
 Périphériques technologiques
Industrie informatique
L'application 360 AI Search est lancée : sur la base de l'exploration 'crawler' et des données soumises par les utilisateurs, elle génère des réponses logiquement claires, bien fondées et traçables jusqu'à la source.
Périphériques technologiques
Industrie informatique
L'application 360 AI Search est lancée : sur la base de l'exploration 'crawler' et des données soumises par les utilisateurs, elle génère des réponses logiquement claires, bien fondées et traçables jusqu'à la source.
L'application 360 AI Search est lancée : sur la base de l'exploration 'crawler' et des données soumises par les utilisateurs, elle génère des réponses logiquement claires, bien fondées et traçables jusqu'à la source.

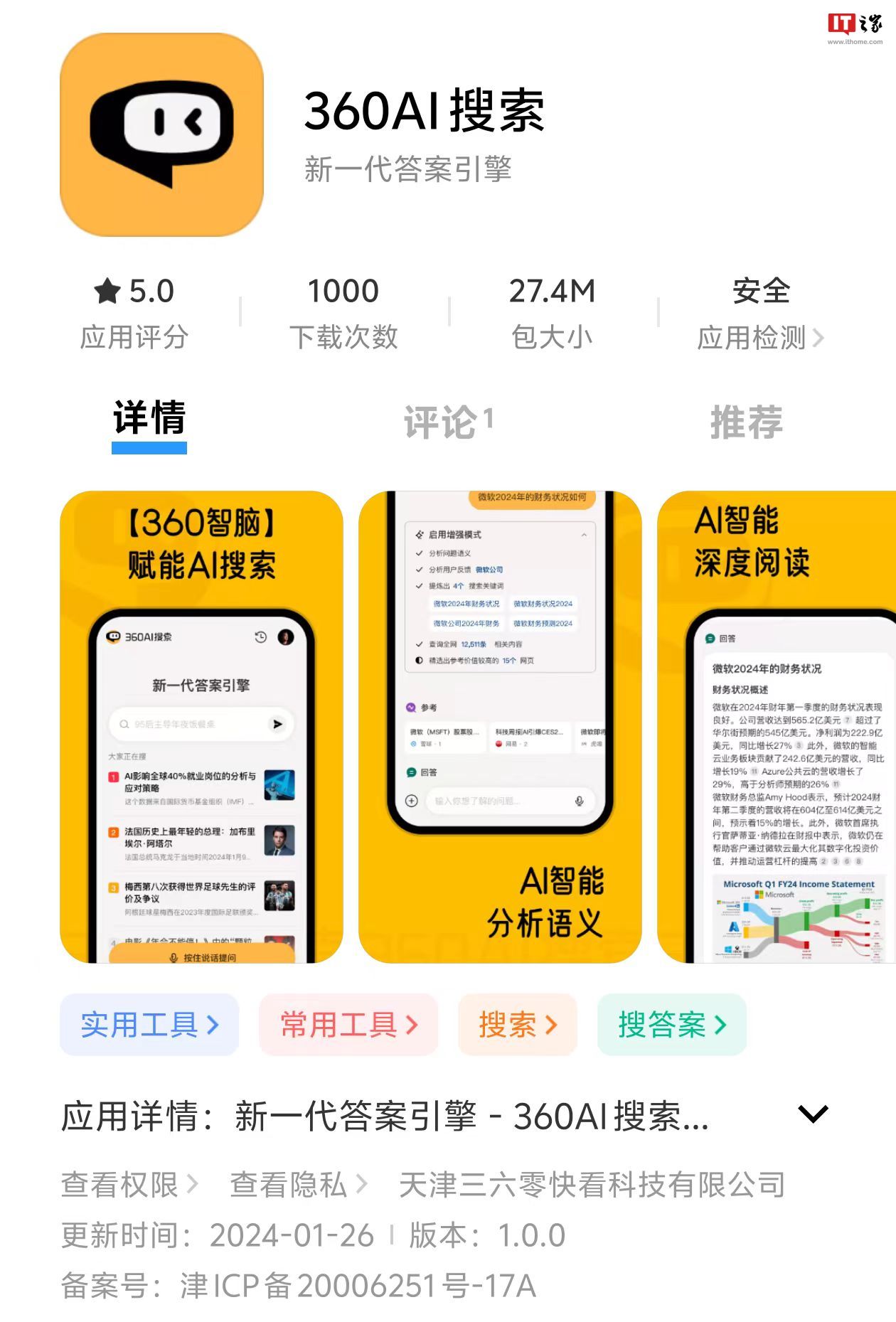
Ce site Web a rapporté le 29 janvier que l'application 360 AI Search avait été lancée dans les principaux centres d'applications mobiles. La version actuelle est la 1.0.0, La taille du package d'installation est de 27,4 Mo, Il n'y a pas d'option de chargement pour le moment.
