
 Périphériques technologiques
IA
À l'ère des grands modèles, NTU Zhou Zhihua se plonge dans l'étude des logiciels et son dernier article est en ligne
Périphériques technologiques
IA
À l'ère des grands modèles, NTU Zhou Zhihua se plonge dans l'étude des logiciels et son dernier article est en ligne
À l'ère des grands modèles, NTU Zhou Zhihua se plonge dans l'étude des logiciels et son dernier article est en ligne

L'apprentissage automatique a connu un grand succès dans divers domaines et un grand nombre de modèles d'apprentissage automatique de haute qualité émergent constamment. Cependant, il n'est pas facile pour les utilisateurs ordinaires de trouver un modèle adapté à leurs tâches, et encore moins de créer un nouveau modèle à partir de zéro. Afin de résoudre ce problème, le professeur Zhou Zhihua de l'Université de Nanjing a proposé un paradigme appelé « logiciel d'apprentissage ». Grâce à l'idée de modèles et de réglementations, un marché des logiciels d'apprentissage (maintenant appelé système de base du logiciel d'apprentissage) a été construit pour permettre aux utilisateurs de unifier Choisissez et déployez des modèles adaptés à vos besoins. Aujourd'hui, le paradigme du logiciel d'apprentissage a inauguré sa première plate-forme de base open source, nommée Beimingwu. Cette plate-forme fournira aux utilisateurs une riche bibliothèque de modèles et des outils de déploiement, rendant l'utilisation et la personnalisation des modèles d'apprentissage automatique plus faciles et plus efficaces. Grâce à Beimingwu, les utilisateurs peuvent mieux utiliser la puissance de l'apprentissage automatique pour résoudre divers problèmes pratiques.

Dans le paradigme classique de l'apprentissage automatique, afin de former un modèle haute performance à partir de zéro, une grande quantité de données de haute qualité, une expérience d'expert et des ressources informatiques sont nécessaires, ce qui prend sans aucun doute beaucoup de temps. , tâche laborieuse et coûteuse. En outre, la réutilisation des modèles existants pose également certains problèmes. Par exemple, il est difficile d’adapter un modèle entraîné spécifique à différents environnements, et des oublis catastrophiques peuvent survenir lors de l’amélioration progressive d’un modèle entraîné. Nous devons donc trouver une manière plus efficace et plus flexible de relever ces défis.
Les problèmes de confidentialité et de propriété des données entravent non seulement le partage d'expériences entre développeurs, mais limitent également la capacité d'application des grands modèles dans des scénarios sensibles aux données. La recherche se concentre souvent sur ces questions, mais dans la pratique, elles se posent souvent simultanément et s’influencent mutuellement.
Dans les domaines du traitement du langage naturel et de la vision par ordinateur, bien que le paradigme traditionnel de développement de grands modèles ait obtenu des résultats remarquables, certains problèmes importants n'ont pas encore été résolus. Ces problèmes incluent un nombre illimité de tâches et de scénarios imprévus, des changements constants dans l'environnement, des oublis catastrophiques, des besoins élevés en ressources, des problèmes de confidentialité, des exigences de déploiement localisées et des exigences de personnalisation et de personnalisation. Par conséquent, construire un grand modèle correspondant à chaque tâche potentielle n’est pas une solution pratique. Ces défis nous obligent à trouver de nouvelles méthodes et stratégies, telles que l'adoption d'architectures de modèles plus flexibles et personnalisables, et l'utilisation de techniques telles que l'apprentissage par transfert et l'apprentissage incrémentiel pour nous adapter aux changements dans différentes tâches et environnements. Ce n’est qu’en intégrant plusieurs approches et stratégies que nous pourrons mieux résoudre ces problèmes complexes.
Afin de résoudre des tâches d'apprentissage automatique, le professeur Zhou Zhihua de l'Université de Nanjing a proposé le concept de learnware en 2016. Il a créé un nouveau paradigme basé sur le learningware et a proposé le système Learningware Dock comme plate-forme de base. L'objectif de ce système est d'adapter uniformément les modèles d'apprentissage automatique soumis par les développeurs du monde entier et d'utiliser les capacités des modèles pour résoudre de nouvelles tâches en fonction des besoins des utilisateurs potentiels. Cette innovation apporte de nouvelles possibilités et opportunités dans le domaine de l’apprentissage automatique.
La conception fondamentale du paradigme du learningware est la suivante : pour des modèles de haute qualité issus de différentes tâches, le learningware est une unité de base avec un format unifié. Le logiciel d'apprentissage se compose du modèle lui-même et d'une spécification qui décrit les caractéristiques du modèle dans une certaine représentation. Les développeurs peuvent soumettre librement des modèles, et le système de quai d'apprentissage aidera à générer des spécifications et à stocker le logiciel d'apprentissage dans le quai d'apprentissage. Dans ce processus, les développeurs n'ont pas besoin de divulguer leurs données de formation au quai d'apprentissage. À l'avenir, les utilisateurs pourront soumettre leurs exigences au système de base du logiciel d'apprentissage et résoudre leurs propres tâches d'apprentissage automatique en recherchant et en réutilisant le logiciel d'apprentissage sans divulguer leurs propres données au système du logiciel d'apprentissage. Cette conception rend le partage de modèles et la résolution de tâches plus efficaces, plus pratiques et plus privées.
Afin d'établir une plate-forme de recherche scientifique préliminaire pour le paradigme des logiciels d'apprentissage, l'équipe du professeur Zhou Zhihua a récemment construit Beimingwu, qui est le premier système de base open source pour la recherche future sur le paradigme des logiciels d'apprentissage. Le document concerné a été publié et compte 37 pages.
Au niveau technique, le système Beimingwu a jeté les bases de la future recherche universitaire sur les algorithmes et les systèmes liés aux logiciels grâce à une conception d'architecture de système et de moteur évolutive et à une mise en œuvre et une optimisation approfondies de l'ingénierie. De plus, le système intègre également l'algorithme de base du processus complet et crée un scénario d'évaluation de l'algorithme de base. Ces fonctionnalités permettent non seulement au système de prendre en charge les logiciels d'apprentissage, mais offrent également la possibilité d'héberger un grand nombre de logiciels d'apprentissage et d'établir un écosystème de logiciels d'apprentissage.

