
 Périphériques technologiques
IA
Le travail révolutionnaire de Transformer a été contesté, l'examen de l'ICLR a soulevé des questions ! Le public accuse les opérations de boîte noire, LeCun révèle une expérience similaire
Périphériques technologiques
IA
Le travail révolutionnaire de Transformer a été contesté, l'examen de l'ICLR a soulevé des questions ! Le public accuse les opérations de boîte noire, LeCun révèle une expérience similaire
Le travail révolutionnaire de Transformer a été contesté, l'examen de l'ICLR a soulevé des questions ! Le public accuse les opérations de boîte noire, LeCun révèle une expérience similaire

En décembre de l'année dernière, deux chercheurs de la CMU et de Princeton ont publié l'architecture Mamba, qui a instantanément choqué la communauté de l'IA !
En conséquence, ce document, qui devrait « renverser l'hégémonie de Transformer », s'est révélé aujourd'hui soupçonné d'être rejeté ? !
Ce matin, Sasha Rush, professeure agrégée à l'Université Cornell, a découvert pour la première fois que cet article qui devrait devenir un ouvrage fondateur semble avoir été rejeté par l'ICLR 2024.
et a dit : "Pour être honnête, je ne comprends pas. S'il est rejeté, quelle chance avons-nous".
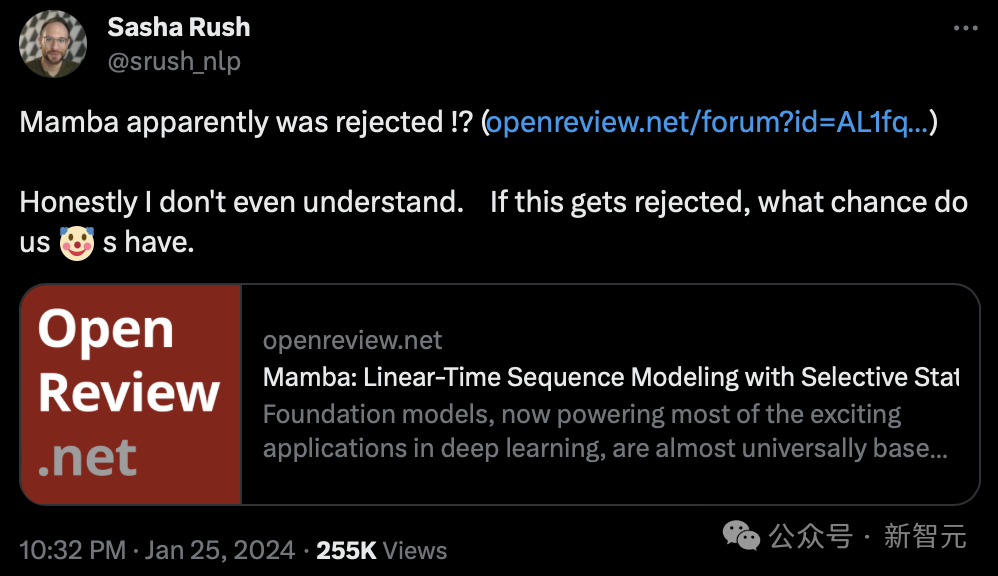
Comme vous pouvez le voir sur OpenReview, les notes attribuées par les quatre évaluateurs sont 3, 6, 8 et 8.
Bien que ce score ne puisse pas entraîner le rejet de l'article, un score aussi bas que 3 points est également scandaleux.
Niu Wen a marqué 3 points, et LeCun est même sorti pour crier
Cet article publié par deux chercheurs de la CMU et de l'Université de Princeton propose une nouvelle architecture Mamba.
Cette architecture SSM est comparable à Transformers en matière de modélisation de langage, et peut également évoluer de manière linéaire, tout en ayant 5 fois le débit d'inférence !

Adresse papier : https://arxiv.org/pdf/2312.00752.pdf
Dès que le document est sorti, il a directement choqué la communauté de l'IA De nombreuses personnes ont dit que l'architecture. qui a renversé Transformer est enfin né.