Selon la description officielle, toute question saisie par l'utilisateur lors de l'utilisation de la recherche 360 AI déclenchera une série de processus de traitement complexes pour générer des réponses.
Tout d'abord, 360 Big Model effectuera une analyse du problème s'il s'avère que le problème est ambigu ou que des informations clés sont manquantes, il demandera de manière proactive des éclaircissements ou complétera les informations manquantes de l'utilisateur. Les grands modèles décomposent des problèmes de recherche complexes en plusieurs mots-clés couvrant différentes directions.
Ensuite, ces mots-clés sont récupérés sur des millions de pages Web via la recherche 360 et reclassés en fonction des questions de l'utilisateur.
Ensuite, le grand modèle extrait le contenu de dizaines de pages Web qui correspondent à la question de l'utilisateur.
Après cela, la recherche 360AI générera des réponses logiquement claires, bien fondées et traçables en fonction des questions de l'utilisateur.
Caractéristiques du produit :
Recherche IA : une fois que l'utilisateur a posé une question, l'IA la récupérera via le moteur de recherche, lira et analysera le contenu de plusieurs pages Web et produira des conclusions précises.
Mode amélioré : Une fois que l'utilisateur a posé une question, l'IA effectuera une analyse sémantique et posera des questions pour compléter plus d'informations. Ensuite, l'IA divise la question en plusieurs groupes de mots-clés pour la récupération par les moteurs de recherche, lit davantage de contenu Web en profondeur et génère des réponses logiquement claires et précises.
Il est entendu que "360 Search" fonctionne sur la base des données capturées par "Spider" et des données activement soumises par les utilisateurs, c'est-à-dire que le robot d'exploration de "360 Search" démarrera à partir de certaines pages Web et passer par La relation de lien mutuel entre les pages Web, combinée aux données activement soumises par les utilisateurs, pour accéder et télécharger des hyperliens sur Internet.
"360 Search" générera des résultats de recherche basés sur les mots-clés saisis par l'utilisateur dans le champ de recherche et les instructions de recherche émises, et sur la base d'un algorithme unique Le contenu des résultats de recherche est un certain nombre de sites Web tiers. liens liés aux mots-clés .
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Ce guide vous guidera pour apprendre à utiliser Syslog dans Debian Systems. Syslog est un service clé dans les systèmes Linux pour les messages du système de journalisation et du journal d'application. Il aide les administrateurs à surveiller et à analyser l'activité du système pour identifier et résoudre rapidement les problèmes. 1. Connaissance de base de Syslog Les fonctions principales de Syslog comprennent: la collecte et la gestion des messages journaux de manière centralisée; Prise en charge de plusieurs formats de sortie de journal et des emplacements cibles (tels que les fichiers ou les réseaux); Fournir des fonctions de visualisation et de filtrage des journaux en temps réel. 2. Installer et configurer syslog (en utilisant RSYSLOG) Le système Debian utilise RSYSLOG par défaut. Vous pouvez l'installer avec la commande suivante: SudoaptupDatesud
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment configurer les règles de pare-feu pour Debian Syslog
Apr 13, 2025 am 06:51 AM
Comment configurer les règles de pare-feu pour Debian Syslog
Apr 13, 2025 am 06:51 AM
Cet article décrit comment configurer les règles de pare-feu à l'aide d'iptables ou UFW dans Debian Systems et d'utiliser Syslog pour enregistrer les activités de pare-feu. Méthode 1: Utiliser iptableIpTable est un puissant outil de pare-feu de ligne de commande dans Debian System. Afficher les règles existantes: utilisez la commande suivante pour afficher les règles iptables actuelles: Sudoiptables-L-N-V permet un accès IP spécifique: Par exemple, permettez l'adresse IP 192.168.1.100 pour accéder au port 80: Sudoiptables-Ainput-PTCP - DPORT80-S192.16
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
