

Knowledge graph : le partenaire idéal des grands modèles

Les modèles linguistiques à grande échelle (LLM) ont la capacité de générer des textes fluides et cohérents, ouvrant de nouvelles perspectives dans des domaines tels que le dialogue sur l'intelligence artificielle et l'écriture créative. Cependant, le LLM présente également certaines limites clés. Premièrement, leurs connaissances se limitent aux modèles reconnus à partir des données de formation, sans une véritable compréhension du monde. Deuxièmement, les capacités de raisonnement sont limitées et ne peuvent pas faire de déductions logiques ni fusionner des faits provenant de plusieurs sources de données. Face à des questions plus complexes et ouvertes, les réponses de LLM peuvent devenir absurdes ou contradictoires, ce que l'on appelle des « illusions ». Par conséquent, bien que le LLM soit très utile à certains égards, il présente néanmoins certaines limites lorsqu’il s’agit de problèmes complexes et de situations du monde réel.
Pour combler ces lacunes, des systèmes de génération augmentée de récupération (RAG) ont vu le jour ces dernières années, dont l'idée principale est de fournir un contexte au LLM en récupérant des connaissances pertinentes auprès de sources externes pour apporter des réponses plus éclairées. Les systèmes actuels utilisent principalement la similarité sémantique des intégrations vectorielles pour récupérer des passages. Cependant, cette approche présente ses propres inconvénients, tels que le manque de véritable corrélation, l'incapacité d'agréger les faits et le manque de chaînes d'inférence. Les domaines d’application des graphes de connaissances peuvent résoudre ces problèmes. Le graphe de connaissances est une représentation structurée d'entités et de relations du monde réel. En codant les interconnexions entre les faits contextuels, les graphiques de connaissances surmontent les inconvénients de la recherche vectorielle pure, et la recherche graphique permet un raisonnement complexe à plusieurs niveaux sur plusieurs sources d'informations.
La combinaison de l'intégration de vecteurs et du graphe de connaissances peut améliorer la capacité de raisonnement du LLM et améliorer sa précision et son interprétabilité. Ce partenariat allie parfaitement la sémantique de surface avec des connaissances et une logique structurées, permettant à LLM d'appliquer simultanément l'apprentissage statistique et la représentation symbolique.
 Images
Images
1. Limites de la recherche vectorielle
La plupart des systèmes RAG trouvent le contexte du LLM grâce à la recherche vectorielle de passages dans une collection de documents. Il y a plusieurs étapes clés dans ce processus.
- Encodage de texte : le système utilise un modèle d'intégration tel que BERT pour encoder le texte des paragraphes du corpus en représentations vectorielles. Chaque article est compressé dans un vecteur dense pour capturer la sémantique.
- Index : ces vecteurs de canaux sont indexés dans un espace vectoriel de grande dimension pour permettre des recherches rapides du voisin le plus proche. Les méthodes populaires incluent Faiss et Pinecone, entre autres.
- Encodage de requête : l'instruction de requête de l'utilisateur est également codée dans une représentation vectorielle en utilisant le même modèle d'intégration.
- Récupération de similarité : une recherche du voisin le plus proche est effectuée sur les paragraphes indexés, trouvant les paragraphes les plus proches du vecteur de requête en fonction d'une métrique de distance (telle que la distance cosinus).
- Renvoyer les résultats du paragraphe : renvoie le vecteur de paragraphe le plus similaire, extrayez le texte original pour fournir un contexte au LLM.
Ce pipeline présente plusieurs limitations majeures :
- les vecteurs de canal peuvent ne pas capturer complètement l'intention sémantique de la requête, les intégrations ne peuvent pas représenter certaines connexions d'inférence et un contexte important finit par être ignoré.
- Condenser un paragraphe entier en un seul vecteur perdra sa nuance et les principaux détails pertinents intégrés dans la phrase deviendront flous.
- La correspondance est effectuée indépendamment pour chaque paragraphe, il n'y a pas d'analyse conjointe entre les différents paragraphes, et il y a un manque de faits de connexion et de réponses qui doivent être regroupées.
- Le processus de classement et d'appariement est opaque et il n'y a aucune transparence pour expliquer pourquoi certains passages sont considérés comme plus pertinents.
- Seule la similarité sémantique est codée, et il n'y a aucune représentation des relations, structures, règles et autres contenus entre différentes connexions.