Maintenant, l’article de Mamba risque d’être rejeté, ce que beaucoup de gens ne peuvent pas comprendre.
Même le géant de Turing, LeCun, a participé à cette discussion, affirmant qu'il avait été confronté à une "injustice" similaire.
"Je pense qu'à l'époque, j'avais le plus de citations. Les articles que j'ai soumis sur Arxiv uniquement ont été cités plus de 1880 fois, mais ils n'ont jamais été acceptés."
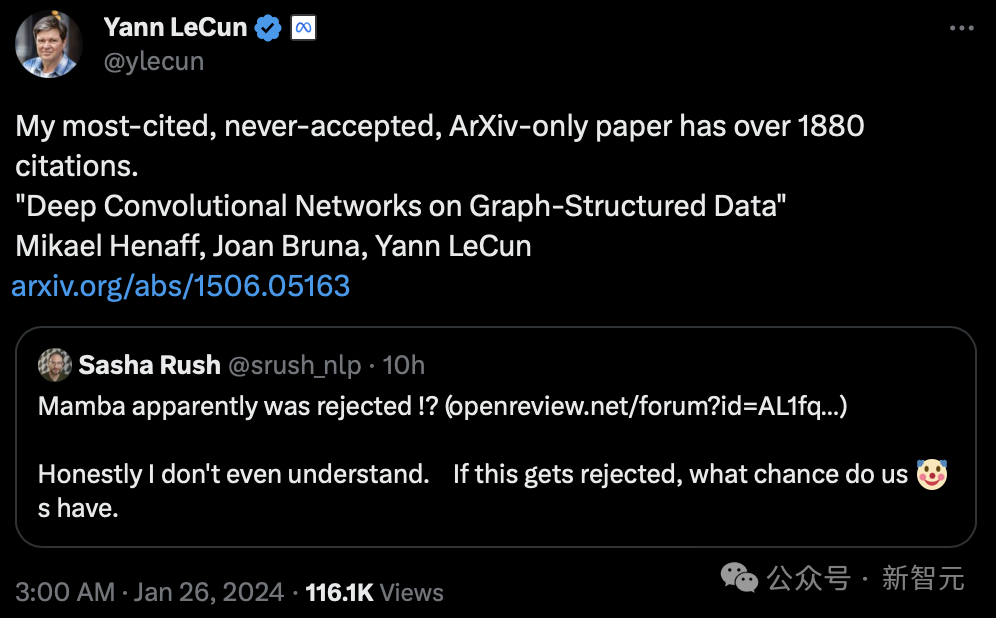
LeCun est célèbre pour ses travaux sur la reconnaissance optique de caractères et la vision par ordinateur utilisant les réseaux de neurones convolutifs (CNN), pour lesquels il a remporté le prix Turing en 2019.
Cependant, son article « Deep Convolutional Network Based on Graph Structure Data » publié en 2015 n'a jamais été accepté par la conférence.

Adresse papier : https://arxiv.org/pdf/1506.05163.pdf
Le chercheur en IA en apprentissage profond Sebastian Raschka a déclaré que malgré cela, Mamba a eu un impact profond sur la communauté de l'IA .
Une grande vague de recherches a récemment été dérivée de l'architecture Mamba, comme MoE-Mamba et Vision Mamba.

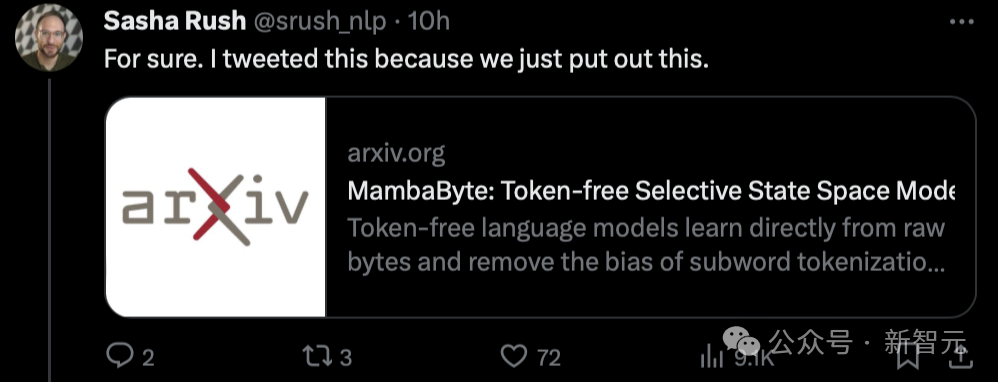
Fait intéressant, Sasha Rush, qui a annoncé que Mamba avait reçu un score faible, a également publié aujourd'hui un nouvel article basé sur de telles recherches - MambaByte.

