industrielle nécessite des efforts considérables pour réduire le coût d’inférence. Pour combler cette lacune, nous proposons une solution d'inférence évolutive : Easy and Efficient Transformer (EET). EET est un système qui comprend une série d'optimisations de raisonnement Transformer aux niveaux de l'algorithme et de la mise en œuvre. En optimisant les processus de calcul et de données de Transformer, EET peut réduire considérablement le coût d'inférence et améliorer l'efficacité et les performances du modèle. Nos résultats expérimentaux montrent que l'EET peut améliorer considérablement la vitesse d'inférence et l'utilisation des ressources sans perdre en précision du modèle, offrant ainsi une solution simple et efficace pour les applications de modèles à grande échelle dans la production industrielle.
Tout d'abord, nous avons conçu un noyau hautement optimisé pour les entrées longues et les grandes tailles cachées.
De plus, nous proposons également un gestionnaire de mémoire CUDA flexible pour réduire l'empreinte mémoire lors du déploiement de grands modèles. Par rapport à la bibliothèque d'inférence Transformer de pointe (Faster Transformer v4.0), EET est capable d'atteindre une accélération moyenne de la couche de décodage de 1,40 à 4,20x sur le GPU A100.
Adresse papier
https://arxiv.org/abs/2104.12470
Adresse Github
https://github.com/NetEase-FuXi/EET
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Article chaud

Outils chauds Tags

Article chaud

Tags d'article chaud

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Qu'est-ce que le protocole de contexte modèle (MCP)?
Mar 03, 2025 pm 07:09 PM
Qu'est-ce que le protocole de contexte modèle (MCP)?
Mar 03, 2025 pm 07:09 PM
Qu'est-ce que le protocole de contexte modèle (MCP)?
 Construire un agent de vision local utilisant omniparser v2 et omnitool
Mar 03, 2025 pm 07:08 PM
Construire un agent de vision local utilisant omniparser v2 et omnitool
Mar 03, 2025 pm 07:08 PM
Construire un agent de vision local utilisant omniparser v2 et omnitool
 J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
Mar 20, 2025 pm 03:34 PM
J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
Mar 20, 2025 pm 03:34 PM
J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
 Replit Agent: un guide avec des exemples pratiques
Mar 04, 2025 am 10:52 AM
Replit Agent: un guide avec des exemples pratiques
Mar 04, 2025 am 10:52 AM
Replit Agent: un guide avec des exemples pratiques
 Guide de la piste ACT-ONE: Je me suis filmé pour le tester
Mar 03, 2025 am 09:42 AM
Guide de la piste ACT-ONE: Je me suis filmé pour le tester
Mar 03, 2025 am 09:42 AM
Guide de la piste ACT-ONE: Je me suis filmé pour le tester
 5 invites Grok 3 qui peuvent faciliter votre travail
Mar 04, 2025 am 10:54 AM
5 invites Grok 3 qui peuvent faciliter votre travail
Mar 04, 2025 am 10:54 AM
5 invites Grok 3 qui peuvent faciliter votre travail
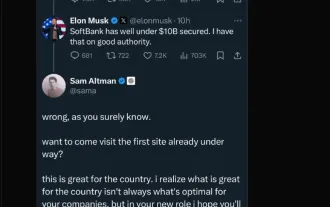 Elon Musk et Sam Altman s'affrontent plus de 500 milliards de dollars Stargate Project
Mar 08, 2025 am 11:15 AM
Elon Musk et Sam Altman s'affrontent plus de 500 milliards de dollars Stargate Project
Mar 08, 2025 am 11:15 AM
Elon Musk et Sam Altman s'affrontent plus de 500 milliards de dollars Stargate Project
 Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
