

À mesure que la technologie des grands modèles de langage (LLM) évolue, l'ingénierie rapide devient de plus en plus importante. Plusieurs instituts de recherche ont publié des directives d'ingénierie des invites LLM, notamment Microsoft, OpenAI, et plus encore.
Récemment, Meta a fourni un guide d'ingénierie interactif spécifiquement pour son modèle open source Llama 2. Ce guide couvre l'ingénierie rapide et les meilleures pratiques d'utilisation de Llama 2.
Ce qui suit est le contenu principal de ce guide.
En 2023, Meta a lancé les modèles Llama et Llama 2. Les modèles plus petits sont moins chers à déployer et à exécuter, tandis que les modèles plus grands sont plus performants.
Les échelles de paramètres du modèle de la série Llama 2 sont les suivantes :

Code Llama est un LLM centré sur le code, construit sur la base de Llama 2, il existe également diverses échelles de paramètres et variantes de réglage fin :

LLM peut être déployé et accessible de différentes manières, notamment :
Auto-hébergement : utilisez du matériel local pour exécuter l'inférence, par exemple en utilisant lama.cpp dans Llama 2 fonctionnant sur Macbook Pro. Avantages : L'auto-hébergement est préférable si vous avez des besoins en matière de confidentialité/sécurité ou si vous disposez de suffisamment de GPU.
Hébergement cloud : comptez sur un fournisseur de cloud pour déployer des instances hébergeant des modèles spécifiques, comme l'exécution de Llama 2 via des fournisseurs de cloud tels qu'AWS, Azure, GCP, etc. Avantages : L'hébergement cloud est le meilleur moyen de personnaliser votre modèle et son exécution.
API hébergée : appelez LLM directement via l'API. De nombreuses entreprises proposent des API d'inférence Llama 2, notamment AWS Bedrock, Replicate, Anyscale, Together et d'autres. Avantages : L’API hébergée est globalement l’option la plus simple.
API hébergée
L'API hébergée a généralement deux points de terminaison principaux :
1.
2. chat_completion : génère le message suivant dans la liste des messages, fournissant des instructions et un contexte plus clairs pour les cas d'utilisation tels que les chatbots.
token
LLM gère les entrées et les sorties sous la forme de blocs appelés jetons, et chaque modèle a son propre schéma de tokenisation. Par exemple, la phrase suivante :
Notre destin est écrit dans les étoiles.
La tokenisation de Llama 2 est ["notre", "dest", "iny", "is", "writing", "in", "les étoiles"]. Les jetons sont particulièrement importants lorsque l’on considère la tarification des API et le comportement interne (tels que les hyperparamètres). Chaque modèle a une longueur de contexte maximale que l'invite ne peut pas dépasser, Llama 2 est de 4 096 jetons et Code Llama est de 100 000 jetons.
À titre d'exemple, nous utilisons Replicate pour appeler le chat Llama 2 et utilisons LangChain pour configurer facilement l'API de complétion de chat.
Installez d'abord les prérequis :
pip install langchain replicate
from typing import Dict, Listfrom langchain.llms import Replicatefrom langchain.memory import ChatMessageHistoryfrom langchain.schema.messages import get_buffer_stringimport os# Get a free API key from https://replicate.com/account/api-tokensos.environ ["REPLICATE_API_TOKEN"] = "YOUR_KEY_HERE"LLAMA2_70B_CHAT = "meta/llama-2-70b-chat:2d19859030ff705a87c746f7e96eea03aefb71f166725aee39692f1476566d48"LLAMA2_13B_CHAT = "meta/llama-2-13b-chat:f4e2de70d66816a838a89eeeb621910adffb0dd0baba3976c96980970978018d"# We'll default to the smaller 13B model for speed; change to LLAMA2_70B_CHAT for more advanced (but slower) generationsDEFAULT_MODEL = LLAMA2_13B_CHATdef completion (prompt: str,model: str = DEFAULT_MODEL,temperature: float = 0.6,top_p: float = 0.9,) -> str:llm = Replicate (model=model,model_kwargs={"temperature": temperature,"top_p": top_p, "max_new_tokens": 1000})return llm (prompt)def chat_completion (messages: List [Dict],model = DEFAULT_MODEL,temperature: float = 0.6,top_p: float = 0.9,) -> str:history = ChatMessageHistory ()for message in messages:if message ["role"] == "user":history.add_user_message (message ["content"])elif message ["role"] == "assistant":history.add_ai_message (message ["content"])else:raise Exception ("Unknown role")return completion (get_buffer_string (history.messages,human_prefix="USER",ai_prefix="ASSISTANT",),model,temperature,top_p,)def assistant (content: str):return { "role": "assistant", "content": content }def user (content: str):return { "role": "user", "content": content }def complete_and_print (prompt: str, model: str = DEFAULT_MODEL):print (f'==============\n {prompt}\n==============')response = completion (prompt, model)print (response, end='\n\n')API de complétion
complete_and_print ("The typical color of the sky is:")complete_and_print ("which model version are you?")Le modèle de complétion de chat fournit une structure supplémentaire pour interagir avec LLM, en envoyant un tableau d'objets de message structurés au LLM au lieu d'un seul texte. Cette liste de messages fournit à LLM des informations « de fond » ou « historiques » sur lesquelles poursuivre.
