
 Périphériques technologiques
IA
Apprentissage des connaissances sur l'occupation intermodale : RadOcc utilisant la technologie de distillation assistée par rendu
Périphériques technologiques
IA
Apprentissage des connaissances sur l'occupation intermodale : RadOcc utilisant la technologie de distillation assistée par rendu
Apprentissage des connaissances sur l'occupation intermodale : RadOcc utilisant la technologie de distillation assistée par rendu

Titre original : Radocc : Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation
Lien papier : https://arxiv.org/pdf/2312.11829.pdf
Affiliation de l'auteur : FNii, CUHK-Shenzhen SSE, CUHK-Shenzhen Huawei Noah's Ark Laboratory
Conférence : AAAI 2024

Idée de papier :
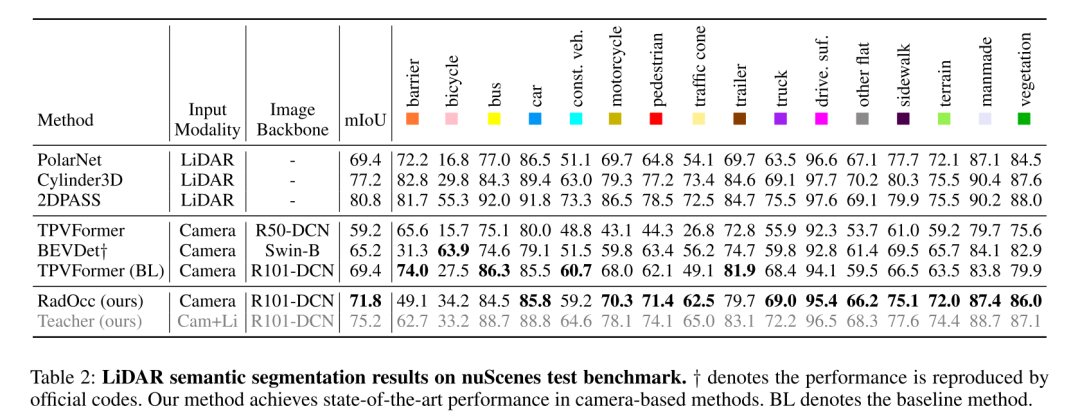
La prédiction d'occupation 3D est une tâche émergente qui vise à estimer l'état d'occupation et la sémantique de scènes 3D à l'aide d'images multi-vues. Cependant, la perception de scènes basée sur l’image se heurte à des défis importants pour obtenir des prédictions précises en raison du manque d’a priori géométriques. Cet article aborde ce problème en explorant la distillation des connaissances intermodales dans cette tâche, c'est-à-dire que nous utilisons un modèle multimodal plus puissant pour guider le modèle visuel pendant le processus de formation. En pratique, cet article observe que l'application directe de l'alignement des caractéristiques ou des logits, proposée et largement utilisée dans la perception à vol d'oiseau (BEV), ne donne pas de résultats satisfaisants. Pour surmonter ce problème, cet article présente RadOcc, un paradigme de distillation assistée par rendu pour la prédiction d'occupation 3D. En utilisant un rendu de volume différentiable, nous générons des cartes de profondeur et sémantiques en perspective et proposons deux nouveaux critères de cohérence entre la sortie rendue des modèles d'enseignant et d'élève. Plus précisément, la perte de cohérence en profondeur aligne les distributions de terminaison des rayons de rendu, tandis que la perte de cohérence sémantique imite la similarité intra-segment guidée par le modèle de base visuel (VLM). Les résultats expérimentaux sur l'ensemble de données nuScenes démontrent l'efficacité de la méthode proposée dans cet article pour améliorer diverses méthodes de prédiction d'occupation 3D. Par exemple, la méthode proposée dans cet article améliore la ligne de base de cet article de 2,2 % dans la métrique mIoU et atteint 2,2 %. dans le benchmark Occ3D 50%.
Principales contributions :
Cet article présente un paradigme de distillation assistée par rendu appelé RadOcc pour la prédiction d'occupation 3D. Il s'agit du premier article explorant la distillation intermodale des connaissances en 3D-OP, fournissant des informations précieuses sur l'application des techniques de distillation BEV existantes dans cette tâche.