- Une focalisation unique sur la similarité des vecteurs sémantiques conduit à un manque de réelle compréhension en matière de récupération.
À mesure que les requêtes deviennent plus complexes, ces limitations deviennent de plus en plus apparentes dans l'incapacité de raisonner sur le contenu récupéré.
2. Intégrer le graphe de connaissances
Le graphe de connaissances est basé sur des entités et des relations, transmet des informations via des réseaux interconnectés et améliore les capacités de récupération grâce à un raisonnement complexe.
- Faits explicites Les faits sont capturés directement sous forme de nœuds et de bords plutôt que compressés en vecteurs opaques, ce qui préserve les détails critiques.
- Détails du contexte, les entités contiennent des attributs riches, tels que des descriptions, des alias et des métadonnées qui fournissent un contexte clé.
- La structure du réseau exprime les connexions réelles, les règles de capture, les hiérarchies, les chronologies, etc. entre les entités de modélisation des relations.
- Le raisonnement à plusieurs niveaux est basé sur le parcours des relations et la connexion de faits provenant de différentes sources pour obtenir des réponses qui nécessitent un raisonnement en plusieurs étapes.
- Le raisonnement conjoint est lié aux mêmes objets du monde réel grâce à la résolution d'entités, permettant une analyse collective.
- Corrélation interprétable, la topologie graphique offre une transparence qui peut expliquer pourquoi certains faits basés sur sont pertinents en fonction de connexions.
- Personnalisation, capture des attributs des utilisateurs, du contexte et des interactions historiques pour adapter les résultats.
Le graphe de connaissances n'est pas simplement une simple correspondance, mais un processus de parcours du graphe pour collecter des faits contextuels liés à la requête. Les méthodes de classement interprétables exploitent la topologie des graphiques pour améliorer les capacités de récupération en codant des faits structurés, des relations et un contexte, permettant ainsi un raisonnement précis en plusieurs étapes. Cette approche offre une plus grande corrélation et un plus grand pouvoir explicatif par rapport aux recherches vectorielles pures.
3. Utiliser des contraintes simples pour améliorer l'intégration des graphes de connaissancesL'intégration de graphes de connaissances dans un espace vectoriel continu est un point chaud de la recherche actuelle. Les graphes de connaissances utilisent des intégrations vectorielles pour représenter des entités et des relations afin de prendre en charge les opérations mathématiques. De plus, des contraintes supplémentaires peuvent optimiser davantage la représentation.
- Les contraintes de non-négativité, limitant les intégrations d'entités à des valeurs positives comprises entre 0 et 1 conduisent à la parcimonie, modélisent explicitement leur nature positive et améliorent l'interprétabilité.
- Les contraintes d'implication codent directement des règles logiques telles que la symétrie, l'inversion, la composition, etc. dans des contraintes relationnellement intégrées pour appliquer ces modèles.
- Modélisation de la confiance, contraintes souples avec des variables slack peuvent coder la confiance de règles logiques basées sur des preuves.
- La régularisation, qui impose un biais inductif utile et ajoute seulement une étape de projection sans rendre l'optimisation plus complexe.
- Interprétabilité et contraintes structurées assurent la transparence des modèles appris par le modèle, ce qui explique le processus d'inférence.
- La précision, la contrainte améliore la généralisation en réduisant l'espace des hypothèses à une représentation qui répond aux exigences.
Des contraintes simples et universelles sont ajoutées à l'intégration du graphe de connaissances, ce qui donne une représentation plus optimisée, plus facile à interpréter et logiquement compatible. Les intégrations obtiennent des biais inductifs qui imitent les structures et les règles du monde réel sans introduire beaucoup de complexité supplémentaire pour un raisonnement plus précis et interprétable.
4. Intégrer plusieurs cadres de raisonnementLe graphe de connaissances nécessite un raisonnement pour dériver de nouveaux faits, répondre à des questions et faire des prédictions. Différentes technologies ont des avantages complémentaires :
Les règles logiques expriment les connaissances sous forme d'axiomes et d'ontologies logiques, raisonnables et raisonnement complet à travers des preuves de théorèmes et un traitement limité des incertitudes. L'intégration de graphiques est une structure de graphe de connaissances intégrée utilisée pour les opérations spatiales vectorielles, qui peut gérer l'incertitude mais manque d'expressivité. Les réseaux de neurones combinés aux recherches vectorielles sont adaptatifs, mais l'inférence est opaque. Des règles peuvent être créées automatiquement grâce à une analyse statistique de la structure des graphiques et des données, mais leur qualité est incertaine. Les pipelines hybrides codent des contraintes explicites via des règles logiques, les intégrations fournissent des opérations spatiales vectorielles et les réseaux de neurones bénéficient des avantages de la fusion grâce à une formation conjointe. Utilisez des méthodes de logique basées sur des cas, floues ou probabilistes pour accroître la transparence, exprimer l'incertitude et la confiance dans les règles. Étendez les connaissances en incorporant les faits déduits et les règles apprises dans des graphiques, fournissant ainsi une boucle de rétroaction.