En règle générale, chaque message contient des rôles et du contenu :
Les messages avec des rôles système sont utilisés par les développeurs pour fournir des instructions de base à LLM.
Les messages avec des rôles d'utilisateur sont généralement des messages fournis par des humains.
Les messages avec le rôle d'assistant sont généralement générés par LLM.
response = chat_completion (messages=[user ("My favorite color is blue."),assistant ("That's great to hear!"),user ("What is my favorite color?"),])print (response)# "Sure, I can help you with that! Your favorite color is blue."Hyperparamètres LLM
LLM API 通常会采用影响输出的创造性和确定性的参数。在每一步中,LLM 都会生成 token 及其概率的列表。可能性最小的 token 会从列表中「剪切」(基于 top_p),然后从剩余候选者中随机(温度参数 temperature)选择一个 token。换句话说:top_p 控制生成中词汇的广度,温度控制词汇的随机性,温度参数 temperature 为 0 会产生几乎确定的结果。
def print_tuned_completion (temperature: float, top_p: float):response = completion ("Write a haiku about llamas", temperature=temperature, top_p=top_p)print (f'[temperature: {temperature} | top_p: {top_p}]\n {response.strip ()}\n')print_tuned_completion (0.01, 0.01)print_tuned_completion (0.01, 0.01)# These two generations are highly likely to be the sameprint_tuned_completion (1.0, 1.0)print_tuned_completion (1.0, 1.0)# These two generations are highly likely to be different详细、明确的指令会比开放式 prompt 产生更好的结果:
complete_and_print (prompt="Describe quantum physics in one short sentence of no more than 12 words")# Returns a succinct explanation of quantum physics that mentions particles and states existing simultaneously.
我们可以给定使用规则和限制,以给出明确的指令。
使用要点;
以 JSON 对象形式返回;
使用较少的技术术语并用于工作交流中。
以下是给出明确指令的例子:
complete_and_print ("Explain the latest advances in large language models to me.")# More likely to cite sources from 2017complete_and_print ("Explain the latest advances in large language models to me. Always cite your sources. Never cite sources older than 2020.")# Gives more specific advances and only cites sources from 2020零样本 prompting
一些大型语言模型(例如 Llama 2)能够遵循指令并产生响应,而无需事先看过任务示例。没有示例的 prompting 称为「零样本 prompting(zero-shot prompting)」。例如:
complete_and_print ("Text: This was the best movie I've ever seen! \n The sentiment of the text is:")# Returns positive sentimentcomplete_and_print ("Text: The director was trying too hard. \n The sentiment of the text is:")# Returns negative sentiment少样本 prompting
添加所需输出的具体示例通常会产生更加准确、一致的输出。这种方法称为「少样本 prompting(few-shot prompting)」。例如:
