

Pika Peking University et Stanford s'associent pour open sourcele dernier framework de génération/édition de texte-image !
Sans formation supplémentaire, le modèle de diffusion peut avoir de plus grandes capacités de compréhension rapide des mots.
Face à des mots d'invite longs et complexes, la précision est plus élevée, les détails sont mieux contrôlés et les images générées sont plus naturelles.
L'effet surpasse les modèles de génération d'images les plus puissants Dall·E 3 et SDXL.
Par exemple, l'image doit avoir deux couches de glace et de feu à gauche et à droite, avec des icebergs à gauche et des volcans à droite.
SDXL ne répondait pas du tout aux exigences en matière de mots d'invite et Dall·E 3 n'a pas généré les détails du volcan.

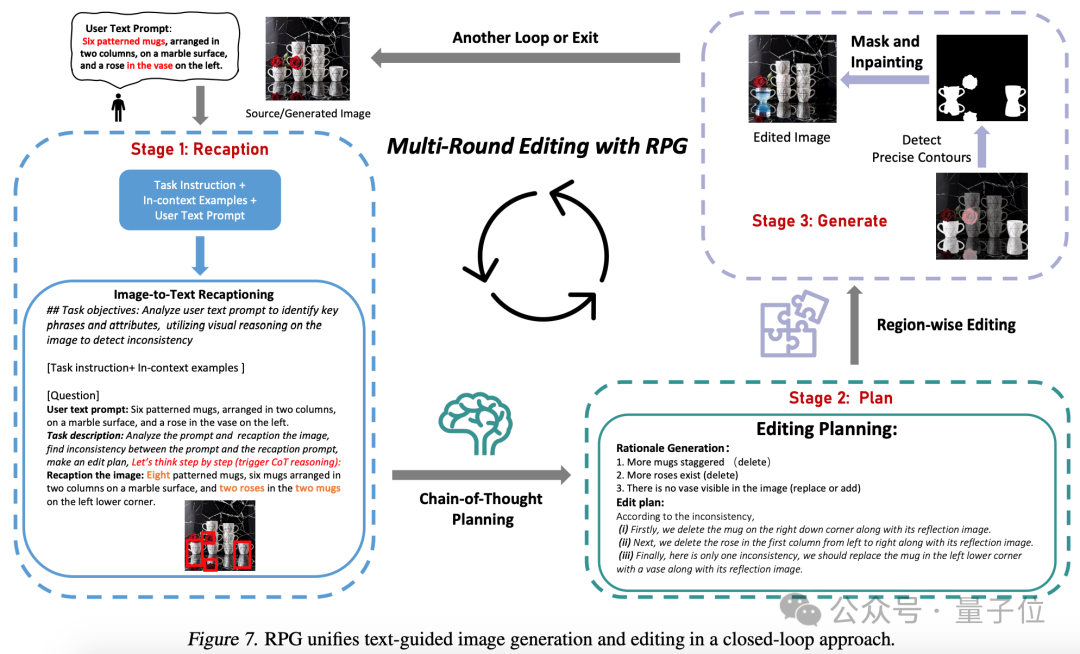
Vous pouvez également générer des modifications secondaires d'images via des paires de mots rapides.
Il s'agit du cadre de génération/édition de texte-image RPG (Recaption, Plan and Generate), qui a suscité de vives discussions sur Internet.