Titre de l'article : Beimingwu : A Learnware Dock System
Adresse de l'article : https://arxiv.org/pdf/2401.14427.pdf
Page d'accueil de Beimingwu : https://bmwu .cloud /
Entrepôt open source de Beimingwu : https://www.gitlink.org.cn/beimingwu/beimingwu
Entrepôt open source du moteur principal : https://www.gitlink.org.cn/beimingwu /learnware
Dans cet article, les contributions du chercheur peuvent être résumées ainsi :
Basé sur le paradigme du learningware, il simplifie le développement de modèles permettant aux utilisateurs de résoudre de nouvelles tâches : il atteint l'efficacité des données, ne nécessite pas de connaissances expertes et ne divulgue pas les données originales
-
Propose un système complet, unifié et évolutif ; conception de l'architecture du moteur ;
Développement d'un système de base logicielle d'apprentissage open source avec une interface utilisateur unifiée ;
Utilisé pour la mise en œuvre et l'évaluation d'un algorithme de base de processus complet dans différents scénarios.
Aperçu du paradigme Learningware
Le paradigme Learningware a été proposé par l'équipe du professeur Zhou Zhihua en 2016, et a été résumé et approfondi dans l'article de 2024 « Learnware : les petits modèles font grand ». Le processus simplifié de ce paradigme est illustré dans la figure 1 ci-dessous : pour les modèles d'apprentissage automatique de haute qualité, de tout type et de toute structure, leurs développeurs ou propriétaires peuvent volontairement soumettre les modèles formés au système de base du logiciel d'apprentissage (anciennement connu sous le nom de système de base du logiciel d'apprentissage). marché des pièces détachées).
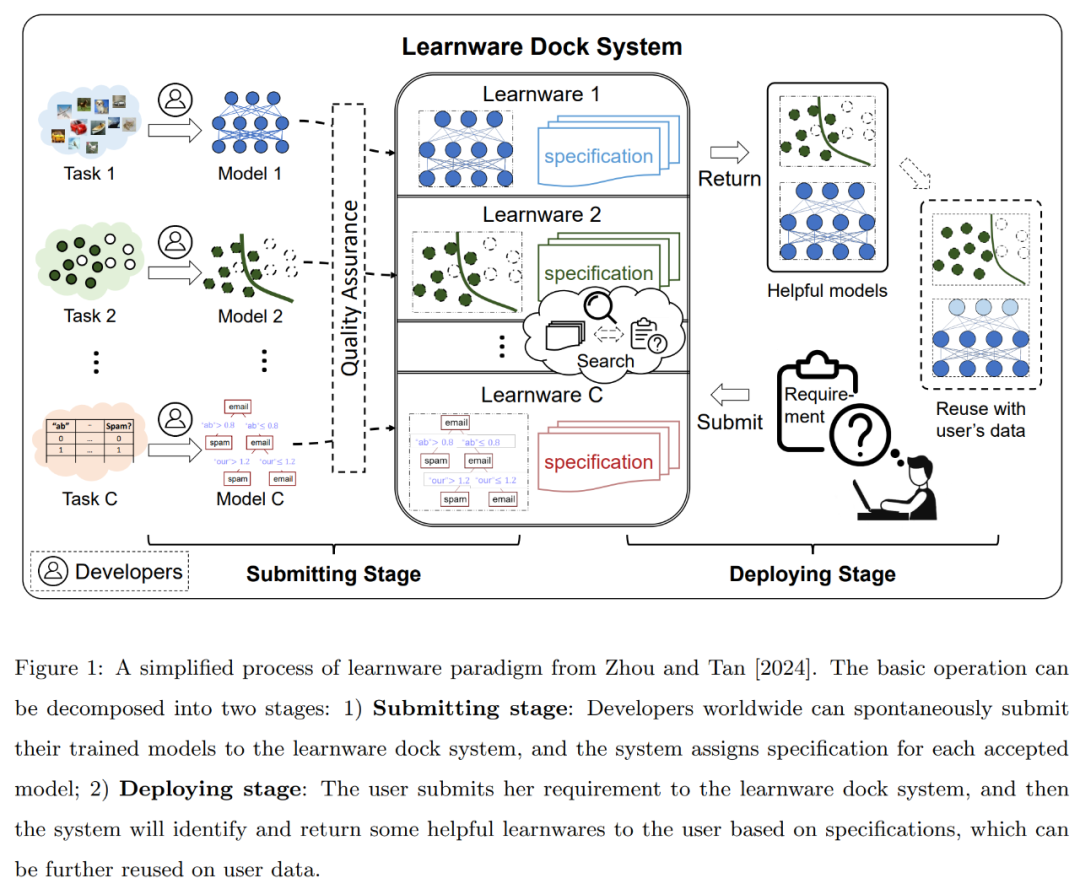
Comme introduit ci-dessus, le paradigme du logiciel d'apprentissage propose d'établir un système de base de logiciel d'apprentissage pour accueillir, organiser et utiliser uniformément les modèles existants qui fonctionnent bien, tirant ainsi uniformément parti des efforts de toutes les communautés pour répondre aux tâches des nouveaux utilisateurs, et peut simultanément résoudre certains des problèmes majeurs, notamment le manque de données de formation et de compétences en matière de formation, l'oubli catastrophique, la difficulté de parvenir à un apprentissage continu, la confidentialité ou la propriété des données, les nouvelles tâches non planifiées dans le monde ouvert, la duplication et le gaspillage, les émissions de carbone causées par la formation, etc.