En fait, l'architecture Mamba a déjà atteint le statut de « une seule étincelle peut allumer un feu de prairie », et son influence dans le cercle universitaire devient de plus en plus large.
Certains internautes ont déclaré que les journaux Mamba commenceraient à occuper arXiv.
"Par exemple, je viens de voir cet article proposant MambaByte, un modèle d'espace d'état sélectif sans jeton. En gros, il adapte Mamba SSM pour apprendre directement à partir des jetons originaux." Mamba Papers a également transmis cette recherche aujourd'hui.

Un article aussi populaire a reçu une note faible. Certaines personnes ont dit qu'il semble que les pairs évaluateurs ne prêtent pas vraiment attention au marketing.
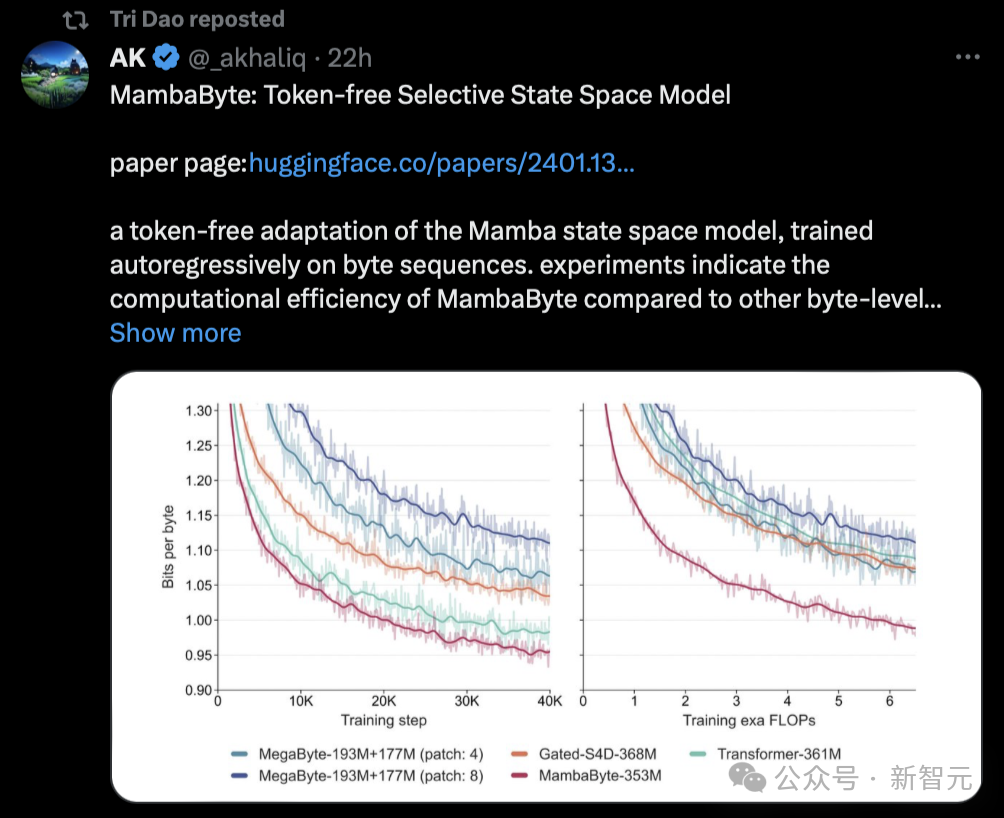
La raison pour laquelle l'article de Mamba a reçu une note de 3
 Quelle est la raison pour laquelle l'article de Mamba a reçu une note faible ?
