
 Périphériques technologiques
IA
Les internautes ont exposé la technologie d'intégration utilisée dans le nouveau modèle d'OpenAI
Périphériques technologiques
IA
Les internautes ont exposé la technologie d'intégration utilisée dans le nouveau modèle d'OpenAI
Les internautes ont exposé la technologie d'intégration utilisée dans le nouveau modèle d'OpenAI

Il y a quelques jours, OpenAI est arrivé avec une vague de mises à jour majeures, annonçant 5 nouveaux modèles à la fois, dont deux nouveaux modèles d'intégration de texte.
L'intégration est l'utilisation de séquences numériques pour représenter des concepts en langage naturel, code, etc. Ils aident les modèles d'apprentissage automatique et d'autres algorithmes à mieux comprendre les relations entre les contenus et facilitent l'exécution de tâches telles que le regroupement ou la récupération.
Généralement, l'utilisation de modèles d'intégration plus grands (tels que stockés dans la mémoire vectorielle pour la récupération) consomme plus de coûts, de puissance de calcul, de mémoire et de ressources de stockage. Cependant, les deux modèles d'intégration de texte lancés par OpenAI offrent des options différentes. Premièrement, le modèle text-embedding-3-small est un modèle plus petit mais efficace. Il peut être utilisé dans des environnements aux ressources limitées et fonctionne bien lors de la gestion des tâches d'intégration de texte. En revanche, le modèle text-embedding-3-large est plus grand et plus puissant. Ce modèle peut gérer des tâches d'intégration de texte plus complexes et fournir des représentations d'intégration plus précises et détaillées. Cependant, l’utilisation de ce modèle nécessite plus de ressources informatiques et d’espace de stockage. Par conséquent, en fonction des besoins spécifiques et des contraintes de ressources, un modèle approprié peut être sélectionné pour équilibrer la relation entre coût et performance.
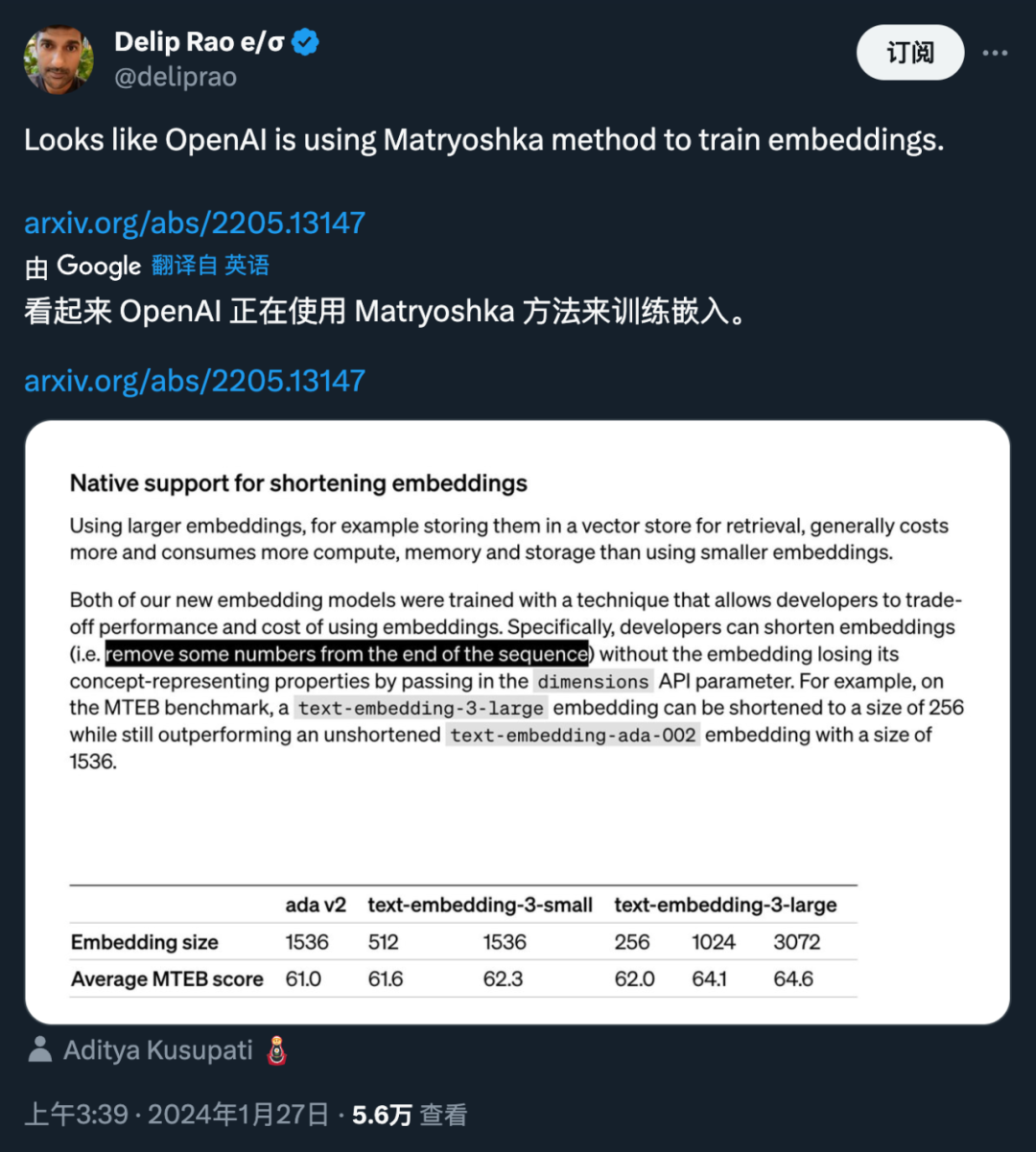
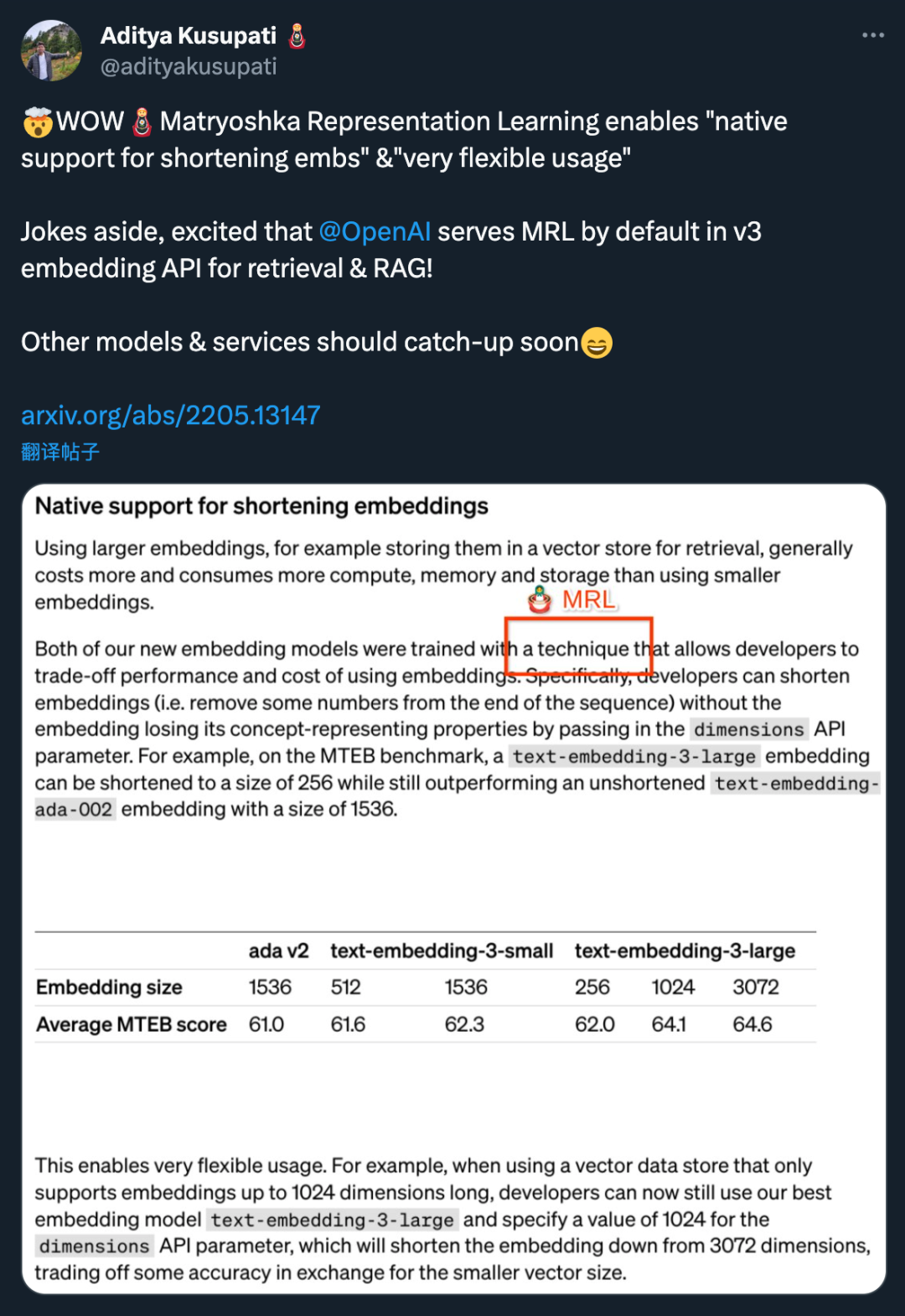
Les deux nouveaux modèles d'intégration sont réalisés à l'aide d'une technique de formation qui permet aux développeurs de faire un compromis entre les performances et le coût de l'intégration. Plus précisément, les développeurs peuvent réduire la taille de l'intégration sans perdre ses propriétés de représentation conceptuelle en transmettant l'intégration dans le paramètre API dimensions. Par exemple, sur le benchmark MTEB, text-embedding-3-large peut être raccourci à une taille de 256 mais surpasse toujours l'intégration text-embedding-ada-002 non raccourcie (de taille 1536). De cette manière, les développeurs peuvent choisir un modèle d'intégration approprié en fonction de besoins spécifiques, qui peut non seulement répondre aux exigences de performances, mais également contrôler les coûts.

L'application de cette technologie est très flexible. Par exemple, lors de l'utilisation d'un magasin de données vectorielles qui ne prend en charge que les intégrations jusqu'à 1 024 dimensions, un développeur peut sélectionner le meilleur modèle d'intégration text-embedding-3-large et modifier les dimensions d'intégration à partir de 3 072 en spécifiant une valeur de 1 024 pour l'API de dimensions. paramètre raccourci à 1024. Bien qu'une certaine précision puisse être sacrifiée en procédant ainsi, des tailles de vecteurs plus petites peuvent être obtenues.
La méthode « d'intégration raccourcie » utilisée par OpenAI a ensuite attiré l'attention des chercheurs.
Il a été constaté que cette méthode est la même que la méthode « Matryoshka Representation Learning » proposée dans un article de mai 2022.
