
 Périphériques technologiques
IA
Le classement des coûts d'inférence à grande échelle mené par la haute efficacité de Jia Yangqing est publié
Périphériques technologiques
IA
Le classement des coûts d'inférence à grande échelle mené par la haute efficacité de Jia Yangqing est publié
Le classement des coûts d'inférence à grande échelle mené par la haute efficacité de Jia Yangqing est publié

"Les API de grands modèles sont-elles une affaire déficitaire ?"
Avec la mise en pratique de la technologie des grands modèles de langage, de nombreuses entreprises technologiques ont lancé des API de grands modèles que les développeurs peuvent utiliser. Cependant, on ne peut s'empêcher de commencer à se demander si une entreprise basée sur de grands modèles peut être pérenne, d'autant plus qu'OpenAI dépense 700 000 $ par jour.
Ce jeudi, la startup d'IA Martian l'a soigneusement calculé pour nous.
Lien de classement : https://leaderboard.withmartian.com/
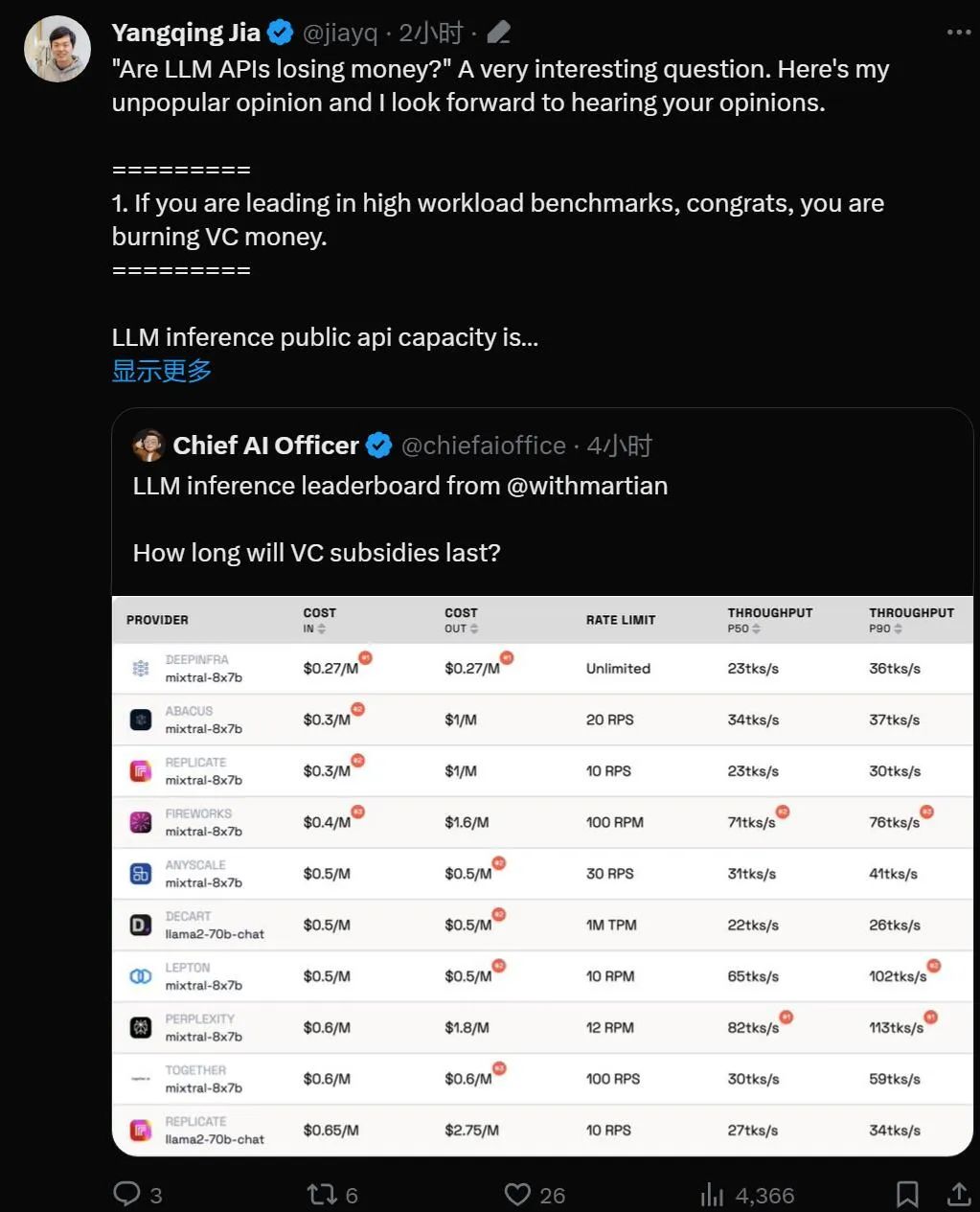
Le classement des fournisseurs d'inférence LLM est un classement open source de produits d'inférence API pour les grands modèles. Il évalue le coût et les limites de débit. , débit et P50 et P90 TTFT pour les points de terminaison publics Mixtral-8x7B et Llama-2-70B-Chat de chaque fournisseur.