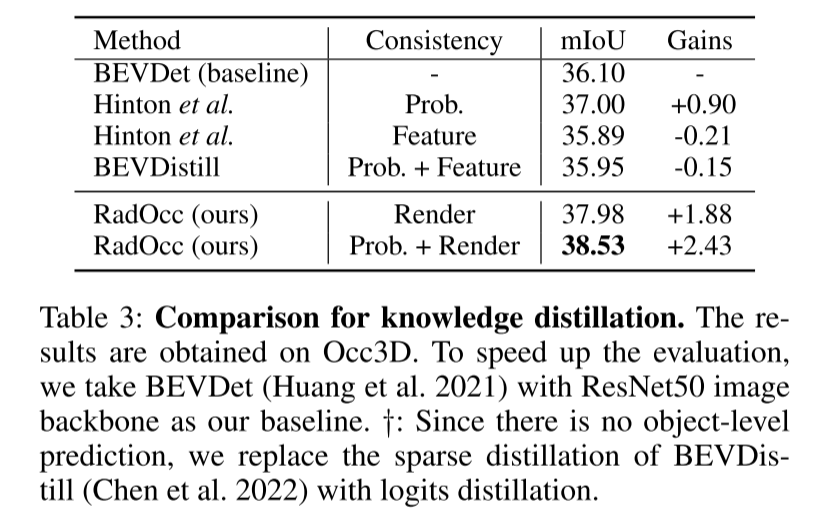
Les auteurs proposent deux nouvelles contraintes de distillation, à savoir la profondeur de rendu et la cohérence sémantique (RDC et RSC). Ces contraintes améliorent efficacement le processus de transfert de connaissances en alignant les matrices de distribution de lumière et de corrélation guidées par le modèle de base de vision. La clé de cette approche consiste à utiliser des informations approfondies et sémantiques pour guider le processus de rendu, améliorant ainsi la qualité et la précision des résultats de rendu. En combinant ces deux contraintes, les chercheurs ont réalisé des améliorations significatives, apportant de nouvelles solutions pour le transfert de connaissances dans les tâches de vision.
Équipé de la méthode proposée, RadOcc affiche des performances de pointe en matière de prédiction d'occupation dense et clairsemée sur les benchmarks Occ3D et nuScenes. De plus, des expériences ont prouvé que la méthode de distillation proposée dans cet article peut améliorer efficacement les performances de plusieurs modèles de base.
Conception de réseau :
Cet article est le premier à étudier la distillation des connaissances intermodales pour la tâche de prédiction d'occupation 3D. Basé sur la méthode de transfert de connaissances utilisant la cohérence BEV ou logits dans le domaine de détection BEV, cet article étend ces techniques de distillation à la tâche de prédiction d'occupation 3D, visant à aligner les caractéristiques du voxel et les logits du voxel, comme le montre la figure 1 (a). Cependant, des expériences préliminaires montrent que ces techniques d'alignement sont confrontées à des défis importants dans les tâches 3D-OP, en particulier la première méthode qui introduit un transfert négatif. Ce défi peut provenir de la différence fondamentale entre la détection d'objets 3D et la prédiction d'occupation, qui, en tant que tâche de perception plus fine, nécessite de capturer des détails géométriques ainsi que des objets d'arrière-plan.
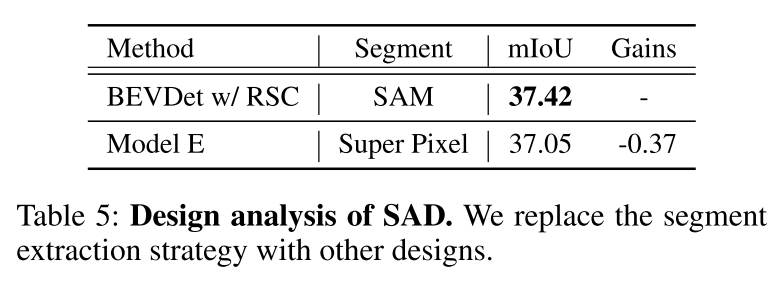
Pour relever les défis ci-dessus, cet article propose RadOcc, une nouvelle méthode de distillation de connaissances multimodales utilisant le rendu de volume différentiable. L'idée principale de RadOcc est d'aligner les résultats de rendu générés par le modèle d'enseignant et le modèle d'étudiant, comme le montre la figure 1(b). Plus précisément, cet article utilise les paramètres intrinsèques et extrinsèques de la caméra pour effectuer un rendu volumique des caractéristiques du voxel (Mildenhall et al. 2021), ce qui permet à cet article d'obtenir des cartes de profondeur et des cartes sémantiques correspondantes à partir de différents points de vue. Pour obtenir un meilleur alignement entre les sorties rendues, cet article introduit de nouvelles pertes de cohérence de profondeur de rendu (RDC) et de cohérence sémantique de rendu (RSC). D'une part, la perte RDC renforce la cohérence de la distribution des rayons, ce qui permet au modèle Student de capturer la structure sous-jacente des données. D'autre part, la perte RSC tire parti du modèle de base visuel (Kirillov et al. 2023) et utilise des segments pré-extraits pour la distillation par affinité. Cette norme permet aux modèles d'apprendre et de comparer les représentations sémantiques de différentes régions d'image, améliorant ainsi leur capacité à capturer des détails fins. En combinant les contraintes ci-dessus, la méthode proposée dans cet article exploite efficacement la distillation des connaissances intermodales, améliorant ainsi les performances et optimisant mieux le modèle étudiant. Cet article démontre l'efficacité de notre approche sur la prévision d'occupation dense et clairsemée, obtenant des résultats de pointe sur les deux tâches.