La clé est d'identifier les types d'inférence requis et de les mapper aux techniques appropriées, en combinant des formes logiques, des représentations vectorielles et des pipelines composables de composants neuronaux pour fournir robustesse et interprétabilité.
4.1 Maintenir le flux d'informations de LLM
La récupération de faits dans le graphe de connaissances pour LLM introduit des goulots d'étranglement d'informations qui doivent être maintenus par la conception pour maintenir la pertinence. Diviser le contenu en petits morceaux améliore l'isolement mais perd le contexte environnant, ce qui entrave le raisonnement entre les morceaux. La génération de résumés de blocs fournit un contexte plus concis, avec des détails clés condensés pour mettre en évidence la signification. Joignez des résumés, des titres, des balises, etc. en tant que métadonnées pour maintenir le contexte du contenu source. La réécriture de la requête originale dans une version plus détaillée permet de mieux cibler la récupération sur les besoins du LLM. La fonction de parcours du graphe de connaissances maintient la connexion entre les faits et maintient le contexte. Le tri chronologique ou par pertinence peut optimiser la structure de l'information du LLM, et la conversion des connaissances implicites en faits explicites énoncés pour le LLM peut faciliter le raisonnement.
L'objectif est d'optimiser la pertinence, le contexte, la structure et l'expression explicite des connaissances récupérées pour maximiser les capacités de raisonnement. Il faut trouver un équilibre entre granularité et cohésion. Les relations entre les graphes de connaissances aident à créer un contexte pour des faits isolés.
4.2 Débloquez les capacités de raisonnement
La combinaison des graphiques de connaissances et de la technologie embarquée a l'avantage de surmonter les faiblesses de chacun.
Le graphe de connaissances fournit une expression structurée des entités et des relations. Améliorez les capacités de raisonnement complexes grâce à des fonctions de parcours et gérez le raisonnement à plusieurs niveaux ; l'intégration code des informations pour des opérations basées sur la similarité dans l'espace vectoriel, prend en charge une recherche approximative efficace à une certaine échelle et fait apparaître des modèles potentiels. Le codage conjoint génère des intégrations pour les entités et les relations dans les graphes de connaissances. Les réseaux de neurones graphiques fonctionnent sur des structures graphiques et des éléments intégrés via la transmission de messages différenciables.
Le graphe de connaissances collecte d'abord des connaissances structurées, puis intègre une recherche et une récupération axées sur le contenu associé. Les relations explicites du graphe de connaissances offrent une interprétabilité pour le processus de raisonnement. Les connaissances déduites peuvent être étendues aux graphiques, et les GNN permettent l'apprentissage de représentations continues.
Ce partenariat se reconnaît à travers des motifs ! L'évolutivité des forces et des réseaux de neurones améliore la représentation des connaissances structurées. C’est la clé du besoin d’apprentissage statistique et de logique symbolique pour faire progresser l’IA linguistique.