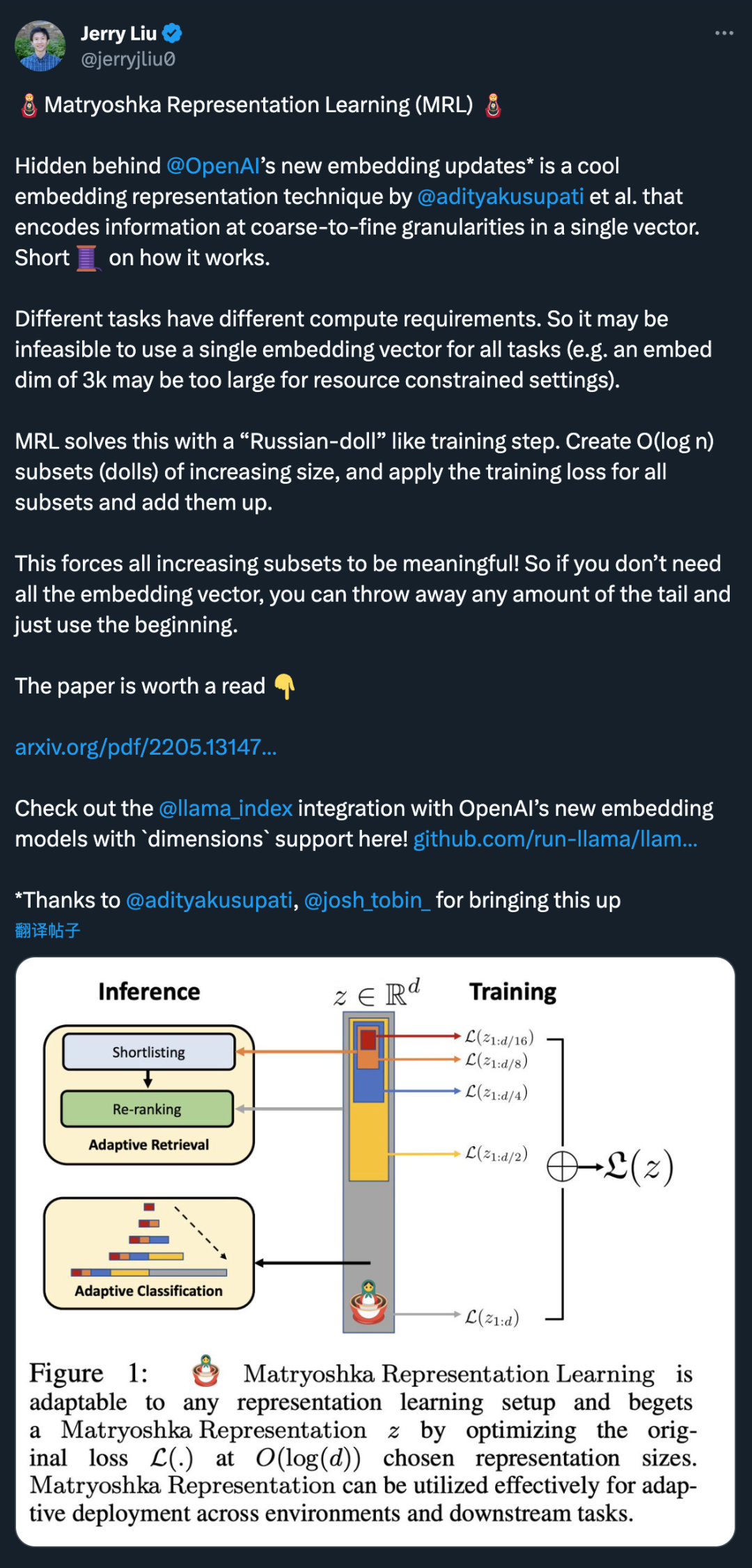
Derrière la nouvelle mise à jour du modèle d'intégration d'OpenAI se cache une technique de représentation d'intégration intéressante proposée par @adityakusupati et al.
Et Aditya Kusupati, l'un des auteurs de MRL, a également déclaré : "OpenAI utilise MRL par défaut dans l'API intégrée v3 pour la récupération et RAG ! D'autres modèles et services devraient bientôt rattraper leur retard
." Alors MRL, c'est quoi exactement ? Comment est l'effet ? Tout est dans le document 2022 ci-dessous.
MRL Paper Introduction

- Titre de l'article : Matryoshka Representation Learning
- Lien de l'article : https://arxiv.org/pdf/2205.13147.pdf
La question posée par les chercheurs est la suivante : une méthode de représentation flexible peut-elle être conçue pour s'adapter à plusieurs tâches en aval avec différentes ressources informatiques ?
MRL apprend les représentations de différentes capacités dans le même vecteur de haute dimension en optimisant explicitement les vecteurs de basse dimension O (log (d)) de manière imbriquée, d'où le nom Matryoshka. MRL peut être adapté à n’importe quel pipeline de représentation existant et peut être facilement étendu à de nombreuses tâches standard en vision par ordinateur et en traitement du langage naturel.
