
 Périphériques technologiques
IA
Optimisation du LLM à l'aide de la technologie SPIN pour la formation de mise au point du jeu personnel
Périphériques technologiques
IA
Optimisation du LLM à l'aide de la technologie SPIN pour la formation de mise au point du jeu personnel
Optimisation du LLM à l'aide de la technologie SPIN pour la formation de mise au point du jeu personnel

2024 est l'année du développement rapide des grands modèles de langage (LLM). Dans la formation du LLM, les méthodes d'alignement sont un moyen technique important, notamment le réglage fin supervisé (SFT) et l'apprentissage par renforcement avec retour humain (RLHF) qui s'appuie sur les préférences humaines. Ces méthodes ont joué un rôle crucial dans le développement du LLM, mais les méthodes d’alignement nécessitent une grande quantité de données annotées manuellement. Face à ce défi, la mise au point est devenue un domaine de recherche dynamique, les chercheurs travaillant activement au développement de méthodes permettant d’exploiter efficacement les données humaines. Par conséquent, le développement de méthodes d’alignement favorisera de nouvelles percées dans la technologie LLM.
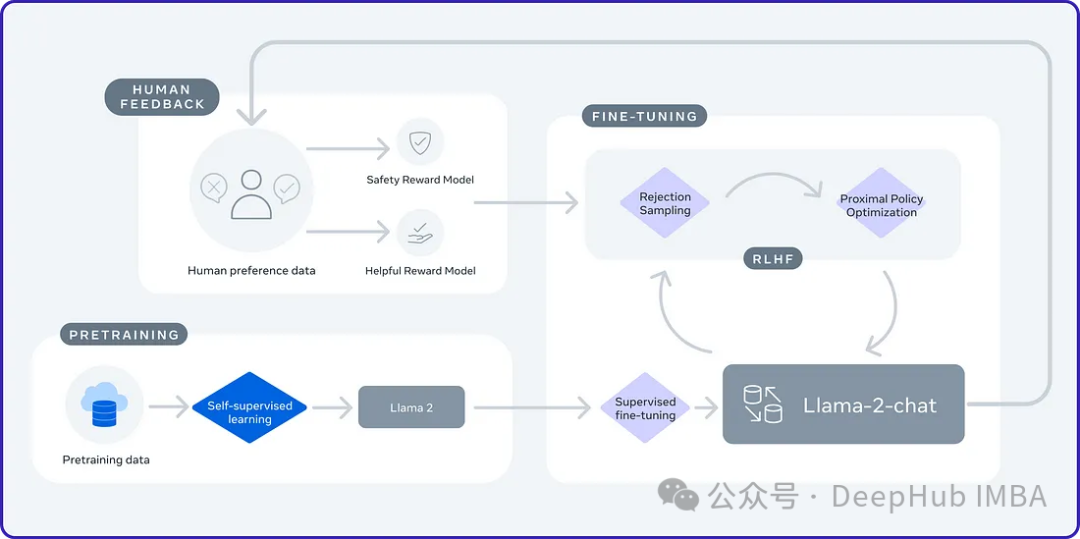
L'Université de Californie a récemment mené une étude et introduit une nouvelle technologie appelée SPIN (Self Play fine tuNing). SPIN s'appuie sur le mécanisme de jeu autonome efficace de jeux tels que AlphaGo Zero et AlphaZero pour permettre au LLM (Language Learning Model) de participer au jeu autonome. Cette technologie élimine le besoin d’annotateurs professionnels, qu’il s’agisse d’humains ou de modèles plus avancés (tels que GPT-4). Le processus de formation de SPIN consiste à former un nouveau modèle de langage et à distinguer ses propres réponses générées des réponses générées par l'homme à travers une série d'itérations. Le but ultime est de développer un modèle de langage qui génère des réponses impossibles à distinguer des réponses humaines. Le but de cette recherche est d’améliorer encore la capacité d’auto-apprentissage du modèle linguistique et de le rapprocher de l’expression et de la pensée humaines. Les résultats de ces recherches devraient apporter de nouvelles avancées dans le développement du traitement du langage naturel.
