
 Périphériques technologiques
IA
Grands modèles multimodaux Kuaishou et Beida : les images sont des langues étrangères, comparables à la percée de DALLE-3
Périphériques technologiques
IA
Grands modèles multimodaux Kuaishou et Beida : les images sont des langues étrangères, comparables à la percée de DALLE-3
Grands modèles multimodaux Kuaishou et Beida : les images sont des langues étrangères, comparables à la percée de DALLE-3

Segmentation visuelle dynamique des mots, représentation graphique et textuelle unifiée, Kuaishou et l'Université de Pékin ont coopéré pour proposer le modèle de base LaVIT pour brosser la liste des tâches de compréhension et de génération multimodales.
Les modèles linguistiques actuels à grande échelle tels que GPT, LLaMA, etc. ont fait des progrès significatifs dans le domaine du traitement du langage naturel et sont capables de comprendre et de générer du contenu textuel complexe. Pour autant, avons-nous envisagé de transférer cette puissante capacité de compréhension et de génération aux données multimodales ? Cela nous permettra de donner facilement un sens à d’énormes quantités d’images et de vidéos et de créer un contenu richement illustré. Pour réaliser cette vision, Kuaishou et l'Université de Pékin ont récemment collaboré pour développer un nouveau grand modèle multimodal appelé LaVIT. LaVIT transforme progressivement cette idée en réalité et nous attendons avec impatience son développement ultérieur.

Titre de l'article : Pré-formation unifiée en langage-vision en LLM avec tokenisation visuelle discrète dynamique
Adresse de l'article : https://arxiv.org/abs/2309.04669
Adresse du modèle de code : https : //github.com/jy0205/LaVIT
Présentation du modèle
LaVIT est un nouveau modèle de base multimodal général, similaire à un modèle de langage, qui peut comprendre et générer du contenu visuel. Le paradigme de formation de LaVIT s'appuie sur l'expérience réussie de grands modèles de langage et utilise une approche autorégressive pour prédire le prochain jeton d'image ou de texte. Après la formation, LaVIT peut servir d’interface universelle multimodale capable d’effectuer des tâches de compréhension et de génération multimodales sans ajustement supplémentaire. Par exemple, LaVIT a les capacités suivantes :
LaVIT est un modèle de génération d'images avancé qui peut générer des formats d'image multiples de haute qualité et des images très esthétiques basées sur des invites de texte. Les capacités de génération d'images de LaVIT se comparent avantageusement aux modèles de génération d'images de pointe tels que Parti, SDXL et DALLE-3. Il peut efficacement générer du texte en image de haute qualité, offrant aux utilisateurs plus de choix et une meilleure expérience visuelle.

Génération d'images basée sur des invites multimodales : étant donné que dans LaVIT, les images et les textes sont uniformément représentés sous forme de jetons discrétisés, il peut accepter plusieurs combinaisons modales (telles que texte, image + texte, image + image) comme invite pour générer l’image correspondante sans aucun réglage fin.

Comprendre le contenu de l'image et répondre aux questions : étant donné une image d'entrée, LaVIT est capable de lire le contenu de l'image et de comprendre sa sémantique. Par exemple, le modèle peut fournir des légendes pour les images d'entrée et répondre aux questions correspondantes.

