
 Périphériques technologiques
IA
Un chef-d'œuvre de 8 ans de l'équipe de NTU Zhou Zhihua ! Le système « learningware » résout le problème de la réutilisation de l'apprentissage automatique et la « fusion de modèles » fait émerger un nouveau paradigme de recherche scientifique
Périphériques technologiques
IA
Un chef-d'œuvre de 8 ans de l'équipe de NTU Zhou Zhihua ! Le système « learningware » résout le problème de la réutilisation de l'apprentissage automatique et la « fusion de modèles » fait émerger un nouveau paradigme de recherche scientifique
Un chef-d'œuvre de 8 ans de l'équipe de NTU Zhou Zhihua ! Le système « learningware » résout le problème de la réutilisation de l'apprentissage automatique et la « fusion de modèles » fait émerger un nouveau paradigme de recherche scientifique

HuggingFace est la communauté open source d'apprentissage automatique la plus populaire, avec 300 000 modèles d'apprentissage automatique différents et 100 000 applications disponibles.
Si ces 300 000 modèles présents sur HuggingFace pouvaient être librement combinés pour réaliser ensemble de nouvelles tâches d'apprentissage, à quoi cela ressemblerait-il ?
En fait, en 2016, lorsque HuggingFace est sorti, le professeur Zhou Zhihua de l'Université de Nanjing a proposé le concept de « Learnware » et a dessiné un tel plan.
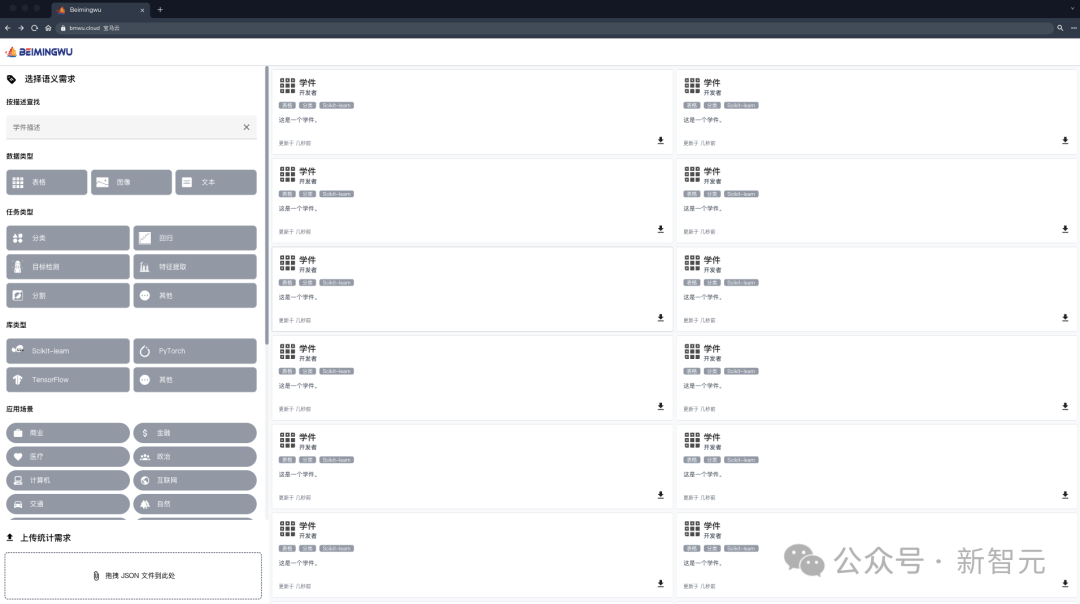
Récemment, l'équipe du professeur Zhou Zhihua de l'Université de Nanjing a lancé une telle plateforme - Beimingwu.
Adresse : https://bmwu.cloud/
Beimingwu offre non seulement aux chercheurs et aux utilisateurs la possibilité de télécharger leurs propres modèles, mais effectue également la mise en correspondance de modèles et la fusion de collaboration en fonction des besoins de l'utilisateur pour gérer efficacement l'apprentissage. Tâches .

Adresse papier : https://arxiv.org/abs/2401.14427
Entrepôt du système Beimingwu : https://www.gitlink.org.cn/beimingwu/beimingwu
Recherche scientifique entrepôt de boîtes à outils : https://www.gitlink.org.cn/beimingwu/learnware
La plus grande caractéristique de cette plate-forme est l'introduction du système d'apprentissage, réalisant ainsi une percée dans la réalisation de modèles basés sur les besoins des utilisateurs. Correspondance adaptative et capacités de collaboration.
Learningware se compose d'un modèle d'apprentissage automatique et d'une spécification décrivant le modèle, c'est-à-dire "learningware = modèle + spécification".
La spécification du logiciel d'apprentissage se compose de deux parties : « spécification sémantique » et « spécification statistique » :
- la spécification sémantique décrit le type et la fonction du modèle à travers le texte
- la spécification statistique utilise divers apprentissages automatiques ; technologies , décrivant les informations statistiques contenues dans le modèle.
