
 Périphériques technologiques
IA
Aucune annotation manuelle requise ! LLM prend en charge l'apprentissage par intégration de texte : prend facilement en charge 100 langues et s'adapte à des centaines de milliers de tâches en aval.
Périphériques technologiques
IA
Aucune annotation manuelle requise ! LLM prend en charge l'apprentissage par intégration de texte : prend facilement en charge 100 langues et s'adapte à des centaines de milliers de tâches en aval.
Aucune annotation manuelle requise ! LLM prend en charge l'apprentissage par intégration de texte : prend facilement en charge 100 langues et s'adapte à des centaines de milliers de tâches en aval.

L'intégration de texte (incorporation de mots) est une technologie de base dans le domaine du traitement du langage naturel (NLP). Elle peut mapper le texte dans l'espace sémantique et le convertir en représentation vectorielle dense. Cette méthode a été largement utilisée dans diverses tâches de PNL, notamment la recherche d'informations (RI), la réponse aux questions, le calcul de similarité de texte et les systèmes de recommandation. Grâce à l'intégration de texte, nous pouvons mieux comprendre la signification et la relation du texte, améliorant ainsi l'efficacité des tâches de PNL.
Dans le domaine de la recherche d'informations (RI), la première étape de la récupération utilise généralement des intégrations de texte pour le calcul de similarité. Il fonctionne en rappelant un petit ensemble de documents candidats dans un corpus à grande échelle, puis effectue des calculs fins. La récupération basée sur l'intégration est également un élément important de la génération augmentée par récupération (RAG). Il permet aux grands modèles de langage (LLM) d'accéder à des connaissances externes dynamiques sans modifier les paramètres du modèle. De cette manière, le système IR peut mieux utiliser les incorporations de texte et les connaissances externes pour améliorer les résultats de récupération.
Bien que les premières méthodes d'apprentissage intégrant du texte telles que word2vec et GloVe soient largement utilisées, leurs caractéristiques statiques limitent la capacité de capturer des informations contextuelles riches en langage naturel. Cependant, avec l'essor des modèles de langage pré-entraînés, certaines nouvelles méthodes telles que Sentence-BERT et SimCSE ont réalisé des progrès significatifs sur les ensembles de données d'inférence en langage naturel (NLI) en affinant BERT pour apprendre l'intégration de texte. Ces méthodes exploitent les capacités contextuelles de BERT pour mieux comprendre la sémantique et le contexte du texte, améliorant ainsi la qualité et l'expressivité des intégrations de texte. Grâce à la combinaison de pré-formation et de réglage fin, ces méthodes sont capables d'apprendre des informations sémantiques plus riches à partir de corpus à grande échelle pour le traitement du langage naturel
Pour améliorer les performances et la robustesse de l'intégration de texte, des méthodes avancées telles que E5 et BGE Multi -une formation par étapes a été utilisée. Ils sont d’abord pré-entraînés sur des milliards de paires de textes faiblement supervisés puis affinés sur plusieurs jeux de données annotés. Cette stratégie peut améliorer efficacement les performances de l’intégration de texte.
Les méthodes multi-étapes existantes présentent encore deux défauts :
1 La construction d'un pipeline de formation complexe en plusieurs étapes nécessite beaucoup de travail d'ingénierie pour gérer un grand nombre de paires de corrélation.
2. Le réglage fin repose sur des ensembles de données collectés manuellement, qui sont souvent limités par la diversité des tâches et la couverture linguistique.
La plupart des méthodes utilisent des encodeurs de style BERT et ignorent les progrès de la formation d'un meilleur LLM et des techniques associées.
L'équipe de recherche de Microsoft a récemment proposé une méthode de formation à l'intégration de texte simple et efficace pour surmonter certaines des lacunes des méthodes précédentes. Cette approche ne nécessite pas de conceptions de pipeline complexes ni d'ensembles de données construits manuellement, mais exploite LLM pour synthétiser diverses données textuelles. Grâce à cette approche, ils ont pu générer des intégrations de texte de haute qualité pour des centaines de milliers de tâches d'intégration de texte dans près de 100 langues, tandis que l'ensemble du processus de formation a nécessité moins de 1 000 étapes.

Lien papier : https://arxiv.org/abs/2401.00368
Plus précisément, les chercheurs ont utilisé une stratégie d'incitation en deux étapes, en incitant d'abord le groupe de tâches des candidats au brainstorming LLM, puis l'invite LLM génère des données pour une tâche donnée à partir du pool.
