
 Périphériques technologiques
IA
Il y a aussi des voleurs dans les grands modèles ? Pour protéger vos paramètres, soumettez le grand modèle pour créer une 'empreinte digitale lisible par l'homme'.
Périphériques technologiques
IA
Il y a aussi des voleurs dans les grands modèles ? Pour protéger vos paramètres, soumettez le grand modèle pour créer une 'empreinte digitale lisible par l'homme'.
Il y a aussi des voleurs dans les grands modèles ? Pour protéger vos paramètres, soumettez le grand modèle pour créer une 'empreinte digitale lisible par l'homme'.

symbolise différents modèles de base comme différentes races de chiens, où la même « empreinte digitale en forme de chien » indique qu'ils sont dérivés du même modèle de base.
La pré-formation de grands modèles nécessite une grande quantité de ressources informatiques et de données. Par conséquent, les paramètres des modèles pré-entraînés sont devenus le cœur de la compétitivité et des atouts que les grandes institutions se concentrent sur la protection. Cependant, contrairement à la protection traditionnelle de la propriété intellectuelle des logiciels, il existe deux nouveaux problèmes pour juger du vol des paramètres de modèles pré-entraînés :
1) Les paramètres des modèles pré-entraînés, en particulier ceux de centaines de milliards de modèles, ne sont généralement pas ouverts. source.
La sortie et les paramètres du modèle pré-entraîné seront affectés par les étapes de traitement ultérieures (telles que SFT, RLHF, continuer le pré-entraînement, etc.), ce qui rend difficile de juger si un modèle est affiné sur la base d'un autre modèle existant. modèle. Qu'il s'agisse de juger sur la base des résultats du modèle ou des paramètres du modèle, il existe certains défis.
Par conséquent, la protection des paramètres des grands modèles est un tout nouveau problème qui manque de solutions efficaces.
L'équipe de recherche Lumia du professeur Lin Zhouhan de l'Université Jiao Tong de Shanghai a développé une technologie innovante capable d'identifier les relations d'ascendance entre les grands modèles. Cette approche utilise une empreinte digitale lisible par l'homme d'un grand modèle sans exposer les paramètres du modèle. La recherche et le développement de cette technologie revêtent une grande importance pour le développement et l’application de grands modèles.
Cette méthode propose deux méthodes d'identification : l'une est une méthode d'identification quantitative, qui détermine si le modèle de base pré-entraîné a été volé en comparant la similarité entre le grand modèle testé et une série de modèles de base ; l'autre est une identification qualitative ; méthode , découvrez rapidement les relations d'héritage entre les modèles en générant des « diagrammes de chien » lisibles par l'homme.

Empreintes digitales de 6 modèles de base différents (première rangée) et de leurs modèles descendants correspondants (deux rangées du bas).