def sentiment (text):response = chat_completion (messages=[user ("You are a sentiment classifier. For each message, give the percentage of positive/netural/negative."),user ("I liked it"),assistant ("70% positive 30% neutral 0% negative"),user ("It could be better"),assistant ("0% positive 50% neutral 50% negative"),user ("It's fine"),assistant ("25% positive 50% neutral 25% negative"),user (text),])return responsedef print_sentiment (text):print (f'INPUT: {text}')print (sentiment (text))print_sentiment ("I thought it was okay")# More likely to return a balanced mix of positive, neutral, and negativeprint_sentiment ("I loved it!")# More likely to return 100% positiveprint_sentiment ("Terrible service 0/10")# More likely to return 100% negativeRole Prompting
Llama 2 在指定角色时通常会给出更一致的响应,角色为 LLM 提供了所需答案类型的背景信息。
例如,让 Llama 2 对使用 PyTorch 的利弊问题创建更有针对性的技术回答:
complete_and_print ("Explain the pros and cons of using PyTorch.")# More likely to explain the pros and cons of PyTorch covers general areas like documentation, the PyTorch community, and mentions a steep learning curvecomplete_and_print ("Your role is a machine learning expert who gives highly technical advice to senior engineers who work with complicated datasets. Explain the pros and cons of using PyTorch.")# Often results in more technical benefits and drawbacks that provide more technical details on how model layers思维链
简单地添加一个「鼓励逐步思考」的短语可以显著提高大型语言模型执行复杂推理的能力(Wei et al. (2022)),这种方法称为 CoT 或思维链 prompting:
complete_and_print ("Who lived longer Elvis Presley or Mozart?")# Often gives incorrect answer of "Mozart"complete_and_print ("Who lived longer Elvis Presley or Mozart? Let's think through this carefully, step by step.")# Gives the correct answer "Elvis"自洽性(Self-Consistency)
LLM 是概率性的,因此即使使用思维链,一次生成也可能会产生不正确的结果。自洽性通过从多次生成中选择最常见的答案来提高准确性(以更高的计算成本为代价):
import refrom statistics import modedef gen_answer ():response = completion ("John found that the average of 15 numbers is 40.""If 10 is added to each number then the mean of the numbers is?""Report the answer surrounded by three backticks, for example:```123```",model = LLAMA2_70B_CHAT)match = re.search (r'```(\d+)```', response)if match is None:return Nonereturn match.group (1)answers = [gen_answer () for i in range (5)]print (f"Answers: {answers}\n",f"Final answer: {mode (answers)}",)# Sample runs of Llama-2-70B (all correct):# [50, 50, 750, 50, 50]-> 50# [130, 10, 750, 50, 50] -> 50# [50, None, 10, 50, 50] -> 50检索增强生成
有时我们可能希望在应用程序中使用事实知识,那么可以从开箱即用(即仅使用模型权重)的大模型中提取常见事实:
complete_and_print ("What is the capital of the California?", model = LLAMA2_70B_CHAT)# Gives the correct answer "Sacramento"然而,LLM 往往无法可靠地检索更具体的事实或私人信息。模型要么声明它不知道,要么幻想出一个错误的答案:
