
 Java
javaDidacticiel
Explication détaillée des paramètres de commande de démarrage de Kafka et suggestions d'optimisation
Java
javaDidacticiel
Explication détaillée des paramètres de commande de démarrage de Kafka et suggestions d'optimisation
Explication détaillée des paramètres de commande de démarrage de Kafka et suggestions d'optimisation


Guide d'analyse et d'optimisation des paramètres de la commande de démarrage Kafka
1. Analyse des paramètres de la commande de démarrage
Le format de la commande de démarrage Kafka est le suivant :
kafka-server-start.sh [options] [config.file]
Parmi eux, options</code > est les paramètres de la commande de démarrage, <code>config.file est le fichier de configuration Kafka. options是启动命令的参数,config.file是Kafka配置文件。
常见的启动命令参数有:
-daemon: 以守护进程的方式启动Kafka。-port: 指定Kafka监听的端口号。默认端口号为9092。-log.dirs: 指定Kafka日志文件的存储目录。-zookeeper.connect: 指定Kafka连接ZooKeeper的地址。-broker.id: 指定Kafka代理的ID。-num.partitions: 指定每个主题的分区数。-replication.factor: 指定每个主题的副本数。-min.insync.replicas: 指定每个主题的最小同步副本数。
2. 启动命令参数优化
为了提高Kafka的性能,我们可以对启动命令参数进行优化。
常见的优化参数有:
-num.io.threads: 指定Kafka处理IO请求的线程数。默认值为8。-num.network.threads: 指定Kafka处理网络请求的线程数。默认值为8。-num.replica.fetchers: 指定每个副本从领导者副本获取数据的线程数。默认值为1。-num.replica.alter.log.dirs.threads: 指定更改副本日志文件存储目录的线程数。默认值为1。-socket.send.buffer.bytes: 指定Kafka发送数据的套接字缓冲区大小。默认值为102400。-socket.receive.buffer.bytes: 指定Kafka接收数据的套接字缓冲区大小。默认值为102400。-log.segment.bytes: 指定Kafka日志分段的大小。默认值为1073741824。-log.retention.hours: 指定Kafka日志保留的小时数。默认值为24。-log.retention.minutes
-daemon : démarrez Kafka en tant que processus démon.
-port : spécifiez le numéro de port sur lequel Kafka écoute. Le numéro de port par défaut est 9092. -log.dirs : Spécifiez le répertoire de stockage des fichiers journaux Kafka. -zookeeper.connect : Spécifiez l'adresse à laquelle Kafka se connecte à ZooKeeper. -broker.id : Spécifiez l'ID du courtier Kafka. -num.partitions : Spécifiez le nombre de partitions pour chaque sujet. -replication.factor : Spécifie le nombre de répliques par sujet. -min.insync.replicas : Spécifie le nombre minimum de répliques synchronisées par sujet. 🎜2. Optimisation des paramètres de commande de démarrage🎜🎜🎜Afin d'améliorer les performances de Kafka, nous pouvons optimiser les paramètres de commande de démarrage. 🎜🎜🎜Les paramètres d'optimisation courants sont : 🎜🎜-num.io.threads: spécifiez le nombre de threads utilisés par Kafka pour traiter les requêtes IO. La valeur par défaut est 8. 🎜-num.network.threads: Spécifiez le nombre de threads utilisés par Kafka pour traiter les requêtes réseau. La valeur par défaut est 8. 🎜-num.replica.fetchers: Spécifie le nombre de threads pour chaque réplique pour récupérer les données de la réplique principale. La valeur par défaut est 1. 🎜-num.replica.alter.log.dirs.threads: Spécifiez le nombre de threads pour modifier le répertoire dans lequel les fichiers journaux de réplique sont stockés. La valeur par défaut est 1. 🎜-socket.send.buffer.bytes: Spécifie la taille du tampon de socket pour que Kafka envoie des données. La valeur par défaut est 102400. 🎜-socket.receive.buffer.bytes: Spécifie la taille du tampon de socket pour que Kafka reçoive des données. La valeur par défaut est 102400. 🎜-log.segment.bytes: Spécifiez la taille des segments du journal Kafka. La valeur par défaut est 1073741824. 🎜-log.retention.hours: spécifiez le nombre d'heures de conservation des journaux Kafka. La valeur par défaut est 24. 