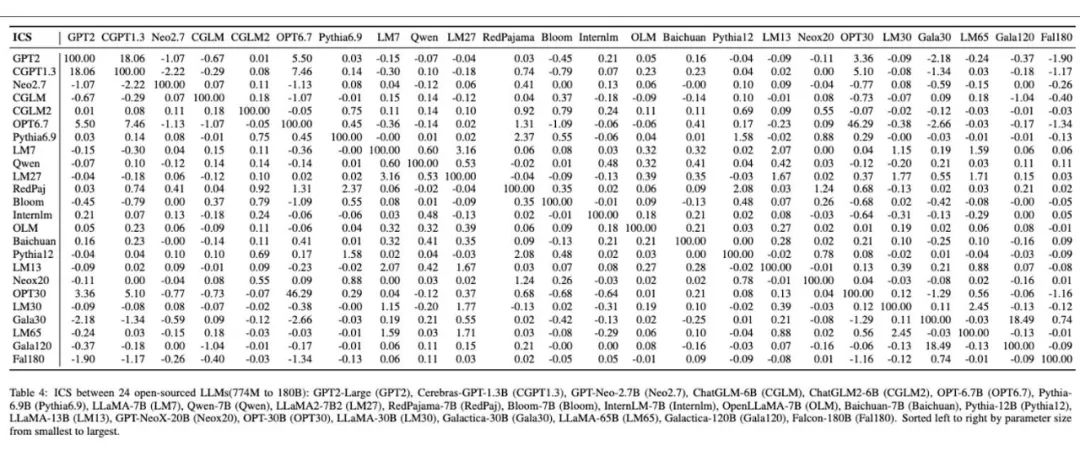
Empreintes digitales grand modèle lisibles par l'homme produites sur 24 grands modèles différents.
Motivation et approche globale
Le développement rapide des modèles à grande échelle apporte un large éventail de perspectives d'application, mais il déclenche également une série de nouveaux défis. Deux des problèmes en suspens incluent :
Problème de vol de modèle : Un "voleur" intelligent qui n'apporte que des ajustements mineurs au grand modèle original et prétend ensuite avoir créé un tout nouveau modèle, exagérant sa propre contribution. Comment identifier s'il s'agit d'un modèle piraté ?
Problème d'abus de modèle : Lorsqu'un criminel modifie de manière malveillante le modèle LLaMA et l'utilise pour générer des informations nuisibles, même si la politique de Meta interdit clairement ce comportement, comment pouvons-nous prouver qu'il utilise le modèle LLaMA ?
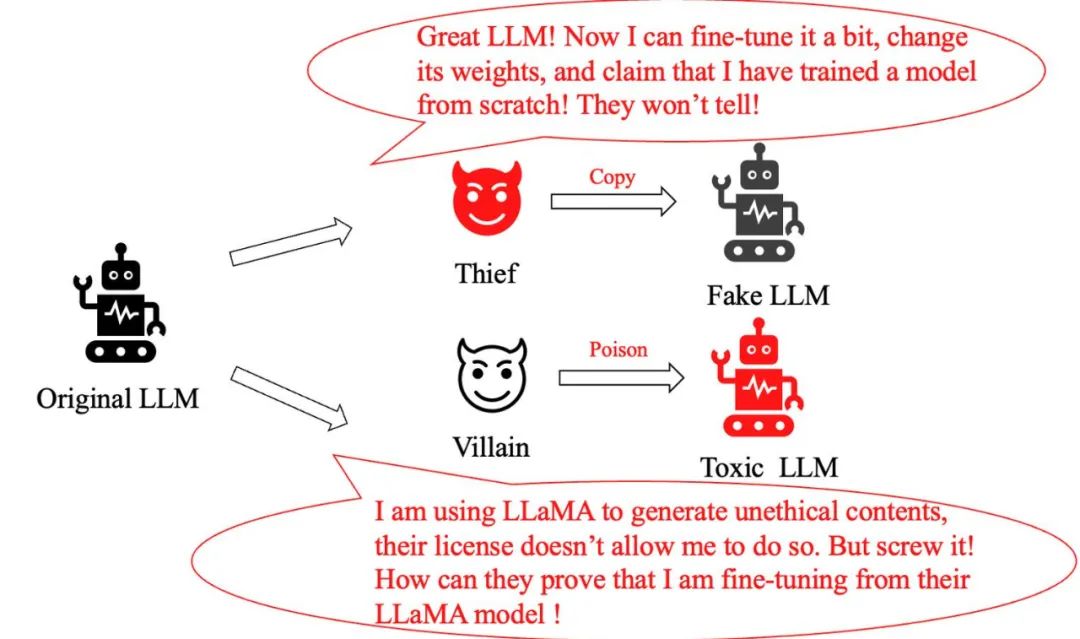
Auparavant, les méthodes conventionnelles pour résoudre ce type de problème incluaient l'ajout de filigranes lors de l'entraînement et de l'inférence du modèle, ou la classification du texte généré par de grands modèles. Cependant, ces méthodes nuisent aux performances des grands modèles ou sont facilement contournées par un simple réglage fin ou un pré-entraînement supplémentaire.
Cela soulève une question clé : existe-t-il une méthode qui n'interfère pas avec la distribution de sortie d'un grand modèle, qui soit robuste pour un réglage fin et un pré-entraînement ultérieur, et qui puisse également suivre avec précision le modèle de base d'un grand modèle, et ainsi efficacement protéger le droit d’auteur du modèle ?
Une équipe de l'Université Jiao Tong de Shanghai s'est inspirée des caractéristiques uniques des empreintes digitales humaines et a développé une méthode permettant de produire des « empreintes digitales lisibles par l'homme » pour les grands modèles. Ils représentaient différents modèles de base comme différentes races de chiens, avec la même « empreinte digitale en forme de chien » indiquant qu'ils étaient dérivés du même modèle de base.
Cette méthode intuitive permet au public d'identifier facilement la connexion entre les différents grands modèles et de retracer le modèle de base du modèle grâce à ces empreintes digitales, empêchant ainsi efficacement le piratage et les abus des modèles. Il est à noter que les fabricants de grands modèles n'ont pas besoin de publier leurs paramètres, mais uniquement les invariants utilisés pour générer les empreintes digitales.

