

Il s'agit d'un cas partagé par M. Chen Hongyi (Old K) lors de la conférence MOORACLE de Shanghai en août 2016. En réécrivant un SQL de fusion en plsql, l'efficacité d'exécution a été grandement améliorée. Lorsque Tiger Liu a vu ce cas, il n'a d'abord pas remarqué le nombre réel d'enregistrements dans chaque tableau affiché dans le plan d'exécution. Il ne pensait pas que la façon de réécrire plsql était plus efficace que la façon d'écrire les fonctions analytiques. plusieurs discussions par courrier électronique avec le professeur Chen. Ce n'est que plus tard que j'ai examiné de plus près le plan d'exécution.
Le SQL d'origine est le suivant :fusionner dans t_customer c en utilisant
(
sélectionnez a.cstno, a.amount depuis t_trade a,
(sélectionnez cstno,max(trade_date) trade_date de t_trade
groupe par cstno) b
où a.cstno = b.cstno et a.trade_date=b.trade_date
) m
on(c.cstno = m.cstno)
quand correspond alors
mise à jour définie c.amount = m.amount;
Ce SQL consiste à mettre à jour le dernier montant de consommation dans la table des détails de la transaction utilisateur (t_trade) avec le champ du montant de consommation dans la table d'informations utilisateur (t_customer), en utilisant l'opération de fusion.
Plan d'exécution :

Note du Tigre Liu :
Avant de maîtriser la méthode d'écriture des fonctions analytiques, la partie rouge de SQL est une manière courante d'écrire d'autres informations de champ après le regroupement par, ce qui est également la raison fondamentale de la mauvaise efficacité d'exécution de ce SQL.
Il existe un autre danger caché dans le SQL d'origine, c'est-à-dire que si la trade_date maximale correspondant à un certain cstno de t_trade est répétée, alors ce SQL signalera une erreur ORA-30926 et ne pourra pas être exécuté.
Si vous ne regardez pas attentivement le plan d'exécution (les informations réelles sur le volume de données des deux tables), la méthode d'optimisation habituelle pour ce type de SQL consiste à utiliser des fonctions analytiques pour réécrire :
Méthode de réécriture 1 :fusionner dans t_customer c en utilisant
(
sélectionnez a.cstno,a.amount from
(sélectionnez trade_date,cstno,montant,
row_number()over(partition par cstno order by trade_date desc) RNO de t_trade)a
où RNO=1
) m
on(c.cstno = m.cstno)
quand correspond alors
mise à jour définie c.amount = m.amount;
Cette méthode de réécriture sera bien plus efficace que le SQL original, et il n'y aura aucun problème d'erreurs répétées pour le max trade_date correspondant à un certain cstno.
Mais le professeur Chen n'a pas utilisé la méthode de réécriture de la fonction analytique. Au lieu de cela, sur la base de la grande différence de volume de données entre les deux tables, il a réécrit le SQL en un plsql plus efficace :
Méthode de réécriture 2 :déclarer
numéro vamount ;
commencer
pour v in (sélectionnez * parmi t_customer)
boucle
sélectionnez le montant dans vamount à partir de
(sélectionnez le montant dans t_trade où cstno=v.cstno order by trade_date desc)
où numéro de rangée
mettre à jour le montant défini par t_customer = vamount où cstno=v.cstno;
fin de boucle
s'engager ;
fin;
/
Selon le plan d'exécution SQL d'origine, nous savons que le nombre d'enregistrements dans la table t_customer est relativement faible, seulement plus de 1 000, alors que la table t_trade compte 10 millions d'enregistrements, avec un ratio de 1:10 000 (je ne sais pas savoir s'il s'agit de données réelles ou de données de test, il n'y a que plus de 1 000 utilisateurs, et un utilisateur a en moyenne 10 000 détails de consommation, ce qui ne ressemble pas à des données réelles).
Dans un cas aussi particulier où les données entre les deux tables sont assez différentes, la méthode d'écriture plsql est en effet plus efficace que la méthode d'écriture de fonction analytique. Cette réécriture est très intelligente.