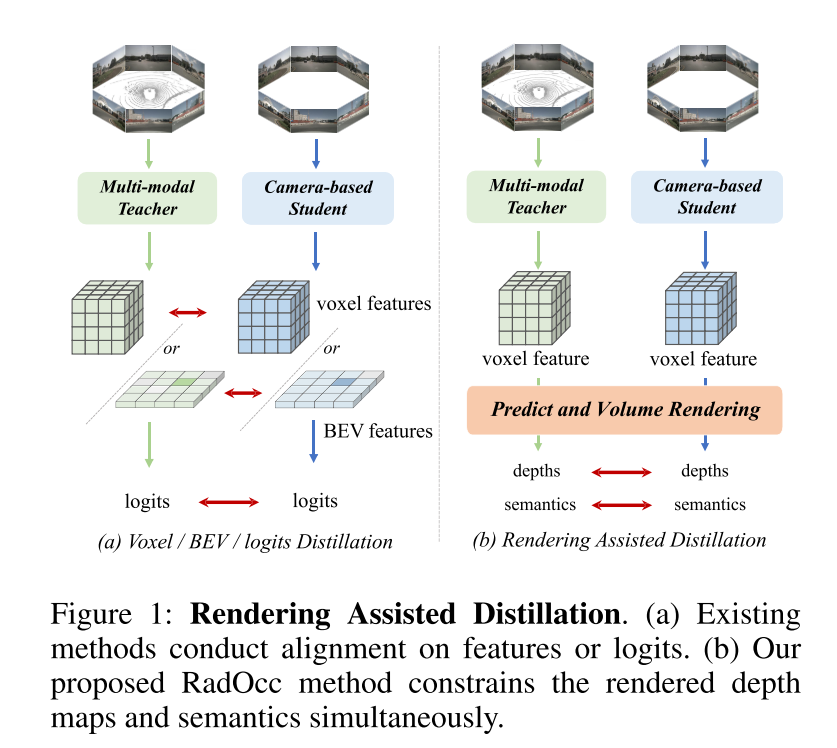
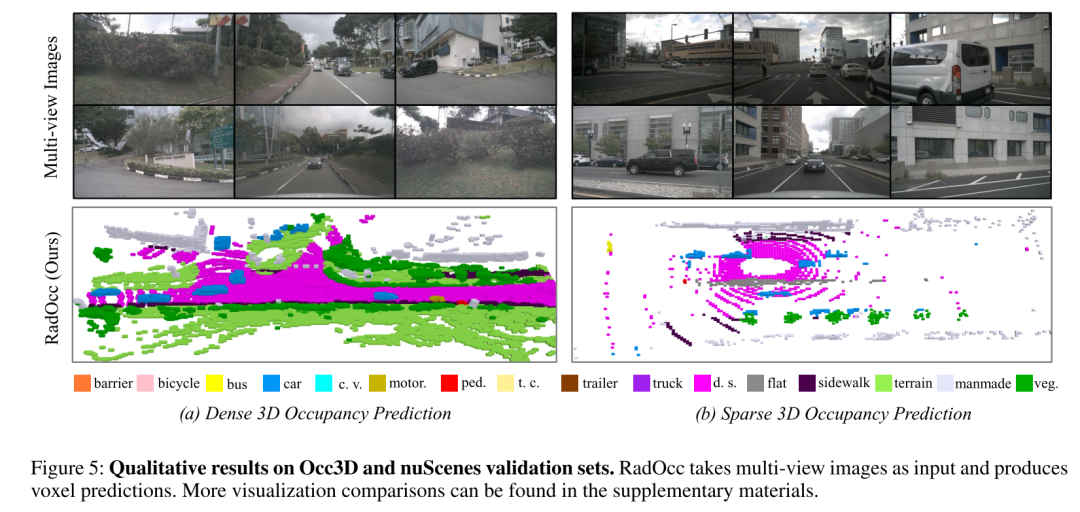
Figure 1 : Distillation assistée par rendu. (a) Les méthodes existantes alignent les caractéristiques ou les logits. (b) La méthode RadOcc proposée dans cet article contraint simultanément la carte de profondeur rendue et la sémantique. 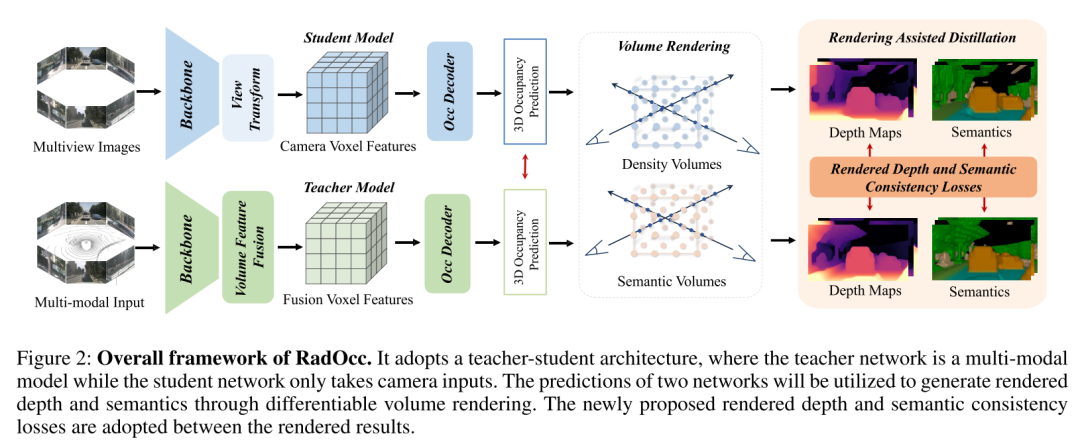 Figure 2 : Cadre global de RadOcc. Il adopte une architecture enseignant-élève, dans laquelle le réseau enseignant est un modèle multimodal et le réseau étudiant n'accepte que les entrées de caméra. Les prédictions des deux réseaux seront utilisées pour générer de la profondeur et de la sémantique du rendu grâce à un rendu de volume différentiable. Les pertes de profondeur de rendu et de cohérence sémantique nouvellement proposées sont adoptées entre les résultats de rendu.
Figure 2 : Cadre global de RadOcc. Il adopte une architecture enseignant-élève, dans laquelle le réseau enseignant est un modèle multimodal et le réseau étudiant n'accepte que les entrées de caméra. Les prédictions des deux réseaux seront utilisées pour générer de la profondeur et de la sémantique du rendu grâce à un rendu de volume différentiable. Les pertes de profondeur de rendu et de cohérence sémantique nouvellement proposées sont adoptées entre les résultats de rendu.