Self-Game
Le self-game est une technique d'apprentissage qui augmente le défi et la complexité de l'environnement d'apprentissage en jouant contre des copies de soi. Cette approche permet à un agent d'interagir avec différentes versions de lui-même, améliorant ainsi ses capacités. AlphaGo Zero est un cas réussi de self-game.

Le jeu de soi s'est avéré être une méthode efficace dans l'apprentissage par renforcement multi-agents (MARL). Cependant, son application à l’augmentation de grands modèles de langage (LLM) est une nouvelle approche. En appliquant le jeu de soi à de grands modèles linguistiques, leur capacité à générer un texte plus cohérent et riche en informations peut être encore améliorée. Cette méthode devrait promouvoir le développement et l’amélioration des modèles de langage.
Le self-play peut être appliqué dans des contextes compétitifs ou coopératifs. En compétition, les copies de l’algorithme s’affrontent pour atteindre un objectif ; en coopération, les copies travaillent ensemble pour atteindre un objectif commun. Il peut être combiné avec l’apprentissage supervisé, l’apprentissage par renforcement et d’autres technologies pour améliorer les performances.
SPIN
SPIN est comme un jeu à deux joueurs. Dans ce jeu :
Le rôle du maître modèle (nouveau LLM) est d'apprendre à distinguer les réponses générées par un modèle de langage (LLM) et les réponses créées par les humains. À chaque itération, le modèle maître forme activement le LLM pour améliorer sa capacité à reconnaître et à distinguer les réponses.
Le modèle adversaire (ancien LLM) est chargé de générer des réponses similaires à celles produites par les humains. Il est généré via le LLM de l’itération précédente, en utilisant un mécanisme d’auto-jeu pour générer un résultat basé sur les connaissances passées. L’objectif du modèle de l’adversaire est de créer une réponse si réaliste que le nouveau LLM ne peut pas être sûr qu’elle a été générée par une machine.
Ce processus n'est-il pas très similaire au GAN, mais ce n'est toujours pas le même
La dynamique de SPIN implique l'utilisation d'un ensemble de données de réglage fin supervisé (SFT), composé d'une entrée (x) et d'une sortie (y ) paires. Ces exemples sont annotés par des humains et servent de base à la formation du modèle principal pour reconnaître les réponses de type humain. Certains ensembles de données SFT publics incluent Dolly15K, Baize, Ultrachat, etc.
Formation du modèle principal
Afin d'entraîner le modèle principal à faire la distinction entre les modèles de langage (LLM) et les réponses humaines, SPIN utilise une fonction objective. Cette fonction mesure l'écart de valeur attendue entre les données réelles et la réponse produite par le modèle adverse. L’objectif du modèle principal est de maximiser cet écart de valeur attendue. Cela implique d'attribuer des valeurs élevées aux signaux associés à des réponses provenant de données réelles et d'attribuer des valeurs faibles aux paires de réponses générées par le modèle d'adversaire. Cette fonction objectif est formulée comme un problème de minimisation.
Le travail du modèle maître consiste à minimiser la fonction de perte, qui mesure la différence entre les valeurs d'affectation par paire des données réelles et les valeurs d'affectation par paire des réponses du modèle adverse. Tout au long du processus de formation, le modèle maître ajuste ses paramètres pour minimiser cette fonction de perte. Ce processus itératif se poursuit jusqu'à ce que le modèle maître soit capable de distinguer efficacement les réponses LLM des réponses humaines.
Mise à jour du modèle de l'adversaire
La mise à jour du modèle de l'adversaire implique d'améliorer la capacité du modèle maître, qui au cours de la formation a appris à distinguer les données réelles des réponses du modèle de langage. À mesure que le modèle maître s'améliore et que sa compréhension des classes de fonctions spécifiques s'améliore, nous devons également mettre à jour des paramètres tels que le modèle adversaire. Lorsque le joueur maître est confronté aux mêmes invites, il utilise sa discrimination apprise pour évaluer leur valeur.