Présentation de la méthode
La structure du modèle de LaVIT est présentée dans la figure ci-dessous. L'ensemble de son processus d'optimisation comprend deux étapes :
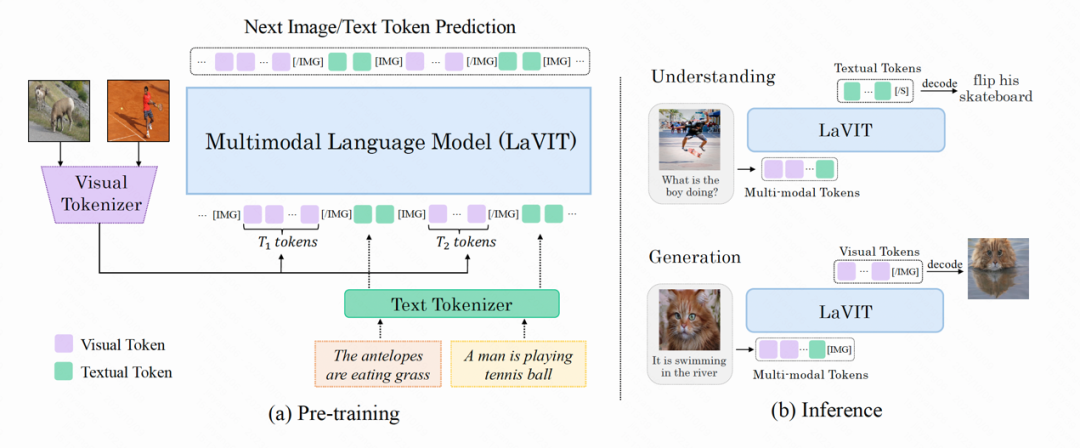
Figure : L'architecture globale du modèle LaVIT
.Phase 1 : Dynamic Visual Tokenizer
Afin de pouvoir comprendre et générer du contenu visuel comme le langage naturel, LaVIT introduit un tokenizer visuel bien conçu pour convertir le contenu visuel (signaux continus) en séquences de jetons comme le texte, tout comme Comme les langues étrangères que LLM peut comprendre. L'auteur estime que pour parvenir à une vision unifiée et à une modélisation du langage, le tokenizer visuel (Tokenizer) doit avoir les deux caractéristiques suivantes :
Discrétisation : les jetons visuels doivent être représentés sous des formes discrétisées comme le texte. Cela utilise une forme de représentation unifiée pour les deux modalités, ce qui permet à LaVIT d'utiliser la même perte de classification pour l'optimisation de la modélisation multimodale dans un cadre de formation générative autorégressive unifié.
Dynamicification : contrairement aux jetons de texte, les correctifs d'image ont des interdépendances importantes entre eux, ce qui rend relativement simple la déduction d'un correctif à partir d'un autre. Par conséquent, cette dépendance réduit l’efficacité de l’objectif d’optimisation de la prédiction du prochain jeton du LLM d’origine. LaVIT propose de réduire la redondance entre les correctifs visuels en utilisant la fusion de jetons, qui code un nombre dynamique de jetons visuels en fonction de la complexité sémantique différente des différentes images. De cette manière, pour des images de complexité différente, l'utilisation du codage dynamique des jetons améliore encore l'efficacité du pré-entraînement et évite les calculs de jetons redondants.
La figure suivante est la structure visuelle du segmenteur de mots proposée par LaVIT :
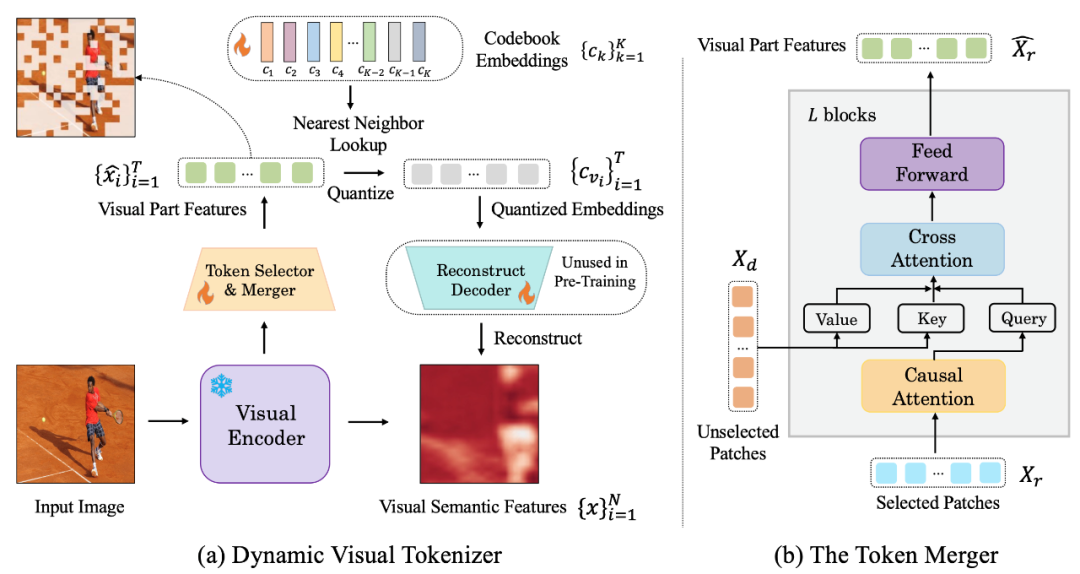
Figure : (a) Générateur de jetons visuels dynamiques (b) combinateur de jetons
Le tokeniseur visuel dynamique comprend un sélecteur de jetons et un combinateur de jetons. Comme le montre la figure, le sélecteur de jetons est utilisé pour sélectionner les blocs d'images les plus informatifs, tandis que la fusion de jetons compresse les informations de ces blocs visuels non informatifs dans les jetons conservés pour réaliser la fusion des jetons redondants. L'ensemble du segmenteur de mots visuel dynamique est entraîné en maximisant la reconstruction sémantique de l'image d'entrée.