4.3 Utiliser le filtrage collaboratif pour améliorer la recherche
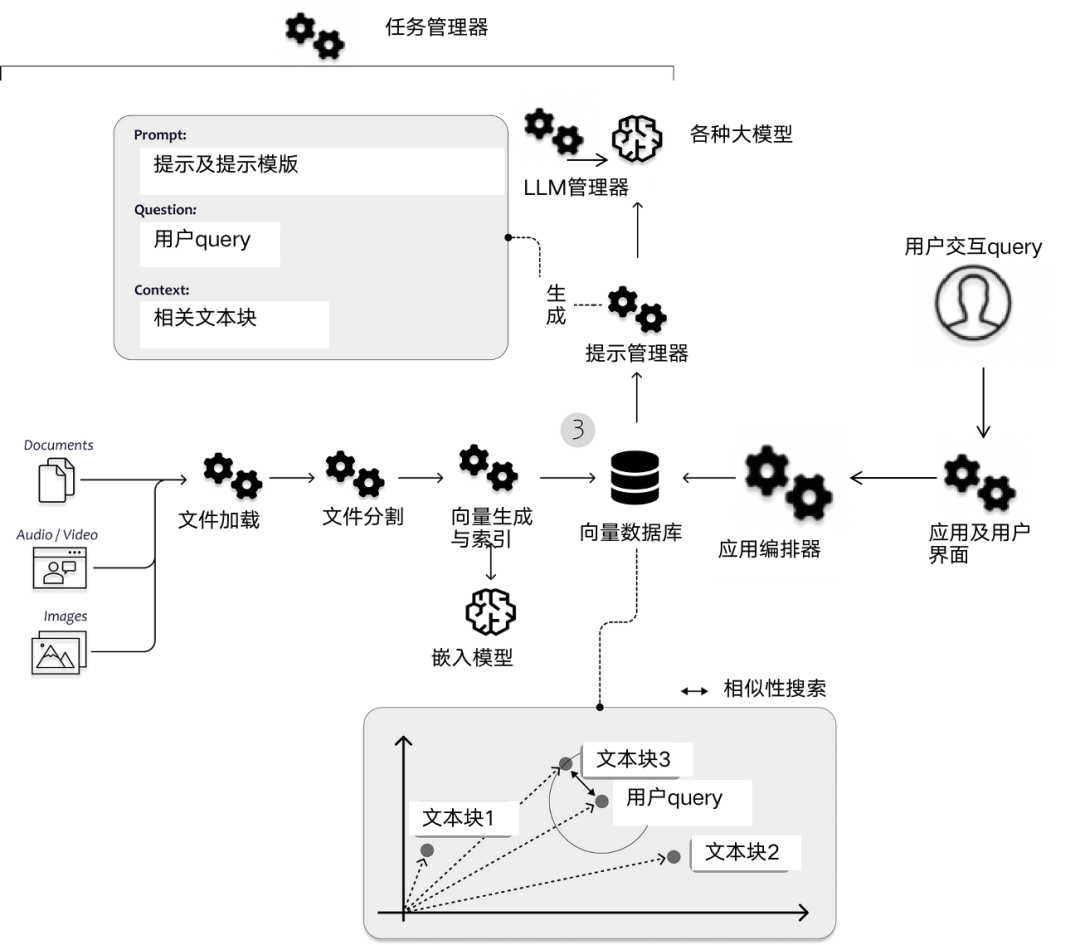
Le filtrage collaboratif utilise les connexions entre les entités pour améliorer la recherche. Le processus général est le suivant :
- Construisez un graphe de connaissances dans lequel les nœuds représentent des entités et les bords représentent des relations.
- Générez un vecteur d'intégration pour certains attributs de nœud clés (tels que le titre, la description, etc.).
- Vector Index - Construit un index de similarité vectorielle des intégrations de nœuds.
- Recherche du voisin le plus proche - Pour une requête de recherche, recherchez les nœuds avec les intégrations les plus similaires.
- Ajustement collaboratif - Connexions basées sur des nœuds, utilisant des algorithmes comme le PageRank pour propager et ajuster les scores de similarité.
- Poids du bordーAjustez le poids en fonction du type de bord, de la force, de la confiance, etc.
- Normalisation des scores ーーNormalise les scores ajustés pour maintenir les classements relatifs.
- Résultats réorganisésーーRésultats initiaux réorganisés en fonction des scores de collaboration ajustés.
- Contexte utilisateurーーaffiné en fonction du profil, de l'historique et des préférences de l'utilisateur.
 Photos
Photos
5. Alimenter le moteur RAG – Volant de données
Construire un système de génération d'augmentation de récupération (RAG) hautes performances en constante amélioration peut nécessiter la mise en œuvre d'un volant de données. Les graphes de connaissances débloquent de nouvelles capacités de raisonnement pour les modèles de langage en fournissant des connaissances structurées du monde. Toutefois, la création de cartes de haute qualité reste un défi. C’est là qu’intervient le volant de données, améliorant continuellement le graphe de connaissances en analysant les interactions du système.