Bien qu'ils soient en concurrence les uns avec les autres, Martian a constaté que les services de grand modèle de chaque entreprise sont coût, il existe des différences significatives en termes de débit et de limitation de débit. Ces différences dépassent la différence de coût 5x, la différence de débit 6x et les différences de limite de débit encore plus importantes. Le choix de différentes API est essentiel pour obtenir les meilleures performances, même si cela fait partie des activités commerciales.
Selon le classement actuel, le service fourni par Anyscale a le meilleur débit sous une charge de service moyenne de Llama-2-70B. Pour les charges de service importantes, Together AI a obtenu de meilleurs résultats avec les débits P50 et P90 sur Llama-2-70B et Mixtral-8x7B.
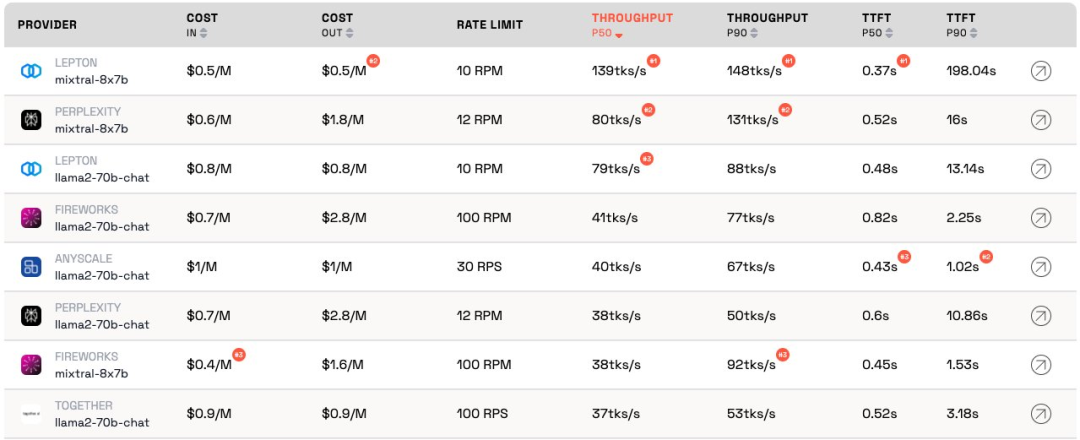
De plus, LeptonAI de Jia Yangqing a montré le meilleur débit lors de la gestion de petites charges de tâches avec des entrées courtes et des signaux de sortie longs. Son débit P50 de 130 tks/s est le plus rapide parmi les modèles actuellement proposés par tous les fabricants du marché.
Jia Yangqing, un spécialiste bien connu de l'IA et fondateur de Lepton AI, a commenté immédiatement après la publication du classement. Voyons ce qu'il a dit.

Jia Yangqing a d'abord expliqué l'état actuel de l'industrie dans le domaine de l'intelligence artificielle, puis a affirmé l'importance des tests de référence et a enfin souligné que LeptonAI aidera les utilisateurs à trouver la meilleure stratégie de base en matière d'IA.