Sélecteur de jetons
Le sélecteur de jetons reçoit N fonctionnalités au niveau du bloc d'image en entrée. Son objectif est d'évaluer l'importance de chaque bloc d'image et de sélectionner le bloc contenant le plus d'informations pour représenter pleinement la sémantique entière. Pour atteindre cet objectif, un module léger composé de plusieurs couches MLP est utilisé pour prédire la distribution π. En échantillonnant à partir de la distribution π, un masque de décision binaire est généré qui indique s'il faut conserver le patch d'image correspondant.
Combinateur de jetons
Le combinateur de jetons divise N blocs d'images en deux groupes : conservez X_r et supprimez X_d en fonction du masque de décision généré. Contrairement à la suppression directe de X_d, le combinateur de jetons peut préserver au maximum la sémantique détaillée de l'image d'entrée. Le combinateur de jetons se compose de L blocs empilés, dont chacun comprend une couche d'auto-attention causale, une couche d'attention croisée et une couche de rétroaction. Dans la couche d'auto-attention causale, chaque jeton de X_r ne prête attention qu'à son jeton précédent pour garantir la cohérence avec la forme du jeton de texte dans LLM. Cette stratégie est plus performante que l’auto-attention bidirectionnelle. La couche d'attention croisée prend le jeton conservé X_r comme requête et fusionne les jetons dans X_d en fonction de leur similarité sémantique.
Phase 2 : Pré-formation générative unifiée
Les jetons visuels traités par le segmenteur de mots visuel sont connectés aux jetons de texte pour former une séquence multimodale comme entrée pendant la formation. Afin de distinguer les deux modalités, l'auteur insère des jetons spéciaux au début et à la fin de la séquence de jetons d'image : [IMG] et [/IMG], qui servent à indiquer le début et la fin du contenu visuel. Afin de pouvoir générer du texte et des images, LaVIT utilise deux formes de connexion image-texte : [image, texte] et [texte ;
Pour ces séquences d'entrée multimodales, LaVIT utilise une approche unifiée et autorégressive pour maximiser directement la probabilité de chaque séquence multimodale pour la pré-entraînement. Cette unification complète de l'espace de représentation et des méthodes de formation aide LLM à mieux apprendre l'interaction et l'alignement multimodaux. Une fois la pré-formation terminée, LaVIT a la capacité de percevoir des images et peut comprendre et générer des images comme du texte.
Expériences
Compréhension multimodale sans tir
LaVIT a obtenu des résultats de pointe sur des tâches de compréhension multimodale sans tir telles que la génération de légendes d'images (NoCaps, Flickr30k) et la réponse visuelle aux questions (VQAv2 , OKVQA, GQA, VizWiz) Performances de pointe.
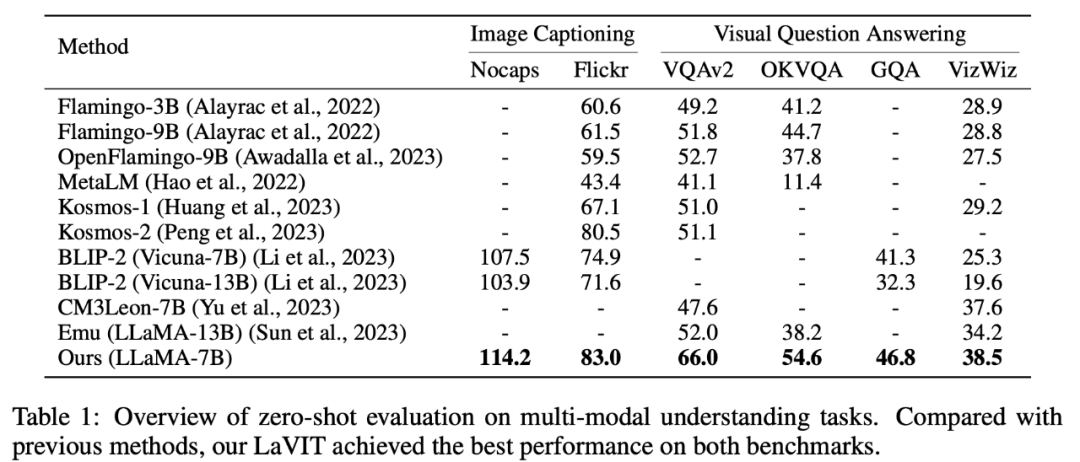
Tableau 1 Évaluation de la tâche de compréhension multimodale Zero-shot
Génération multimodale Zero-shot
Dans cette expérience, puisque le tokenizer visuel proposé est capable de représenter l'image comme un jeton de discrétisation, LaVIT a la capacité de synthétiser des images en générant des jetons visuels de type texte par autorégression. L'auteur a effectué une évaluation quantitative des performances de synthèse d'images du modèle dans des conditions de texte à échantillon nul, et les résultats de la comparaison sont présentés dans le tableau 2.