La figure 1 montre l'idée de base de MRL et le paramètre de déploiement adaptatif de la représentation Matriochka apprise :
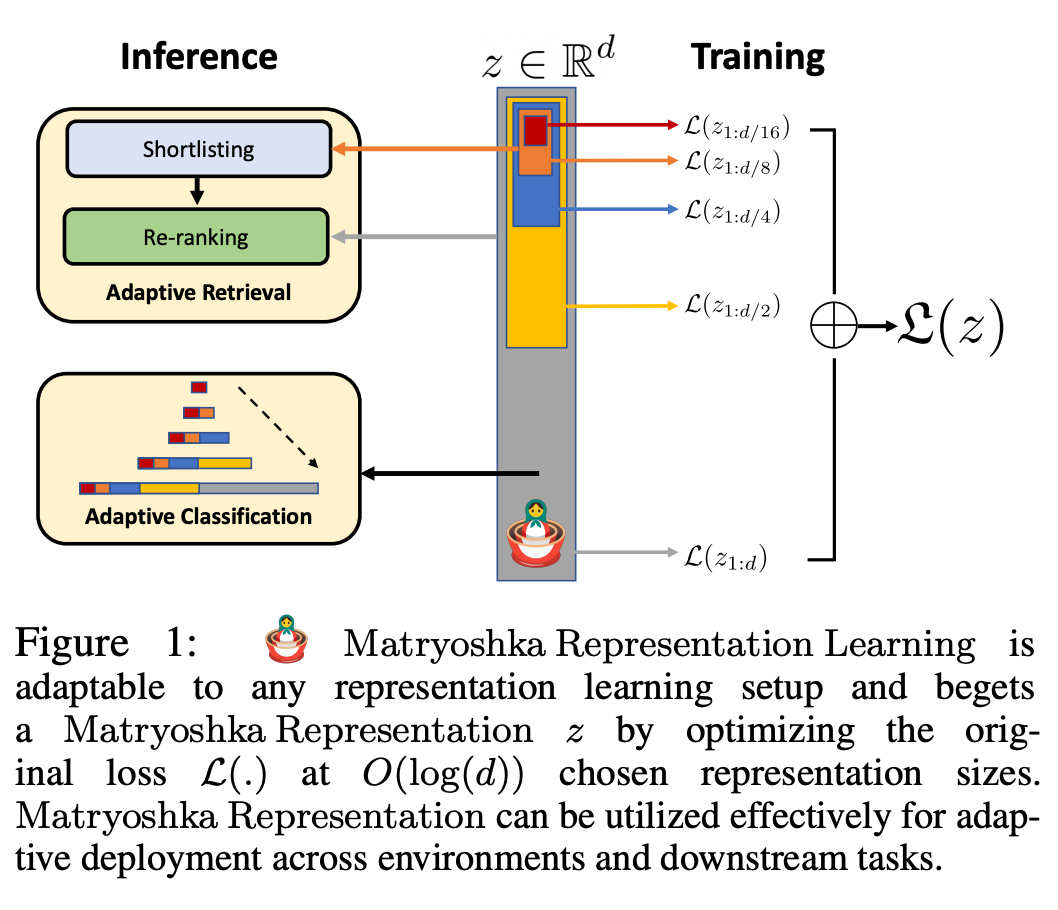
La première m-dimensions (m∈[d]) de la représentation Matriochka est une information- riche vecteur de faible dimension, aucun coût de formation supplémentaire n'est requis et sa précision n'est pas inférieure à celle de la méthode de représentation à m dimensions entraînée indépendamment. Le contenu informatif des représentations Matriochka augmente avec l'augmentation des dimensions, formant une représentation grossière à fine sans nécessiter une formation approfondie ni une surcharge de déploiement supplémentaire. MRL offre la flexibilité et la multi-fidélité requises pour caractériser les vecteurs, garantissant un compromis presque optimal entre précision et effort de calcul. Grâce à ces avantages, MRL peut être déployé de manière adaptative en fonction de la précision et des contraintes informatiques.
Dans ce travail, les chercheurs se concentrent sur deux éléments clés des systèmes de ML du monde réel : la classification et la récupération à grande échelle.
Pour la classification, les chercheurs ont utilisé des cascades adaptatives et des représentations de taille variable produites par des modèles entraînés par MRL, réduisant ainsi considérablement la dimension intégrée moyenne requise pour atteindre une précision spécifique. Par exemple, sur ImageNet-1K, la classification adaptative MRL + entraîne une réduction de la taille de la représentation jusqu'à 14x avec la même précision que la ligne de base.