L'objectif du joueur modèle adverse est d'améliorer le modèle de langage afin que ses réponses soient impossibles à distinguer des données réelles du joueur maître. Cela nécessite la mise en place d’un processus d’ajustement des paramètres du modèle linguistique. L'objectif est de maximiser l'évaluation par le modèle maître de la réponse du modèle de langage tout en maintenant la stabilité. Cela implique un exercice d'équilibre, garantissant que les améliorations ne s'éloignent pas trop du modèle linguistique d'origine.
Cela semble un peu déroutant, résumons brièvement :
Il n'y a qu'un seul modèle pendant l'entraînement, mais le modèle est divisé en modèle du tour précédent (ancien modèle LLM/adversaire) et le modèle principal (en cours d'entraînement), utilisation La sortie du modèle en cours de formation est comparée à la sortie de la série précédente de modèles pour optimiser la formation du modèle actuel. Mais ici, nous devons avoir un modèle entraîné comme modèle adverse, donc l'algorithme SPIN ne convient que pour affiner les résultats de l'entraînement.
Algorithme SPIN
SPIN génère des données synthétiques à partir de modèles pré-entraînés. Ces données synthétiques sont ensuite utilisées pour affiner le modèle sur de nouvelles tâches.

Ce ci-dessus est le pseudo-code de l'algorithme Spin dans l'article original. Il semble un peu difficile à comprendre. Nous le reproduisons en Python pour mieux expliquer son fonctionnement.
1. Paramètres d'initialisation et ensemble de données SFT
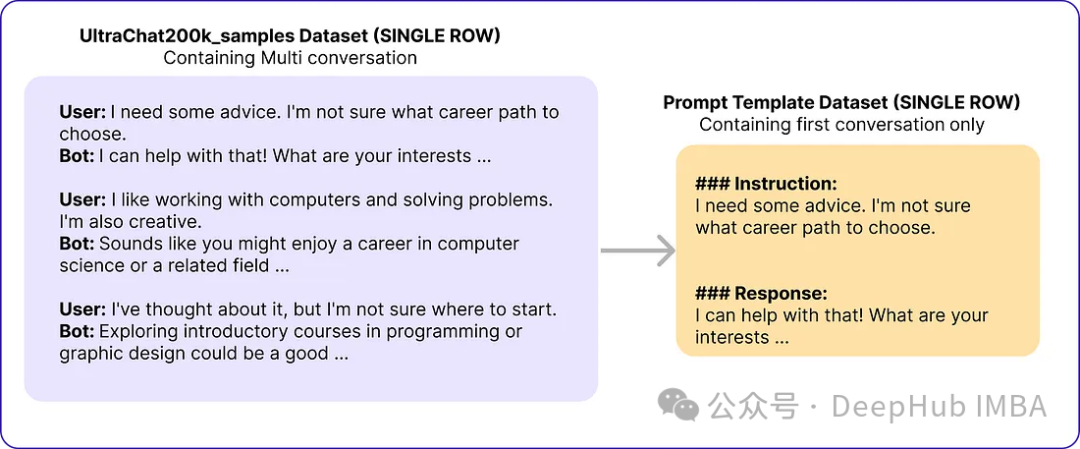
L'article original utilise Zephyr-7B-SFT-Full comme modèle de base. Pour l’ensemble de données, ils ont utilisé un sous-ensemble du plus grand corpus Ultrachat200k, qui comprend environ 1,4 million de conversations générées à l’aide de l’API Turbo d’OpenAI. Ils ont échantillonné au hasard 50 000 signaux et ont utilisé un modèle de base pour générer des réponses synthétiques.