Enregistrez toutes les requêtes, réponses, scores, actions des utilisateurs et plus encore du système pour fournir une visibilité sur la façon dont le graphique de connaissances est utilisé, utilisez l'agrégation de données pour faire apparaître les mauvaises réponses, regroupez et analysez ces réponses pour identifier les modèles qui indiquent des lacunes dans les connaissances. Examinez manuellement les réponses problématiques du système et tracez les problèmes jusqu'aux faits manquants ou incorrects dans la carte. Ensuite, modifiez directement le graphique pour ajouter les données factuelles manquantes, améliorer la structure, améliorer la clarté, et bien plus encore. Les étapes ci-dessus sont complétées dans une boucle continue et chaque itération améliore encore le graphe de connaissances.
La diffusion en continu de sources de données en temps réel telles que les actualités et les réseaux sociaux fournit un flux constant de nouvelles informations pour maintenir le graphique des connaissances à jour. L’utilisation de la génération de requêtes pour identifier et combler les lacunes critiques en matière de connaissances dépasse la portée de ce qu’offre le streaming. Trouvez des trous dans le graphique, posez des questions, récupérez les faits manquants et ajoutez-les. Pour chaque cycle, le graphique de connaissances est progressivement amélioré en analysant les modèles d'utilisation et en résolvant les problèmes de données. Le graphique amélioré améliore les performances du système.
Ce processus de volant d'inertie permet aux graphiques de connaissances et aux modèles de langage de co-évoluer en fonction des retours d'utilisation du monde réel. Les cartes sont activement modifiées pour répondre aux besoins du modèle.
En bref, le volant de données fournit un échafaudage pour l'amélioration continue et automatique du graphe de connaissances en analysant les interactions du système. Cela renforce la précision, la pertinence et l’adaptabilité des modèles de langage dépendants des graphes.
6. Résumé
L'intelligence artificielle doit combiner connaissances externes et raisonnement, c'est là qu'intervient le graphe de connaissances. Les graphes de connaissances fournissent des représentations structurées d'entités et de relations du monde réel, codant des faits sur le monde et les connexions entre eux. Cela permet un raisonnement logique complexe sur plusieurs étapes en parcourant ces faits interdépendants
Cependant, les graphiques de connaissances ont leurs propres limites, comme la rareté et le manque de gestion de l'incertitude, et c'est là que les intégrations de graphiques facilitent la localisation. En codant les éléments du graphe de connaissances dans l'espace vectoriel, les intégrations permettent un apprentissage statistique à partir de grands corpus jusqu'à des représentations de modèles latents, et permettent également des opérations efficaces basées sur la similarité.
Ni le graphe de connaissances ni l'intégration de vecteurs ne suffisent à eux seuls pour former une intelligence linguistique de type humain, mais ensemble, ils fournissent une combinaison efficace de représentation structurée des connaissances, de raisonnement logique et d'apprentissage statistique, et le graphe de connaissances couvre le modèle de réseau neuronal Au-delà la capacité de reconnaître la logique et les relations symboliques, des techniques telles que les réseaux de neurones graphiques unifient davantage ces approches grâce à des structures et des intégrations de graphiques de transfert d'informations. Cette relation symbiotique permet au système d'utiliser à la fois l'apprentissage statistique et la logique symbolique, combinant les avantages des réseaux neuronaux et de la représentation structurée des connaissances.
Il existe encore des défis dans la création de graphiques de connaissances de haute qualité, de tests de référence, de traitement du bruit, etc. Cependant, les technologies hybrides couvrant les réseaux symboliques et neuronaux restent prometteuses. À mesure que les graphes de connaissances et les modèles linguistiques continuent de se développer, leur intégration ouvrira de nouveaux domaines d’IA explicable.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Selon les informations de ce site Web du 5 juillet, GlobalFoundries a publié un communiqué de presse le 1er juillet de cette année, annonçant l'acquisition de la technologie de nitrure de gallium (GaN) et du portefeuille de propriété intellectuelle de Tagore Technology, dans l'espoir d'élargir sa part de marché dans l'automobile et Internet. des objets et des domaines d'application des centres de données d'intelligence artificielle pour explorer une efficacité plus élevée et de meilleures performances. Alors que des technologies telles que l’intelligence artificielle générative (GenerativeAI) continuent de se développer dans le monde numérique, le nitrure de gallium (GaN) est devenu une solution clé pour une gestion durable et efficace de l’énergie, notamment dans les centres de données. Ce site Web citait l'annonce officielle selon laquelle, lors de cette acquisition, l'équipe d'ingénierie de Tagore Technology rejoindrait GF pour développer davantage la technologie du nitrure de gallium. g