1. L'API du grand modèle « brûle de l'argent »
Si le modèle est en tête dans les benchmarks à charge de travail élevée, alors félicitations, il « brûle de l'argent ».
LLM Raisonner sur la capacité d'une API publique, c'est comme gérer un restaurant : vous avez un chef et vous devez estimer le trafic client. Embaucher un chef coûte de l’argent. La latence et le débit peuvent être compris comme « la rapidité avec laquelle vous pouvez cuisiner pour les clients ». Pour une entreprise raisonnable, il faut un nombre « raisonnable » de chefs. En d’autres termes, vous souhaitez disposer d’une capacité capable de gérer le trafic normal, et non des rafales soudaines de trafic qui se produisent en quelques secondes. Une augmentation du trafic signifie attendre ; sinon, le « cuisinier » n'aura rien à faire.
Dans le monde de l'intelligence artificielle, le GPU joue le rôle de « chef ». Les charges de base sont éclatantes. Sous de faibles charges de travail, la charge de base est intégrée au trafic normal et les mesures fournissent une représentation précise de la façon dont le service fonctionne sous les charges de travail actuelles.
Les scénarios de charge de service élevée sont intéressants car ils provoquent des interruptions. Le benchmark n'est exécuté que quelques fois par jour/semaine, ce n'est donc pas le trafic régulier auquel on devrait s'attendre. Imaginez que 100 personnes se rendent dans votre restaurant local pour vérifier à quelle vitesse le chef cuisine. Les résultats seraient excellents. Pour emprunter la terminologie de la physique quantique, c’est ce qu’on appelle « l’effet observateur ». Plus l’interférence est forte (c’est-à-dire plus la charge d’éclatement est importante), plus la précision est faible. En d’autres termes : si vous imposez une charge soudaine et élevée à un service et constatez que le service répond très rapidement, vous savez que le service a une grande capacité inutilisée. En tant qu’investisseur, lorsque vous voyez cette situation, vous devriez vous demander : cette façon de brûler de l’argent est-elle responsable ?
2. Le modèle atteindra à terme des performances similaires
Le domaine de l'intelligence artificielle adore les compétitions, ce qui est effectivement intéressant. Tout le monde converge rapidement vers la même solution, et Nvidia finit toujours par gagner grâce au GPU. C'est grâce à d'excellents projets open source, vLLM en est un excellent exemple. Cela signifie qu'en tant que fournisseur, si votre modèle fonctionne bien moins bien que les autres, vous pouvez facilement rattraper votre retard en recherchant des solutions open source et en appliquant une bonne ingénierie.
3. "En tant que client, je ne me soucie pas du coût du fournisseur"
Pour les créateurs d'applications d'IA, nous avons de la chance : il y a toujours des fournisseurs d'API prêts à "brûler de l'argent". L'industrie de l'IA brûle de l'argent pour gagner du trafic, et la prochaine étape consiste à se soucier des profits.
Le benchmarking est une tâche fastidieuse et sujette aux erreurs. Pour le meilleur ou pour le pire, il arrive généralement que les gagnants vous félicitent et que les perdants vous blâment. Ce fut le cas lors de la dernière série d’analyses comparatives des réseaux neuronaux convolutifs. Ce n’est pas une tâche facile, mais l’analyse comparative nous aidera à multiplier par 10 l’infrastructure de l’IA.
Basé sur le cadre d'intelligence artificielle et l'infrastructure cloud, LeptonAI aidera les utilisateurs à trouver la meilleure stratégie de base en matière d'IA.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 CentOS8 redémarre SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 redémarre SSH
Apr 14, 2025 pm 09:00 PM
La commande pour redémarrer le service SSH est: SystemCTL Redémarrer SSHD. Étapes détaillées: 1. Accédez au terminal et connectez-vous au serveur; 2. Entrez la commande: SystemCTL Restart SSHD; 3. Vérifiez l'état du service: SystemCTL Status Sshd.
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
