
 Périphériques technologiques
IA
La fusion de plusieurs grands modèles hétérogènes apporte des résultats étonnants
Périphériques technologiques
IA
La fusion de plusieurs grands modèles hétérogènes apporte des résultats étonnants
La fusion de plusieurs grands modèles hétérogènes apporte des résultats étonnants

Avec le succès des grands modèles linguistiques tels que LLaMA et Mistral, de nombreuses entreprises ont commencé à créer leurs propres grands modèles linguistiques. Cependant, former un nouveau modèle à partir de zéro coûte cher et peut comporter des fonctionnalités redondantes.
Récemment, des chercheurs de l'Université Sun Yat-sen et du Tencent AI Lab ont proposé FuseLLM, qui est utilisé pour « fusionner plusieurs grands modèles hétérogènes ».
Différent des méthodes traditionnelles d'intégration de modèles et de fusion de poids, FuseLLM offre une nouvelle façon de fusionner les connaissances de plusieurs grands modèles de langage hétérogènes. Au lieu de déployer plusieurs grands modèles de langage en même temps ou de nécessiter la fusion des résultats du modèle, FuseLLM utilise une méthode légère de formation continue pour transférer les connaissances et les capacités de modèles individuels dans un grand modèle de langage fusionné. Ce qui est unique dans cette approche est sa capacité à utiliser plusieurs grands modèles de langage hétérogènes au moment de l'inférence et à externaliser leurs connaissances dans un modèle fusionné. De cette manière, FuseLLM améliore efficacement les performances et l'efficacité du modèle.
Cet article vient d'être publié sur arXiv et a attiré beaucoup d'attention et de transmission de la part des internautes.

Quelqu'un a pensé que ce serait intéressant de former un modèle sur une autre langue et j'y ai réfléchi.
Actuellement, cet article a été accepté par l'ICLR 2024.