La spécification du logiciel d'apprentissage décrit les capacités du modèle, de sorte que le modèle puisse être entièrement reconnu et réutilisé à l'avenir sans que l'utilisateur sache quoi que ce soit à l'avance sur le logiciel d'apprentissage pour répondre aux besoins de l'utilisateur.
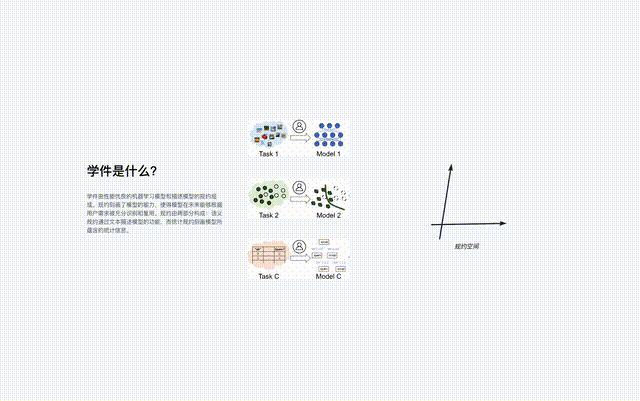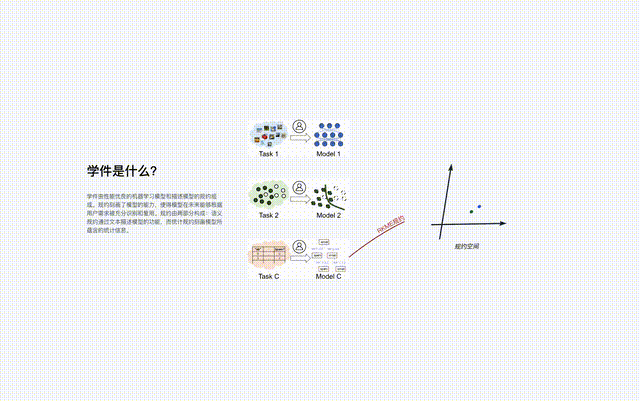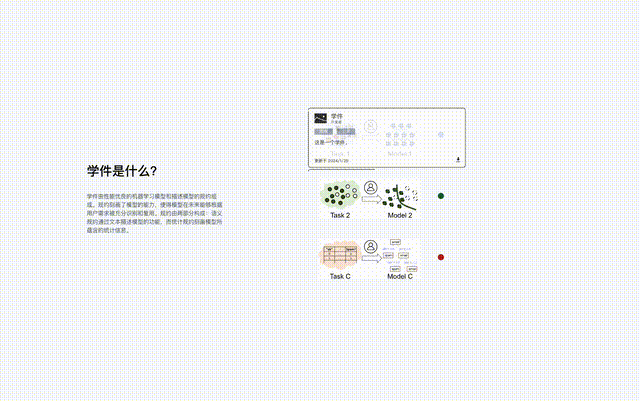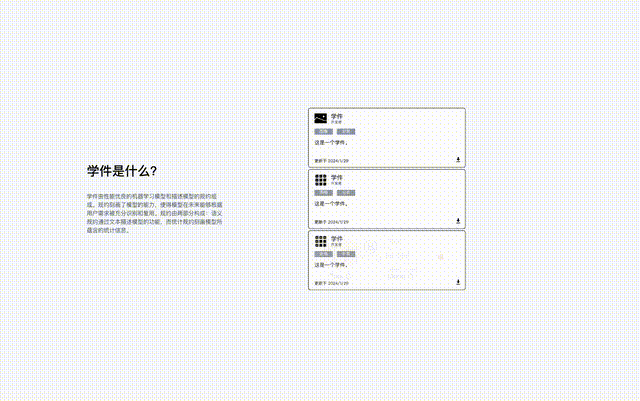
Le protocole est le composant central du système de base du logiciel d'apprentissage, qui connecte tous les processus du logiciel d'apprentissage dans le système, y compris le téléchargement, l'organisation, la recherche, le déploiement et la réutilisation du logiciel d'apprentissage.
Tout comme Yanziwu dans "Dragon" est composé de nombreuses petites îles, les réglementations de Beimingwu sont aussi comme de petites îles.