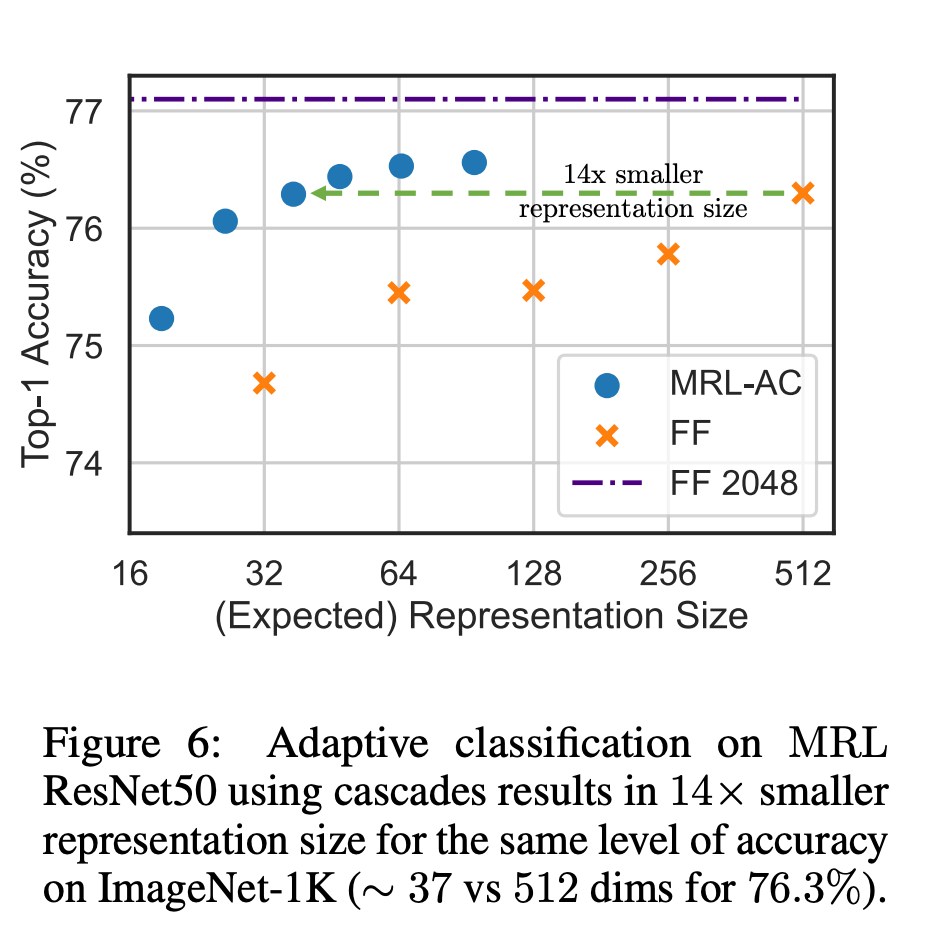
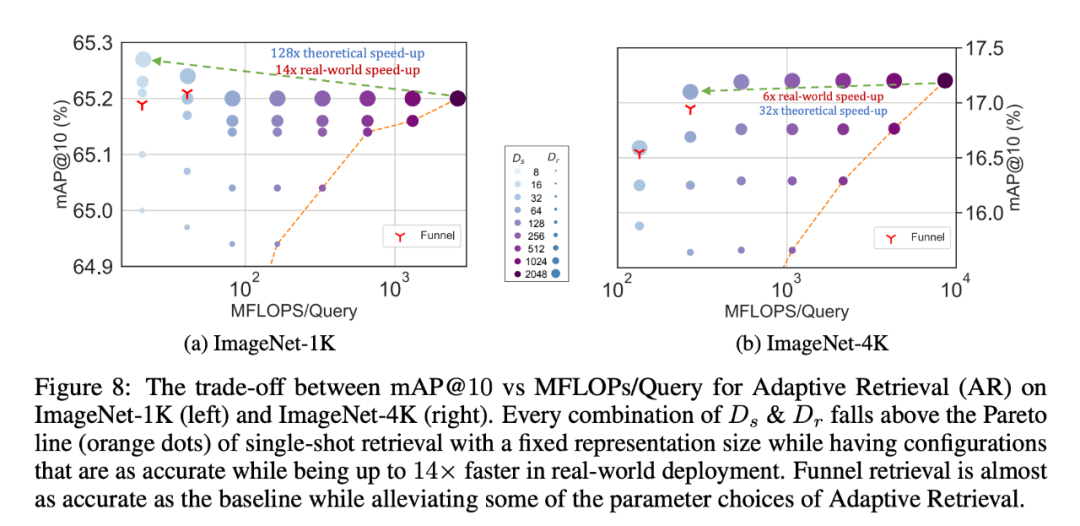
De même, les chercheurs ont également utilisé le MRL dans des systèmes de récupération adaptatifs. Étant donné une requête, les premières dimensions de l'intégration de la requête sont utilisées pour filtrer les candidats à la récupération, puis successivement d'autres dimensions sont utilisées pour réorganiser l'ensemble de récupération. Une mise en œuvre simple de cette approche atteint 128 fois la vitesse théorique (en FLOPS) et 14 fois le temps d'horloge murale par rapport à un seul système de récupération utilisant des vecteurs d'intégration standard. Il est important de noter que la précision de récupération de MRL est comparable à la précision de ; une seule récupération (Section 4.3.1).
