
 Périphériques technologiques
IA
Découverte du framework d'inférence de grands modèles NVIDIA : TensorRT-LLM
Périphériques technologiques
IA
Découverte du framework d'inférence de grands modèles NVIDIA : TensorRT-LLM
Découverte du framework d'inférence de grands modèles NVIDIA : TensorRT-LLM

1. Positionnement produit de TensorRT-LLM
TensorRT-LLM est une solution d'inférence évolutive développée par NVIDIA pour les grands modèles de langage (LLM). Il crée, compile et exécute des graphiques de calcul basés sur le cadre de compilation d'apprentissage en profondeur TensorRT et s'appuie sur l'implémentation efficace des noyaux dans FastTransformer. De plus, il utilise NCCL pour la communication entre appareils. Les développeurs peuvent personnaliser les opérateurs pour répondre à des besoins spécifiques en fonction du développement technologique et des différences de demande, comme le développement de GEMM personnalisés basés sur le coutelas. TensorRT-LLM est la solution d'inférence officielle de NVIDIA, engagée à fournir des performances élevées et à améliorer continuellement sa praticité.

TensorRT-LLM est open source sur GitHub et est divisé en deux branches : la branche Release et la branche Dev. La branche Release est mise à jour une fois par mois, tandis que la branche Dev mettra à jour plus fréquemment les fonctionnalités à partir de sources officielles ou communautaires pour permettre aux développeurs de découvrir et d'évaluer les dernières fonctionnalités. La figure ci-dessous montre la structure du framework TensorRT-LLM, à l'exception de la partie de compilation verte TensorRT et des noyaux impliquant des informations matérielles, les autres parties sont open source.

TensorRT-LLM fournit également une API similaire à Pytorch pour réduire les coûts d'apprentissage des développeurs et fournit de nombreux modèles prédéfinis que les utilisateurs peuvent utiliser.

En raison de la grande taille des grands modèles de langage, l'inférence peut ne pas être effectuée sur une seule carte graphique. TensorRT-LLM fournit donc deux mécanismes parallèles : le parallélisme tensoriel et le parallélisme pipeline pour prendre en charge le raisonnement sur plusieurs cartes ou plusieurs machines. . Ces mécanismes permettent au modèle d'être divisé en plusieurs parties et distribué sur plusieurs cartes graphiques ou machines pour un calcul parallèle afin d'améliorer les performances d'inférence. Le parallélisme tensoriel réalise le calcul parallèle en distribuant les paramètres du modèle sur différents appareils et en calculant la sortie de différentes parties en même temps. Le parallélisme du pipeline divise le modèle en plusieurs étapes. Chaque étape est calculée en parallèle sur différents appareils et transmet la sortie à l'étape suivante, obtenant ainsi l'ensemble

2. TensorRT Caractéristiques importantes de LLM
TensorRT-LLM est un outil puissant avec une prise en charge riche de modèles et des capacités d'inférence de faible précision. Tout d'abord, TensorRT-LLM prend en charge les grands modèles de langage traditionnels, y compris l'adaptation de modèles réalisée par les développeurs, tels que Qwen (Qianwen), et a été inclus dans le support officiel. Cela signifie que les utilisateurs peuvent facilement étendre ou personnaliser ces modèles prédéfinis et les appliquer à leurs propres projets rapidement et facilement. Deuxièmement, TensorRT-LLM utilise par défaut la méthode d'inférence de précision FP16/BF16. Ce raisonnement de faible précision peut non seulement améliorer les performances de raisonnement, mais également utiliser les méthodes de quantification de l'industrie pour optimiser davantage le débit matériel. En réduisant la précision du modèle, TensorRT-LLM peut améliorer considérablement la vitesse et l'efficacité de l'inférence sans sacrifier trop de précision. En résumé, la riche prise en charge des modèles et les capacités d'inférence de faible précision de TensorRT-LLM en font un outil très pratique. Que ce soit pour les développeurs ou les chercheurs, TensorRT-LLM peut fournir des solutions d'inférence efficaces pour les aider à obtenir de meilleures performances dans les applications de deep learning.

Une autre fonctionnalité est l'implémentation du noyau FMHA (fused multi-head attention). Étant donné que la partie la plus longue de Transformer est le calcul de l'auto-attention, le responsable a conçu FMHA pour optimiser le calcul de l'auto-attention et a fourni différentes versions avec des accumulateurs de fp16 et fp32. De plus, outre l’amélioration de la vitesse, l’utilisation de la mémoire est également considérablement réduite. Nous fournissons également une implémentation basée sur l'attention flash qui peut étendre la longueur de la séquence à des longueurs arbitraires.