- Titre de l'article : Fusion des connaissances des grands modèles de langage
- Adresse de l'article : https://arxiv.org/abs/2401.10491
- Entrepôt de papier : https://github.com/fanqiwan/FuseLLM
Introduction à la méthode
La clé de FuseLLM est d'explorer la fusion de grands modèles de langage du point de vue de la représentation de la distribution de probabilité pour la même entrée. texte, l'auteur Les représentations générées par différents grands modèles de langage sont censées refléter leurs connaissances intrinsèques dans la compréhension de ces textes. Par conséquent, FuseLLM utilise d'abord plusieurs grands modèles de langage sources pour générer des représentations, externalise leurs connaissances collectives et leurs avantages respectifs, puis intègre les multiples représentations générées pour se compléter, et enfin migre vers le grand modèle de langage cible grâce à une formation continue légère. La figure ci-dessous montre un aperçu de l'approche FuseLLM.
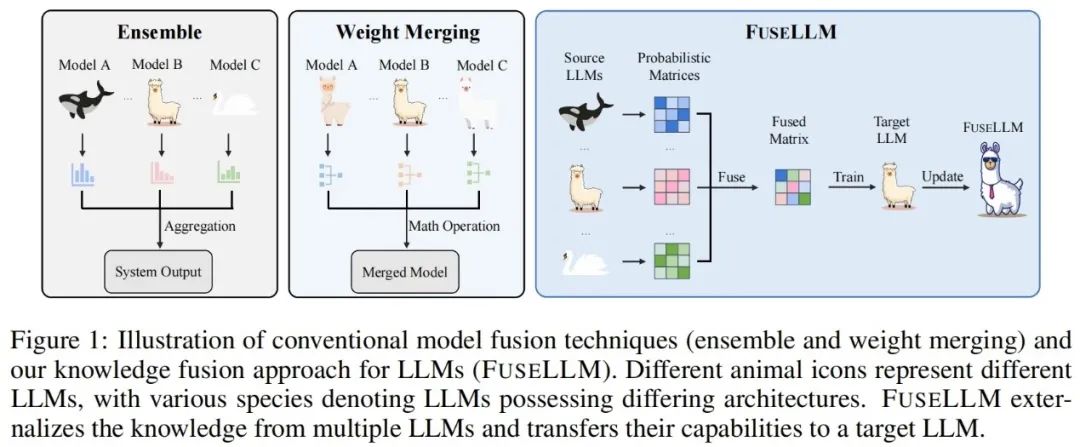
Compte tenu des différences entre les tokeniseurs et les listes de vocabulaire de plusieurs grands modèles de langage hétérogènes, la manière d'aligner les résultats de segmentation de mots est une clé lors de la fusion de plusieurs représentations : FuseLLM est basé sur une correspondance complète au niveau du vocabulaire. l'alignement basé sur la distance d'édition minimale est en outre conçu pour conserver au maximum les informations disponibles dans la représentation.
Afin de combiner la connaissance collective de plusieurs grands modèles de langage tout en conservant leurs avantages respectifs, les stratégies de représentations fusionnées générées par des modèles doivent être soigneusement conçues. Plus précisément, FuseLLM évalue dans quelle mesure différents grands modèles de langage comprennent ce texte en calculant l'entropie croisée entre la représentation générée et le texte de l'étiquette, puis introduit deux fonctions de fusion basées sur l'entropie croisée :
- MinCE : Input Multiple large les modèles génèrent des représentations pour le texte actuel et génèrent la représentation avec la plus petite entropie croisée
- AvgCE : saisissez les représentations générées par plusieurs grands modèles pour le texte actuel et générez une représentation moyenne pondérée basée sur le poids obtenu par croix ; entropie ;
Dans la phase de formation continue, FuseLLM utilise la représentation fusionnée comme cible pour calculer la perte de fusion, tout en conservant également la perte du modèle de langage. La fonction de perte finale est la somme de la perte de fusion et de la perte du modèle de langage.
Résultats expérimentaux
Dans la partie expérimentale, l'auteur considère un scénario de fusion de grands modèles de langage général mais difficile, où les modèles sources ont des points communs mineurs en termes de structure ou de capacités. Plus précisément, il a mené des expériences à l’échelle 7B et sélectionné trois modèles open source représentatifs : Llama-2, OpenLLaMA et MPT comme grands modèles à fusionner.
L'auteur a évalué FuseLLM dans des scénarios tels que le raisonnement général, le raisonnement de bon sens, la génération de code, la génération de texte et le suivi d'instructions, et a constaté qu'il obtenait des améliorations de performances significatives par rapport à tous les modèles sources et aux modèles de base de formation continue.
Raisonnement général et raisonnement de bon sens
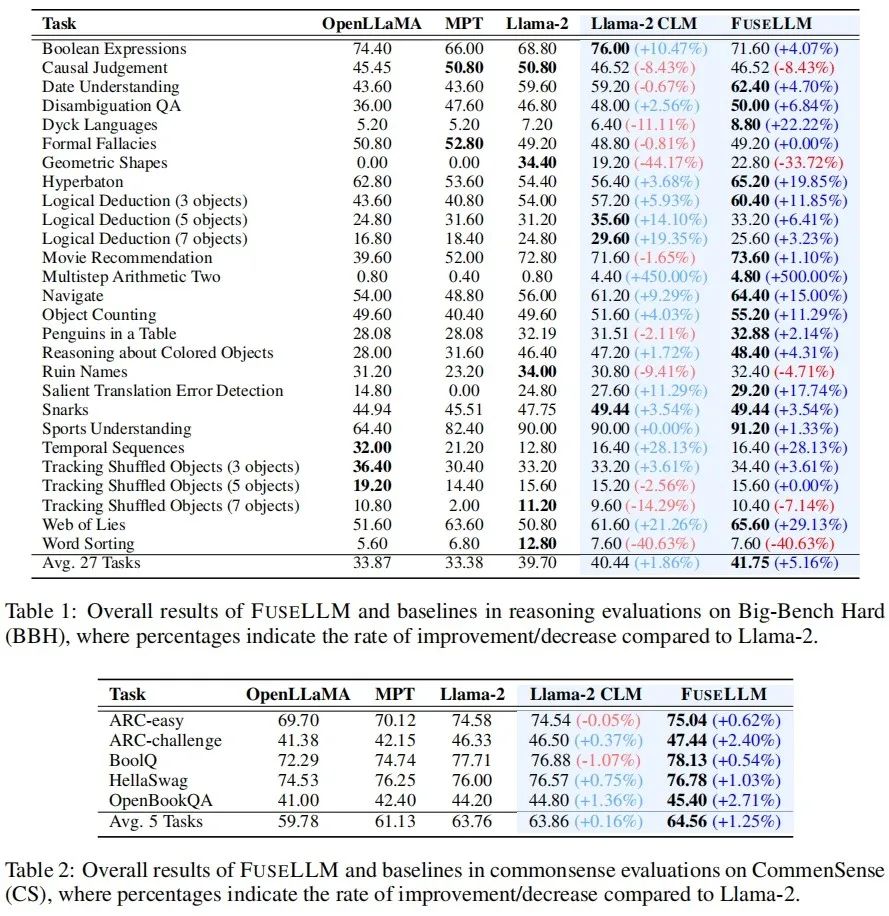
Sur le Big-Bench Hard Benchmark qui teste la capacité de raisonnement général, Llama-2 CLM après une formation continue est comparé à Llama-2 à 27 An une amélioration moyenne de 1,86 % a été obtenue sur chaque tâche, tandis que FuseLLM a obtenu une amélioration de 5,16 % par rapport à Llama-2, ce qui est nettement meilleur que Llama-2 CLM, indiquant que FuseLLM peut combiner les avantages de plusieurs grands modèles de langage pour atteindre Amélioration des performances. .
Sur le Common Sense Benchmark, qui teste la capacité de raisonnement de bon sens, FuseLLM a surpassé tous les modèles sources et modèles de base, obtenant les meilleures performances sur toutes les tâches.
Génération de code et génération de texte