Récemment, le paradigme du learningware et ses idées fondamentales ont reçu de plus en plus d'attention. Mais la question clé et le principal défi sont les suivants : comment identifier et sélectionner l'élément d'apprentissage ou l'ensemble d'éléments le plus utile pour la tâche d'un nouvel utilisateur, étant donné qu'un système de base d'éléments d'apprentissage peut accueillir des milliers, voire des millions de modèles ? De toute évidence, soumettre les données utilisateur directement dans le système à des fins d'expérimentation coûte cher et expose les données originales de l'utilisateur.
La conception centrale du paradigme d'apprentissage réside dans le protocole. Les recherches récentes sont principalement basées sur le protocole d'intégration moyenne réduite du noyau (RKME).
Bien que les recherches d'analyse théorique et empirique existantes aient prouvé l'efficacité de l'identification des logiciels d'apprentissage basée sur des protocoles, la mise en œuvre du système de base des logiciels d'apprentissage fait toujours défaut et fait face à d'énormes défis. Une nouvelle conception d'architecture basée sur des protocoles est nécessaire pour faire face à des réalités diversifiées. -tâches et modèles mondiaux, et recherche et réutilisation uniformes d'un grand nombre de matériels d'apprentissage en fonction des exigences des tâches de l'utilisateur.
Les chercheurs ont construit le premier système de base de matériel d'apprentissage - Beimingwu, qui prend en charge l'ensemble du processus, y compris la soumission, les tests d'utilisabilité, l'organisation, la gestion, l'identification, le déploiement et la réutilisation du matériel d'apprentissage.
Utilisez Beimingwu pour résoudre des tâches d'apprentissage
Basé sur la première implémentation système du paradigme du learningware, Beimingwu simplifie considérablement le processus de création de modèles d'apprentissage automatique pour de nouvelles tâches. Nous pouvons désormais construire le modèle en suivant le processus du paradigme du learningware. Et bénéficiant d'une structure logicielle d'apprentissage unifiée, d'une conception d'architecture unifiée et d'une interface utilisateur unifiée, tous les modèles soumis à Beimingwu permettent une identification et une réutilisation unifiées.
Ce qui est passionnant, c'est que étant donné une nouvelle tâche utilisateur, si Beimingwu dispose du logiciel d'apprentissage capable de résoudre cette tâche, l'utilisateur peut facilement obtenir et déployer le modèle de haute qualité avec seulement quelques lignes de code, cela ne nécessite pas une grande quantité de données et de connaissances d'experts, et ne divulguera pas vos propres données brutes.
La figure 2 ci-dessous est un exemple de code permettant d'utiliser Beimingwu pour résoudre des tâches d'apprentissage.

La figure 3 ci-dessous montre l'ensemble du flux de travail d'utilisation de Beimingwu, y compris la génération de spécifications statistiques, l'identification des pièces d'apprentissage, le chargement et la réutilisation. Basée sur une mise en œuvre technique et une conception d'interface unifiée, chaque étape peut être réalisée via une ligne de code clé.

Les chercheurs ont déclaré que lors de la résolution de tâches d'apprentissage, le processus de développement de modèles utilisant le paradigme du logiciel d'apprentissage basé sur Beimingwu présente les avantages significatifs suivants :
Ne nécessite pas une grande quantité de données et de ressources informatiques ;
Ne nécessite pas beaucoup d'expertise en apprentissage automatique ; - Fournit un déploiement local unifié et simple pour divers modèles
- Protection de la confidentialité : ne divulgue pas les données originales des utilisateurs.
- Actuellement, Beimingwu ne dispose que de 1 100 outils d'apprentissage construits à un stade précoce sur des ensembles de données open source, ce qui ne couvre pas de nombreux scénarios, et sa capacité à gérer un grand nombre de scénarios spécifiques et inédits est encore limitée. Basé sur la conception d'une architecture évolutive, Beimingwu peut être utilisé comme plate-forme de recherche pour les paradigmes des logiciels d'apprentissage, fournissant une mise en œuvre pratique des algorithmes et une conception expérimentale pour la recherche liée aux logiciels d'apprentissage.
Dans le même temps, en s'appuyant sur une mise en œuvre de base et un support d'architecture évolutif, du matériel d'apprentissage soumis en permanence et des algorithmes continuellement améliorés, ils continueront d'améliorer la capacité du système à résoudre des tâches et à améliorer la réutilisation par le système de modèles existants bien entraînés pour résoudre les problèmes au-delà. la portée des développeurs La capacité d'effectuer de nouvelles tâches sur la cible d'origine. À l’avenir, l’évolution continue des systèmes de base des logiciels d’apprentissage leur permettra de répondre à un nombre croissant de tâches utilisateur sans oubli catastrophique et permettra naturellement un apprentissage tout au long de la vie.
Beimingwu Design
La section 4 de l'article présente la conception du système Beimingwu. Comme le montre la figure 4, l'ensemble du système comprend quatre niveaux : stockage du logiciel d'apprentissage, moteur système, arrière-plan du système et interface utilisateur. Cette section présente d'abord un aperçu de chaque couche, puis présente le moteur principal du système basé sur la conception du protocole, et enfin présente les algorithmes implémentés dans le système.