Analysons les avantages et les inconvénients de ces deux réécritures :1. La méthode de réécriture de plsql convient lorsque la table t_customer est relativement petite et que le rapport entre le nombre d'enregistrements dans les tables t_customer et t_trade est relativement grand, l'efficacité d'exécution sera supérieure à la réécriture de la fonction analytique. Dans cet exemple, si le nombre d'enregistrements dans la table t_customer est de 100 000, alors la manière d'écrire la fonction analytique est des dizaines à des centaines de fois plus rapide que la manière d'écrire plsql.
3. Le prérequis pour cette réécriture de plsql est qu'il doit y avoir un index conjoint des deux champs cstno + trade_date de la table t_trade. La réécriture des fonctions analytiques ne nécessite aucun support d'index.
4. Pour les tables contenant des dizaines de millions d'enregistrements comme t_trade, la méthode d'écriture utilisant les fonctions analytiques peut être accélérée en activant le parallélisme ; si vous souhaitez améliorer l'efficacité lors de la réécriture de plsql, vous devez d'abord regrouper la table t_customer par cstno et utilisez plusieurs sessions pour l’exécuter simultanément.
Voyons si le plsql du professeur Chen peut être implémenté avec un seul SQL. J'ai fait une tentative. Le code SQL est le suivant :
.fusionner dans t_customer c en utilisant
(
sélectionnez tc.cstno,
(sélectionnez le montant
de t_trade td1
où td1.cstno=tc.cstno et td1.trade_date = (sélectionnez max(trade_date) from t_trade td2 où tc.cstno = td2.cstno) et rownum=1 ) comme montant
de t_client tc
) m
on(c.cstno = m.cstno)
quand correspond alors
mise à jour définie c.amount = m.amount;
Le plan d'exécution est à peu près le suivant :
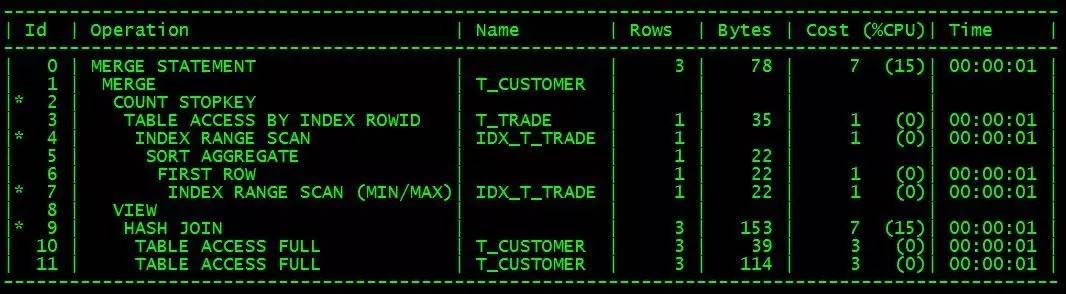
Cette méthode d'écriture nécessite également que l'index conjoint cstno+trade_date (IDX_T_TRADE) existe dans la table t_trade, et le volume de données de la table T_customer est bien inférieur à celui de T_trade.
Selon le plan d'exécution, l'efficacité d'exécution de ce sql devrait être comparable à l'efficacité de l'écriture de plsql.
Résumé :L'optimisation SQL, en plus d'éviter une écriture SQL inefficace, dépend principalement du volume de données et de la distribution des données de la table. La méthode de réécriture de plsql montrera une efficacité plus élevée dans quelques cas particuliers. l'efficacité peut ne pas être aussi bonne que celle du SQL d'origine. Cependant, les idées d’optimisation valent la peine d’être apprises.
La façon dont la fonction d'analyse est réécrite, quelle que soit la façon dont les données sont distribuées, sera plus efficace et plus polyvalente que le SQL d'origine.
De nombreux développeurs et administrateurs de bases de données devraient encore utiliser le SQL avant que cet exemple ne soit réécrit. Après avoir compris comment utiliser la fonction d'analyse, la manière inefficace d'écrire le SQL d'origine devrait être complètement abandonnée.
Le dernier plsql est réécrit en un seul SQL. La logique semble compliquée et difficile à comprendre. Généralement, une telle réécriture n'est pas utilisée. Ce serait bien si tout le monde la comprenait.
Toujours la même phrase, il n'y a pas de formule définitive d'optimisation. L'optimiseur est mort, mais le cerveau humain est vivant Ce n'est qu'en maîtrisant les principes que l'efficacité de l'exécution SQL peut devenir de plus en plus élevée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