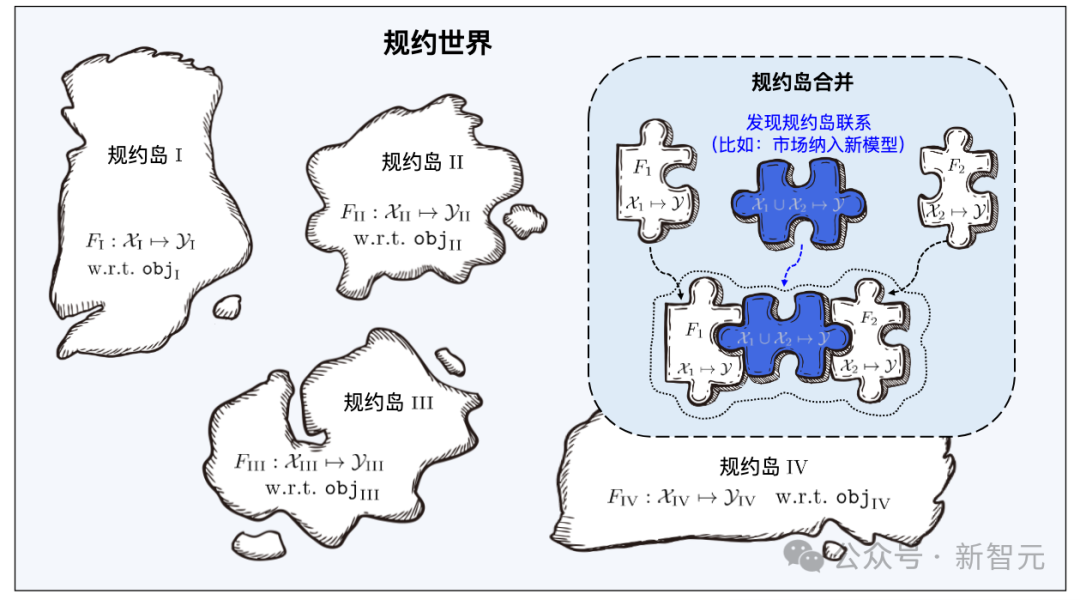
Les logiciels d'apprentissage de différents espaces de fonctionnalités/marqueurs constituent de nombreux îlots de protocole, et tous les îlots de protocole constituent ensemble le monde des protocoles dans le système de base du logiciel d'apprentissage. Dans le monde protocolaire, si les connexions entre les différentes îles peuvent être découvertes et établies, alors les îlots protocolaires correspondants pourront être fusionnés.
Dans le cadre du paradigme du logiciel d'apprentissage, les développeurs du monde entier peuvent partager des modèles avec le système de base du logiciel d'apprentissage. Le système aide les utilisateurs à résoudre efficacement les tâches d'apprentissage automatique en recherchant et en réutilisant efficacement les logiciels d'apprentissage sans avoir à créer un modèle d'apprentissage automatique à partir de zéro.
Beimingwu est la première implémentation open source systématique de logiciels universitaires, fournissant une plate-forme de recherche scientifique préliminaire pour la recherche liée aux logiciels universitaires.
Les développeurs qui souhaitent partager peuvent librement soumettre des modèles, et le Learning Warehouse aide à générer des spécifications pour former un logiciel d'apprentissage et à les stocker dans le Learning Warehouse. Dans ce processus, les développeurs n'ont pas besoin de divulguer leur formation. données vers le Learning Warehouse.
Les futurs utilisateurs peuvent soumettre leurs besoins au Learning Warehouse et rechercher du matériel d'apprentissage réutilisé avec l'aide du Learning Warehouse pour terminer leurs tâches d'apprentissage automatique, et les utilisateurs n'ont pas besoin de divulguer leurs propres données au Learning Warehouse.
Et à l'avenir, une fois que le dock d'apprentissage aura des millions d'éléments d'apprentissage, un comportement « émergent » se produira probablement : les tâches d'apprentissage automatique qui n'ont pas eu de modèles spécialement développés dans le passé pourront être réutilisées en réutilisant plusieurs éléments d'apprentissage existants. Et résoudre.
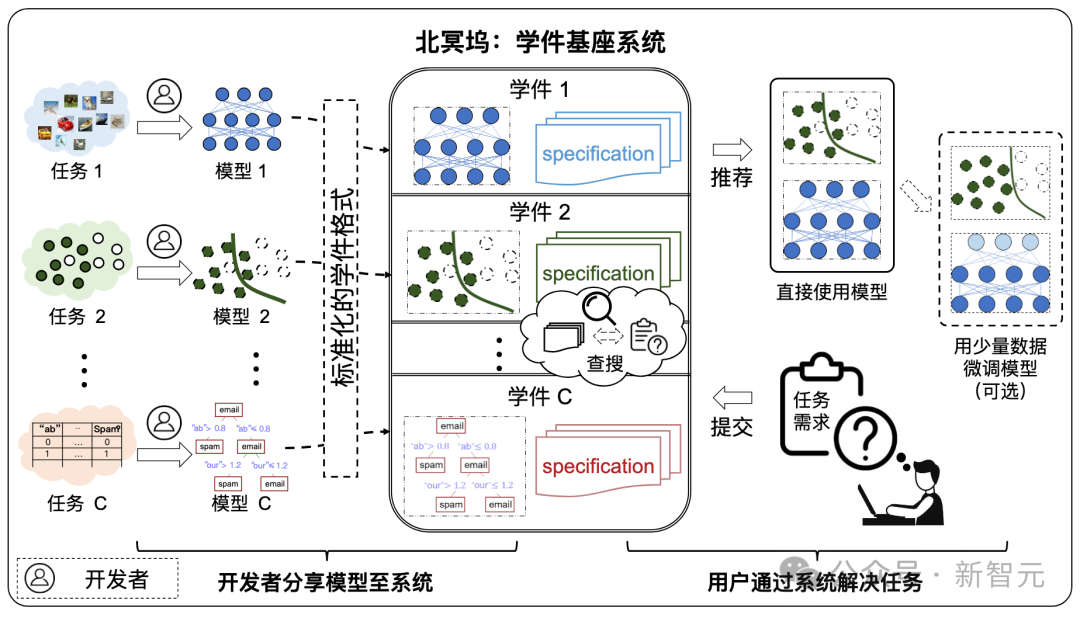
Learningware Base System
L'apprentissage automatique a connu un grand succès dans de nombreux domaines, mais il est encore confronté à de nombreux problèmes, tels que le besoin de grandes quantités de données de formation et de superbes compétences de formation, la difficulté de l'apprentissage continu et des catastrophes. oubli. Risques et fuites de confidentialité/propriété des données, etc.