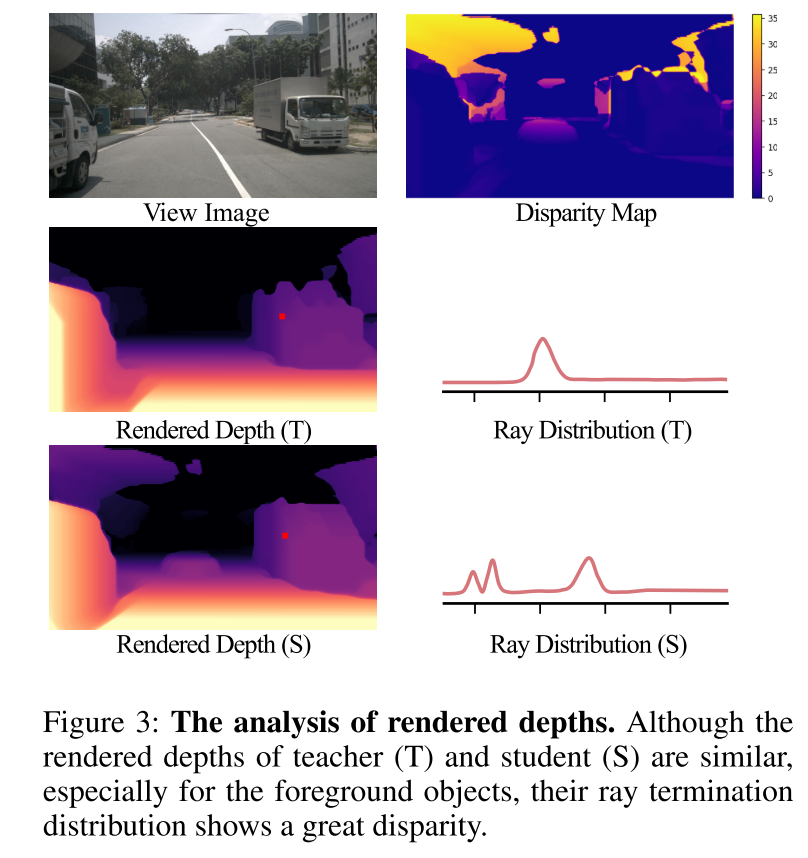
Figure 3 : Analyse de la profondeur du rendu. Bien que l'enseignant (T) et l'élève (S) aient des profondeurs de rendu similaires, en particulier pour les objets du premier plan, leurs distributions de terminaison lumineuse présentent de grandes différences.
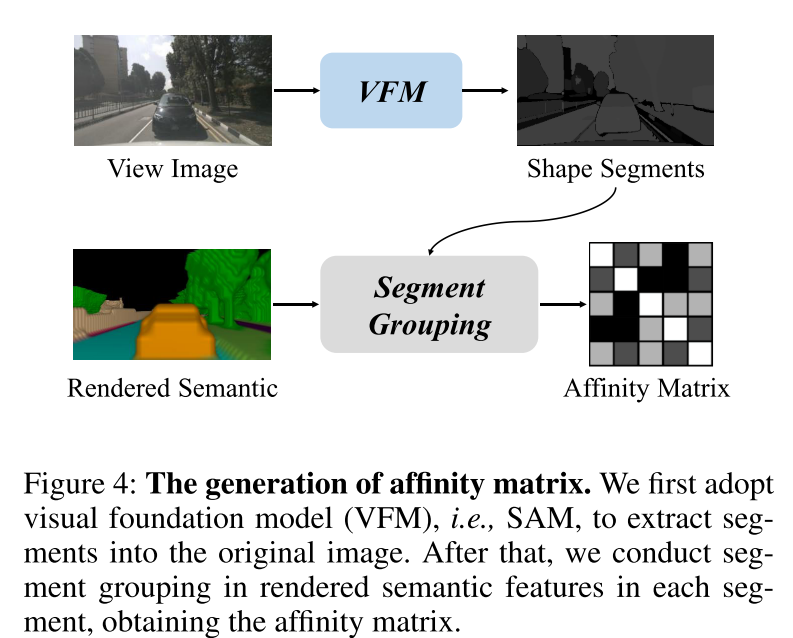
Figure 4 : Génération de matrice d'affinité. Cet article utilise d'abord le Vision Foundation Model (VFM), à savoir SAM, pour extraire des segments dans l'image originale. Ensuite, cet article effectue une agrégation de segments sur les caractéristiques sémantiques rendues dans chaque segment pour obtenir la matrice d'affinité.