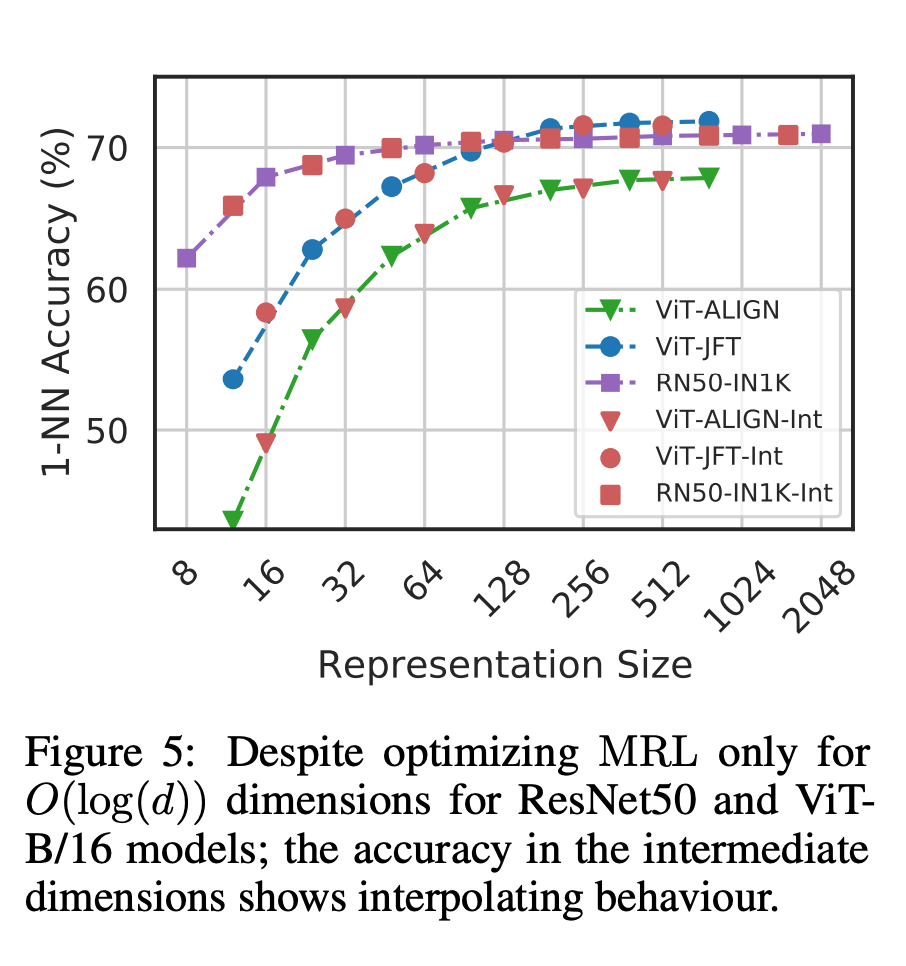
Enfin, puisque MRL apprend explicitement les vecteurs de représentation de grossier à fin, de manière intuitive, il devrait partager davantage d'informations sémantiques sur différentes dimensions (Figure 5). Cela se reflète dans les paramètres d'apprentissage continu à longue traîne, qui peuvent améliorer la précision jusqu'à 2 % tout en étant aussi robustes que les intégrations d'origine. De plus, en raison de la nature grossière à fine du MRL, il peut également être utilisé comme méthode pour analyser la facilité de classification des instances et les goulots d'étranglement des informations.