Bien que chacun des problèmes ci-dessus ait des recherches correspondantes, étant donné que les problèmes sont couplés les uns aux autres, la résolution de l'un des problèmes peut aggraver d'autres problèmes.
Le système de base d'apprentissage espère résoudre plusieurs des problèmes ci-dessus en même temps grâce à un cadre global :
- Manque de données/compétences de formation : même pour les utilisateurs ordinaires qui manquent de compétences en formation ou ont une petite quantité de données, ils peuvent obtenir de puissants modèles d'apprentissage automatique, car les utilisateurs peuvent prendre un logiciel d'apprentissage très performant à partir d'un système de base de logiciel d'apprentissage et le peaufiner ou l'améliorer davantage, plutôt que de créer eux-mêmes le modèle à partir de zéro.
- Apprentissage continu : à mesure que des logiciels d'apprentissage offrant d'excellentes performances et formés à diverses tâches sont soumis en permanence, les connaissances du système de base du logiciel d'apprentissage continueront à s'enrichir, permettant ainsi naturellement un apprentissage continu et tout au long de la vie.
- Oubli catastrophique : Une fois qu'une pièce d'apprentissage est reçue, elle sera toujours hébergée dans le système de base de la pièce d'apprentissage, à moins que tous les aspects de ses fonctions puissent être remplacés par d'autres pièces d'apprentissage. Par conséquent, les anciennes connaissances du système de base d’apprentissage sont toujours conservées et jamais oubliées.
- Confidentialité/propriété des données : les développeurs soumettent uniquement des modèles sans partager de données privées, afin que la confidentialité/propriété des données puisse être bien protégée. Bien que la possibilité d'une ingénierie inverse du modèle ne puisse pas être complètement exclue, le risque de fuite de confidentialité avec le système de base d'apprentissage est très faible par rapport à de nombreux autres systèmes de protection de la vie privée.
La composition du système de base du logiciel d'apprentissage
Comme le montre la figure ci-dessous, le flux de travail du système est divisé en deux étapes suivantes :
- Étape de soumission : les développeurs soumettent spontanément divers supports d'apprentissage à un système de base. pour les pièces d'apprentissage qui effectuent des contrôles de qualité et une organisation plus poussée.
- Étape de déploiement : lorsque l'utilisateur soumet les exigences de la tâche, le système de base du logiciel d'apprentissage recommandera le logiciel d'apprentissage utile à la tâche de l'utilisateur conformément à la spécification du logiciel d'apprentissage et guidera l'utilisateur pour le déployer et le réutiliser.
Protocol World
Le protocole est le composant principal du système de base du logiciel d'apprentissage, qui connecte tous les processus du logiciel d'apprentissage dans le système, y compris le téléchargement, l'organisation, la recherche, le déploiement et la réutilisation du logiciel.
Les logiciels d'apprentissage de différents espaces de fonctionnalités/marqueurs constituent de nombreux îlots de protocole, et tous les îlots de protocole constituent ensemble le monde des protocoles dans le système de base du logiciel d'apprentissage. Dans le monde protocolaire, si les connexions entre les différentes îles peuvent être découvertes et établies, alors les îlots protocolaires correspondants pourront être fusionnés.