# Import necessary libraries from datasets import load_dataset import pandas as pd # Load the Ultrachat 200k dataset ultrachat_dataset = load_dataset("HuggingFaceH4/ultrachat_200k") # Initialize an empty DataFrame combined_df = pd.DataFrame() # Loop through all the keys in the Ultrachat dataset for key in ultrachat_dataset.keys():# Convert each dataset key to a pandas DataFrame and concatenate it with the existing DataFramecombined_df = pd.concat([combined_df, pd.DataFrame(ultrachat_dataset[key])]) # Shuffle the combined DataFrame and reset the index combined_df = combined_df.sample(frac=1, random_state=123).reset_index(drop=True) # Select the first 50,000 rows from the shuffled DataFrame ultrachat_50k_sample = combined_df.head(50000)Le modèle d'invite de l'auteur "### Instruction : {prompt}nn### Réponse :"
# for storing each template in a list templates_data = [] for index, row in ultrachat_50k_sample.iterrows():messages = row['messages'] # Check if there are at least two messages (user and assistant)if len(messages) >= 2:user_message = messages[0]['content']assistant_message = messages[1]['content'] # Create the templateinstruction_response_template = f"### Instruction: {user_message}\n\n### Response: {assistant_message}" # Append the template to the listtemplates_data.append({'Template': instruction_response_template}) # Create a new DataFrame with the generated templates (ground truth) ground_truth_df = pd.DataFrame(templates_data)Ensuite, nous avons obtenu des données similaires aux suivantes :
L'algorithme SPIN met à jour le modèle de langage (LLM) en paramètres d'itération pour les maintenir cohérents avec la réponse de vérité terrain. Ce processus se poursuit jusqu'à ce qu'il soit difficile de distinguer la réponse générée de la vérité terrain, atteignant ainsi un niveau élevé de similarité (perte réduite).
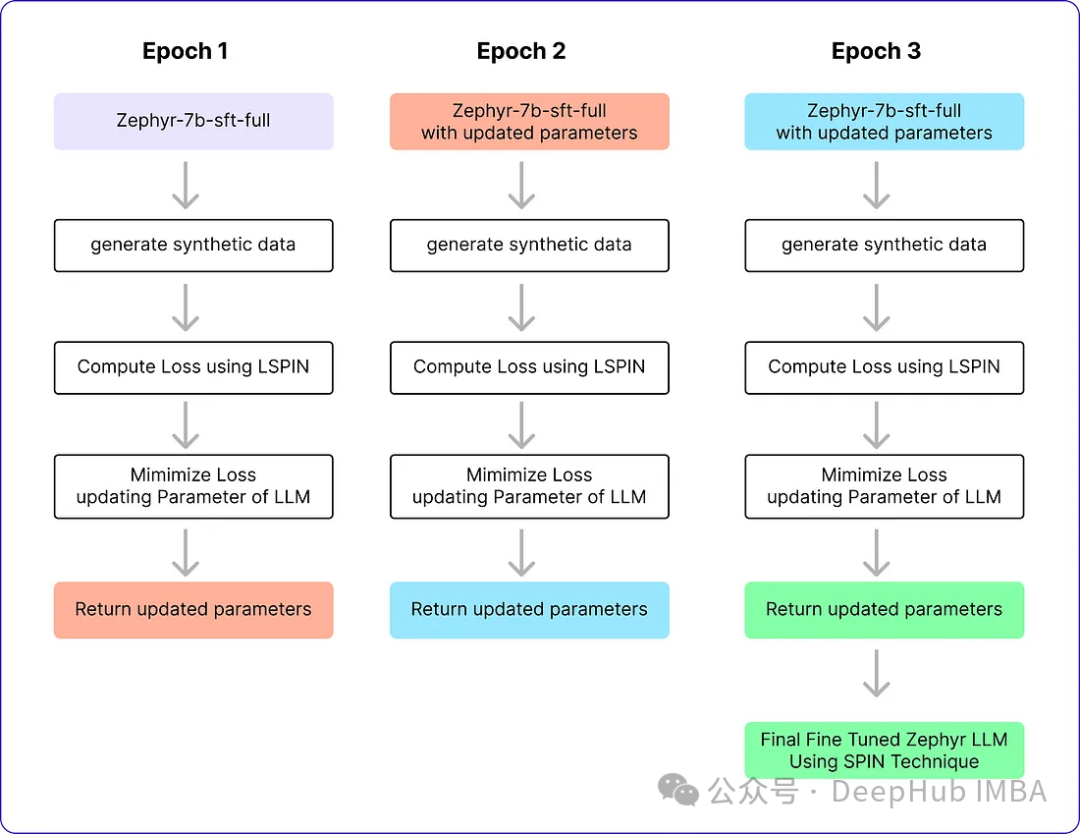
L'algorithme SPIN comporte deux boucles. La boucle interne a été exécutée en fonction du nombre d'échantillons que nous utilisions, et la boucle externe a été exécutée sur un total de 3 itérations, car les auteurs ont constaté que les performances du modèle n'ont pas changé par la suite. La bibliothèque Alignment Handbook est utilisée comme bibliothèque de codes pour la méthode de réglage fin, et combinée au module DeepSpeed , le coût de formation est réduit. Ils ont entraîné Zephyr-7B-SFT-Full avec l'optimiseur RMSProp, sans perte de poids pour toutes les itérations, comme c'est généralement le cas pour affiner le llm. La taille globale du lot est définie sur 64, en utilisant la précision bfloat16. Le taux d'apprentissage maximal pour les itérations 0 et 1 est fixé à 5e-7, et le taux d'apprentissage maximal pour les itérations 2 et 3 diminue à 1e-7 à mesure que la boucle approche de la fin du réglage fin de l'auto-jeu. Enfin, β = 0,1 est choisi et la longueur maximale de la séquence est fixée à 2048 jetons. Voici ces paramètres