Ce qui suit sont les informations détaillées de la FMHA, où MQA est Multi Query Attention et GQA est Group Query Attention.
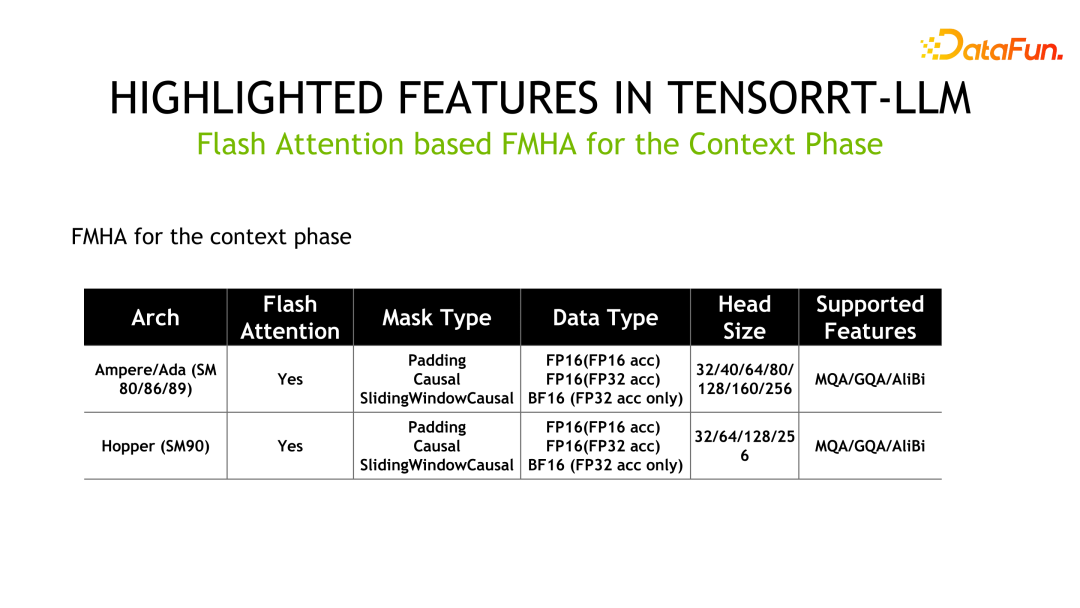
Un autre noyau est le MMHA (Masked Multi-Head Attention). FMHA est principalement utilisé pour les calculs dans la phase de contexte, tandis que MMHA fournit principalement une accélération de l'attention dans la phase de génération et prend en charge Volta et les architectures ultérieures. Par rapport à l'implémentation de FastTransformer, TensorRT-LLM est encore optimisé et les performances sont améliorées jusqu'à 2x.

Une autre caractéristique importante est la technologie de quantification, qui permet d'obtenir une accélération d'inférence avec une précision moindre. Les méthodes de quantification couramment utilisées sont principalement divisées en PTQ (Post Training Quantization) et QAT (Quantization-aware Training). Pour TensorRT-LLM, la logique de raisonnement de ces deux méthodes de quantification est la même. Pour la technologie de quantification LLM, une caractéristique importante est la co-conception de la conception de l'algorithme et de la mise en œuvre technique, c'est-à-dire que les caractéristiques du matériel doivent être prises en compte dès le début de la conception de la méthode de quantification correspondante. Sinon, l’amélioration attendue de la vitesse d’inférence risque de ne pas être obtenue.

Les étapes de quantification PTQ dans TensorRT sont généralement divisées en les étapes suivantes. Tout d'abord, le modèle est quantifié, puis les poids et le modèle sont convertis en représentation TensorRT-LLM. Pour certaines opérations personnalisées, les utilisateurs doivent également écrire leurs propres noyaux. Les méthodes de quantification PTQ couramment utilisées incluent INT8 pondéré uniquement, SmoothQuant, GPTQ et AWQ, qui sont des méthodes de co-conception typiques.

Le poids INT8 quantifie uniquement directement le poids en INT8, mais la valeur d'activation reste telle que FP16. L'avantage de cette méthode est que le stockage du modèle est réduit de 2 fois et que la bande passante de stockage pour le chargement des poids est réduite de moitié, ce qui permet d'améliorer les performances d'inférence. Cette méthode est appelée W8A16 dans l'industrie, c'est-à-dire que le poids est INT8 et la valeur d'activation est FP16/BF16 - stockée avec la précision INT8 et calculée au format FP16/BF16. Cette méthode est intuitive, ne modifie pas les poids, est facile à mettre en œuvre et présente de bonnes performances de généralisation.

