
 Java
javaDidacticiel
Cinq types courants de stratégies de partition Kafka et analyse de leurs caractéristiques
Java
javaDidacticiel
Cinq types courants de stratégies de partition Kafka et analyse de leurs caractéristiques
Cinq types courants de stratégies de partition Kafka et analyse de leurs caractéristiques


Cinq types courants de stratégies de partition Kafka et leurs caractéristiques
La stratégie de partition Kafka détermine la manière dont les messages sont distribués sur différentes partitions pour obtenir un équilibrage de charge et une haute disponibilité. Kafka prend en charge cinq stratégies de partitionnement courantes, à savoir :
- Round-robin : il s'agit de la stratégie de partitionnement la plus simple, qui distribue les messages de manière uniforme sur toutes les partitions. L'avantage de cette stratégie est qu'elle est simple et facile à utiliser, mais l'inconvénient est qu'elle peut entraîner une surcharge de certaines partitions et une sous-charge d'autres partitions.
- Stratégie aléatoire (Random) : Cette stratégie distribue les messages de manière aléatoire à toutes les partitions. L'avantage de cette stratégie est qu'elle peut éviter le problème de charge inégale qui peut survenir dans la stratégie d'interrogation, mais l'inconvénient est qu'elle peut entraîner une surcharge de certaines partitions et une sous-charge d'autres partitions.
- Consistent Hashing : Cette stratégie distribue les messages aux partitions afin que les messages avec la même clé soient toujours distribués sur la même partition. L'avantage de cette stratégie est qu'elle garantit que les messages avec la même clé sont toujours stockés sur la même partition, mais l'inconvénient est qu'elle peut entraîner une surcharge de certaines partitions et une sous-charge d'autres partitions.
- Partitionnement des clés : Cette stratégie distribue les messages aux partitions afin que les messages avec la même clé soient toujours distribués sur la même partition. L'avantage de cette stratégie est qu'elle garantit que les messages avec la même clé sont toujours stockés sur la même partition, mais l'inconvénient est qu'elle peut entraîner une surcharge de certaines partitions et une sous-charge d'autres partitions.
- Range Partitioning : Cette stratégie distribue les messages aux partitions afin que les messages avec des clés dans la même plage soient toujours distribués sur la même partition. L'avantage de cette stratégie est qu'elle garantit que les messages avec la même plage de clés sont toujours stockés sur la même partition, mais l'inconvénient est qu'elle peut entraîner une surcharge de certaines partitions et une sous-charge d'autres partitions.
Considérations lors du choix d'une stratégie de partitionnement
Lors du choix d'une stratégie de partitionnement, vous devez prendre en compte les facteurs suivants :
- Type de message : Si les messages ont la même clé, vous pouvez utiliser une stratégie de hachage cohérente ou Stratégie de partitionnement des clés. Si les messages n'ont pas la même clé, vous pouvez utiliser une stratégie round-robin ou une stratégie aléatoire.
- Nombre de partitions : Le nombre de partitions doit correspondre à la taille du cluster. Si le nombre de partitions est trop petit, certaines partitions peuvent être surchargées et d'autres sous-chargées. S'il y a trop de partitions, cela peut entraîner une surcharge excessive de gestion des partitions.
- Équilibrage de charge : La stratégie de partitionnement doit être capable d'atteindre un équilibrage de charge pour éviter que certaines partitions ne soient surchargées tandis que d'autres sont sous-chargées.
- Haute disponibilité : La stratégie de partitionnement doit être capable de garantir une haute disponibilité des messages pour éviter la perte de messages due à une défaillance de partition.
Conclusion
La stratégie de partitionnement Kafka détermine la manière dont les messages sont distribués sur différentes partitions pour obtenir un équilibrage de charge et une haute disponibilité. Kafka prend en charge cinq stratégies de partitionnement courantes, à savoir la stratégie d'interrogation, la stratégie aléatoire, la stratégie de hachage cohérente, la stratégie de partitionnement par clé et la stratégie de partitionnement par plage. Lorsque vous choisissez une stratégie de partitionnement, vous devez prendre en compte des facteurs tels que le type de message, le nombre de partitions, l'équilibrage de charge et la haute disponibilité.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

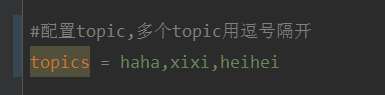 Comment spécifier dynamiquement plusieurs sujets à l'aide de @KafkaListener dans springboot+kafka
May 20, 2023 pm 08:58 PM
Comment spécifier dynamiquement plusieurs sujets à l'aide de @KafkaListener dans springboot+kafka
May 20, 2023 pm 08:58 PM
Expliquez que ce projet est un projet d'intégration springboot+kafak, il utilise donc l'annotation de consommation kafak @KafkaListener dans springboot. Tout d'abord, configurez plusieurs sujets séparés par des virgules dans application.properties. Méthode : utilisez l'expression SpEl de Spring pour configurer les sujets comme : @KafkaListener(topics="#{’${topics}’.split(’,’)}") pour exécuter le programme. L'effet d'impression de la console est le suivant.