# Importing the PyTorch library import torch # Importing the neural network module from PyTorch import torch.nn as nn # Importing the DeepSpeed library for distributed training import deepspeed # Importing the AutoTokenizer and AutoModelForCausalLM classes from the transformers library from transformers import AutoTokenizer, AutoModelForCausalLM # Loading the zephyr-7b-sft-full model from HuggingFace tokenizer = AutoTokenizer.from_pretrained("alignment-handbook/zephyr-7b-sft-full") model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full") # Initializing DeepSpeed Zero with specific configuration settings deepspeed_config = deepspeed.config.Config(train_batch_size=64, train_micro_batch_size_per_gpu=4) model, optimizer, _, _ = deepspeed.initialize(model=model, config=deepspeed_config, model_parameters=model.parameters()) # Defining the optimizer and setting the learning rate using RMSprop optimizer = deepspeed.optim.RMSprop(optimizer, lr=5e-7) # Setting up a learning rate scheduler using LambdaLR from PyTorch scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lambda epoch: 0.2 ** epoch) # Setting hyperparameters for training num_epochs = 3 max_seq_length = 2048 beta = 0.12. Générer des données synthétiques (boucle interne de l'algorithme SPIN)
Cette boucle interne est chargée de générer des réponses qui doivent être cohérentes avec les données réelles, qui sont le code d'un lot d'entraînement
# zephyr-sft-dataframe (that contains output that will be improved while training) zephyr_sft_output = pd.DataFrame(columns=['prompt', 'generated_output']) # Looping through each row in the 'ultrachat_50k_sample' dataframe for index, row in ultrachat_50k_sample.iterrows():# Extracting the 'prompt' column value from the current rowprompt = row['prompt'] # Generating output for the current prompt using the Zephyr modelinput_ids = tokenizer(prompt, return_tensors="pt").input_idsoutput = model.generate(input_ids, max_length=200, num_beams=5, no_repeat_ngram_size=2, top_k=50, top_p=0.95) # Decoding the generated output to human-readable textgenerated_text = tokenizer.decode(output[0], skip_special_tokens=True) # Appending the current prompt and its generated output to the new dataframe 'zephyr_sft_output'zephyr_sft_output = zephyr_sft_output.append({'prompt': prompt, 'generated_output': generated_text}, ignore_index=True)Ceci. est un indice Exemples de valeurs réelles et de sorties du modèle.

Nouveau df zephyr_sft_output, qui contient des astuces et leurs sorties correspondantes générées par le modèle de base Zephyr-7B-SFT-Full.