Quelle est la raison pour laquelle l'article de Mamba a reçu une note faible ?
Vous pouvez constater que le critique qui a attribué à l'avis une note de 3 a un niveau de confiance de 5, ce qui signifie qu'il est très sûr de cette note.
Dans la revue, les questions qu'il a soulevées sont divisées en deux parties : l'une remet en question la conception du modèle et l'autre remet en question l'expérience.

- La motivation de conception de Mamba est de résoudre les lacunes du modèle de boucle tout en améliorant l'efficacité du modèle basé sur Transformer. Il existe de nombreuses études allant dans ce sens : S4-diagonal [1], SGConv [2], MEGA [3], SPADE [4] et de nombreux modèles de transformateurs efficaces (tels que [5]). Ces modèles atteignent tous une complexité quasi-linéaire, et les auteurs doivent comparer Mamba avec ces travaux en termes de performances et d'efficacité des modèles. Concernant les performances du modèle, quelques expériences simples (telles que la modélisation du langage sur Wikitext-103) suffisent. - De nombreux modèles Transformer basés sur l'attention présentent la capacité de généralisation de longueur, c'est-à-dire que le modèle peut être entraîné sur des longueurs de séquence plus courtes, puis testé sur des longueurs de séquence plus longues. Quelques exemples incluent le codage de position relative (T5) et l'alibi [6]. Puisque SSM est généralement continu, Mamba a-t-il cette capacité de généralisation de longueur ?
Expérience

- Les auteurs doivent comparer avec des lignes de base plus solides. Les auteurs reconnaissent que H3 a été utilisé comme motivation pour l'architecture du modèle. Cependant, ils n’ont pas été comparés expérimentalement au H3. Comme le montre le tableau 4 de [7], sur l'ensemble de données Pile, les ppl de H3 sont respectivement de 8,8 (125 M), 7,1 (355 M) et 6,0 (1,3 B), ce qui est bien meilleur que Mamba. Les auteurs doivent montrer une comparaison avec H3. - Pour le modèle pré-entraîné, l'auteur ne montre que les résultats de l'inférence zéro-shot. Cette configuration est assez limitée et les résultats ne démontrent pas très bien l'efficacité de Mamba. Je recommande aux auteurs de mener davantage d'expériences avec de longues séquences, telles que le résumé de documents, où les séquences d'entrée seront naturellement très longues (par exemple, la longueur moyenne des séquences de l'ensemble de données arXiv est supérieure à 8 ko).
- L'auteur affirme que l'une de ses principales contributions est la modélisation de séquences longues. Les auteurs devraient comparer avec davantage de références sur LRA (Long Range Arena), qui est fondamentalement la référence standard pour la compréhension des séquences longues.
- Benchmark de mémoire manquant. Bien que la section 4.5 soit intitulée « Benchmarks de vitesse et de mémoire », elle ne couvre que les comparaisons de vitesse. De plus, l'auteur doit fournir des paramètres plus détaillés sur le côté gauche de la figure 8, tels que les couches du modèle, la taille du modèle, les détails de convolution, etc. Les auteurs peuvent-ils fournir une explication intuitive sur la raison pour laquelle FlashAttention est le plus lent lorsque la longueur de la séquence est très grande (Figure 8 à gauche) ?
En réponse aux doutes du critique, l'auteur est également retourné faire ses devoirs et a proposé quelques données expérimentales pour réfuter.
Par exemple, concernant la première question sur la conception du modèle, l'auteur a déclaré que l'équipe avait l'intention de se concentrer sur la complexité de la pré-formation à grande échelle plutôt que sur les benchmarks à petite échelle.