complete_and_print ("What was the temperature in Menlo Park on December 12th, 2023?")# "I'm just an AI, I don't have access to real-time weather data or historical weather records."complete_and_print ("What time is my dinner reservation on Saturday and what should I wear?")# "I'm not able to access your personal information [..] I can provide some general guidance"检索增强生成(RAG)是指在 prompt 中包含从外部数据库检索的信息(Lewis et al. (2020))。RAG 是将事实纳入 LLM 应用的有效方法,并且比微调更经济实惠,微调可能成本高昂并对基础模型的功能产生负面影响。
MENLO_PARK_TEMPS = {"2023-12-11": "52 degrees Fahrenheit","2023-12-12": "51 degrees Fahrenheit","2023-12-13": "51 degrees Fahrenheit",}def prompt_with_rag (retrived_info, question):complete_and_print (f"Given the following information: '{retrived_info}', respond to: '{question}'")def ask_for_temperature (day):temp_on_day = MENLO_PARK_TEMPS.get (day) or "unknown temperature"prompt_with_rag (f"The temperature in Menlo Park was {temp_on_day} on {day}'",# Retrieved factf"What is the temperature in Menlo Park on {day}?",# User question)ask_for_temperature ("2023-12-12")# "Sure! The temperature in Menlo Park on 2023-12-12 was 51 degrees Fahrenheit."ask_for_temperature ("2023-07-18")# "I'm not able to provide the temperature in Menlo Park on 2023-07-18 as the information provided states that the temperature was unknown."LLM 本质上不擅长执行计算,例如:
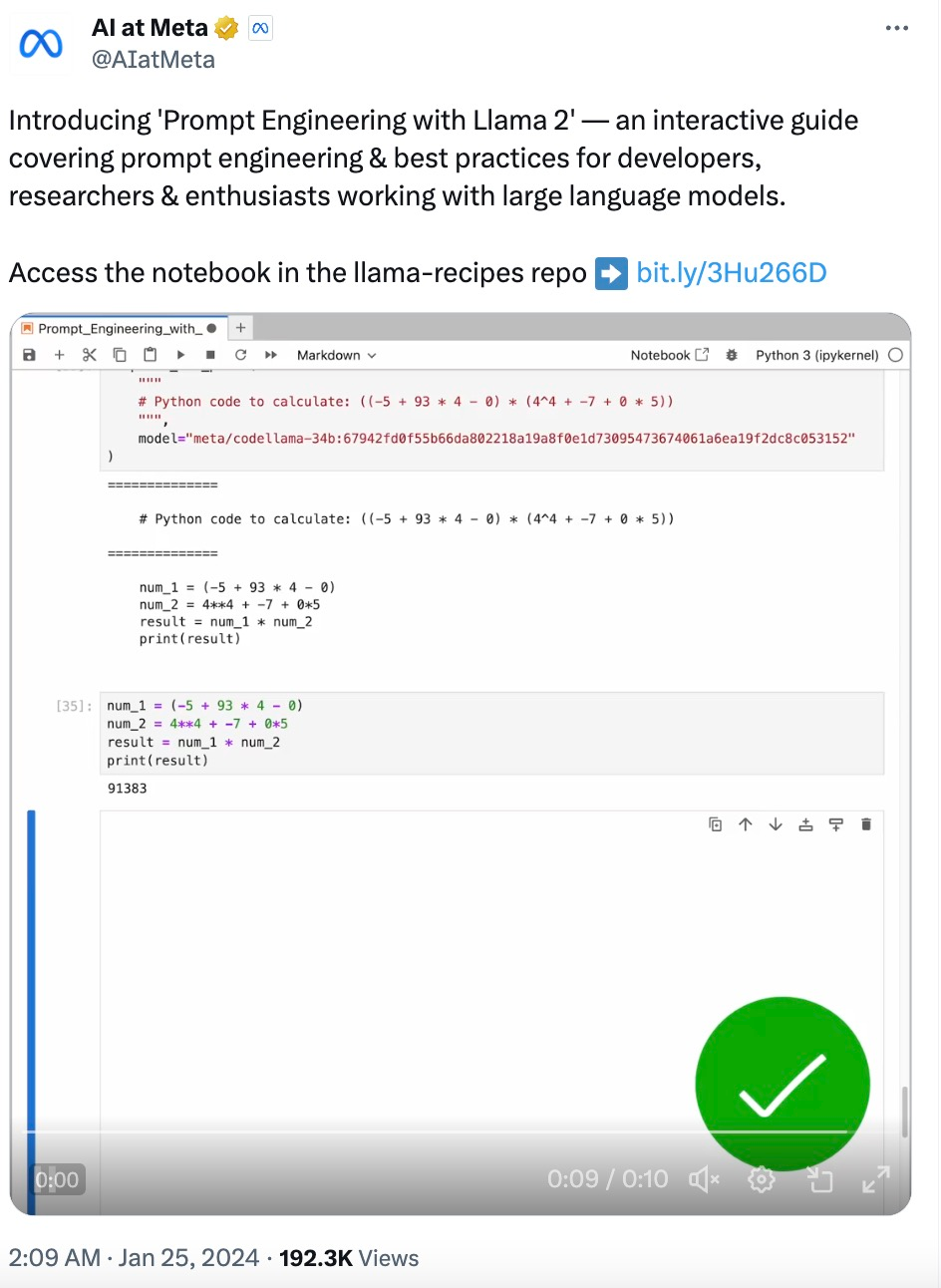
complete_and_print ("""Calculate the answer to the following math problem:((-5 + 93 * 4 - 0) * (4^4 + -7 + 0 * 5))""")# Gives incorrect answers like 92448, 92648, 95463Gao et al. (2022) 提出「程序辅助语言模型(Program-aided Language Models,PAL)」的概念。虽然 LLM 不擅长算术,但它们非常擅长代码生成。PAL 通过指示 LLM 编写代码来解决计算任务。
complete_and_print ("""# Python code to calculate: ((-5 + 93 * 4 - 0) * (4^4 + -7 + 0 * 5))""",model="meta/codellama-34b:67942fd0f55b66da802218a19a8f0e1d73095473674061a6ea19f2dc8c053152")# The following code was generated by Code Llama 34B:num1 = (-5 + 93 * 4 - 0)num2 = (4**4 + -7 + 0 * 5)answer = num1 * num2print (answer)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment utiliser la fonction de conversion convertir
Comment utiliser la fonction de conversion convertir
 Que faire si le changement de nom du fichier temporaire échoue
Que faire si le changement de nom du fichier temporaire échoue
 Quelle carte est la carte TF ?
Quelle carte est la carte TF ?
 Méthode BigDecimal pour comparer les tailles
Méthode BigDecimal pour comparer les tailles
 Que faire si l'image intégrée ne s'affiche pas complètement
Que faire si l'image intégrée ne s'affiche pas complètement
 Comment configurer la variable d'environnement path en Java
Comment configurer la variable d'environnement path en Java
 Solution au code Java qui ne fonctionne pas
Solution au code Java qui ne fonctionne pas
 utilisation de l'insertion Oracle
utilisation de l'insertion Oracle








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