🎜-log.retention.minutes: spécifiez le nombre de minutes de conservation des journaux Kafka. La valeur par défaut est 0. 🎜🎜🎜🎜3. Exemple de code🎜🎜🎜Ce qui suit est un exemple d'optimisation des paramètres de commande de démarrage de Kafka : 🎜🎜🎜4. Résumé🎜🎜🎜En optimisant les paramètres de commande de démarrage de Kafka, nous pouvons améliorer les performances de Kafka. Lors de l'optimisation des paramètres, ils doivent être ajustés en fonction de la situation réelle. 🎜kafka-server-start.sh -daemon -port 9092 -log.dirs /var/log/kafka -zookeeper.connect localhost:2181 -broker.id 0 -num.partitions 1 -replication.factor 1 -min.insync.replicas 1 -num.io.threads 8 -num.network.threads 8 -num.replica.fetchers 1 -num.replica.alter.log.dirs.threads 1 -socket.send.buffer.bytes 102400 -socket.receive.buffer.bytes 102400 -log.segment.bytes 1073741824 -log.retention.hours 24 -log.retention.minutes 0
Copier après la connexionCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment mettre en œuvre une analyse boursière en temps réel à l'aide de PHP et Kafka
Jun 28, 2023 am 10:04 AM
Comment mettre en œuvre une analyse boursière en temps réel à l'aide de PHP et Kafka
Jun 28, 2023 am 10:04 AM
Avec le développement d’Internet et de la technologie, l’investissement numérique est devenu un sujet de préoccupation croissant. De nombreux investisseurs continuent d’explorer et d’étudier des stratégies d’investissement, dans l’espoir d’obtenir un retour sur investissement plus élevé. Dans le domaine du trading d'actions, l'analyse boursière en temps réel est très importante pour la prise de décision, et l'utilisation de la file d'attente de messages en temps réel Kafka et de la technologie PHP constitue un moyen efficace et pratique. 1. Introduction à Kafka Kafka est un système de messagerie distribué de publication et d'abonnement à haut débit développé par LinkedIn. Les principales fonctionnalités de Kafka sont
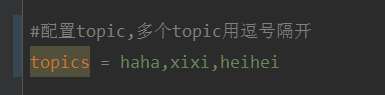 Comment spécifier dynamiquement plusieurs sujets à l'aide de @KafkaListener dans springboot+kafka
May 20, 2023 pm 08:58 PM
Comment spécifier dynamiquement plusieurs sujets à l'aide de @KafkaListener dans springboot+kafka
May 20, 2023 pm 08:58 PM
Expliquez que ce projet est un projet d'intégration springboot+kafak, il utilise donc l'annotation de consommation kafak @KafkaListener dans springboot. Tout d'abord, configurez plusieurs sujets séparés par des virgules dans application.properties. Méthode : utilisez l'expression SpEl de Spring pour configurer les sujets comme : @KafkaListener(topics="#{’${topics}’.split(’,’)}") pour exécuter le programme. L'effet d'impression de la console est le suivant.
 Comment SpringBoot intègre la classe d'outils de configuration Kafka
May 12, 2023 pm 09:58 PM
Comment SpringBoot intègre la classe d'outils de configuration Kafka
May 12, 2023 pm 09:58 PM
spring-kafka est basé sur l'intégration de la version java de kafkaclient et spring. Il fournit KafkaTemplate, qui encapsule diverses méthodes pour une utilisation facile. Il encapsule le client kafka d'Apache, et il n'est pas nécessaire d'importer le client pour dépendre de l'organisation. .springframework.kafkaspring-kafkaYML configuration kafka:#bootstrap-servers:server1:9092,server2:9093#adresse de développement de kafka,#producteur de configuration du producteur:#clé de classe de sérialisation et de désérialisation fournie par Kafka.