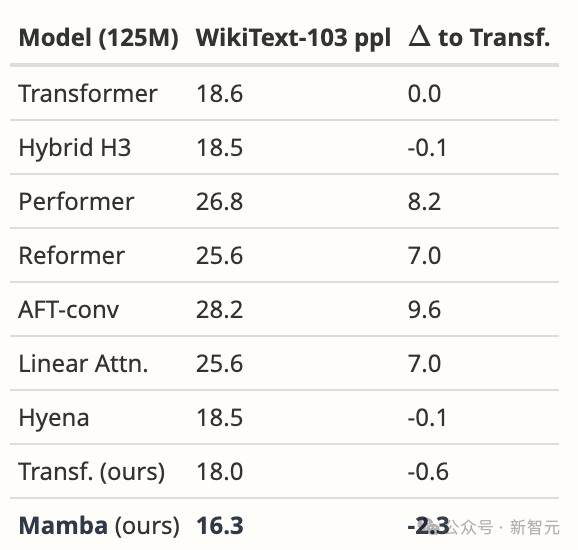
Néanmoins, Mamba surpasse considérablement tous les modèles proposés et plus encore sur WikiText-103, ce que nous attendrions de nos résultats généraux en langues.
Tout d'abord, nous avons comparé Mamba exactement dans le même environnement que le papier Hyena [Poli, Tableau 4.3]. En plus de leurs données rapportées, nous avons également ajusté notre propre base de référence solide pour Transformer.
Nous avons ensuite changé le modèle en Mamba, ce qui a amélioré de 1,7 personnes par rapport à notre Transformer et de 2,3 personnes par rapport au Transformer de base d'origine. Comme pour la plupart des modèles de séquence profonde (y compris FlashAttention), l'utilisation de la mémoire correspond uniquement à la taille du tenseur d'activation. En fait, Mamba est très économe en mémoire ; nous avons également mesuré les besoins en mémoire d'entraînement du modèle 125 Mo sur un GPU A100 de 80 Go. Chaque lot est constitué de séquences d'une longueur de 2048. Nous avons comparé cela à l'implémentation de Transformer la plus économe en mémoire que nous connaissons (fusion du noyau et FlashAttention-2 utilisant torch.compile).
Pour plus de détails sur les réfutations, veuillez consulter https://openreview.net/forum?id=AL1fq05o7H
En général, les commentaires des critiques ont été résolus par l'auteur. Cependant, ces réfutations Mais. ils ont tous été ignorés par les critiques.
 Quelqu'un a trouvé un « point » dans l'opinion de ce critique : Peut-être qu'il ne comprend pas ce qu'est le rnn ?
Quelqu'un a trouvé un « point » dans l'opinion de ce critique : Peut-être qu'il ne comprend pas ce qu'est le rnn ?
Les internautes qui ont regardé l'ensemble du processus ont déclaré que l'ensemble du processus était trop pénible à lire. L'auteur du journal a donné une réponse si approfondie, mais les critiques n'ont pas hésité du tout et n'ont pas réévalué.