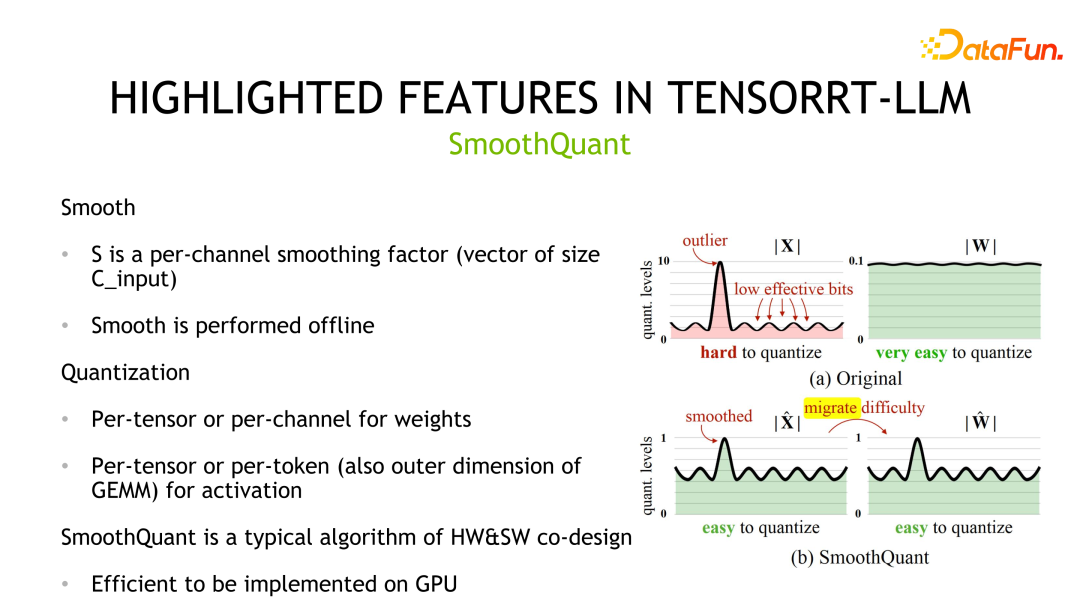
La deuxième méthode de quantification est SmoothQuant, qui a été conçue conjointement par NVIDIA et la communauté. On observe que les poids obéissent généralement à une distribution gaussienne et sont faciles à quantifier, mais il existe des valeurs aberrantes dans les valeurs d'activation et l'utilisation des bits de quantification n'est pas élevée.

SmoothQuant compresse la distribution correspondante en lissant d'abord la valeur d'activation, c'est-à-dire en la divisant par une échelle. En même temps, afin d'assurer l'équivalence, les poids doivent être multipliés par la même échelle. Ensuite, les poids et les activations peuvent être quantifiés. La précision de stockage et de calcul correspondante peut être INT8 ou FP8, et INT8 ou FP8 TensorCore peut être utilisé pour le calcul. En termes de détails de mise en œuvre, les poids prennent en charge la quantification par tenseur et par canal, et les valeurs d'activation prennent en charge la quantification par tenseur et par jeton.
La troisième méthode de quantification est GPTQ, une méthode de quantification couche par couche mise en œuvre en minimisant la perte de reconstruction. GPTQ est une méthode basée uniquement sur le poids et le calcul utilise le format de données FP16. Cette méthode est utilisée lors de la quantification de grands modèles. Étant donné que la quantification elle-même est relativement coûteuse, l'auteur a conçu quelques astuces pour réduire le coût de la quantification elle-même, telles que les mises à jour par lots paresseuses et la quantification des poids de toutes les lignes dans le même ordre. GPTQ peut également être utilisé en conjonction avec d'autres méthodes telles que les stratégies de regroupement. De plus, TensorRT-LLM offre différentes performances d'optimisation de mise en œuvre pour différentes situations. Plus précisément, lorsque la taille du lot est petite, cuda core est utilisé pour l'implémenter ; à l'inverse, lorsque la taille du lot est grande, le noyau tensoriel est utilisé pour l'implémenter ;

La quatrième méthode de quantification est l'AWQ. Cette méthode considère que tous les poids n'ont pas la même importance, que seulement 0,1 à 1 % des poids (poids saillants) contribuent davantage à la précision du modèle, et ces poids dépendent de la distribution des valeurs d'activation plutôt que de la distribution des poids. Le processus de quantification de cette méthode est similaire à celui de SmoothQuant. La principale différence est que l'échelle est calculée en fonction de la distribution des valeurs d'activation.