Les « empreintes digitales » d'Alpaga et de LLaMA sont très similaires, car le modèle d'Alpaga est obtenu en affinant LLaMA, tandis que les empreintes digitales de plusieurs autres modèles présentent des différences évidentes, reflétant le fait qu'elles proviennent d'un modèle de base différent ; .
Article "HUREF : EMPREINTES DIGITALES LISIBLES PAR L'HUMAIN POUR LES GRANDS MODÈLES DE LANGUE" :

Adresse de téléchargement du papier : https://arxiv.org/pdf/2312.04828.pdf
Invariants observés à partir d'expériences
L'équipe de l'Université de Jiaotong a découvert que lors du réglage fin ou du pré-entraînement supplémentaire d'un grand modèle, ces le vecteur de paramètres du modèle change très légèrement de direction. En revanche, pour un grand modèle formé à partir de zéro, la direction de ses paramètres sera complètement différente de celle des autres modèles de base.
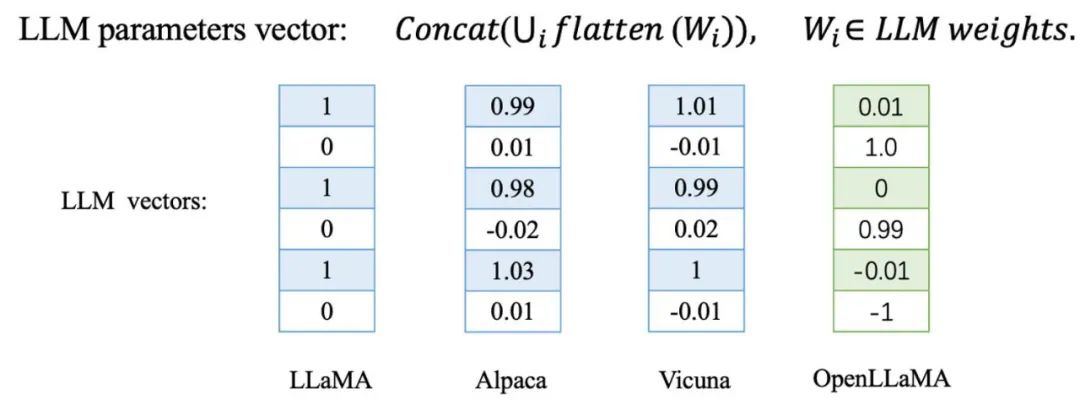
Ils ont été vérifiés sur une série de modèles dérivés de LLaMA, notamment l'Alpaga et la Vicuna obtenus par un réglage fin du LLaMA, et le LLaMA chinois et l'Alpaga chinois obtenus par un pré-entraînement supplémentaire du LLaMA. En outre, ils ont également testé des modèles de base formés de manière indépendante, tels que Baichuan et Shusheng.

Le modèle dérivé LLaMA marqué en bleu dans le tableau et le modèle de base LLaMA-7B présentent une similarité cosinus extrêmement élevée dans le vecteur de paramètres, ce qui signifie que ces modèles dérivés sont très proches du modèle de base dans la direction du vecteur de paramètres. En revanche, les modèles de base formés indépendamment et marqués en rouge présentent une situation complètement différente, avec leurs directions vectorielles de paramètres totalement indépendantes.
Sur la base de ces observations, ils se sont demandé s'ils pouvaient créer une empreinte digitale du modèle basée sur cette règle empirique. Cependant, une question clé demeure : cette approche est-elle suffisamment robuste contre les attaques malveillantes ?
Afin de vérifier cela, l'équipe de recherche a ajouté la similarité des paramètres entre les modèles comme perte de pénalité lors du réglage fin de LLaMA, de sorte que lors du réglage fin du modèle, la direction des paramètres s'écarte autant que possible du modèle de base, et testé si le modèle peut maintenir les performances. En même temps, ils se sont écartés de la direction des paramètres d'origine :

Ils ont testé le modèle d'origine et le modèle obtenu en ajoutant un réglage fin de la perte de pénalité sur 8 benchmarks tels que BoolQ et MMLU. . Comme vous pouvez le voir sur le graphique ci-dessous, les performances du modèle se détériorent rapidement à mesure que la similarité du cosinus diminue. Cela montre qu'il est assez difficile de s'écarter de la direction des paramètres d'origine sans endommager les capacités du modèle de base !