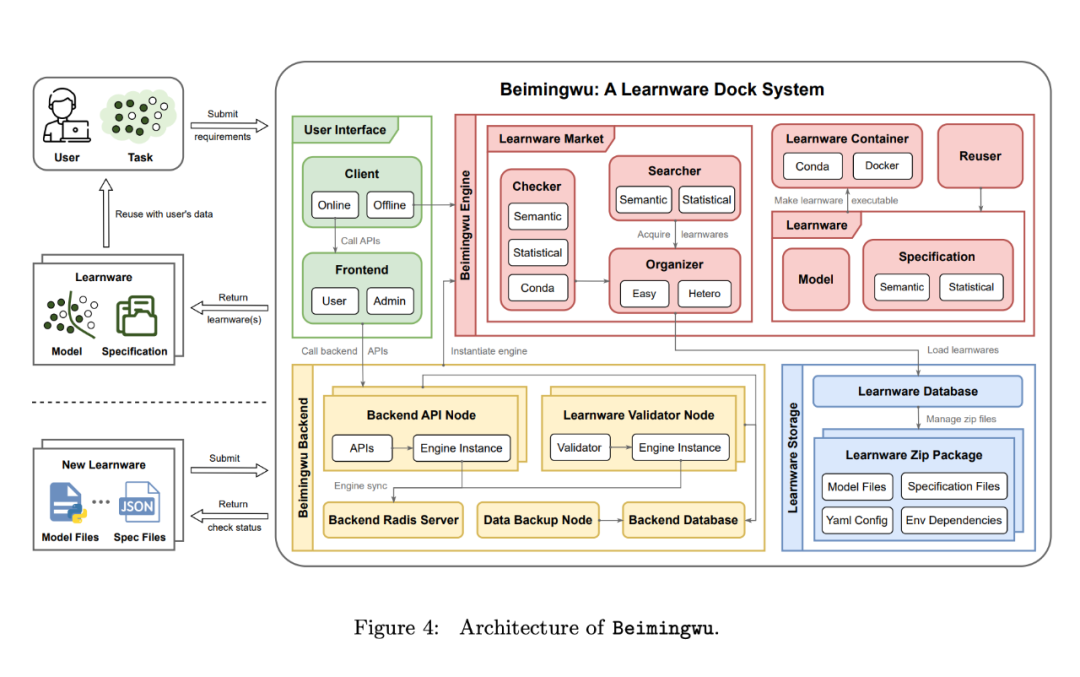
Tout d'abord, jetons un coup d'œil à l'aperçu de chaque couche :
Learningware Storage Layer. À Beimingwu, le matériel d'apprentissage est stocké dans des packages compressés. Ces packages compressés comprennent principalement quatre types de fichiers : les fichiers de modèle, les fichiers de spécifications, les fichiers de dépendances de l'environnement d'exécution du modèle et les fichiers de configuration du logiciel d'apprentissage.
Ces packages compressés de logiciels d'apprentissage sont gérés de manière centralisée par la base de données des logiciels d'apprentissage. Le tableau des éléments d'apprentissage dans la base de données stocke des informations clés, notamment l'ID de l'élément d'apprentissage, le chemin de stockage et l'état de l'élément d'apprentissage (tel que non vérifié et vérifié). Cette base de données fournit une interface unifiée permettant aux moteurs principaux ultérieurs de Beimingwu d'accéder aux informations d'apprentissage.
De plus, la base de données peut être construite à l'aide de SQLite (adapté à une configuration facile dans des environnements de développement et expérimentaux) ou PostgreSQL (recommandé pour un déploiement stable dans des environnements de production), tous deux utilisant la même interface.
Couche de moteur de base. Afin de conserver la simplicité et la structure de Beimingwu, les auteurs ont séparé les composants et algorithmes de base d'un grand nombre de détails techniques. Ces composants extraits peuvent désormais être utilisés comme packages de logiciels d'apprentissage Python, qui constituent le moteur principal de Beimingwu.
En tant que cœur du système, ce moteur couvre tous les processus du paradigme du learningware, y compris la soumission du learningware, les tests d'utilisabilité, l'organisation, l'identification, le déploiement et la réutilisation. Il fonctionne indépendamment de l'arrière-plan et du premier plan et fournit une interface algorithmique complète pour l'apprentissage des tâches liées aux logiciels et des expériences de recherche.
De plus, les spécifications sont le composant central du moteur, représentant chaque modèle d'un point de vue sémantique et statistique et reliant divers composants importants du système logiciel d'apprentissage. En plus des spécifications générées lorsque les développeurs soumettent des modèles, le moteur peut également utiliser la connaissance du système pour générer de nouvelles spécifications système pour les logiciels d'apprentissage, améliorant ainsi la gestion des logiciels d'apprentissage et caractérisant davantage leurs capacités.
Les plateformes de gestion de modèles existantes, telles que Hugging Face, collectent et hébergent uniquement des modèles de manière passive, permettant aux utilisateurs de décider eux-mêmes des capacités du modèle et de sa pertinence par rapport à la tâche. En revanche, Beimingwu utilise son moteur pour créer un tout nouveau modèle. l'architecture du système gère de manière proactive le matériel d'apprentissage. Cette gestion active ne se limite pas à la collecte et au stockage. Le système organise le matériel d'apprentissage selon des protocoles, peut faire correspondre le matériel d'apprentissage pertinent en fonction des exigences des tâches de l'utilisateur et fournit des méthodes de réutilisation et de déploiement de logiciels d'apprentissage correspondants.