Il est développé conjointement par l'Université de Pékin, Stanford et Pika. Parmi les auteurs figurent le professeur Cui Bin de l'École d'informatique de l'Université de Pékin, Chenlin Meng, co-fondateur et CTO de Pika, etc.
Le code-cadre actuel est open source et est compatible avec divers grands modèles multimodaux (tels que MiniGPT-4) et réseaux fédérateurs de modèles de diffusion (tels que ControlNet).
Pendant longtemps, les modèles de diffusion ont été relativement faibles dans la compréhension des mots d'invite complexes.
Certaines méthodes d'amélioration existantes soit n'aboutissent pas au final à des résultats assez bons, soit nécessitent une formation supplémentaire.
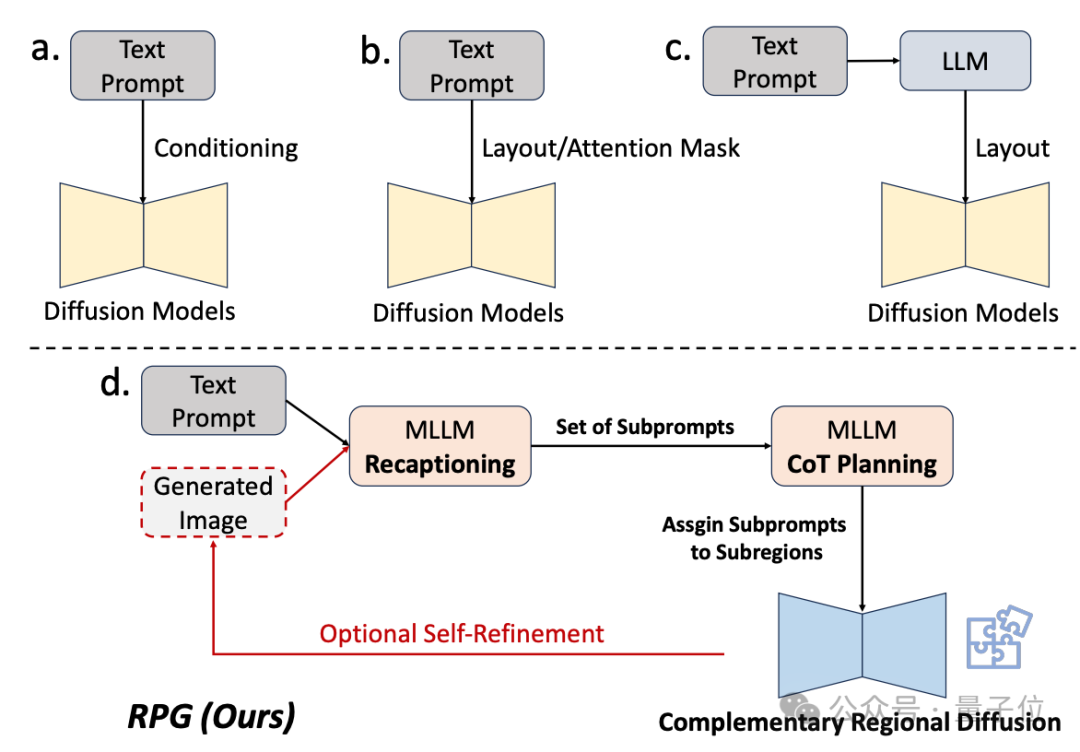
Par conséquent, l'équipe de recherche utilise la capacité de compréhension des grands modèles multimodaux pour améliorer la combinaison et la contrôlabilité du modèle de diffusion.
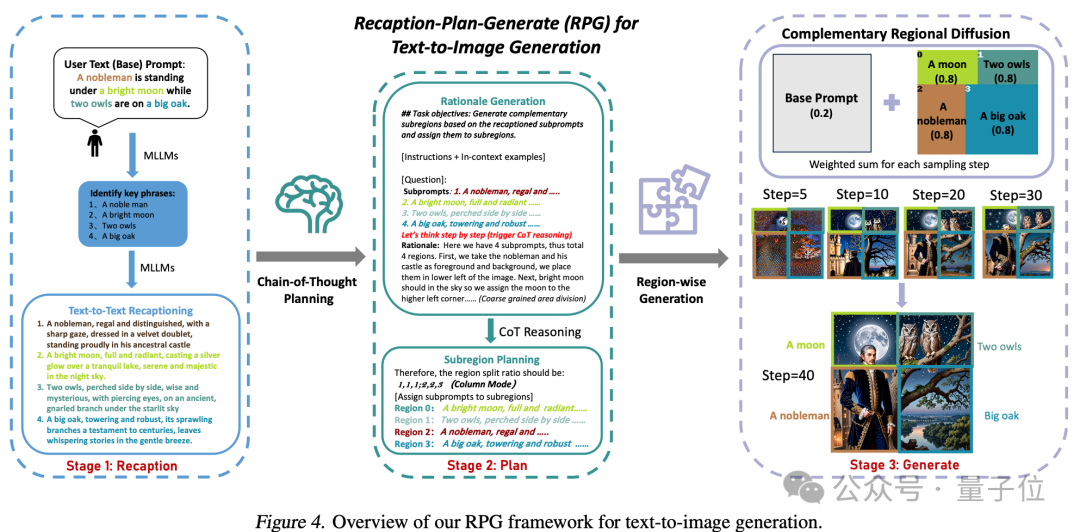
Comme le montre le nom du framework, il permet au modèle de « redécrire, planifier et générer ».
La stratégie de base de cette méthode comporte trois aspects :
1. Récapitulation multimodale : utilisez un grand modèle pour décomposer les invites textuelles complexes en plusieurs sous-invites et mettez à jour chaque sous-invite pour l'améliorer. la capacité du modèle de diffusion à comprendre les mots d'invite.
2. Planification de la chaîne de pensée (Planification de la chaîne de pensée) : utiliser les capacités de raisonnement en chaîne de pensée des grands modèles multimodaux pour diviser l'espace de l'image en sous-régions complémentaires et faire correspondre différentes sous-régions. -des invites pour chaque sous-région, décomposent les tâches de génération complexes en plusieurs tâches de génération plus simples.