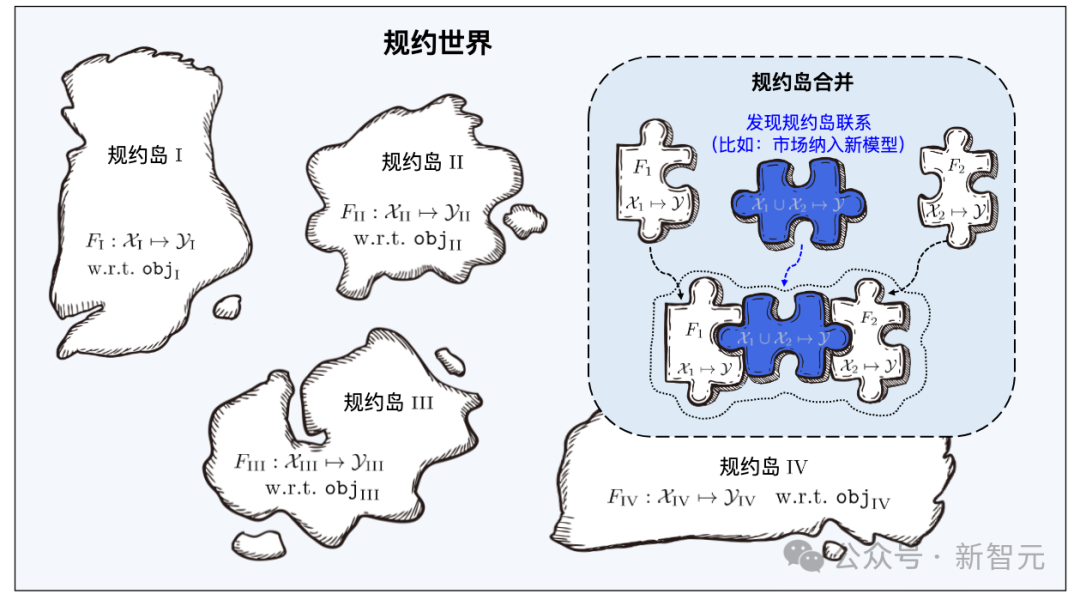
Lors de la recherche, le système de base d'apprentissage localise d'abord l'îlot de protocole spécifique grâce aux spécifications sémantiques dans les exigences de l'utilisateur, puis identifie avec précision le matériel d'apprentissage sur l'îlot de protocole grâce aux spécifications statistiques dans les exigences de l'utilisateur. La fusion de différents îlots de protocole signifie que le logiciel d'apprentissage correspondant peut être utilisé pour des tâches dans différents espaces de fonctionnalités/marqueurs, c'est-à-dire qu'il peut être réutilisé pour des tâches au-delà de son objectif initial.
Le paradigme du learningware construit un espace de spécification unifié en exploitant pleinement les capacités des modèles d'apprentissage automatique partagés par la communauté et résout efficacement les tâches d'apprentissage automatique pour les nouveaux utilisateurs de manière unifiée. À mesure que le nombre d'éléments d'apprentissage augmente, en organisant efficacement la structure des éléments d'apprentissage, la capacité globale du système de base des éléments d'apprentissage à résoudre des tâches sera considérablement améliorée.
L'architecture de Beimingwu
Comme le montre la figure ci-dessous, l'architecture système de Beimingwu comprend quatre niveaux, de la couche de stockage du logiciel d'apprentissage à la couche d'interaction utilisateur. C'est la première fois qu'un logiciel d'apprentissage est systématiquement implémenté à partir de. le paradigme du bas vers le haut. Les fonctions spécifiques des quatre niveaux sont les suivantes :
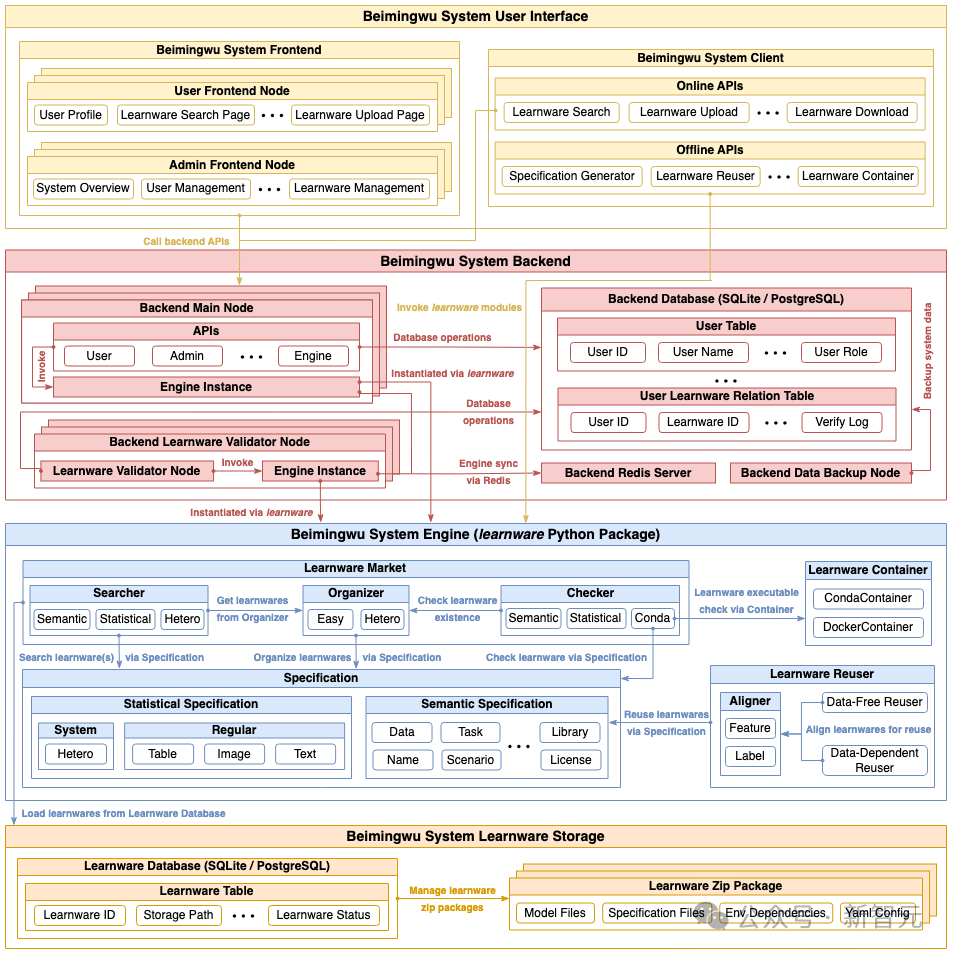
- Couche de stockage du logiciel d'apprentissage : gère le logiciel d'apprentissage stocké au format zip et permet d'accéder aux informations pertinentes via la base de données du logiciel d'apprentissage ;
- Couche moteur du système : inclut tous les processus du paradigme du logiciel d'apprentissage, y compris le téléchargement, la détection, l'organisation, la recherche et le déploiement du logiciel d'apprentissage ; et réutiliser, et s'exécuter indépendamment du back-end et du front-end sous la forme d'un package Python d'apprentissage, fournissant une interface d'algorithme riche pour les tâches liées à l'apprentissage et l'exploration de la recherche scientifique
- Couche back-end du système : implémentation Avec le ; Déploiement de qualité industrielle de Beimingwu, il fournit des services système en ligne stables et prend en charge l'interaction utilisateur entre le front-end et le client en fournissant une riche API back-end
- Couche d'interaction utilisateur : implémente le front-end et la commande basés sur le Web ; basé sur les lignes Le client offre des moyens riches et pratiques d'interaction avec l'utilisateur.