Sur le benchmark MultiPL-E qui teste les capacités de génération de code, FuseLLM a surpassé Llama-2 dans 9 tâches sur 10, atteignant une amélioration moyenne des performances de 6,36%. La raison pour laquelle FuseLLM ne dépasse pas MPT et OpenLLaMA peut être due à l'utilisation de Llama-2 comme grand modèle de langage cible, qui a de faibles capacités de génération de code et une faible proportion de données de code dans le corpus de formation continue, représentant seulement environ 7,59%.
Sur plusieurs tests de génération de texte mesurant la réponse aux questions de connaissances (TrivialQA), la compréhension en lecture (DROP), l'analyse de contenu (LAMBADA), la traduction automatique (IWSLT2017) et l'application du théorème (SciBench), FuseLLM dépasse également dans toutes les tâches surpassé toutes les sources. modèles et a surpassé Llama-2 CLM dans 80 % des tâches.
Instruction suivie

Étant donné que FuseLLM n'a besoin que d'extraire les représentations de plusieurs modèles sources pour la fusion, puis d'entraîner en continu le modèle cible, il peut également être utilisé pour affiner de grands modèles de langage avec instructions Fusion. Sur le Vicuna Benchmark, qui évalue la capacité à suivre les instructions, FuseLLM a également atteint d'excellentes performances, surpassant tous les modèles sources et CLM.
FuseLLM vs. Distillation des connaissances, intégration de modèles et fusion de poids
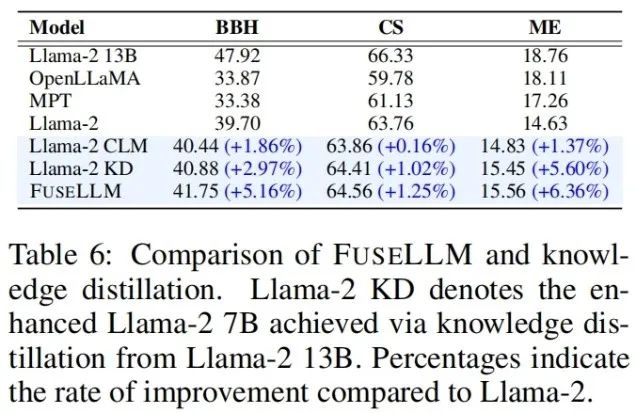
Considérant que la distillation des connaissances est également une méthode permettant d'utiliser la représentation pour améliorer les performances des grands modèles de langage, l'auteur combine FuseLLM et Llama-2 13B distillé Llama-2 KD a été comparé. Les résultats montrent que FuseLLM surpasse la distillation à partir d'un seul modèle 13B en fusionnant trois modèles 7B avec des architectures différentes.

Pour comparer FuseLLM avec les méthodes de fusion existantes (telles que l'ensemble de modèles et la fusion de poids), les auteurs ont simulé un scénario dans lequel plusieurs modèles sources provenaient d'un modèle de base de la même structure, mais étaient continuellement formés sur différents corpus. , et testé la perplexité de diverses méthodes sur différents benchmarks de test. On peut voir que bien que toutes les techniques de fusion puissent combiner les avantages de plusieurs modèles sources, FuseLLM peut atteindre la perplexité moyenne la plus faible, ce qui indique que FuseLLM a le potentiel de combiner la connaissance collective des modèles sources plus efficacement que les méthodes d'ensemble de modèles et de fusion de poids.
Enfin, bien que la communauté s'intéresse actuellement à la fusion de grands modèles, les approches actuelles sont principalement basées sur la fusion de poids et ne peuvent pas être étendues à des scénarios de fusion de modèles de différentes structures et tailles. Bien que FuseLLM ne soit qu'une recherche préliminaire sur la fusion de modèles hétérogènes, étant donné qu'il existe actuellement un grand nombre de grands modèles linguistiques, visuels, audio et multimodaux de structures et de tailles différentes dans la communauté technique, quelle sera la fusion de ces modèles hétérogènes ? éclater dans le futur ? attendons de voir !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Gérer les journaux Hadoop sur Debian, vous pouvez suivre les étapes et les meilleures pratiques suivantes: l'agrégation de journal Activer l'agrégation de journaux: définir yarn.log-aggregation-inable à true dans le fichier yarn-site.xml pour activer l'agrégation de journaux. Configurer la stratégie de rétention du journal: Définissez Yarn.log-agregation.retain-secondes pour définir le temps de rétention du journal, tel que 172800 secondes (2 jours). Spécifiez le chemin de stockage des journaux: via yarn.n