Afin de couvrir différents scénarios d'application, les chercheurs ont conçu plusieurs modèles d'invite pour chaque type de tâche et ont combiné les données générées par différents modèles pour accroître la diversité.
Les résultats expérimentaux prouvent que lors du réglage fin « uniquement des données synthétiques », Mistral-7B atteint des performances très compétitives sur les benchmarks BEIR et MTEB lorsque le réglage fin des données synthétiques et annotées est ajouté, atteignez les performances sota ;
Utilisez de grands modèles pour améliorer l'intégration de texte
1. Génération de données synthétiques
L'utilisation de grands modèles de langage (LLM) de pointe tels que GPT-4 pour synthétiser des données attire de plus en plus d'attention. , qui peut améliorer le modèle en termes de diversité de capacités multitâches et multilingues, qui peut ensuite former des intégrations de texte plus robustes qui fonctionnent bien dans diverses tâches en aval (telles que la récupération sémantique, le calcul de similarité de texte, le clustering).
Pour générer diverses données synthétiques, les chercheurs ont proposé une taxonomie simple qui classe d'abord les tâches d'intégration, puis utilise différents modèles d'invite pour chaque type de tâche.
Tâches asymétriques
Comprend les tâches où la requête et le document sont sémantiquement liés mais ne se paraphrasent pas.
En fonction de la longueur de la requête et du document, les chercheurs ont divisé les tâches asymétriques en quatre sous-catégories : la correspondance courte-longue (requête courte et document long, un scénario typique dans les moteurs de recherche commerciaux), la correspondance longue-courte, court - Match court et match long-long.
Pour chaque sous-catégorie, les chercheurs ont conçu un modèle d'invite en deux étapes, invitant d'abord LLM à réfléchir à une liste de tâches, puis générant un exemple spécifique des conditions définies par la tâche, le résultat de GPT-4 était pour l'essentiel cohérent ; La qualité est très élevée.

Dans des expériences préliminaires, les chercheurs ont également essayé d'utiliser une seule invite pour générer des paires de définitions de tâches et de documents d'interrogation, mais la diversité des données n'était pas aussi bonne que la méthode en deux étapes mentionnée ci-dessus.
Les tâches de symétrie
incluent principalement des requêtes et des documents avec une sémantique similaire mais des formes de surface différentes.
Deux scénarios d'application sont étudiés dans cet article : la similarité de texte sémantique monolingue (STS) et la récupération bi-texte, et deux modèles d'invite différents sont conçus pour chaque scénario, personnalisés en fonction de leurs objectifs spécifiques depuis la définition de la tâche. est relativement simple, l’étape de brainstorming peut être omise.
Afin d'augmenter encore la diversité des mots d'invite et d'améliorer la diversité des données synthétiques, les chercheurs ont ajouté plusieurs espaces réservés à chaque tableau d'invite et les ont échantillonnés de manière aléatoire au moment de l'exécution. Par exemple, "{query_length}" représente Sampled from. l'ensemble "{moins de 5 mots, 5-10 mots, au moins 10 mots}".
Afin de générer des données multilingues, les chercheurs ont échantillonné la valeur de « {langue} » dans la liste des langues de XLM-R, en accordant plus de poids aux langues à hautes ressources ; le format sera ignoré lors de l'analyse ; les doublons sont également supprimés en fonction de la correspondance exacte des chaînes.
2. Formation
Étant donné une paire requête-document associée, utilisez d'abord la requête d'origine q+ pour générer une nouvelle instruction q_inst, où "{task_definition}" est un espace réservé pour intégrer une description en une phrase du symbole de tâche.
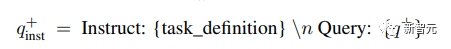
Pour les données synthétiques générées, le résultat de l'étape de brainstorming est utilisé ; pour d'autres ensembles de données, tels que MS-MARCO, les chercheurs créent manuellement des définitions de tâches et les appliquent à toutes les requêtes de l'ensemble de données sans modifier les fichiers. N'importe quel préfixe de commande à la fin.
De cette façon, l'index du document est pré-construit et les tâches à effectuer peuvent être personnalisées en modifiant uniquement le côté requête.
À partir d'un LLM pré-entraîné, ajoutez un jeton [EOS] à la fin de la requête et du document, puis introduisez-le dans le LLM pour obtenir les intégrations de requête et de document en obtenant le vecteur [EOS] de la dernière couche.
Utilisez ensuite la perte InfoNCE standard pour calculer la perte des négatifs intra-lot et des négatifs durs.