Évaluation expérimentale
Dans cet article, l'équipe de recherche a également construit divers types de scénarios expérimentaux de base pour évaluer des algorithmes de référence pour la génération de protocoles, l'apprentissage de la reconnaissance et de la réutilisation d'artefacts sur des tableaux, des images et des données textuelles.
Expérience de données tabulaires
Sur divers ensembles de données tabulaires, l'équipe a d'abord évalué les performances d'identification et de réutilisation des outils d'apprentissage du système d'apprentissage qui a le même espace de fonctionnalités que la tâche utilisateur.
De plus, étant donné que les tâches de table proviennent généralement de différents espaces de fonctionnalités, l'équipe de recherche a également évalué l'identification et la réutilisation d'éléments d'apprentissage provenant de différents espaces de fonctionnalités.
Cas homogène
Dans le cas homogène, les 53 magasins du jeu de données PFS agissent comme 53 utilisateurs indépendants.
Chaque magasin utilise ses propres données de test comme données de tâches utilisateur et adopte une approche d'ingénierie de fonctionnalités unifiée. Ces utilisateurs peuvent ensuite rechercher dans le système de base des éléments d'apprentissage homogènes partageant le même espace de fonctionnalités que leur tâche.
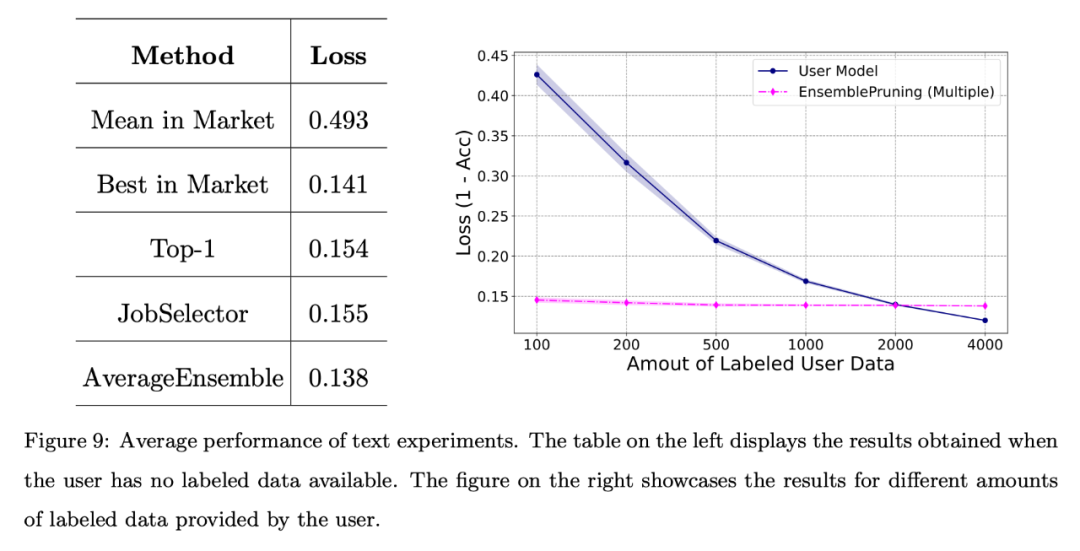
Lorsque l'utilisateur ne dispose pas de données étiquetées ou que la quantité de données étiquetées est limitée, l'équipe a comparé différents algorithmes de référence et la perte moyenne pour tous les utilisateurs est indiquée dans la figure ci-dessous. Le tableau de gauche montre que l'approche sans données est bien meilleure que la sélection et le déploiement aléatoires d'un didacticiel du marché ; le graphique de droite montre que lorsque l'utilisateur dispose de données de formation limitées, il est préférable d'identifier et de réutiliser un ou plusieurs didacticiels plutôt que de former l'utilisateur. modèles. Meilleures performances.