Actuellement, la direction du vecteur paramètre d'un grand modèle est devenue un indicateur extrêmement efficace et robuste pour identifier son modèle de base. Cependant, l’utilisation directe de la direction du vecteur paramètre comme outil d’identification semble poser certains problèmes. Premièrement, cette approche nécessite de révéler les paramètres du modèle, ce qui peut ne pas être acceptable pour de nombreux grands modèles. Deuxièmement, l'attaquant peut simplement remplacer les unités cachées pour attaquer la direction du vecteur de paramètres sans sacrifier les performances du modèle.
Prenons l'exemple du réseau neuronal à action directe (FFN) dans Transformer. En remplaçant simplement les unités cachées et en ajustant leurs poids en conséquence, vous pouvez modifier la direction du poids sans changer la sortie du réseau.

De plus, l'équipe a également mené une analyse approfondie des attaques de mappage linéaire et des attaques de déplacement sur l'intégration de mots de grand modèle. Ces résultats soulèvent une question : comment devrions-nous répondre et résoudre efficacement ces problèmes face à des méthodes d’attaque aussi diverses ?
Ils ont dérivé trois ensembles d'invariants robustes à ces attaques en éliminant les matrices d'attaque par multiplication entre les matrices de paramètres. "Des invariants aux empreintes digitales lisibles par l'homme" des calculs sont nécessaires pour déterminer la relation entre les différents grands modèles. Existe-t-il une manière plus intuitive et plus compréhensible de présenter ces informations ?
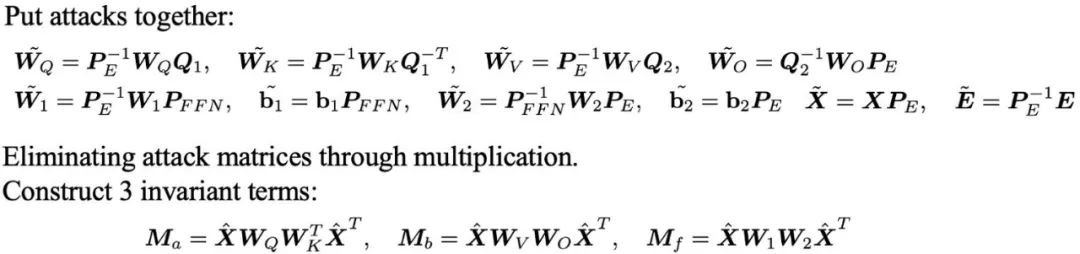
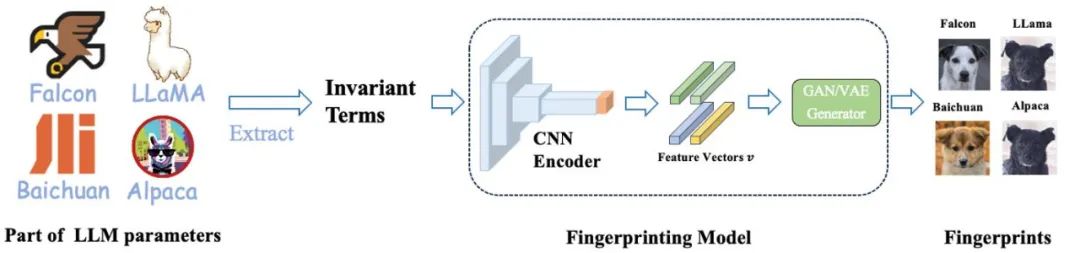
Ils ont d'abord extrait les invariants de certains paramètres du grand modèle, puis ont utilisé l'encodeur CNN pour coder la matrice invariante dans un vecteur de caractéristiques obéissant à la distribution gaussienne tout en conservant la localité, et enfin utilisé un GAN ou un VAE fluide comme générateur d'images pour décoder ces vecteurs de caractéristiques en images visuelles (c'est-à-dire des images de chiens). Ces images sont non seulement lisibles par l'homme, mais démontrent également visuellement les similitudes entre les différents modèles, servant efficacement d'« empreinte visuelle » pour les grands modèles. Ce qui suit est le processus détaillé de formation et d’inférence.