Notez un 3 avec un niveau de confiance de 5 et ignorez la réfutation bien fondée de l'auteur. Ce genre de critique est trop ennuyeux. 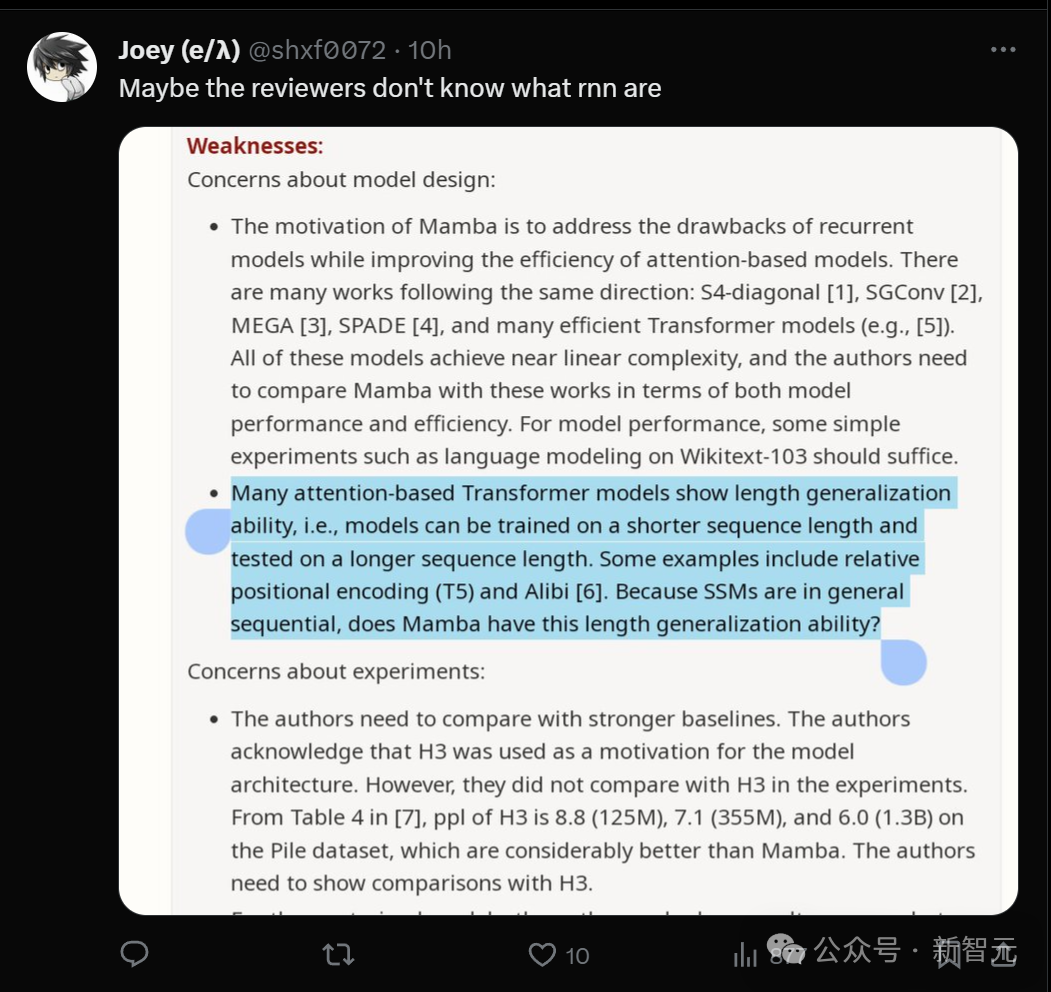
Les trois autres évaluateurs ont donné des notes élevées de 6, 8 et 8. 
Le critique qui a marqué 6 points a souligné que la faiblesse est "le modèle nécessite toujours de la mémoire secondaire comme Transformer pendant l'entraînement".
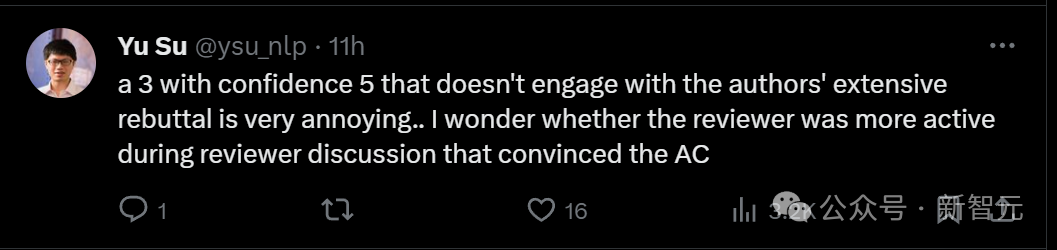
Le critique qui a obtenu 8 points a déclaré que la faiblesse de l'article est simplement "le manque de citations de certains ouvrages connexes".
Un autre critique qui a donné 8 points a fait l'éloge de l'article, affirmant que "la partie empirique est très approfondie et les résultats sont solides". 
Pas même trouvé de faiblesse.
Il devrait y avoir une explication à des classifications aussi divergentes. Mais il n’y a pas encore de commentaires des méta-réviseurs.