La conception du module de base est la suivante :
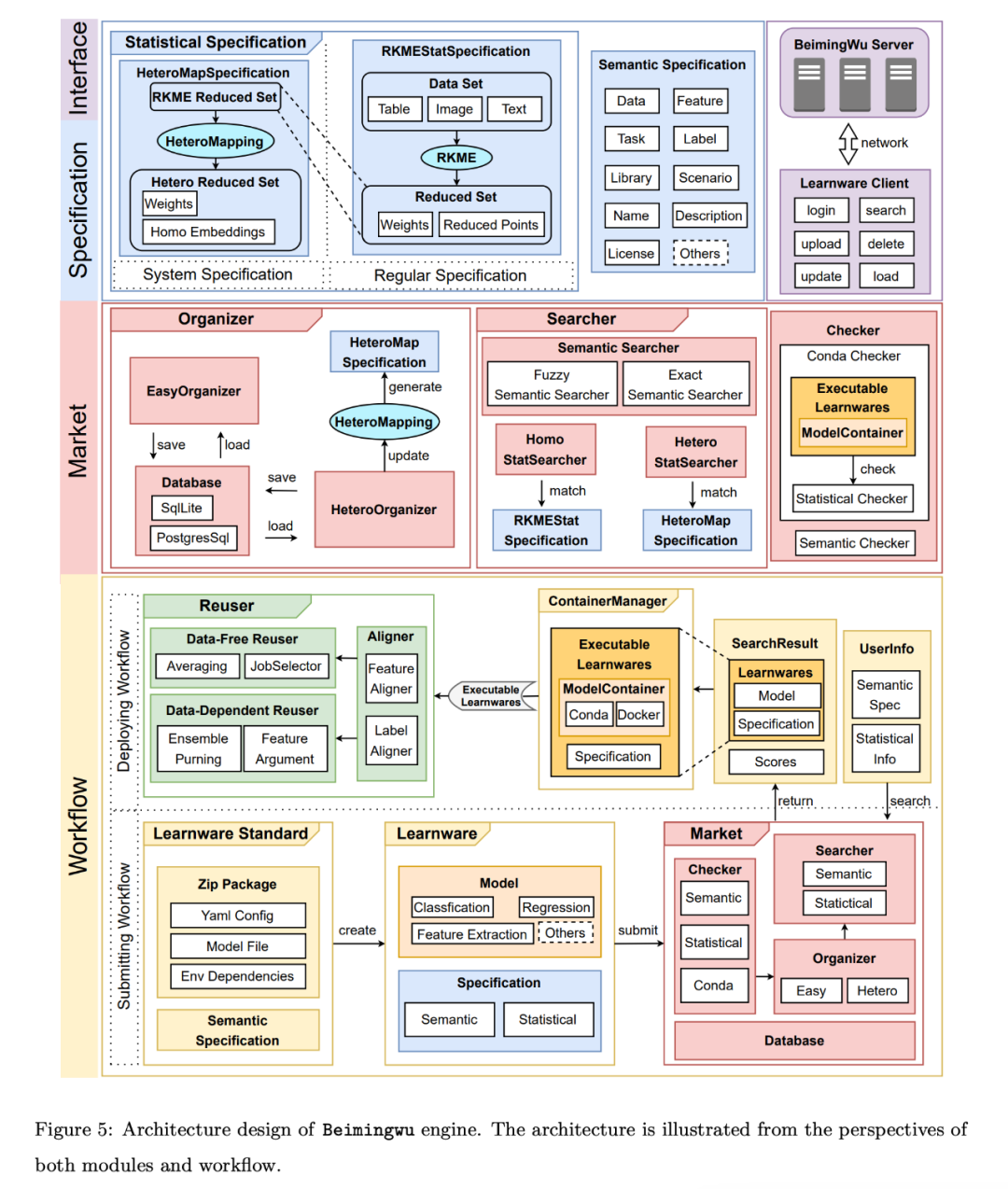
Couche backend du système. Afin de parvenir à un déploiement stable de Beimingwu, l'auteur a développé le backend du système basé sur la couche moteur principale. Grâce à la conception de plusieurs modules et à un grand nombre de développements techniques, Beimingwu a désormais la capacité de déployer en ligne de manière stable, fournissant une interface de programme d'application back-end unifiée pour le front-end et le client.
Afin de garantir un fonctionnement efficace et stable du système, l'auteur a effectué un certain nombre d'optimisations techniques dans la couche backend du système, notamment la vérification du logiciel d'apprentissage asynchrone, une concurrence élevée sur plusieurs nœuds backend, la gestion des autorisations au niveau de l'interface, le backend séparation en lecture-écriture de la base de données et sauvegarde automatique des données système.
Couche d'interface utilisateur. Afin de faciliter l'utilisation des utilisateurs de Beimingwu, l'auteur a développé la couche d'interface utilisateur correspondante, comprenant une interface de navigateur basée sur le réseau et un client de ligne de commande.
Le frontal basé sur le Web fournit à la fois des versions utilisateur et administrateur, fournissant diverses pages d'interaction utilisateur et de gestion du système. De plus, il prend en charge le déploiement multi-nœuds pour un accès fluide au système Beimingwu.
Le client de ligne de commande est intégré au package Python Learningware. En appelant l'interface correspondante, les utilisateurs peuvent appeler l'API backend en ligne via le front-end pour accéder aux modules et algorithmes pertinents du logiciel d'apprentissage.
Évaluation expérimentale
Dans la section 5, l'auteur construit divers types de scénarios expérimentaux de base pour évaluer des algorithmes de référence pour la génération de spécifications, l'identification de didacticiels et la réutilisation sur des données de table, d'image et de texte.
Expériences de données tabulaires
Sur divers ensembles de données tabulaires, les auteurs évaluent d'abord la performance d'identification et de réutilisation des logiciels d'apprentissage du système de logiciels d'apprentissage qui a le même espace de fonctionnalités que la tâche utilisateur. De plus, étant donné que les tâches tabulaires proviennent généralement de différents espaces de fonctionnalités, les auteurs ont également évalué l’identification et la réutilisation d’artefacts d’apprentissage provenant de différents espaces de fonctionnalités.