Dans ce cadre, l'encodeur CNN est la seule partie qui doit être formée. Ils utilisent l'apprentissage contrastif pour assurer la préservation locale de l'encodeur, tout en utilisant l'apprentissage contradictoire génératif pour garantir que le vecteur de caractéristiques obéit à une distribution gaussienne, cohérente avec l'espace d'entrée du générateur GAN ou VAE.
Il est important de noter que pendant le processus de formation, ils n'ont pas besoin d'utiliser de paramètres de modèle réels, toutes les données sont obtenues par échantillonnage de distribution normale. Dans les applications pratiques, l'encodeur CNN formé et le générateur StyleGAN2 disponible dans le commerce formé sur l'ensemble de données canines AFHQ sont directement utilisés pour l'inférence.
Générer des empreintes digitales pour différents grands modèles
Pour vérifier l'efficacité de cette méthode, l'équipe a mené des expériences sur une variété de grands modèles largement utilisés. Ils ont sélectionné plusieurs grands modèles open source bien connus, tels que Falcon, MPT, LLaMA2, Qwen, Baichuan et InternLM, ainsi que leurs modèles dérivés, calculé les invariants de ces modèles et généré l'image de l'empreinte digitale comme le montre la figure ci-dessous. .

Les empreintes digitales des modèles dérivés sont très similaires à celles de leurs modèles originaux, et nous pouvons intuitivement identifier à partir des images sur quel modèle prototype ils sont basés. De plus, ces modèles dérivés conservent également une forte similarité cosinus avec le modèle original en termes d'invariants.
Par la suite, ils ont effectué des tests approfondis sur les modèles de la famille LLaMA, notamment Alpaca et Vicuna obtenus via SFT, les modèles avec un vocabulaire chinois étendu, les chinois LLaMA et BiLLa obtenus grâce à un pré-entraînement supplémentaire, le Beaver obtenu via RLHF et le modèle d'état multimode Minigpt4, etc. .

Le tableau montre la similarité cosinusoïdale des invariants entre les modèles de la famille LLaMA. En même temps, l'image montre les images d'empreintes digitales générées pour ces 14 modèles. Leur similarité est toujours très élevée. Nous pouvons juger à partir des images d'empreintes digitales qu'elles proviennent du même modèle. Il convient de noter que ces modèles couvrent une variété de méthodes d'entraînement différentes telles que le SFT, le pré-entraînement supplémentaire, le RLHF et la multimodalité, ce qui valide encore davantage la méthode proposée par l'étude. robustesse des grands modèles dans différents paradigmes de formation ultérieurs.
De plus, la figure ci-dessous représente les résultats expérimentaux qu'ils ont menés sur 24 modèles de base open source formés indépendamment. Grâce à leur méthode, chaque modèle de base indépendant reçoit une image d'empreinte digitale unique, qui démontre de manière frappante la diversité et la différence des empreintes digitales entre les différents grands modèles. Dans le tableau, les résultats des calculs de similarité entre ces modèles sont cohérents avec les différences présentées dans leurs images d'empreintes digitales.

Enfin, l'équipe a en outre vérifié le caractère unique et la stabilité de la direction des paramètres du modèle de langage formé indépendamment à petite échelle. Ils ont pré-entraîné quatre modèles GPT-NeoX-350M à partir de zéro en utilisant un dixième de l'ensemble de données Pile.
Ces modèles sont identiques dans leur configuration, la seule différence est l'utilisation de différentes graines de nombres aléatoires. Il ressort clairement du graphique ci-dessous que seule la différence entre les valeurs de départ de nombres aléatoires conduit à des directions et des empreintes digitales des paramètres de modèle significativement différentes, ce qui illustre pleinement le caractère unique des directions des paramètres du modèle de langage formés indépendamment.