 Comment créer des applications de traitement de données en temps réel à l'aide de React et Apache Kafka
Sep 27, 2023 pm 02:25 PM
Comment créer des applications de traitement de données en temps réel à l'aide de React et Apache Kafka
Sep 27, 2023 pm 02:25 PM
Comment utiliser React et Apache Kafka pour créer des applications de traitement de données en temps réel Introduction : Avec l'essor du Big Data et du traitement de données en temps réel, la création d'applications de traitement de données en temps réel est devenue la priorité de nombreux développeurs. La combinaison de React, un framework front-end populaire, et d'Apache Kafka, un système de messagerie distribué hautes performances, peut nous aider à créer des applications de traitement de données en temps réel. Cet article expliquera comment utiliser React et Apache Kafka pour créer des applications de traitement de données en temps réel, et
 Cinq sélections d'outils de visualisation pour explorer Kafka
Feb 01, 2024 am 08:03 AM
Cinq sélections d'outils de visualisation pour explorer Kafka
Feb 01, 2024 am 08:03 AM
Cinq options pour les outils de visualisation Kafka ApacheKafka est une plateforme de traitement de flux distribué capable de traiter de grandes quantités de données en temps réel. Il est largement utilisé pour créer des pipelines de données en temps réel, des files d'attente de messages et des applications basées sur des événements. Les outils de visualisation de Kafka peuvent aider les utilisateurs à surveiller et gérer les clusters Kafka et à mieux comprendre les flux de données Kafka. Ce qui suit est une introduction à cinq outils de visualisation Kafka populaires : ConfluentControlCenterConfluent
 Analyse comparative des outils de visualisation kafka : Comment choisir l'outil le plus approprié ?
Jan 05, 2024 pm 12:15 PM
Analyse comparative des outils de visualisation kafka : Comment choisir l'outil le plus approprié ?
Jan 05, 2024 pm 12:15 PM
Comment choisir le bon outil de visualisation Kafka ? Analyse comparative de cinq outils Introduction : Kafka est un système de file d'attente de messages distribué à haute performance et à haut débit, largement utilisé dans le domaine du Big Data. Avec la popularité de Kafka, de plus en plus d'entreprises et de développeurs ont besoin d'un outil visuel pour surveiller et gérer facilement les clusters Kafka. Cet article présentera cinq outils de visualisation Kafka couramment utilisés et comparera leurs caractéristiques et fonctions pour aider les lecteurs à choisir l'outil qui répond à leurs besoins. 1. KafkaManager
 Exemple de code pour le projet Springboot pour configurer plusieurs kafka
May 14, 2023 pm 12:28 PM
Exemple de code pour le projet Springboot pour configurer plusieurs kafka
May 14, 2023 pm 12:28 PM
1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2. Informations relatives au fichier de configuration kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#Le nombre de threads pouvant être consommés simultanément (généralement cohérent avec le nombre de partitions )kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 La pratique du go-zero et Kafka+Avro : construire un système de traitement de données interactif performant
Jun 23, 2023 am 09:04 AM
La pratique du go-zero et Kafka+Avro : construire un système de traitement de données interactif performant
Jun 23, 2023 am 09:04 AM
Ces dernières années, avec l'essor du Big Data et des communautés open source actives, de plus en plus d'entreprises ont commencé à rechercher des systèmes de traitement de données interactifs hautes performances pour répondre aux besoins croissants en matière de données. Dans cette vague de mises à niveau technologiques, le go-zero et Kafka+Avro suscitent l’attention et sont adoptés par de plus en plus d’entreprises. go-zero est un framework de microservices développé sur la base du langage Golang. Il présente les caractéristiques de hautes performances, de facilité d'utilisation, d'extension facile et de maintenance facile. Il est conçu pour aider les entreprises à créer rapidement des systèmes d'applications de microservices efficaces. sa croissance rapide