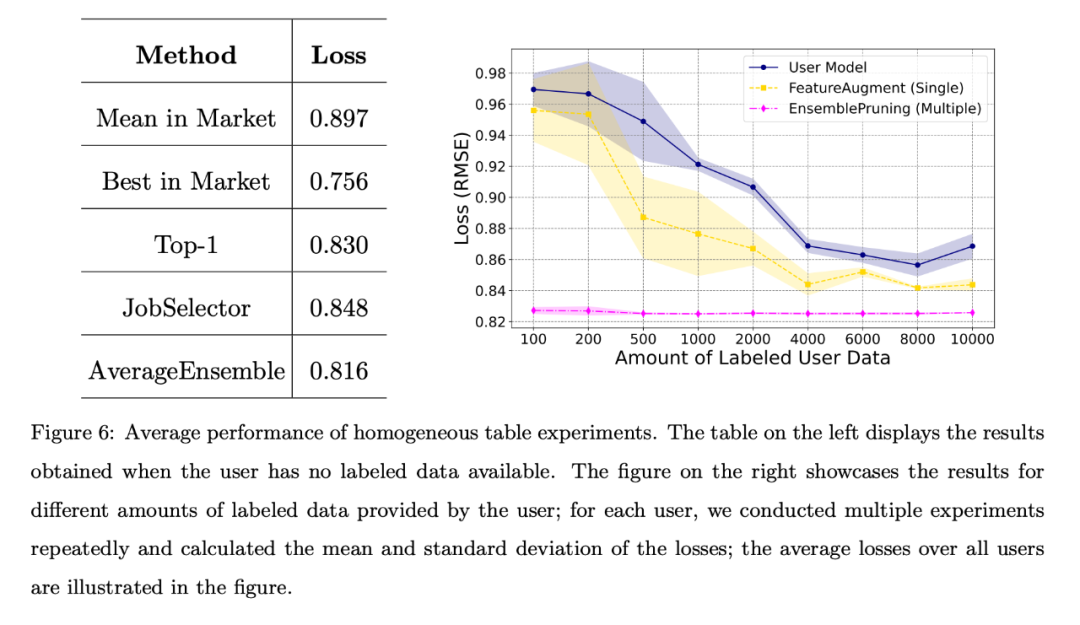
Le tableau de gauche montre que l'approche sans données est bien meilleure que la sélection et le déploiement aléatoires d'un logiciel d'apprentissage sur le marché ; la figure de droite montre que lorsque l'utilisateur dispose de données de formation limitées, il peut identifier et réutiliser un ou plusieurs learnware Le logiciel fonctionne mieux que le modèle formé par l'utilisateur.
Cas hétérogènes
Sur la base de la similitude entre les logiciels du marché et les tâches des utilisateurs, les cas hétérogènes peuvent être divisés en différentes ingénieries de fonctionnalités et différents scénarios de tâches.
Différents scénarios d'ingénierie de fonctionnalités :
Les résultats affichés à gauche dans la figure ci-dessous montrent que même si l'utilisateur manque de données d'annotation, le logiciel d'apprentissage du système peut toujours afficher de bonnes performances, en particulier lorsque plusieurs logiciels d'apprentissage est réutilisé la méthode AverageEnsemble.
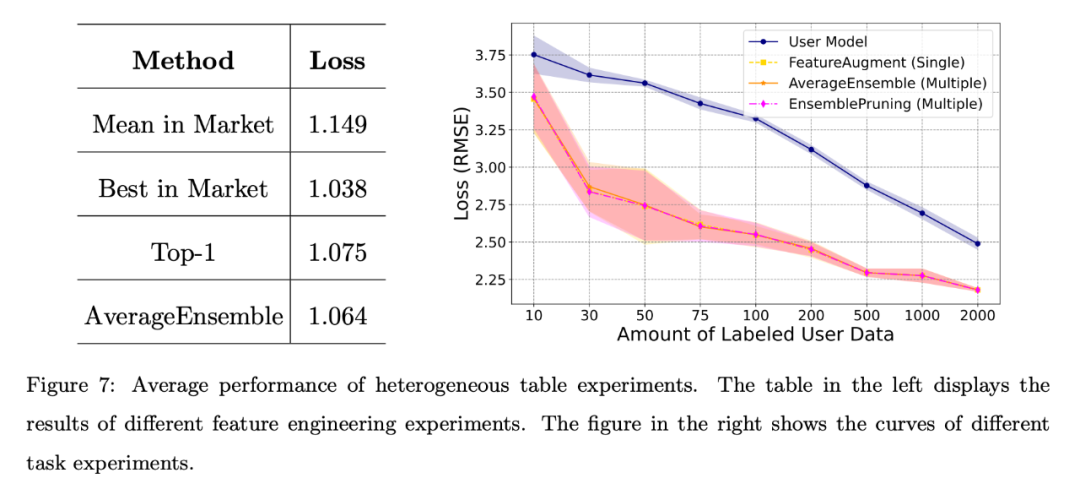
Différents scénarios de tâches :
Le côté droit de la figure ci-dessus montre les courbes de perte du modèle d'auto-formation de l'utilisateur et plusieurs méthodes de réutilisation du learnware.