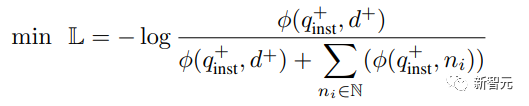
où ℕ représente l'ensemble de tous les négatifs, 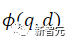 est utilisé pour calculer le score de correspondance entre la requête et le document, t est un hyperparamètre de température, fixé à 0,02 dans l'expérience
est utilisé pour calculer le score de correspondance entre la requête et le document, t est un hyperparamètre de température, fixé à 0,02 dans l'expérience
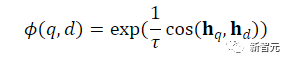
Résultats de l'expérience
Statistiques de données synthétiques
Les chercheurs ont utilisé le service Azure OpenAI pour générer 500 000 échantillons, contenant 150 000 instructions uniques, dont 25 % ont été générées par GPT-3.5-Turbo et le reste par GPT-4. , qui a consommé un total de 180 millions de jetons.
La langue principale est l'anglais, couvrant un total de 93 langues ; pour 75 langues à faibles ressources, il y a en moyenne environ 1 000 échantillons par langue.
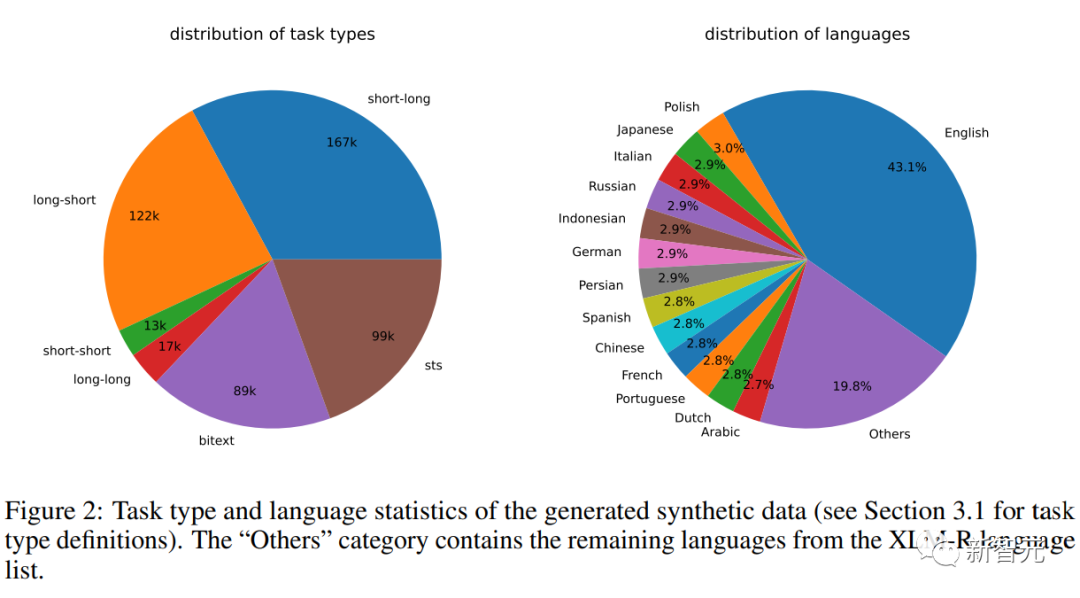
En termes de qualité des données, les chercheurs ont constaté qu'une partie des résultats de GPT-3.5-Turbo ne suivait pas strictement les directives spécifiées dans le modèle d'invite, mais malgré cela, la qualité globale était toujours acceptable, et préliminaire les expériences ont également prouvé que l'utilisation de cela présente les avantages d'un sous-ensemble de données.
Ajustement et évaluation du modèle
Les chercheurs ont utilisé la perte ci-dessus pour affiner le Mistral-7B pré-entraîné pendant 1 époque, ont suivi la méthode d'entraînement de RankLLaMA et ont utilisé LoRA avec le rang 16. .
Pour réduire davantage les besoins en mémoire GPU, des technologies telles que les points de contrôle de gradient, l'entraînement de précision mixte et DeepSpeed ZeRO-3 sont utilisées.
En termes de données de formation, des données synthétiques générées et 13 ensembles de données publics ont été utilisés, ce qui a donné environ 1,8 million d'exemples après échantillonnage.
Pour une comparaison équitable avec certains travaux antérieurs, les chercheurs rapportent également les résultats lorsque la seule supervision des annotations est l'ensemble de données de classement des chapitres MS-MARCO, et évaluent également le modèle sur le benchmark MTEB.