En plus de la méthode de quantification, une autre façon d'améliorer les performances de TensorRT-LLM consiste à utiliser l'inférence multi-machines et multi-cartes. Dans certains scénarios, les grands modèles sont trop volumineux pour être placés sur un seul GPU à des fins d'inférence, ou ils peuvent être déposés mais l'efficacité informatique est affectée, nécessitant plusieurs cartes ou plusieurs machines pour l'inférence.

TensorRT-LLM propose actuellement deux stratégies parallèles, le parallélisme tenseur et le parallélisme pipeline. TP divise le modèle verticalement et place chaque partie sur différents appareils. Cela introduira une communication de données fréquente entre les appareils et est généralement utilisé dans des scénarios avec une interconnexion élevée entre les appareils, tels que NVLINK. Une autre méthode de segmentation est la segmentation horizontale. À l'heure actuelle, il n'y a qu'un seul front horizontal et la méthode de communication correspondante est la communication point à point, qui convient aux scénarios dans lesquels la bande passante de communication de l'appareil est faible.

La dernière fonctionnalité à souligner est le traitement par lots en vol. Le traitement par lots est une pratique courante pour améliorer les performances d'inférence, mais dans les scénarios d'inférence LLM, la longueur de sortie de chaque échantillon/requête dans un lot est imprévisible. Si vous suivez la méthode de traitement par lots statique, le délai d'un lot dépend de celui avec la sortie la plus longue en échantillon/demande. Par conséquent, bien que la sortie de l'échantillon/de la demande la plus courte soit terminée, les ressources informatiques n'ont pas été libérées, et son retard est le même que le retard de l'échantillon/de la demande de sortie le plus long. La méthode de traitement par lots en vol consiste à insérer un nouvel échantillon/demande à la fin de l’échantillon/de la demande. De cette manière, cela réduit non seulement le délai d’un seul échantillon/demande et évite le gaspillage de ressources, mais améliore également le débit de l’ensemble du système.

3. Processus d'utilisation de TensorRT-LLM
TensorRT-LLM est similaire à l'utilisation de TensorRT. Tout d'abord, vous devez obtenir un modèle pré-entraîné, puis l'utiliser. TensorRT-LLM L'API fournie réécrit et reconstruit le graphique de calcul du modèle, puis utilise TensorRT pour la compilation et l'optimisation, puis l'enregistre en tant que moteur sérialisé pour le déploiement d'inférence.

En prenant Llama comme exemple, installez d'abord TensorRT-LLM, puis téléchargez le modèle pré-entraîné, puis utilisez TensorRT-LLM pour compiler le modèle et enfin effectuez l'inférence.

Pour le débogage d'inférence de modèle, la méthode de débogage de TensorRT-LLM est cohérente avec TensorRT. L'une des optimisations apportées grâce au compilateur de deep learning, à savoir TensorRT, est la fusion de couches. Par conséquent, si vous souhaitez afficher les résultats d'une certaine couche, vous devez marquer la couche correspondante comme couche de sortie pour éviter qu'elle ne soit optimisée par le compilateur, puis la comparer et l'analyser avec la ligne de base. Dans le même temps, chaque fois qu'une nouvelle couche de sortie est marquée, le moteur TensorRT doit être recompilé.

Pour les couches personnalisées, TensorRT-LLM fournit de nombreux opérateurs de type Pytorch pour aider les utilisateurs à implémenter des fonctions sans avoir à écrire eux-mêmes le noyau. Comme le montre l'exemple, l'API fournie par TensorRT-LLM est utilisée pour implémenter la logique de la norme rms, et TensorRT générera automatiquement le code d'exécution correspondant sur le GPU.

Si l'utilisateur a des exigences de performances plus élevées ou si TensorRT-LLM ne fournit pas de blocs de construction pour implémenter les fonctions correspondantes, l'utilisateur doit personnaliser le noyau et le conditionner en tant que plugin pour que TensorRT-LLM puisse l'utiliser. L'exemple de code est un exemple de code qui implémente le GEMM personnalisé de SmoothQuant et l'encapsule dans un plugin que TensorRT-LLM peut appeler.