 Comment mettre en œuvre une analyse boursière en temps réel à l'aide de PHP et Kafka
Jun 28, 2023 am 10:04 AM
Comment mettre en œuvre une analyse boursière en temps réel à l'aide de PHP et Kafka
Jun 28, 2023 am 10:04 AM
Avec le développement d’Internet et de la technologie, l’investissement numérique est devenu un sujet de préoccupation croissant. De nombreux investisseurs continuent d’explorer et d’étudier des stratégies d’investissement, dans l’espoir d’obtenir un retour sur investissement plus élevé. Dans le domaine du trading d'actions, l'analyse boursière en temps réel est très importante pour la prise de décision, et l'utilisation de la file d'attente de messages en temps réel Kafka et de la technologie PHP constitue un moyen efficace et pratique. 1. Introduction à Kafka Kafka est un système de messagerie distribué de publication et d'abonnement à haut débit développé par LinkedIn. Les principales fonctionnalités de Kafka sont
 Comment SpringBoot intègre la classe d'outils de configuration Kafka
May 12, 2023 pm 09:58 PM
Comment SpringBoot intègre la classe d'outils de configuration Kafka
May 12, 2023 pm 09:58 PM
spring-kafka est basé sur l'intégration de la version java de kafkaclient et spring. Il fournit KafkaTemplate, qui encapsule diverses méthodes pour une utilisation facile. Il encapsule le client kafka d'Apache, et il n'est pas nécessaire d'importer le client pour dépendre de l'organisation. .springframework.kafkaspring-kafkaYML configuration kafka:#bootstrap-servers:server1:9092,server2:9093#adresse de développement de kafka,#producteur de configuration du producteur:#clé de classe de sérialisation et de désérialisation fournie par Kafka.
 Cinq sélections d'outils de visualisation pour explorer Kafka
Feb 01, 2024 am 08:03 AM
Cinq sélections d'outils de visualisation pour explorer Kafka
Feb 01, 2024 am 08:03 AM
Cinq options pour les outils de visualisation Kafka ApacheKafka est une plateforme de traitement de flux distribué capable de traiter de grandes quantités de données en temps réel. Il est largement utilisé pour créer des pipelines de données en temps réel, des files d'attente de messages et des applications basées sur des événements. Les outils de visualisation de Kafka peuvent aider les utilisateurs à surveiller et gérer les clusters Kafka et à mieux comprendre les flux de données Kafka. Ce qui suit est une introduction à cinq outils de visualisation Kafka populaires : ConfluentControlCenterConfluent
 Analyse comparative des outils de visualisation kafka : Comment choisir l'outil le plus approprié ?
Jan 05, 2024 pm 12:15 PM
Analyse comparative des outils de visualisation kafka : Comment choisir l'outil le plus approprié ?
Jan 05, 2024 pm 12:15 PM
Comment choisir le bon outil de visualisation Kafka ? Analyse comparative de cinq outils Introduction : Kafka est un système de file d'attente de messages distribué à haute performance et à haut débit, largement utilisé dans le domaine du Big Data. Avec la popularité de Kafka, de plus en plus d'entreprises et de développeurs ont besoin d'un outil visuel pour surveiller et gérer facilement les clusters Kafka. Cet article présentera cinq outils de visualisation Kafka couramment utilisés et comparera leurs caractéristiques et fonctions pour aider les lecteurs à choisir l'outil qui répond à leurs besoins. 1. KafkaManager
 Comment installer Apache Kafka sur Rocky Linux ?
Mar 01, 2024 pm 10:37 PM
Comment installer Apache Kafka sur Rocky Linux ?
Mar 01, 2024 pm 10:37 PM
Pour installer ApacheKafka sur RockyLinux, vous pouvez suivre les étapes suivantes : Mettre à jour le système : Tout d'abord, assurez-vous que votre système RockyLinux est à jour, exécutez la commande suivante pour mettre à jour les packages système : sudoyumupdate Installer Java : ApacheKafka dépend de Java, vous vous devez d'abord installer JavaDevelopmentKit (JDK). OpenJDK peut être installé via la commande suivante : sudoyuminstalljava-1.8.0-openjdk-devel Télécharger et décompresser : Visitez le site officiel d'ApacheKafka () pour télécharger le dernier package binaire. Choisissez une version stable
 La pratique du go-zero et Kafka+Avro : construire un système de traitement de données interactif performant
Jun 23, 2023 am 09:04 AM
La pratique du go-zero et Kafka+Avro : construire un système de traitement de données interactif performant
Jun 23, 2023 am 09:04 AM
Ces dernières années, avec l'essor du Big Data et des communautés open source actives, de plus en plus d'entreprises ont commencé à rechercher des systèmes de traitement de données interactifs hautes performances pour répondre aux besoins croissants en matière de données. Dans cette vague de mises à niveau technologiques, le go-zero et Kafka+Avro suscitent l’attention et sont adoptés par de plus en plus d’entreprises. go-zero est un framework de microservices développé sur la base du langage Golang. Il présente les caractéristiques de hautes performances, de facilité d'utilisation, d'extension facile et de maintenance facile. Il est conçu pour aider les entreprises à créer rapidement des systèmes d'applications de microservices efficaces. sa croissance rapide
 Comment créer des applications de traitement de données en temps réel à l'aide de React et Apache Kafka
Sep 27, 2023 pm 02:25 PM
Comment créer des applications de traitement de données en temps réel à l'aide de React et Apache Kafka
Sep 27, 2023 pm 02:25 PM
Comment utiliser React et Apache Kafka pour créer des applications de traitement de données en temps réel Introduction : Avec l'essor du Big Data et du traitement de données en temps réel, la création d'applications de traitement de données en temps réel est devenue la priorité de nombreux développeurs. La combinaison de React, un framework front-end populaire, et d'Apache Kafka, un système de messagerie distribué hautes performances, peut nous aider à créer des applications de traitement de données en temps réel. Cet article expliquera comment utiliser React et Apache Kafka pour créer des applications de traitement de données en temps réel, et