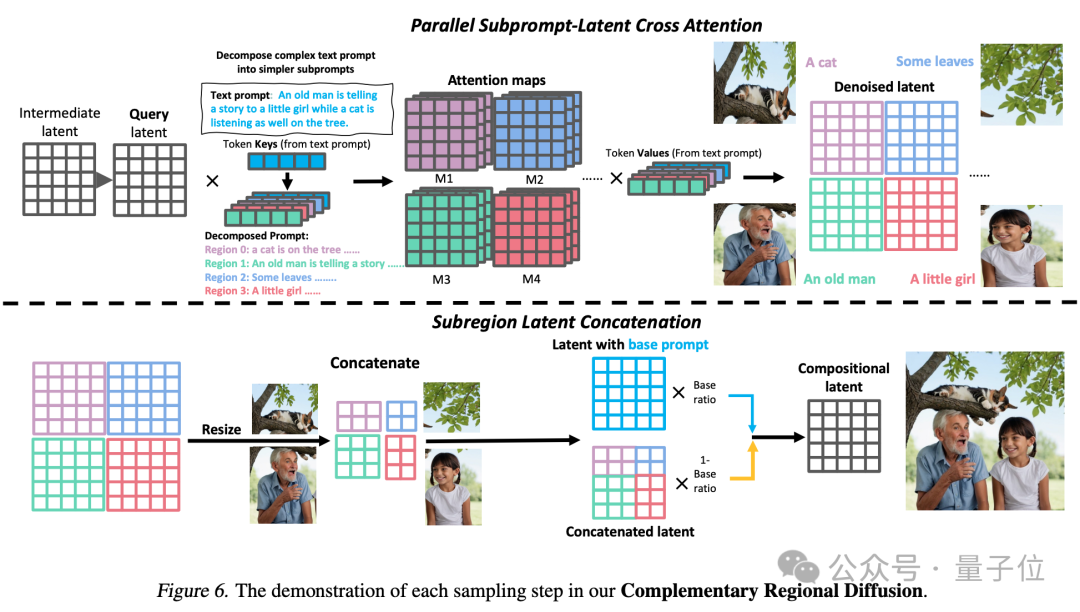
3. Diffusion régionale complémentaire : après avoir divisé l'espace, les zones qui ne se chevauchent pas génèrent des images basées sur des sous-invites, puis les assemblent.