4. Performances d'inférence de TensorRT-LLM
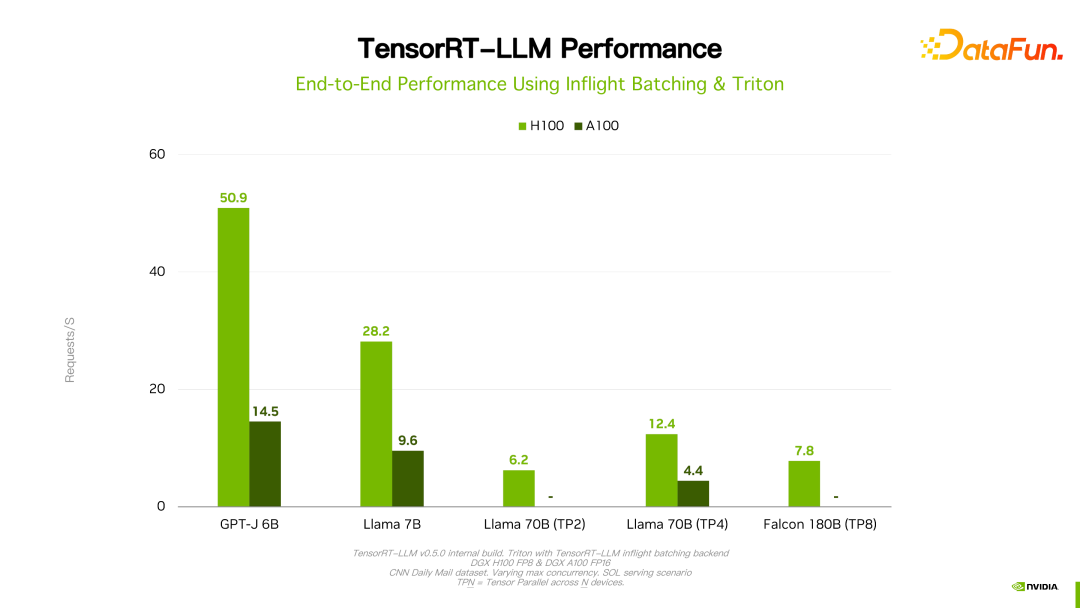
Des détails tels que les performances et la configuration peuvent être consultés sur le site officiel et ne seront pas présentés en détail ici. Ce produit coopère avec de nombreux grands fabricants nationaux depuis sa création. Grâce aux commentaires, en général, TensorRT-LLM est actuellement la meilleure solution du point de vue des performances. Étant donné que de nombreux facteurs tels que l'itération technologique, les méthodes d'optimisation et l'optimisation du système affecteront les performances et changeront très rapidement, les données de performances de TensorRT-LLM ne seront pas présentées en détail ici. Si vous êtes intéressé, vous pouvez vous rendre sur le site officiel pour connaître les détails. Ces performances sont toutes reproductibles.
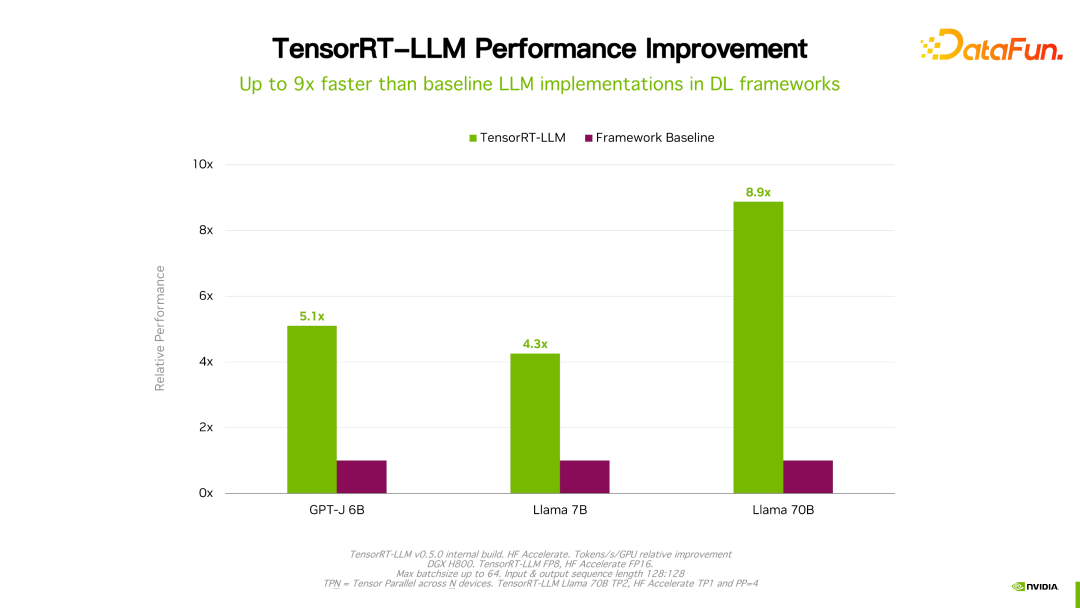
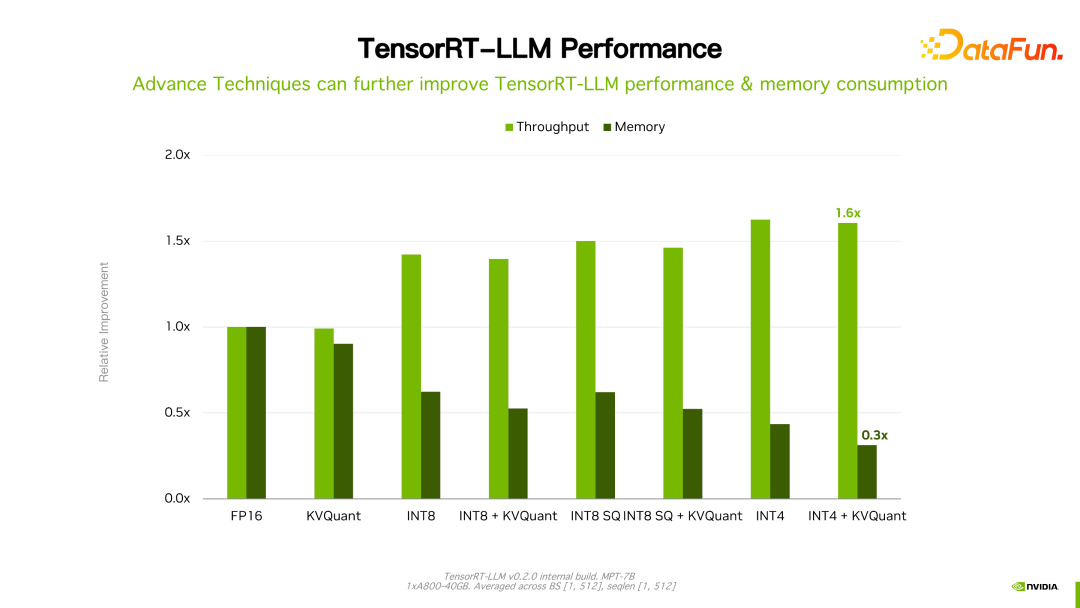
Il convient de mentionner que par rapport à sa version précédente, les performances de TensorRT-LLM ont continué de s'améliorer. Comme le montre la figure ci-dessus, basée sur FP16, après avoir utilisé KVQuant, l'utilisation de la mémoire vidéo est réduite tout en conservant la même vitesse. En utilisant INT8, vous pouvez constater une amélioration significative du débit et, en même temps, l'utilisation de la mémoire est encore réduite. On peut constater qu'avec l'évolution continue de la technologie d'optimisation TensorRT-LLM, les performances continueront de s'améliorer. Cette tendance va se poursuivre.
5. Les perspectives d'avenir de TensorRT-LLM
LLM est un scénario à coût d'inférence élevé et sensible aux coûts. Nous pensons que pour obtenir le prochain effet d'accélération centuple, une itération conjointe des algorithmes et du matériel est nécessaire, et cet objectif peut être atteint grâce à une co-conception entre le logiciel et le matériel. Le matériel fournit une quantification de moindre précision, tandis que la perspective logicielle utilise des algorithmes tels que la quantification optimisée et l'élagage du réseau pour améliorer encore les performances.