Principaux résultats
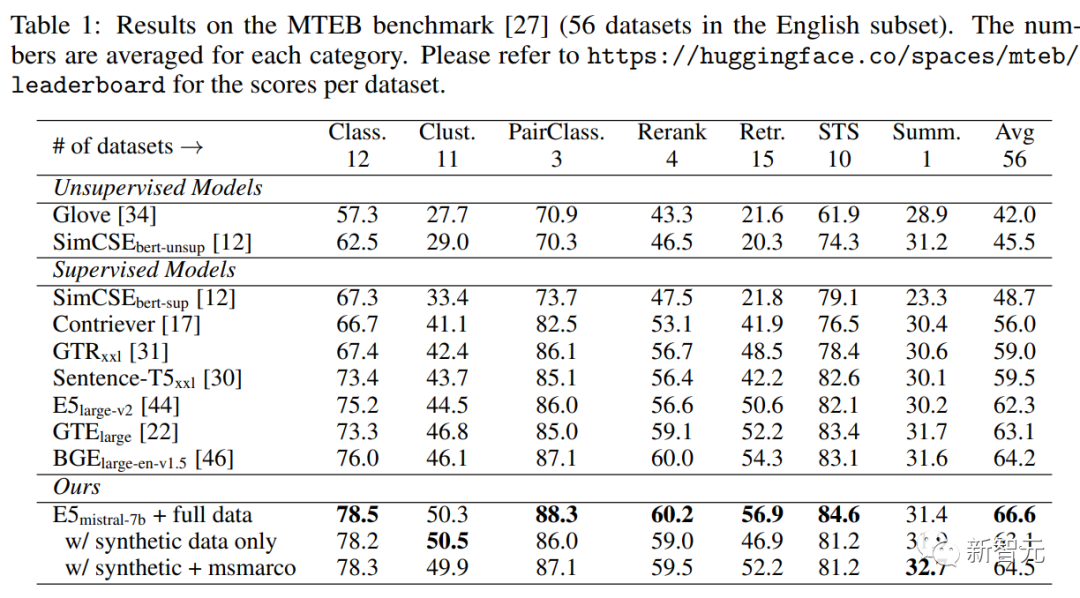
Comme vous pouvez le voir dans le tableau ci-dessous, le modèle "E5mistral-7B + données complètes" obtenu dans l'article a obtenu la note moyenne la plus élevée dans le benchmark MTEB, soit 2,4 de plus que le précédent point du modèle le plus avancé.
Dans le paramètre "avec données synthétiques uniquement", aucune donnée annotée n'est utilisée pour l'entraînement, mais les performances sont toujours très compétitives.
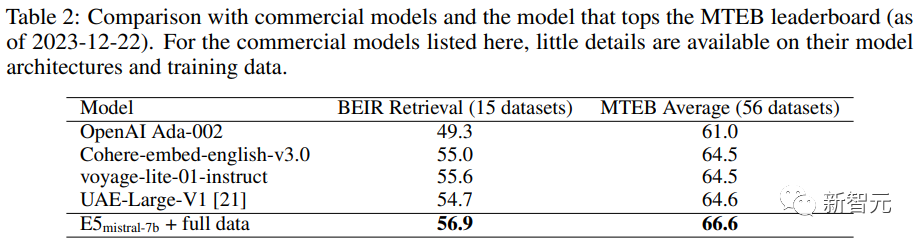
Les chercheurs ont également comparé plusieurs modèles commerciaux d'intégration de texte, mais le manque de transparence et de documentation de ces modèles a empêché une comparaison équitable.
Cependant, il ressort des résultats de comparaison des performances de récupération sur le benchmark BEIR que le modèle formé est dans une large mesure supérieur au modèle commercial actuel.
Récupération multilingue
Pour évaluer les capacités multilingues du modèle, les chercheurs ont mené une évaluation sur l'ensemble de données MIRACL, qui contient des requêtes annotées par l'homme et des jugements de pertinence en 18 langues.
Les résultats montrent que le modèle surpasse mE5-large dans les langues à ressources élevées, notamment en anglais, et que ses performances sont meilleures. Cependant, pour les langues à faibles ressources, le modèle n'est toujours pas idéal par rapport à mE5-base.
Les chercheurs attribuent cela au fait que Mistral-7B a été pré-entraîné principalement sur des données anglaises, une méthode que les modèles prédictifs multilingues peuvent utiliser pour combler cette lacune.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