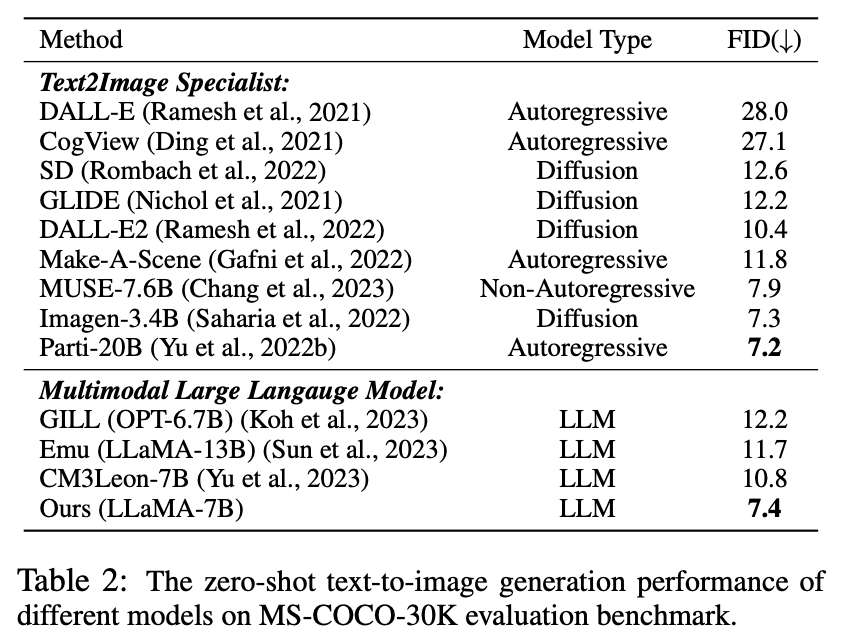
Tableau 2 Performances de génération de texte en image Zero-shot de différents modèles
Comme le montre le tableau, LaVIT surpasse tous les autres modèles de langage multimodal. Par rapport à Emu, LaVIT apporte des améliorations supplémentaires sur les modèles LLM plus petits, démontrant d'excellentes capacités d'alignement visuel-verbal. De plus, LaVIT atteint des performances comparables à celles de l'expert texte-image de pointe Parti tout en utilisant moins de données de formation.
Génération d'images d'invite multimodales
LaVIT est capable d'accepter de manière transparente plusieurs combinaisons modales comme invites et de générer des images correspondantes sans aucun réglage fin. LaVIT génère des images qui reflètent avec précision le style et la sémantique d'un signal multimodal donné. Et il peut modifier l'image d'entrée d'origine avec des indices multimodaux de l'entrée. Les modèles traditionnels de génération d'images tels que Stable Diffusion ne peuvent pas atteindre cette capacité sans données supplémentaires en aval affinées.

Exemple de résultats de génération d'images multimodales
Analyse qualitative
Comme le montre la figure ci-dessous, le tokeniseur dynamique de LaVIT peut sélectionner dynamiquement les blocs d'images les plus informatifs en fonction du contenu de l'image, et le code appris peut produire un codage visuel avec une sémantique de haut niveau.