Les internautes ont crié : Le monde académique a également décliné !
Dans la zone de commentaires, quelqu'un a posé une question sur la torture de l'âme. Qui a obtenu un score aussi bas de 3 ? ?

De toute évidence, cet article a obtenu de meilleurs résultats avec des paramètres très bas, et le code GitHub est également clair et tout le monde peut le tester, il a donc été acclamé par le public, donc tout le monde est scandaleux.
Certains ont simplement crié WTF, même si l'architecture Mamba ne peut pas changer le schéma du LLM, c'est un modèle fiable avec de multiples usages sur de longues séquences. Obtenir ce score, cela signifie-t-il que le monde académique actuel est en déclin ?
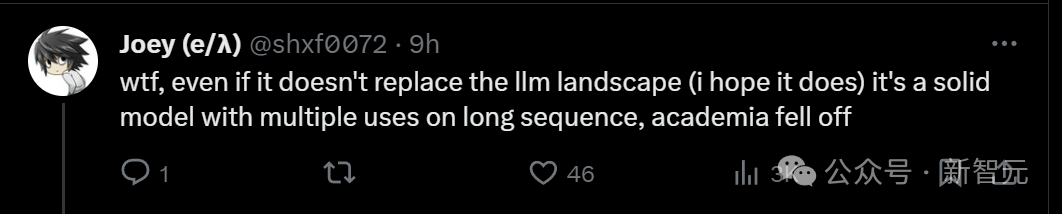
Tout le monde a dit avec émotion que heureusement, ce n'est qu'un des quatre commentaires. Les autres évaluateurs ont donné des notes élevées et la décision finale n'a pas encore été prise.
Certaines personnes pensent que l'évaluateur était peut-être trop fatigué et avait perdu son jugement.
Une autre raison est qu'une nouvelle direction de recherche telle que le modèle State Space peut menacer certains examinateurs et experts qui ont réalisé de grandes réalisations dans le domaine de Transformer.
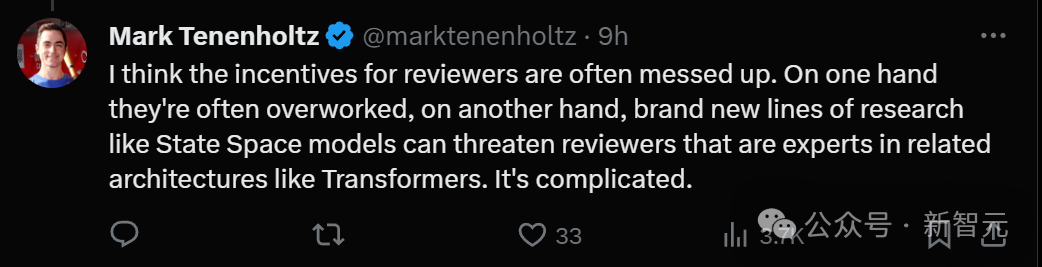
Certaines personnes disent que le papier de Mamba obtenant 3 points est simplement une blague dans l'industrie.
Ils sont tellement concentrés sur la comparaison de références folles et fines, mais la partie vraiment intéressante de l'article est l'ingénierie et l'efficacité. La recherche est en train de mourir parce que nous ne nous soucions que de SOTA, bien que sur des références obsolètes pour un sous-ensemble extrêmement restreint du domaine.
"Pas assez de théorie, trop de projets."

Actuellement, ce "mystère" n'a pas encore été révélé, et toute la communauté de l'IA attend un résultat.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Gérer les journaux Hadoop sur Debian, vous pouvez suivre les étapes et les meilleures pratiques suivantes: l'agrégation de journal Activer l'agrégation de journaux: définir yarn.log-aggregation-inable à true dans le fichier yarn-site.xml pour activer l'agrégation de journaux. Configurer la stratégie de rétention du journal: Définissez Yarn.log-agregation.retain-secondes pour définir le temps de rétention du journal, tel que 172800 secondes (2 jours). Spécifiez le chemin de stockage des journaux: via yarn.n