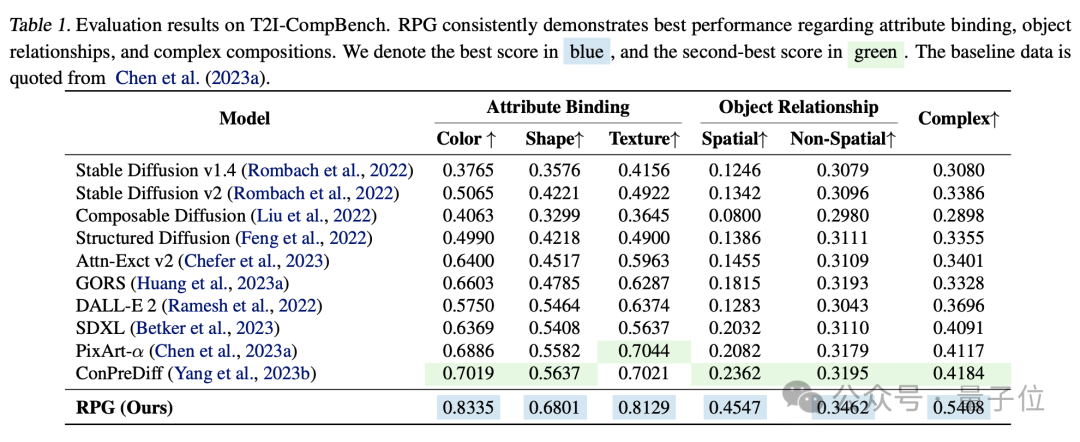
D'après la comparaison expérimentale, RPG surpasse les autres modèles de génération d'images en termes de dimensions telles que la couleur, la forme, l'espace et la précision du texte.
Cette étude est composée de deux co-auteurs, Ling Yang et Zhaochen Yu, tous deux de l'Université de Pékin.
Les auteurs participants incluent Chenlin Meng, co-fondateur et CTO de la startup d'IA Pika.
Elle est titulaire d'un doctorat en informatique de Stanford et possède une riche expérience académique en vision par ordinateur et en vision 3D. Elle a participé à l'article Denoising Diffusion Implicit Model (DDIM), qui compte désormais plus de 1 700 citations dans un seul article. Un certain nombre d'articles de recherche liés à l'IA générative ont été publiés lors de conférences de premier plan telles que ICLR, NeurIPS, CVPR et ICML, et nombre d'entre eux ont été sélectionnés dans Oral.
L'année dernière, Pika est devenu un succès instantané avec son produit de génération vidéo AI Pika 1.0. Le contexte de sa création par deux doctorantes chinoises de Stanford l'a rendu encore plus accrocheur.

△À gauche se trouve Guo Wenjing (PDG de Pika), à droite se trouve Chenlin Meng
Participe également à la recherche le professeur Cui Bin, doyen adjoint de l'École d'informatique de l'Université de Pékin, qui est également directeur de l'Institute of Data Science and Engineering.

Adresse papier : https://arxiv.org/abs/2401.11708
Adresse code : https://github.com/YangLing0818/RPG-DiffusionMaster
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
 Outils de recherche couramment utilisés
Outils de recherche couramment utilisés
 La différence entre Fahrenheit et Celsius
La différence entre Fahrenheit et Celsius
 Comment créer un fichier iso
Comment créer un fichier iso
 Codes couramment utilisés en langage HTML
Codes couramment utilisés en langage HTML
 emplacement.recherche
emplacement.recherche
 Pourquoi ne puis-je pas accéder au navigateur Ethereum ?
Pourquoi ne puis-je pas accéder au navigateur Ethereum ?
 Causes et solutions du délai d'expiration de la passerelle 504
Causes et solutions du délai d'expiration de la passerelle 504
 prix BTC aujourd'hui
prix BTC aujourd'hui








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