Cas homogène
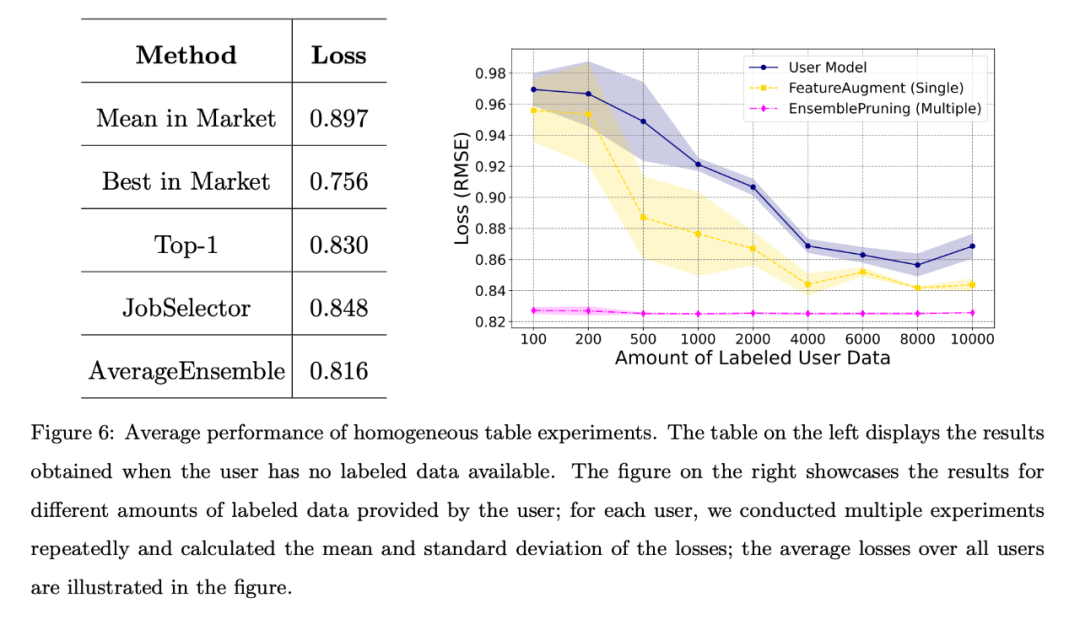
Dans le cas homogène, les 53 magasins de l'ensemble de données PFS agissent comme 53 utilisateurs indépendants. Chaque magasin utilise ses propres données de test comme données de tâches utilisateur et adopte une approche d'ingénierie des fonctionnalités unifiée. Ces utilisateurs peuvent ensuite rechercher dans le système de base des éléments d'apprentissage homogènes partageant le même espace de fonctionnalités que leurs tâches.
Lorsque l'utilisateur ne dispose d'aucune donnée étiquetée ou que la quantité de données étiquetées est limitée, l'auteur a comparé différents algorithmes de base et la perte moyenne de tous les utilisateurs est présentée dans la figure 6. Le tableau de gauche montre que l'approche sans données est bien meilleure que la sélection et le déploiement aléatoires d'un didacticiel du marché ; le graphique de droite montre que lorsque l'utilisateur dispose de données de formation limitées, il est préférable d'identifier et de réutiliser un ou plusieurs didacticiels plutôt que de former l'utilisateur. modèles. Meilleures performances.
Cas hétérogènes
Sur la base de la similitude entre les logiciels du marché et les tâches des utilisateurs, les cas hétérogènes peuvent être divisés en différentes ingénieries de fonctionnalités et différents scénarios de tâches.
Différents scénarios d'ingénierie de fonctionnalités : les résultats présentés sur le côté gauche de la figure 7 montrent que même si l'utilisateur manque de données d'annotation, le logiciel d'apprentissage du système peut afficher de solides performances, en particulier la méthode AverageEnsemble qui réutilise plusieurs logiciels d'apprentissage.
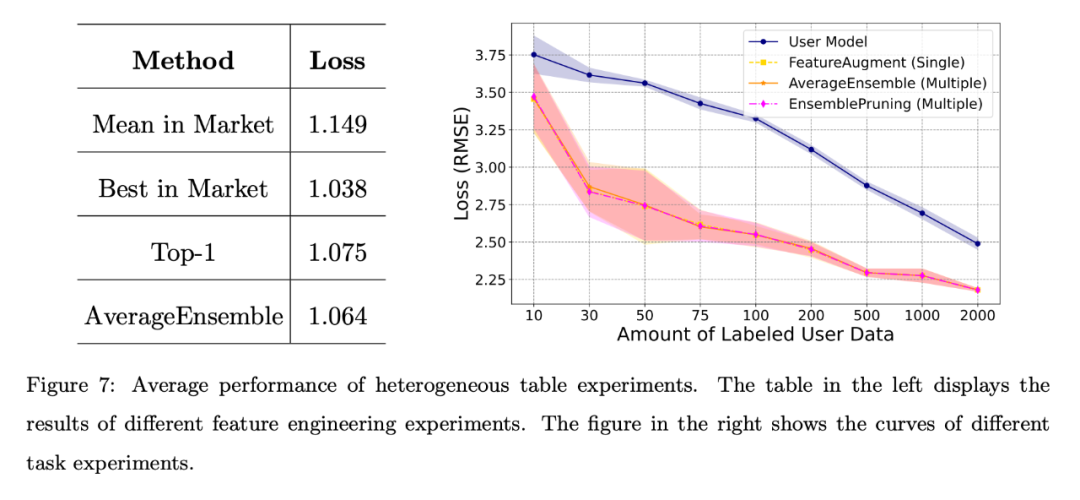
Différents scénarios de mission. Le côté droit de la figure 7 montre les courbes de perte du modèle d'utilisateur auto-formé et plusieurs méthodes de réutilisation des logiciels d'apprentissage. De toute évidence, la vérification expérimentale de composants d'apprentissage hétérogènes est bénéfique lorsque la quantité de données annotées par l'utilisateur est limitée et permet de mieux s'aligner sur l'espace de fonctionnalités de l'utilisateur.
Expériences sur les données d'images et de texte
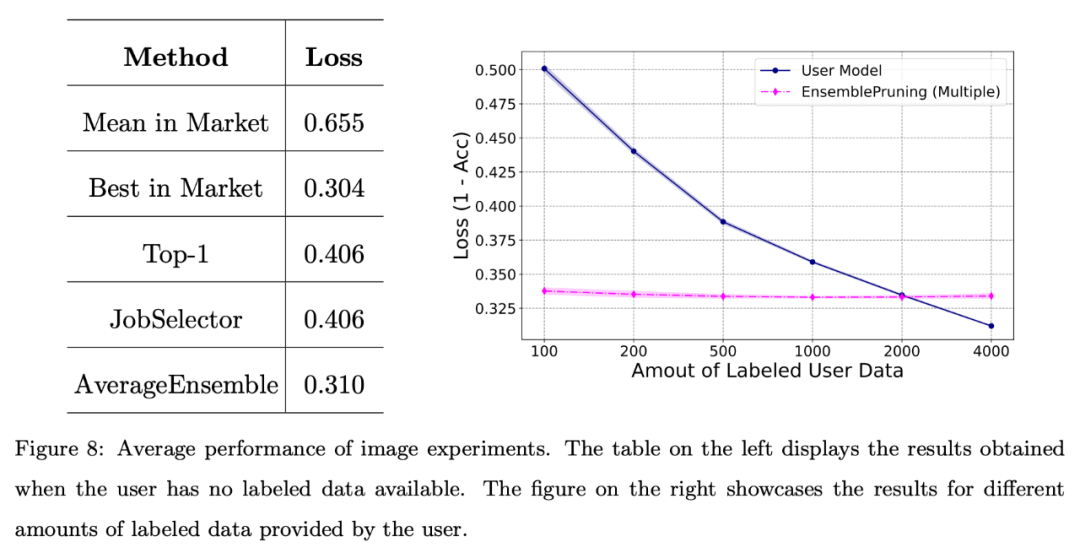
De plus, l'auteur a mené une évaluation de base du système sur des ensembles de données d'images.