Résultats expérimentaux :


Résumé :
Cet article propose RadOcc , un roman 3D de distillation de connaissances multimodales pour le paradigme de prédiction d'occupation. Il utilise un modèle d'enseignant multimodal pour fournir des conseils géométriques et sémantiques au modèle visuel d'élève grâce à un rendu de volume différenciable. En outre, cet article propose deux nouveaux critères de cohérence, la perte de cohérence en profondeur et la perte de cohérence sémantique, pour aligner la distribution des rayons et la matrice d'affinité entre les modèles d'enseignant et d'élève. Des expériences approfondies sur les ensembles de données Occ3D et nuScenes montrent que RadOcc peut améliorer considérablement les performances de diverses méthodes de prédiction d'occupation 3D. Notre méthode obtient des résultats de pointe sur le benchmark du défi Occ3D et surpasse considérablement les méthodes publiées existantes. Nous pensons que notre travail ouvre de nouvelles possibilités d’apprentissage multimodal dans la compréhension des scènes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 En savoir plus sur les emojis 3D Fluent dans Microsoft Teams
Apr 24, 2023 pm 10:28 PM
En savoir plus sur les emojis 3D Fluent dans Microsoft Teams
Apr 24, 2023 pm 10:28 PM
N'oubliez pas, surtout si vous êtes un utilisateur de Teams, que Microsoft a ajouté un nouveau lot d'émojis 3DFluent à son application de visioconférence axée sur le travail. Après que Microsoft a annoncé des emojis 3D pour Teams et Windows l'année dernière, le processus a en fait permis de mettre à jour plus de 1 800 emojis existants pour la plate-forme. Cette grande idée et le lancement de la mise à jour des emoji 3DFluent pour les équipes ont été promus pour la première fois via un article de blog officiel. La dernière mise à jour de Teams apporte FluentEmojis à l'application. Microsoft affirme que les 1 800 emojis mis à jour seront disponibles chaque jour.
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Régression quantile pour la prévision probabiliste de séries chronologiques
May 07, 2024 pm 05:04 PM
Régression quantile pour la prévision probabiliste de séries chronologiques
May 07, 2024 pm 05:04 PM
Ne changez pas la signification du contenu original, affinez le contenu, réécrivez le contenu et ne continuez pas. "La régression quantile répond à ce besoin, en fournissant des intervalles de prédiction avec des chances quantifiées. Il s'agit d'une technique statistique utilisée pour modéliser la relation entre une variable prédictive et une variable de réponse, en particulier lorsque la distribution conditionnelle de la variable de réponse présente un intérêt quand. Contrairement à la régression traditionnelle " Figure (A) : Régression quantile La régression quantile est une estimation. Une méthode de modélisation de la relation linéaire entre un ensemble de régresseurs X et les quantiles. des variables expliquées Y. Le modèle de régression existant est en fait une méthode pour étudier la relation entre la variable expliquée et la variable explicative. Ils se concentrent sur la relation entre variables explicatives et variables expliquées.
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 Paint 3D sous Windows 11 : guide de téléchargement, d'installation et d'utilisation
Apr 26, 2023 am 11:28 AM
Paint 3D sous Windows 11 : guide de téléchargement, d'installation et d'utilisation
Apr 26, 2023 am 11:28 AM
Lorsque les rumeurs ont commencé à se répandre selon lesquelles le nouveau Windows 11 était en développement, chaque utilisateur de Microsoft était curieux de savoir à quoi ressemblerait le nouveau système d'exploitation et ce qu'il apporterait. Après de nombreuses spéculations, Windows 11 est là. Le système d'exploitation est livré avec une nouvelle conception et des modifications fonctionnelles. En plus de quelques ajouts, il s’accompagne de fonctionnalités obsolètes et supprimées. L'une des fonctionnalités qui n'existe pas dans Windows 11 est Paint3D. Bien qu'il propose toujours Paint classique, idéal pour les dessinateurs, les griffonneurs et les griffonneurs, il abandonne Paint3D, qui offre des fonctionnalités supplémentaires idéales pour les créateurs 3D. Si vous recherchez des fonctionnalités supplémentaires, nous recommandons Autodesk Maya comme le meilleur logiciel de conception 3D. comme
 Comment utiliser la base de données MySQL pour les prévisions et l'analyse prédictive ?
Jul 12, 2023 pm 08:43 PM
Comment utiliser la base de données MySQL pour les prévisions et l'analyse prédictive ?
Jul 12, 2023 pm 08:43 PM
Comment utiliser la base de données MySQL pour les prévisions et l'analyse prédictive ? Présentation : les prévisions et l'analyse prédictive jouent un rôle important dans l'analyse des données. MySQL, un système de gestion de bases de données relationnelles largement utilisé, peut également être utilisé pour des tâches de prédiction et d'analyse prédictive. Cet article explique comment utiliser MySQL pour la prédiction et l'analyse prédictive, et fournit des exemples de code pertinents. Préparation des données : Tout d’abord, nous devons préparer les données pertinentes. Supposons que nous souhaitions faire des prévisions de ventes, nous avons besoin d'un tableau contenant des données de ventes. Dans MySQL, nous pouvons utiliser