3. Règles de mise à jour
Avant de coder le problème de minimisation, il est crucial de comprendre comment calculer la distribution de probabilité conditionnelle de la sortie générée par llm. L'article original utilise un processus de Markov, où la distribution de probabilité conditionnelle pθ (y∣x) peut être exprimée par décomposition comme :

Cette décomposition signifie que la probabilité de la séquence de sortie étant donné la séquence d'entrée peut être exprimée en divisant la séquence d'entrée donnée. Chaque jeton de sortie de est calculé en multipliant la probabilité du jeton de sortie précédent. Par exemple, la séquence de sortie est "J'aime lire des livres" et la séquence d'entrée est "J'aime". Compte tenu de la séquence d'entrée, la probabilité conditionnelle de la séquence de sortie peut être calculée comme suit :

La probabilité conditionnelle du processus de Markov. seront des distributions de probabilité utilisées pour calculer la vérité terrain et les réponses Zephyr LLM, qui sont ensuite utilisées pour calculer la fonction de perte. Mais nous devons d’abord coder la fonction de probabilité conditionnelle.
# Conditional Probability Function of input text def compute_conditional_probability(tokenizer, model, input_text):# Tokenize the input text and convert it to PyTorch tensorsinputs = tokenizer([input_text], return_tensors="pt") # Generate text using the model, specifying additional parametersoutputs = model.generate(**inputs, return_dict_in_generate=True, output_scores=True) # Assuming 'transition_scores' is the logits for the generated tokenstransition_scores = model.compute_transition_scores(outputs.sequences, outputs.scores, normalize_logits=True) # Get the length of the input sequenceinput_length = inputs.input_ids.shape[1] # Assuming 'transition_scores' is the logits for the generated tokenslogits = torch.tensor(transition_scores) # Apply softmax to obtain probabilitiesprobs = torch.nn.functional.softmax(logits, dim=-1) # Extract the generated tokens from the outputgenerated_tokens = outputs.sequences[:, input_length:] # Compute conditional probabilityconditional_probability = 1.0for prob in probs[0]:token_probability = prob.item()conditional_probability *= token_probability return conditional_probability
Fonction de perte Elle contient quatre variables de probabilité conditionnelles importantes. Chacune de ces variables dépend de données réelles sous-jacentes ou de données synthétiques créées précédemment.

而lambda是一个正则化参数,用于控制偏差。在KL正则化项中使用它来惩罚对手模型的分布与目标数据分布之间的差异。论文中没有明确提到lambda的具体值,因为它可能会根据所使用的特定任务和数据集进行调优。
def LSPIN_loss(model, updated_model, tokenizer, input_text, lambda_val=0.01):# Initialize conditional probability using the original model and input textcp = compute_conditional_probability(tokenizer, model, input_text) # Update conditional probability using the updated model and input textcp_updated = compute_conditional_probability(tokenizer, updated_model, input_text) # Calculate conditional probabilities for ground truth datap_theta_ground_truth = cp(tokenizer, model, input_text)p_theta_t_ground_truth = cp(tokenizer, model, input_text) # Calculate conditional probabilities for synthetic datap_theta_synthetic = cp_updated(tokenizer, updated_model, input_text)p_theta_t_synthetic = cp_updated(tokenizer, updated_model, input_text) # Calculate likelihood ratioslr_ground_truth = p_theta_ground_truth / p_theta_t_ground_truthlr_synthetic = p_theta_synthetic / p_theta_t_synthetic # Compute the LSPIN lossloss = lambda_val * torch.log(lr_ground_truth) - lambda_val * torch.log(lr_synthetic) return loss
如果你有一个大的数据集,可以使用一个较小的lambda值,或者如果你有一个小的数据集,则可能需要使用一个较大的lambda值来防止过拟合。由于我们数据集大小为50k,所以可以使用0.01作为lambda的值。
4、训练(SPIN算法外循环)
这就是Pytorch训练的一个基本流程,就不详细解释了:
# Training loop for epoch in range(num_epochs): # Model with initial parametersinitial_model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full") # Update the learning ratescheduler.step() # Initialize total loss for the epochtotal_loss = 0.0 # Generating Synthetic Data (Inner loop)for index, row in ultrachat_50k_sample.iterrows(): # Rest of the code ... # Output == prompt response dataframezephyr_sft_output # Computing loss using LSPIN functionfor (index1, row1), (index2, row2) in zip(ultrachat_50k_sample.iterrows(), zephyr_sft_output.iterrows()):# Assuming 'prompt' and 'generated_output' are the relevant columns in zephyr_sft_outputprompt = row1['prompt']generated_output = row2['generated_output'] # Compute LSPIN lossupdated_model = model # It will be replacing with updated modelloss = LSPIN_loss(initial_model, updated_model, tokenizer, prompt) # Accumulate the losstotal_loss += loss.item() # Backward passloss.backward() # Update the parametersoptimizer.step() # Update the value of betaif epoch == 2:beta = 5.0我们运行3个epoch,它将进行训练并生成最终的Zephyr SFT LLM版本。官方实现还没有在GitHub上开源,这个版本将能够在某种程度上产生类似于人类反应的输出。我们看看他的运行流程
表现及结果
SPIN可以显著提高LLM在各种基准测试中的性能,甚至超过通过直接偏好优化(DPO)补充额外的GPT-4偏好数据训练的模型。
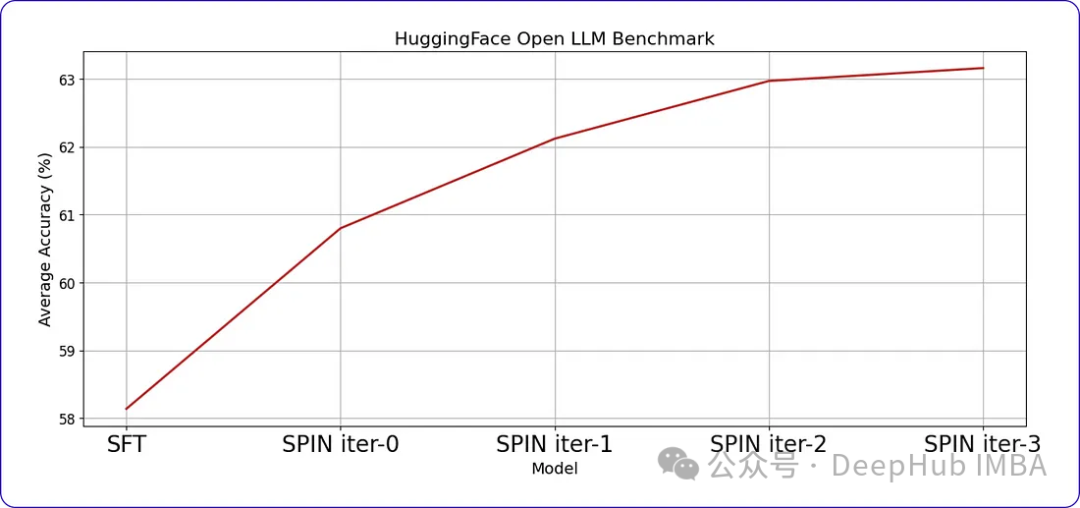
当我们继续训练时,随着时间的推移,进步会变得越来越小。这表明模型达到了一个阈值,进一步的迭代不会带来显著的收益。这是我们训练数据中样本提示符每次迭代后的响应。

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Selon les informations de ce site Web du 5 juillet, GlobalFoundries a publié un communiqué de presse le 1er juillet de cette année, annonçant l'acquisition de la technologie de nitrure de gallium (GaN) et du portefeuille de propriété intellectuelle de Tagore Technology, dans l'espoir d'élargir sa part de marché dans l'automobile et Internet. des objets et des domaines d'application des centres de données d'intelligence artificielle pour explorer une efficacité plus élevée et de meilleures performances. Alors que des technologies telles que l’intelligence artificielle générative (GenerativeAI) continuent de se développer dans le monde numérique, le nitrure de gallium (GaN) est devenu une solution clé pour une gestion durable et efficace de l’énergie, notamment dans les centres de données. Ce site Web citait l'annonce officielle selon laquelle, lors de cette acquisition, l'équipe d'ingénierie de Tagore Technology rejoindrait GF pour développer davantage la technologie du nitrure de gallium. g