Enfin, en comparant la similarité des points de contrôle adjacents, ils ont constaté qu'au cours du processus de pré-entraînement, les paramètres du modèle avaient progressivement tendance à être stables. Ils pensent que cette tendance sera plus évidente dans les étapes de formation plus longues et les modèles plus grands, ce qui explique aussi en partie l’efficacité de leur méthode.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
Il s'agit également d'une vidéo Tusheng, mais PaintsUndo a emprunté une voie différente. L'auteur de ControlNet, LvminZhang, a recommencé à vivre ! Cette fois, je vise le domaine de la peinture. Le nouveau projet PaintsUndo a reçu 1,4kstar (toujours en hausse folle) peu de temps après son lancement. Adresse du projet : https://github.com/lllyasviel/Paints-UNDO Grâce à ce projet, l'utilisateur saisit une image statique et PaintsUndo peut automatiquement vous aider à générer une vidéo de l'ensemble du processus de peinture, du brouillon de ligne au suivi du produit fini. . Pendant le processus de dessin, les changements de lignes sont étonnants. Le résultat vidéo final est très similaire à l’image originale : jetons un coup d’œil à un dessin complet.
 Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Dans le processus de développement de l'intelligence artificielle, le contrôle et le guidage des grands modèles de langage (LLM) ont toujours été l'un des principaux défis, visant à garantir que ces modèles sont à la fois puissant et sûr au service de la société humaine. Les premiers efforts se sont concentrés sur les méthodes d’apprentissage par renforcement par feedback humain (RL
 En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Les auteurs de cet article font tous partie de l'équipe de l'enseignant Zhang Lingming de l'Université de l'Illinois à Urbana-Champaign (UIUC), notamment : Steven Code repair ; doctorant en quatrième année, chercheur
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
Montrez la chaîne causale à LLM et il pourra apprendre les axiomes. L'IA aide déjà les mathématiciens et les scientifiques à mener des recherches. Par exemple, le célèbre mathématicien Terence Tao a partagé à plusieurs reprises son expérience de recherche et d'exploration à l'aide d'outils d'IA tels que GPT. Pour que l’IA soit compétitive dans ces domaines, des capacités de raisonnement causal solides et fiables sont essentielles. La recherche présentée dans cet article a révélé qu'un modèle Transformer formé sur la démonstration de l'axiome de transitivité causale sur de petits graphes peut se généraliser à l'axiome de transitivité sur de grands graphes. En d’autres termes, si le Transformateur apprend à effectuer un raisonnement causal simple, il peut être utilisé pour un raisonnement causal plus complexe. Le cadre de formation axiomatique proposé par l'équipe est un nouveau paradigme pour l'apprentissage du raisonnement causal basé sur des données passives, avec uniquement des démonstrations.
 Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Récemment, l’hypothèse de Riemann, connue comme l’un des sept problèmes majeurs du millénaire, a réalisé une nouvelle avancée. L'hypothèse de Riemann est un problème mathématique non résolu très important, lié aux propriétés précises de la distribution des nombres premiers (les nombres premiers sont les nombres qui ne sont divisibles que par 1 et par eux-mêmes, et jouent un rôle fondamental dans la théorie des nombres). Dans la littérature mathématique actuelle, il existe plus d'un millier de propositions mathématiques basées sur l'établissement de l'hypothèse de Riemann (ou sa forme généralisée). En d’autres termes, une fois que l’hypothèse de Riemann et sa forme généralisée seront prouvées, ces plus d’un millier de propositions seront établies sous forme de théorèmes, qui auront un impact profond sur le domaine des mathématiques et si l’hypothèse de Riemann s’avère fausse, alors parmi eux ; ces propositions qui en font partie perdront également de leur efficacité. Une nouvelle percée vient du professeur de mathématiques du MIT, Larry Guth, et de l'Université d'Oxford
 Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
acclamations! Qu’est-ce que ça fait lorsqu’une discussion sur papier se résume à des mots ? Récemment, des étudiants de l'Université de Stanford ont créé alphaXiv, un forum de discussion ouvert pour les articles arXiv qui permet de publier des questions et des commentaires directement sur n'importe quel article arXiv. Lien du site Web : https://alphaxiv.org/ En fait, il n'est pas nécessaire de visiter spécifiquement ce site Web. Il suffit de remplacer arXiv dans n'importe quelle URL par alphaXiv pour ouvrir directement l'article correspondant sur le forum alphaXiv : vous pouvez localiser avec précision les paragraphes dans. l'article, Phrase : dans la zone de discussion sur la droite, les utilisateurs peuvent poser des questions à l'auteur sur les idées et les détails de l'article. Par exemple, ils peuvent également commenter le contenu de l'article, tels que : "Donné à".
 Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
Jul 23, 2024 pm 02:05 PM
Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
Jul 23, 2024 pm 02:05 PM
Actuellement, les modèles linguistiques autorégressifs à grande échelle utilisant le prochain paradigme de prédiction de jetons sont devenus populaires partout dans le monde. Dans le même temps, un grand nombre d'images et de vidéos synthétiques sur Internet nous ont déjà montré la puissance des modèles de diffusion. Récemment, une équipe de recherche de MITCSAIL (dont Chen Boyuan, doctorant au MIT) a intégré avec succès les puissantes capacités du modèle de diffusion en séquence complète et du prochain modèle de jeton, et a proposé un paradigme de formation et d'échantillonnage : le forçage de diffusion (DF ). Titre de l'article : DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Adresse de l'article : https://