Évidemment, la vérification expérimentale de composants d'apprentissage hétérogènes est bénéfique lorsque la quantité de données annotées par l'utilisateur est limitée et permet de mieux s'aligner sur l'espace de fonctionnalités de l'utilisateur.
Expériences sur les données d'images et de texte
De plus, l'équipe de recherche a mené une évaluation de base du système sur des ensembles de données d'images.
La figure ci-dessous montre que l'exploitation d'un système de base d'apprentissage peut donner de bonnes performances lorsque les utilisateurs sont confrontés à une pénurie de données annotées ou ne disposent que d'une quantité limitée de données (moins de 2 000 instances).
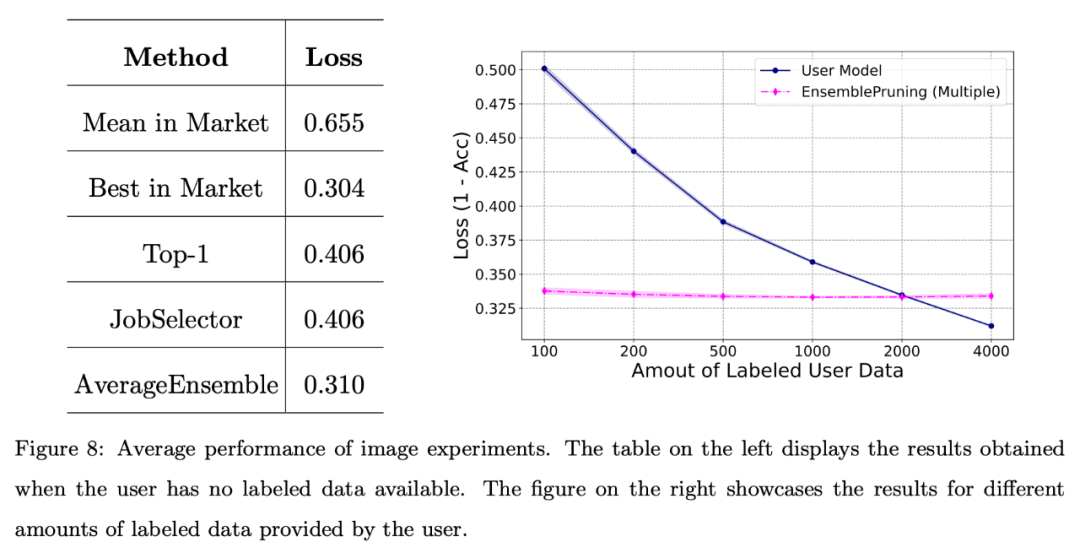
L'équipe a également mené une évaluation de base du système sur un ensemble de données textuelles de référence. Alignement de l’espace des fonctionnalités via un extracteur de fonctionnalités unifié.
Comme le montre la figure ci-dessous, même lorsqu'aucune donnée d'annotation n'est fournie, les performances obtenues grâce à l'identification et à la réutilisation des logiciels d'apprentissage sont comparables à celles du meilleur logiciel d'apprentissage du système.
De plus, par rapport à la formation du modèle à partir de zéro, l'utilisation du système de base d'apprentissage peut réduire environ 2000 échantillons.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Comment afficher les journaux Gitlab sous Centos
Apr 14, 2025 pm 06:18 PM
Comment afficher les journaux Gitlab sous Centos
Apr 14, 2025 pm 06:18 PM
Un guide complet pour consulter les journaux GitLab sous Centos System Cet article vous guidera comment afficher divers journaux GitLab dans le système CentOS, y compris les journaux principaux, les journaux d'exception et d'autres journaux connexes. Veuillez noter que le chemin du fichier journal peut varier en fonction de la version Gitlab et de la méthode d'installation. Si le chemin suivant n'existe pas, veuillez vérifier le répertoire d'installation et les fichiers de configuration de GitLab. 1. Afficher le journal GitLab principal Utilisez la commande suivante pour afficher le fichier journal principal de l'application GitLabRails: Commande: sudocat / var / log / gitlab / gitlab-rails / production.log Cette commande affichera le produit
 Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Lors de l'installation de Pytorch sur le système CentOS, vous devez sélectionner soigneusement la version appropriée et considérer les facteurs clés suivants: 1. Compatibilité de l'environnement du système: Système d'exploitation: Il est recommandé d'utiliser CentOS7 ou plus. CUDA et CUDNN: La version Pytorch et la version CUDA sont étroitement liées. Par exemple, Pytorch1.9.0 nécessite CUDA11.1, tandis que Pytorch2.0.1 nécessite CUDA11.3. La version CUDNN doit également correspondre à la version CUDA. Avant de sélectionner la version Pytorch, assurez-vous de confirmer que des versions compatibles CUDA et CUDNN ont été installées. Version Python: branche officielle de Pytorch