La figure 8 montre que l'exploitation d'un système de base d'apprentissage peut générer de bonnes performances lorsque les utilisateurs sont confrontés à une pénurie de données annotées ou ne disposent que d'une quantité limitée de données (moins de 2 000 instances).
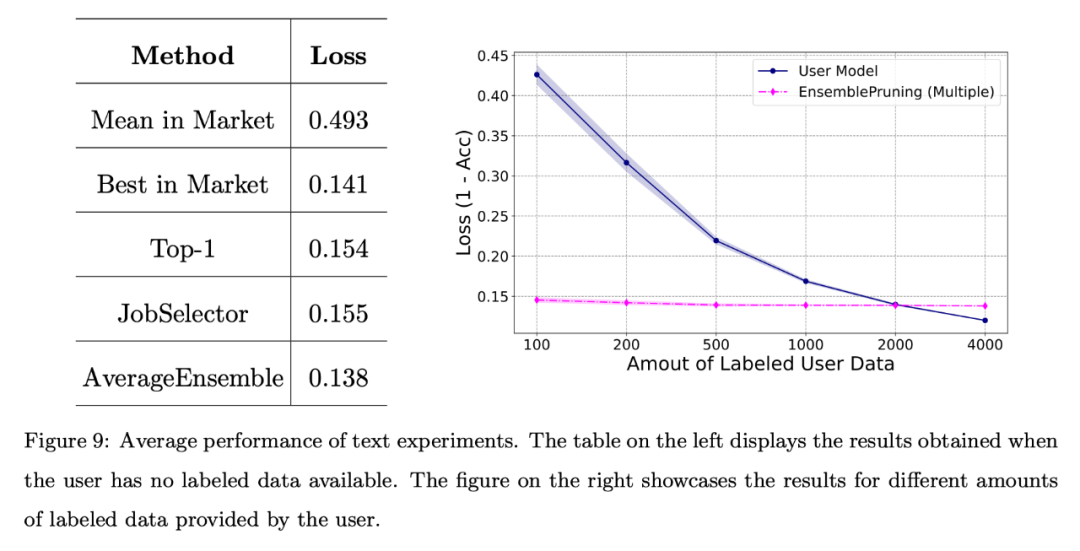
Enfin, l'auteur a mené une évaluation de base du système sur un ensemble de données textuelles de référence. Alignement de l’espace des fonctionnalités via un extracteur de fonctionnalités unifié.
Les résultats sont présentés dans la figure 9. Encore une fois, même lorsqu'aucune donnée d'annotation n'est fournie, les performances obtenues grâce à l'identification et à la réutilisation des logiciels d'apprentissage sont comparables à celles du meilleur logiciel d'apprentissage du système. De plus, l’utilisation du système de base d’apprentissage a permis d’obtenir environ 2 000 échantillons de moins par rapport à la formation du modèle à partir de zéro.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.
Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Mais peut-être qu’il ne pourra pas vaincre le vieil homme dans le parc ? Les Jeux Olympiques de Paris battent leur plein et le tennis de table suscite beaucoup d'intérêt. Dans le même temps, les robots ont également réalisé de nouvelles avancées dans le domaine du tennis de table. DeepMind vient tout juste de proposer le premier agent robot apprenant capable d'atteindre le niveau des joueurs amateurs humains de tennis de table de compétition. Adresse papier : https://arxiv.org/pdf/2408.03906 Quelle est la capacité du robot DeepMind à jouer au tennis de table ? Probablement à égalité avec les joueurs amateurs humains : tant en coup droit qu'en revers : l'adversaire utilise une variété de styles de jeu, et le robot peut également résister : recevoir des services avec des tours différents : Cependant, l'intensité du jeu ne semble pas aussi intense que le vieil homme dans le parc. Pour les robots, le tennis de table
 La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
Le 21 août, la Conférence mondiale sur les robots 2024 s'est tenue en grande pompe à Pékin. La marque de robots domestiques de SenseTime, "Yuanluobot SenseRobot", a dévoilé toute sa famille de produits et a récemment lancé le robot de jeu d'échecs Yuanluobot AI - Chess Professional Edition (ci-après dénommé "Yuanluobot SenseRobot"), devenant ainsi le premier robot d'échecs au monde pour le maison. En tant que troisième produit robot jouant aux échecs de Yuanluobo, le nouveau robot Guoxiang a subi un grand nombre de mises à niveau techniques spéciales et d'innovations en matière d'IA et de machines d'ingénierie. Pour la première fois, il a réalisé la capacité de ramasser des pièces d'échecs en trois dimensions. grâce à des griffes mécaniques sur un robot domestique et effectuer des fonctions homme-machine telles que jouer aux échecs, tout le monde joue aux échecs, réviser la notation, etc.
 Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
La rentrée scolaire est sur le point de commencer, et ce ne sont pas seulement les étudiants qui sont sur le point de commencer le nouveau semestre qui doivent prendre soin d’eux-mêmes, mais aussi les grands modèles d’IA. Il y a quelque temps, Reddit était rempli d'internautes se plaignant de la paresse de Claude. « Son niveau a beaucoup baissé, il fait souvent des pauses et même la sortie devient très courte. Au cours de la première semaine de sortie, il pouvait traduire un document complet de 4 pages à la fois, mais maintenant il ne peut même plus produire une demi-page. !" https://www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ dans un post intitulé "Totalement déçu par Claude", plein de
 Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference qui se tient à Pékin, l'exposition de robots humanoïdes est devenue le centre absolu de la scène. Sur le stand Stardust Intelligent, l'assistant robot IA S1 a réalisé trois performances majeures de dulcimer, d'arts martiaux et de calligraphie. un espace d'exposition, capable à la fois d'arts littéraires et martiaux, a attiré un grand nombre de publics professionnels et de médias. Le jeu élégant sur les cordes élastiques permet au S1 de démontrer un fonctionnement fin et un contrôle absolu avec vitesse, force et précision. CCTV News a réalisé un reportage spécial sur l'apprentissage par imitation et le contrôle intelligent derrière "Calligraphy". Le fondateur de la société, Lai Jie, a expliqué que derrière les mouvements soyeux, le côté matériel recherche le meilleur contrôle de la force et les indicateurs corporels les plus humains (vitesse, charge). etc.), mais du côté de l'IA, les données réelles de mouvement des personnes sont collectées, permettant au robot de devenir plus fort lorsqu'il rencontre une situation forte et d'apprendre à évoluer rapidement. Et agile
 L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
Intégration profonde de la vision et de l'apprentissage des robots. Lorsque deux mains de robot travaillent ensemble en douceur pour plier des vêtements, verser du thé et emballer des chaussures, associées au robot humanoïde 1X NEO qui a fait la une des journaux récemment, vous pouvez avoir le sentiment : nous semblons entrer dans l'ère des robots. En fait, ces mouvements soyeux sont le produit d’une technologie robotique avancée + d’une conception de cadre exquise + de grands modèles multimodaux. Nous savons que les robots utiles nécessitent souvent des interactions complexes et exquises avec l’environnement, et que l’environnement peut être représenté comme des contraintes dans les domaines spatial et temporel. Par exemple, si vous souhaitez qu'un robot verse du thé, le robot doit d'abord saisir la poignée de la théière et la maintenir verticalement sans renverser le thé, puis la déplacer doucement jusqu'à ce que l'embouchure de la théière soit alignée avec l'embouchure de la tasse. , puis inclinez la théière selon un certain angle. ce
 Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Les contributeurs ont beaucoup gagné de cette conférence ACL. L'ACL2024, d'une durée de six jours, se tient à Bangkok, en Thaïlande. ACL est la plus grande conférence internationale dans le domaine de la linguistique informatique et du traitement du langage naturel. Elle est organisée par l'Association internationale pour la linguistique informatique et a lieu chaque année. L'ACL s'est toujours classée première en termes d'influence académique dans le domaine de la PNL, et c'est également une conférence recommandée par le CCF-A. La conférence ACL de cette année est la 62e et a reçu plus de 400 travaux de pointe dans le domaine de la PNL. Hier après-midi, la conférence a annoncé le meilleur article et d'autres récompenses. Cette fois, il y a 7 Best Paper Awards (deux inédits), 1 Best Theme Paper Award et 35 Outstanding Paper Awards. La conférence a également décerné 3 Resource Paper Awards (ResourceAward) et Social Impact Award (
 Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Cet après-midi, Hongmeng Zhixing a officiellement accueilli de nouvelles marques et de nouvelles voitures. Le 6 août, Huawei a organisé la conférence de lancement de nouveaux produits Hongmeng Smart Xingxing S9 et Huawei, réunissant la berline phare intelligente panoramique Xiangjie S9, le nouveau M7Pro et Huawei novaFlip, MatePad Pro 12,2 pouces, le nouveau MatePad Air, Huawei Bisheng With de nombreux nouveaux produits intelligents tous scénarios, notamment la série d'imprimantes laser X1, FreeBuds6i, WATCHFIT3 et l'écran intelligent S5Pro, des voyages intelligents, du bureau intelligent aux vêtements intelligents, Huawei continue de construire un écosystème intelligent complet pour offrir aux consommateurs une expérience intelligente du Internet de tout. Hongmeng Zhixing : Autonomisation approfondie pour promouvoir la modernisation de l'industrie automobile intelligente Huawei s'associe à ses partenaires de l'industrie automobile chinoise pour fournir
 Le premier grand modèle d'interface utilisateur en Chine est lancé ! Le grand modèle de Motiff crée le meilleur assistant pour les concepteurs et optimise le flux de travail de conception d'interface utilisateur
Aug 19, 2024 pm 04:48 PM
Le premier grand modèle d'interface utilisateur en Chine est lancé ! Le grand modèle de Motiff crée le meilleur assistant pour les concepteurs et optimise le flux de travail de conception d'interface utilisateur
Aug 19, 2024 pm 04:48 PM
L’intelligence artificielle se développe plus rapidement que vous ne l’imaginez. Depuis que GPT-4 a introduit la technologie multimodale aux yeux du public, les grands modèles multimodaux sont entrés dans une phase de développement rapide, passant progressivement de la recherche et du développement de modèles purs à l'exploration et à l'application dans des domaines verticaux, et sont profondément intégrés dans tous les horizons. Dans le domaine de l'interaction des interfaces, des géants internationaux de la technologie tels que Google et Apple ont investi dans la recherche et le développement de grands modèles d'interface utilisateur multimodaux, ce qui est considéré comme la seule voie à suivre pour la révolution de l'IA des téléphones mobiles. C’est dans ce contexte qu’est né le premier modèle d’assurance-chômage à grande échelle en Chine. Le 17 août, lors de la conférence internationale sur la conception d'expériences IXDC2024, Motiff, un outil de conception à l'ère de l'IA, a lancé son modèle multimodal d'interface utilisateur développé indépendamment - Motiff Model. Il s'agit du premier outil de conception d'interface utilisateur au monde