Visualisation du tokenizer visuel dynamique (à gauche) et du livre de codes appris (à droite)
Résumé
L'émergence de LaVIT fournit un paradigme innovant pour le traitement des tâches multimodales, hérite du succès paradigme d'apprentissage génératif autorégressif de LLM en utilisant un tokenizer visuel dynamique pour représenter la vision et le langage dans une représentation de token discrète unifiée. En optimisant selon un objectif de génération unifié, LaVIT peut traiter les images comme une langue étrangère, les comprendre et les générer comme du texte. Le succès de cette méthode fournit une nouvelle inspiration pour l’orientation du développement de la future recherche multimodale, en utilisant les puissantes capacités de raisonnement du LLM pour ouvrir de nouvelles possibilités pour une compréhension et une génération multimodales plus intelligentes et plus complètes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Mais peut-être qu’il ne pourra pas vaincre le vieil homme dans le parc ? Les Jeux Olympiques de Paris battent leur plein et le tennis de table suscite beaucoup d'intérêt. Dans le même temps, les robots ont également réalisé de nouvelles avancées dans le domaine du tennis de table. DeepMind vient tout juste de proposer le premier agent robot apprenant capable d'atteindre le niveau des joueurs amateurs humains de tennis de table de compétition. Adresse papier : https://arxiv.org/pdf/2408.03906 Quelle est la capacité du robot DeepMind à jouer au tennis de table ? Probablement à égalité avec les joueurs amateurs humains : tant en coup droit qu'en revers : l'adversaire utilise une variété de styles de jeu, et le robot peut également résister : recevoir des services avec des tours différents : Cependant, l'intensité du jeu ne semble pas aussi intense que le vieil homme dans le parc. Pour les robots, le tennis de table
 La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
Le 21 août, la Conférence mondiale sur les robots 2024 s'est tenue en grande pompe à Pékin. La marque de robots domestiques de SenseTime, "Yuanluobot SenseRobot", a dévoilé toute sa famille de produits et a récemment lancé le robot de jeu d'échecs Yuanluobot AI - Chess Professional Edition (ci-après dénommé "Yuanluobot SenseRobot"), devenant ainsi le premier robot d'échecs au monde pour le maison. En tant que troisième produit robot jouant aux échecs de Yuanluobo, le nouveau robot Guoxiang a subi un grand nombre de mises à niveau techniques spéciales et d'innovations en matière d'IA et de machines d'ingénierie. Pour la première fois, il a réalisé la capacité de ramasser des pièces d'échecs en trois dimensions. grâce à des griffes mécaniques sur un robot domestique et effectuer des fonctions homme-machine telles que jouer aux échecs, tout le monde joue aux échecs, réviser la notation, etc.
 Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
La rentrée scolaire est sur le point de commencer, et ce ne sont pas seulement les étudiants qui sont sur le point de commencer le nouveau semestre qui doivent prendre soin d’eux-mêmes, mais aussi les grands modèles d’IA. Il y a quelque temps, Reddit était rempli d'internautes se plaignant de la paresse de Claude. « Son niveau a beaucoup baissé, il fait souvent des pauses et même la sortie devient très courte. Au cours de la première semaine de sortie, il pouvait traduire un document complet de 4 pages à la fois, mais maintenant il ne peut même plus produire une demi-page. !" https://www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ dans un post intitulé "Totalement déçu par Claude", plein de
 Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference qui se tient à Pékin, l'exposition de robots humanoïdes est devenue le centre absolu de la scène. Sur le stand Stardust Intelligent, l'assistant robot IA S1 a réalisé trois performances majeures de dulcimer, d'arts martiaux et de calligraphie. un espace d'exposition, capable à la fois d'arts littéraires et martiaux, a attiré un grand nombre de publics professionnels et de médias. Le jeu élégant sur les cordes élastiques permet au S1 de démontrer un fonctionnement fin et un contrôle absolu avec vitesse, force et précision. CCTV News a réalisé un reportage spécial sur l'apprentissage par imitation et le contrôle intelligent derrière "Calligraphy". Le fondateur de la société, Lai Jie, a expliqué que derrière les mouvements soyeux, le côté matériel recherche le meilleur contrôle de la force et les indicateurs corporels les plus humains (vitesse, charge). etc.), mais du côté de l'IA, les données réelles de mouvement des personnes sont collectées, permettant au robot de devenir plus fort lorsqu'il rencontre une situation forte et d'apprendre à évoluer rapidement. Et agile
 Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Les contributeurs ont beaucoup gagné de cette conférence ACL. L'ACL2024, d'une durée de six jours, se tient à Bangkok, en Thaïlande. ACL est la plus grande conférence internationale dans le domaine de la linguistique informatique et du traitement du langage naturel. Elle est organisée par l'Association internationale pour la linguistique informatique et a lieu chaque année. L'ACL s'est toujours classée première en termes d'influence académique dans le domaine de la PNL, et c'est également une conférence recommandée par le CCF-A. La conférence ACL de cette année est la 62e et a reçu plus de 400 travaux de pointe dans le domaine de la PNL. Hier après-midi, la conférence a annoncé le meilleur article et d'autres récompenses. Cette fois, il y a 7 Best Paper Awards (deux inédits), 1 Best Theme Paper Award et 35 Outstanding Paper Awards. La conférence a également décerné 3 Resource Paper Awards (ResourceAward) et Social Impact Award (
 Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Cet après-midi, Hongmeng Zhixing a officiellement accueilli de nouvelles marques et de nouvelles voitures. Le 6 août, Huawei a organisé la conférence de lancement de nouveaux produits Hongmeng Smart Xingxing S9 et Huawei, réunissant la berline phare intelligente panoramique Xiangjie S9, le nouveau M7Pro et Huawei novaFlip, MatePad Pro 12,2 pouces, le nouveau MatePad Air, Huawei Bisheng With de nombreux nouveaux produits intelligents tous scénarios, notamment la série d'imprimantes laser X1, FreeBuds6i, WATCHFIT3 et l'écran intelligent S5Pro, des voyages intelligents, du bureau intelligent aux vêtements intelligents, Huawei continue de construire un écosystème intelligent complet pour offrir aux consommateurs une expérience intelligente du Internet de tout. Hongmeng Zhixing : Autonomisation approfondie pour promouvoir la modernisation de l'industrie automobile intelligente Huawei s'associe à ses partenaires de l'industrie automobile chinoise pour fournir
 L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
Intégration profonde de la vision et de l'apprentissage des robots. Lorsque deux mains de robot travaillent ensemble en douceur pour plier des vêtements, verser du thé et emballer des chaussures, associées au robot humanoïde 1X NEO qui a fait la une des journaux récemment, vous pouvez avoir le sentiment : nous semblons entrer dans l'ère des robots. En fait, ces mouvements soyeux sont le produit d’une technologie robotique avancée + d’une conception de cadre exquise + de grands modèles multimodaux. Nous savons que les robots utiles nécessitent souvent des interactions complexes et exquises avec l’environnement, et que l’environnement peut être représenté comme des contraintes dans les domaines spatial et temporel. Par exemple, si vous souhaitez qu'un robot verse du thé, le robot doit d'abord saisir la poignée de la théière et la maintenir verticalement sans renverser le thé, puis la déplacer doucement jusqu'à ce que l'embouchure de la théière soit alignée avec l'embouchure de la tasse. , puis inclinez la théière selon un certain angle. ce
 Conférence sur l'intelligence artificielle distribuée Appel à communications DAI 2024 : Agent Day, Richard Sutton, le père de l'apprentissage par renforcement, sera présent ! Yan Shuicheng, Sergey Levine et les scientifiques de DeepMind prononceront des discours d'ouverture
Aug 22, 2024 pm 08:02 PM
Conférence sur l'intelligence artificielle distribuée Appel à communications DAI 2024 : Agent Day, Richard Sutton, le père de l'apprentissage par renforcement, sera présent ! Yan Shuicheng, Sergey Levine et les scientifiques de DeepMind prononceront des discours d'ouverture
Aug 22, 2024 pm 08:02 PM
Introduction à la conférence Avec le développement rapide de la science et de la technologie, l'intelligence artificielle est devenue une force importante dans la promotion du progrès social. À notre époque, nous avons la chance d’être témoins et de participer à l’innovation et à l’application de l’intelligence artificielle distribuée (DAI). L’intelligence artificielle distribuée est une branche importante du domaine de l’intelligence artificielle, qui a attiré de plus en plus d’attention ces dernières années. Les agents basés sur de grands modèles de langage (LLM) ont soudainement émergé. En combinant les puissantes capacités de compréhension du langage et de génération des grands modèles, ils ont montré un grand potentiel en matière d'interaction en langage naturel, de raisonnement par connaissances, de planification de tâches, etc. AIAgent reprend le grand modèle de langage et est devenu un sujet brûlant dans le cercle actuel de l'IA. Au