TensorRT-LLM, NVIDIA continuera à travailler sur l'amélioration des performances de TensorRT-LLM à l'avenir. Parallèlement, grâce à l'open source, nous collectons des retours et des opinions pour améliorer sa facilité d'utilisation. De plus, en nous concentrant sur la facilité d'utilisation, nous développerons et ouvrirons davantage d'outils d'application, tels que la zone de modèle ou les outils quantitatifs, pour améliorer la compatibilité avec les cadres traditionnels et fournir des solutions de bout en bout, de la formation à l'inférence et au déploiement.

6. Séance de questions et réponses
Q1 : Chaque sortie de calcul doit-elle être déquantifiée ? Que dois-je faire si un dépassement de précision se produit pendant la quantification ?
A1 : Actuellement TensorRT-LLM propose deux types de méthodes, à savoir FP8 et la méthode de quantification INT4/INT8 que nous venons de mentionner. Faible précision Si INT8 est utilisé comme GEMM, l'accumulateur utilisera des types de données de haute précision, tels que fp16, ou même fp32, pour éviter tout débordement. Concernant la quantification inverse, en prenant comme exemple la quantification fp8, lorsque TensorRT-LLM optimise le graphique de calcul, il peut automatiquement déplacer le nœud de quantification inverse et le fusionner dans d'autres opérations pour atteindre des objectifs d'optimisation. Cependant, les GPTQ et QAT introduits précédemment sont actuellement écrits dans le noyau via un codage en dur, et il n'existe pas de traitement unifié des nœuds de quantification ou de déquantification.
Q2 : Effectuez-vous actuellement une quantification inverse spécifiquement pour des modèles spécifiques ?
A2 : La quantification actuelle est en effet comme ça, prenant en charge différents modèles. Nous prévoyons de créer une API plus propre ou de prendre en charge uniformément la quantification des modèles via des éléments de configuration.
Q3 : Pour les meilleures pratiques, TensorRT-LLM doit-il être utilisé directement ou combiné avec Triton Inference Server ? Y a-t-il des fonctionnalités manquantes si elles sont utilisées ensemble ?
A3 : Parce que certaines fonctions ne sont pas open source, s'il s'agit de votre propre portion, vous devez faire un travail d'adaptation. S'il s'agit de triton, ce sera une solution complète.
Q4 : Il existe plusieurs méthodes quantitatives pour l'étalonnage quantitatif, et quel est le rapport d'accélération ? Combien de points y a-t-il dans les effets de ces schémas de quantification ? La longueur de sortie de chaque exemple dans le branchement en vol est inconnue. Comment effectuer un traitement par lots dynamique ?
A4 : Vous pouvez parler en privé des performances quantitatives. Concernant l'effet, nous n'avons effectué qu'une vérification de base pour nous assurer que le noyau implémenté est OK. Nous ne pouvons pas garantir les résultats de tous les algorithmes quantitatifs dans les affaires réelles, car il y en a encore. certains facteurs incontrôlables, tels que l'ensemble de données utilisé pour la quantification et son impact. Concernant le traitement par lots en vol, il s'agit de détecter et de juger si la sortie d'un certain échantillon/demande s'est terminée pendant l'exécution. Si tel est le cas, puis insérez d'autres requêtes arrivant, TensorRT-LLM ne prédira pas et ne pourra pas prédire la longueur de la sortie prédite.
Q5 : L'interface C++ et l'interface python du branchement en vol resteront-elles cohérentes ? Le coût d'installation de TensorRT-LLM est élevé. Existe-t-il des plans d'amélioration à l'avenir ? TensorRT-LLM aura-t-il une perspective de développement différente de celle de VLLM ?
A5 : Nous ferons de notre mieux pour fournir une interface cohérente entre le runtime c++ et le runtime python, qui est déjà en cours de planification. Auparavant, l'équipe se concentrait sur l'amélioration des performances et des fonctionnalités, et continuera à améliorer la facilité d'utilisation à l'avenir. Il n'est pas facile de comparer directement avec vllm ici, mais NVIDIA continuera d'augmenter ses investissements dans le développement TensorRT-LLM, la communauté et le support client pour fournir à l'industrie la meilleure solution d'inférence LLM.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le prix du Bitcoin depuis sa naissance 2009-2025 Le résumé le plus complet des prix historiques du BTC
Jan 15, 2025 pm 08:11 PM
Le prix du Bitcoin depuis sa naissance 2009-2025 Le résumé le plus complet des prix historiques du BTC