Pour plus de détails sur la recherche, veuillez vous référer au texte original de l'article.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Master la clause Order Order by dans SQL: Trier efficacement les données
Apr 08, 2025 pm 07:03 PM
Master la clause Order Order by dans SQL: Trier efficacement les données
Apr 08, 2025 pm 07:03 PM
Explication détaillée de la clause SqlorderBy: le tri efficace de la clause de données d'ordre de données est une déclaration clé de SQL utilisée pour trier les ensembles de résultats de requête. Il peut être organisé en ordre ascendant (ASC) ou ordre décroissant (DESC) dans des colonnes uniques ou plusieurs colonnes, améliorant considérablement la lisibilité des données et l'efficacité de l'analyse. OrderBy Syntax selectColumn1, Column2, ... FromTable_NameOrderByColumn_Name [ASC | DESC]; Column_name: Triez par colonne. ASC: Ascendance Order Sort (par défaut). DESC: Trier en ordre décroissant. ORDERBY Fonctionnalités principales: Tri multi-colonnes: prend en charge le tri de plusieurs colonnes et l'ordre des colonnes détermine la priorité du tri. depuis
 Navicat se connecte au code et à la solution d'erreur de base de données
Apr 08, 2025 pm 11:06 PM
Navicat se connecte au code et à la solution d'erreur de base de données
Apr 08, 2025 pm 11:06 PM
Erreurs et solutions courantes Lors de la connexion aux bases de données: nom d'utilisateur ou mot de passe (erreur 1045) Blocs de pare-feu Connexion (erreur 2003) Délai de connexion (erreur 10060) Impossible d'utiliser la connexion à socket (erreur 1042) Erreur de connexion SSL (erreur 10055) Trop de connexions Résultat de l'hôte étant bloqué (erreur 1129)
 Comment rédiger le dernier tutoriel sur la déclaration d'insertion SQL
Apr 09, 2025 pm 01:48 PM
Comment rédiger le dernier tutoriel sur la déclaration d'insertion SQL
Apr 09, 2025 pm 01:48 PM
L'instruction INSERT SQL est utilisée pour ajouter de nouvelles lignes à une table de base de données, et sa syntaxe est: Insérer dans Table_Name (Column1, Column2, ..., Columnn) VALEUR (VALEUR1, Value2, ..., Valuen);. Cette instruction prend en charge l'insertion de plusieurs valeurs et permet d'insérer des valeurs nulles dans des colonnes, mais il est nécessaire de s'assurer que les valeurs insérées sont compatibles avec le type de données de la colonne pour éviter de violer les contraintes d'unicité.
 Y a-t-il une procédure stockée dans MySQL
Apr 08, 2025 pm 03:45 PM
Y a-t-il une procédure stockée dans MySQL
Apr 08, 2025 pm 03:45 PM
MySQL fournit des procédures stockées, qui sont un bloc de code SQL précompilé qui résume la logique complexe, améliore la réutilisabilité du code et la sécurité. Ses fonctions principales incluent des boucles, des instructions conditionnelles, des curseurs et un contrôle des transactions. En appelant des procédures stockées, les utilisateurs peuvent effectuer des opérations de base de données en entrant et en sortie, sans prêter attention aux implémentations internes. Cependant, il est nécessaire de prêter attention à des problèmes communs tels que les erreurs de syntaxe, les problèmes d'autorisation et les erreurs logiques, et de suivre les principes d'optimisation des performances et de meilleures pratiques.