Jan 15, 2025 pm 08:11 PM
Depuis sa création en 2009, Bitcoin est devenu un leader dans le monde des cryptomonnaies et son prix a connu d’énormes fluctuations. Pour fournir un aperçu historique complet, cet article compile les données sur les prix du Bitcoin de 2009 à 2025, couvrant les principaux événements du marché, les changements de sentiment du marché et les facteurs importants influençant les mouvements de prix.
 Aperçu du prix historique du Bitcoin depuis sa naissance. Collection complète des tendances historiques des prix du Bitcoin.
Jan 15, 2025 pm 08:14 PM
Aperçu du prix historique du Bitcoin depuis sa naissance. Collection complète des tendances historiques des prix du Bitcoin.
Jan 15, 2025 pm 08:14 PM
Le Bitcoin, en tant que crypto-monnaie, a connu une volatilité importante sur le marché depuis sa création. Cet article fournira un aperçu du prix historique du Bitcoin depuis sa naissance pour aider les lecteurs à comprendre ses tendances de prix et ses moments clés. En analysant les données historiques sur les prix du Bitcoin, nous pouvons comprendre l'évaluation de sa valeur par le marché, les facteurs affectant ses fluctuations et fournir une base pour les décisions d'investissement futures.
 Une liste des prix historiques depuis la naissance du tableau des tendances des prix historiques Bitcoin BTC (dernier résumé)
Feb 11, 2025 pm 11:36 PM
Une liste des prix historiques depuis la naissance du tableau des tendances des prix historiques Bitcoin BTC (dernier résumé)
Feb 11, 2025 pm 11:36 PM
Depuis sa création en 2009, le prix de Bitcoin a connu plusieurs fluctuations majeures, passant à 69 044,77 $ en novembre 2021 et tombant à 3191,22 $ en décembre 2018. En décembre 2024, le dernier prix a dépassé 100 204 $.
 Le dernier prix du bitcoin en 2018-2024 USD
Feb 15, 2025 pm 07:12 PM
Le dernier prix du bitcoin en 2018-2024 USD
Feb 15, 2025 pm 07:12 PM
Prix USD Bitcoin en temps réel Facteurs qui affectent le prix du bitcoin Indicateurs pour prédire les prix des futurs bitcoins Voici quelques informations clés sur le prix du bitcoin en 2018-2024:
 Le résumé le plus complet des détails des prix historiques depuis la naissance de Bitcoin (la dernière version en 2025)
Feb 15, 2025 pm 06:45 PM
Le résumé le plus complet des détails des prix historiques depuis la naissance de Bitcoin (la dernière version en 2025)
Feb 15, 2025 pm 06:45 PM
Nœud important pour le prix historique du Bitcoin 3 janvier 2009: Genesis Block a été généré, le premier Bitcoin a été généré, avec une valeur de 0 USD. 5 octobre: La première transaction Bitcoin, un programmeur a acheté deux pizzas avec 10 000 Bitcoins, ce qui équivaut à 0,008 $. 9 février 2010: Le Mt. Gox Exchange est allé en ligne et est devenu la plate-forme principale du commerce du bitcoin précoce. 22 mai: Bitcoin percède 1 $ pour la première fois. 17 juillet: le prix du bitcoin a plongé à 0,008 $, atteignant un creux historique. 9 février 2011: Le prix du bitcoin perdra 10 $ pour la première fois. 10 avril: Mt. Go
 Comment utiliser l'attribut Clip-Path de CSS pour réaliser l'effet de courbe à 45 degrés du segmenter?
Apr 04, 2025 pm 11:45 PM
Comment utiliser l'attribut Clip-Path de CSS pour réaliser l'effet de courbe à 45 degrés du segmenter?
Apr 04, 2025 pm 11:45 PM
Comment réaliser l'effet de courbe à 45 degrés du segmenter? Dans le processus de mise en œuvre du segmentant, comment faire transformer la bordure droite en une courbe de 45 degrés lorsque vous cliquez sur le bouton gauche, et le point ...
 Comment personnaliser le symbole de redimensionnement via CSS et le rendre uniforme avec la couleur d'arrière-plan?
Apr 05, 2025 pm 02:30 PM
Comment personnaliser le symbole de redimensionnement via CSS et le rendre uniforme avec la couleur d'arrière-plan?
Apr 05, 2025 pm 02:30 PM
La méthode de personnalisation des symboles de redimension dans CSS est unifiée avec des couleurs d'arrière-plan. Dans le développement quotidien, nous rencontrons souvent des situations où nous devons personnaliser les détails de l'interface utilisateur, tels que l'ajustement ...
 À l'ère Chatgpt, comment la communauté technique des questions et réponses peut-elle répondre aux défis?
Apr 01, 2025 pm 11:51 PM
À l'ère Chatgpt, comment la communauté technique des questions et réponses peut-elle répondre aux défis?
Apr 01, 2025 pm 11:51 PM
La communauté technique de questions-réponses à l'ère Chatgpt: Stratégie de réponse de SegmentFault StackOverflow ...
